# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2月26日,xAI Grok 4团队核心成员Jiayi Pan宣布离职。
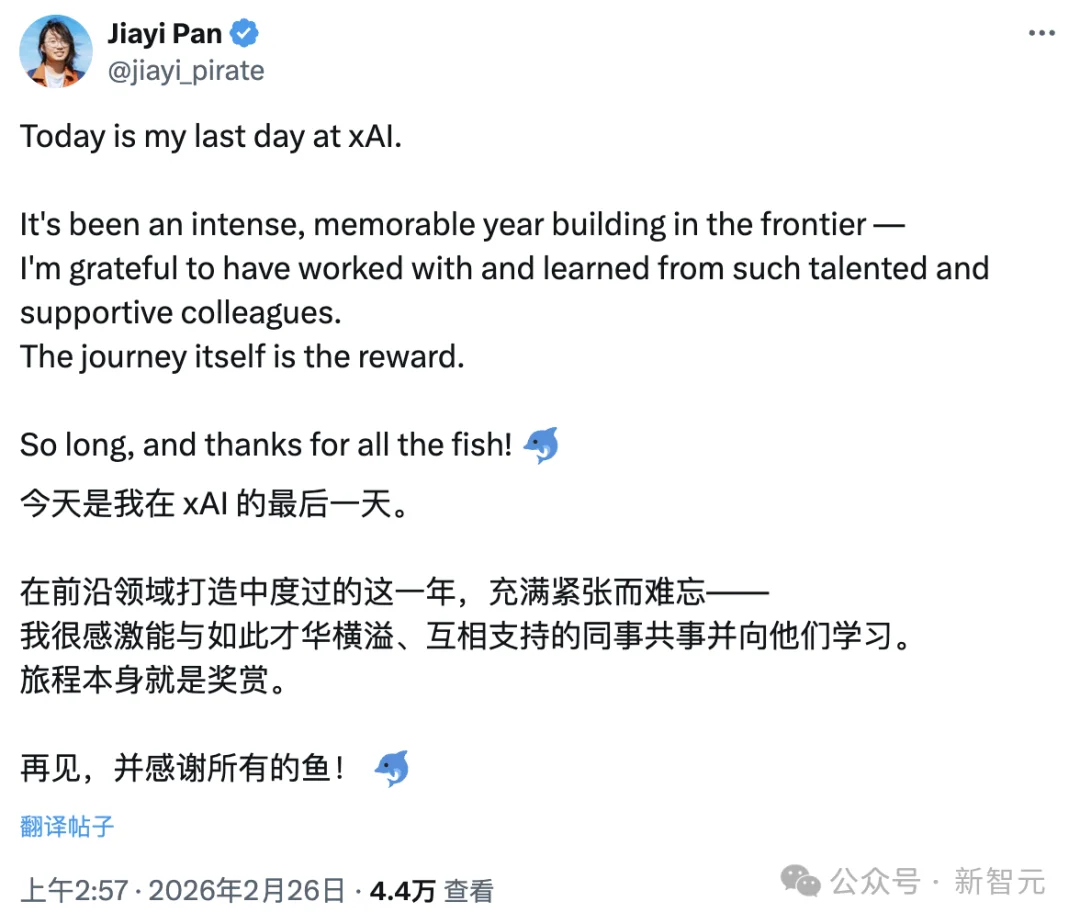
在离职声明中,他感谢了团队所有成员,给马斯克留足了面子。
几乎同一时间,Grok团队的另一位核心研究员Toby Pohlen也宣布离职。
他在X上阴阳Grok的工作机制,称「没有人能比你们更能熬夜」,然后@官方,公开叫板。
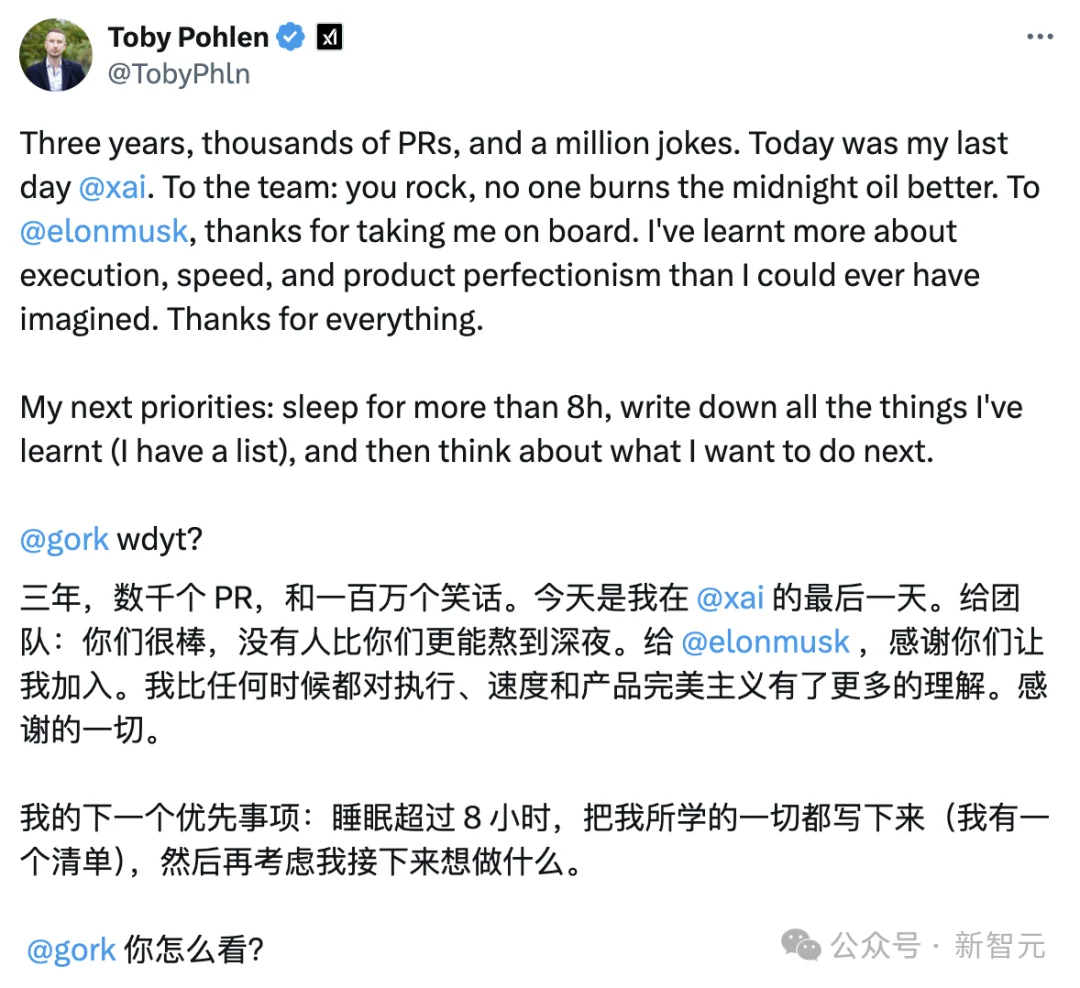
两人都是grok团队的重要贡献者,却在48小时内相继离开,这让外界对xAI内部状况产生了更多猜测。
4年,Jiayi Pan从一个初学者成长为Grok 4的核心贡献者,又选择了一条与巨头算力竞赛截然不同的技术路径。
四年蜕变
从AlphaGo迷弟到Grok 4贡献者
Jiayi Pan的AI之路始于2019年。
他本科就读于密歇根大学,获得计算机科学与电子计算机工程双学位,2023年毕业。
那时,Jiayi Pan对RL还一无所知。据他自己回忆,当导师提到RL时,他下意识想到的还只是AlphaGo。

2023年,他进入加州大学伯克利分校攻读博士,研究语言模型与视觉/机器人学的结合。
在Berkeley的早期项目中,他开发了SWE-Gym,这是一个将RL引入软件工程领域的环境。
代码传送门:https://github.com/SWE-Gym/SWE-Gym
该项目基于SWE-bench数据集的2294个真实GitHub Issue,要求AI不仅能读懂代码,还要生成可通过测试的Patch。
这为他后续的TinyZero研究——让AI学会修正自己,奠定了基础。
2025年5月,Pan加入xAI的Reasoning团队,4开发的核心成员之一。
在xAI的9个月里,他参与了强化学习模块的优化,推动模型从简单预测向自我验证演进。
也正是在这段时间,他启动了TinyZero项目。
30美元的颠覆
TinyZero「羞辱」巨头
2025年,Jiayi Pan在X上宣布开源TinyZero。
这是一个仅需30美元训练成本的3B参数模型,通过纯强化学习实现了自我验证和推理能力。
代码传送门:https://github.com/Jiayi-Pan/TinyZero
TinyZero基于Qwen2.5-3B基础模型,使用veRL框架在Countdown和Multiplication等任务上训练。
实验结果显示,基础模型在Countdown任务上的准确率从0%提升到RL训练后的80%以上。
这验证了一个假设:DeepSeek R1-Zero展现的自我推理能力,不是靠海量参数堆出来的,而是可以通过纯强化学习在小模型上复现的。
通往高级推理能力的路径,可能不需要5000亿美元的基础设施投资。
同一时期,Sam Altman宣布Stargate计划,计划在4年内投资数千亿美元建设AI基础设施,与Microsoft和Oracle合作。
但据报道,该项目因三方利益冲突而陷入停滞,到2025年底,一个数据中心都没建成。

相比之下,TinyZero的性价比拉满。
无需海量数据,无需庞大资金注入,纯靠RL,在极低的算力下完成了关键突破。
这或许也解释了为什么Pan等核心成员相继离职。
当你已经验证了一条不依赖巨头资源的技术路径,留在算力军备竞赛中还有意义吗?
出错了!TinyZero的元认知觉醒
TinyZero最引人注目的不是成本,而是它展现出的「元认知」特征。
在Countdown游戏中,模型不仅会预测答案,还会在输出最终答案前,进行完整的试错与回溯。
训练日志显示,模型会频繁输出<think>标签,内含自我质疑的语句。
例如,当计算路径偏离目标时,它会自动生成类似「Wait, that's wrong」的中间思维链,并立即启动新一轮推演。
这种行为模式此前只在DeepSeek R1-Zero等大规模模型中观察到。
R1-Zero的训练过程中曾出现「顿悟」式的能力跃迁,而这通常需要数周的迭代。
但TinyZero在3B参数、30美元成本的条件下就复现了这一现象。
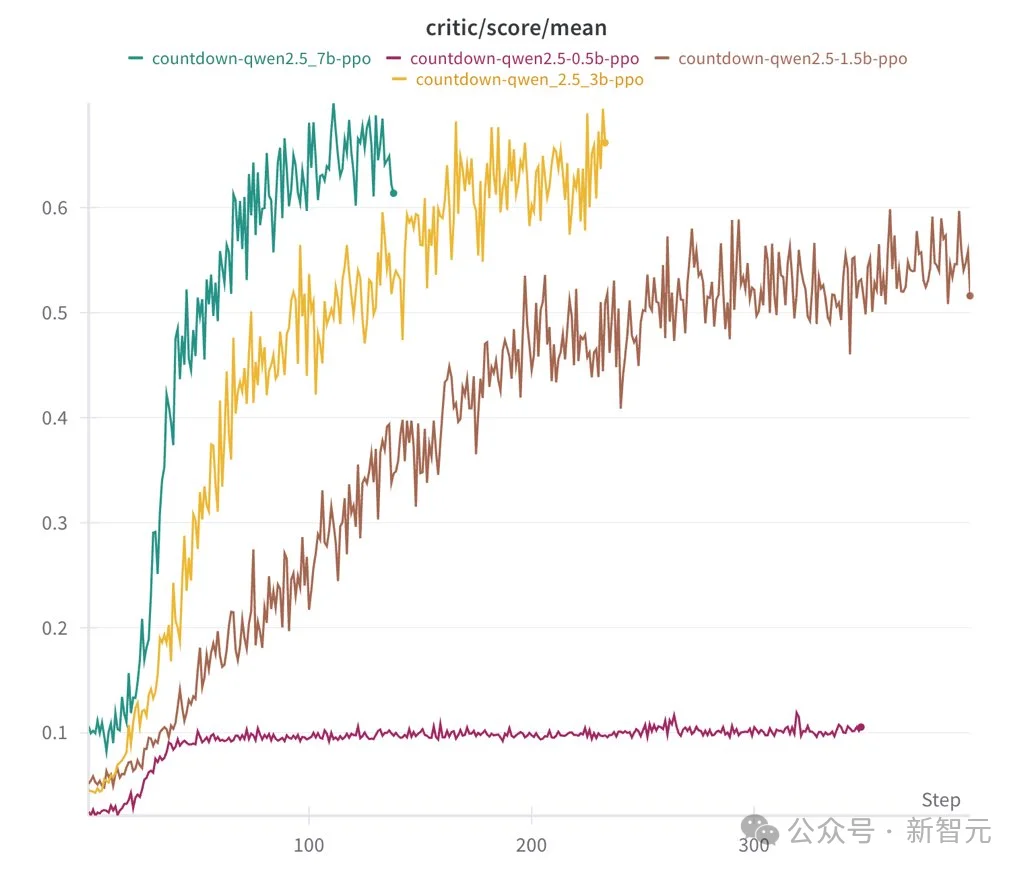
Countdown任务中不同参数规模模型的PPO训练critic score曲线。可以看到,即使是3B的小模型,经过强化学习训练后也能展现出明显的能力提升。
这证明,Scaling Law负责堆砌知识广度,而RL负责打通逻辑深度的最后一公里,两者的结合不一定需要海量参数。
随着TinyZero的开源,这种自我纠错能力不再是巨头的专属技术。
任何开发者都可以在自己的垂直领域训练出具备思考后再回答能力的AI。
技术拼图:自我进化的可能性
回顾Jiayi Pan的研究脉络,可以看到一条清晰的技术路径:
在Berkeley期间开发的SWE-Gym,将软件工程基准SWE-bench转化为强化学习环境,训练AI修复真实代码问题。这是让AI学会改代码。
在xAI期间参与的Grok 4项目,将强化学习应用于大模型推理能力的提升,这让AI学会推理。
而TinyZero的开源,则证明了推理能力可以在小模型上通过纯RL实现,这是让AI学会自我纠错。
当这三块拼图组合在一起,一个更具想象力的可能性浮现:如果AI既能纠错,又能改代码,那它是否能优化自己的训练代码,从而实现某种程度的「自我进化」?
而这,正是2025年发布的Humanity's Last Exam(HLE)基准所隐喻的场景。

论文链接:https://arxiv.org/abs/2501.14249
HLE是一个多模态、超高难度的AI评估基准。
现有的MMLU等测试已被模型以90%+的准确率攻破,失去了区分度,而当AI能力持续提升。
人类需要什么样的「最后一道防线」来评估超级智能?
Jiayi Pan的工作,无论是SWE-Gym、Grok 4还是TinyZero都在逼近这个问题的边界。
他已经离开了xAI,去向未知。但他留下的代码和论文清晰地指向一个方向:
高级AI能力的实现,可能不需要依赖巨头的算力资源,而是可以通过方法论的创新在更小的规模上达成。
这带来了技术平权的可能,也带来了风险扩散的隐忧。
当任何开发者都能用30美元训练出具备自我纠错能力的模型,RL训练的不稳定性、开源模型的伦理边界、失控风险的防范......这些问题都没有现成答案。
或许,这确实是人类面对AI自我进化可能性的「最后一次考试」。
而这场考试,是所有人都需要参与的开卷测验。
参考资料:
https://www.linkedin.com/in/jiayi-pan-88964132a/https://x.com/jiayi_pirate/status/2026733283518906703?s=20
https://x.com/TobyPhln/status/2027188868059926705?s=20
文章来自于微信公众号 "新智元",作者 "新智元"


