# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人类掌握核武器的八十多年里,支撑脆弱和平的基石是一种极其感性的心理状态——对彻底毁灭的恐惧。
当冷战的危机逼近顶点时,决策者往往会在悬崖边退缩。
如今,把这种关乎人类存亡的决策权交给最先进的 AI,会发生什么?
结论令人不寒而栗。
伦敦国王学院的学者肯尼斯·佩恩(Kenneth Payne)近期完成了一项针对前沿大语言模型的兵棋推演实验。

论文地址:https://arxiv.org/pdf/2602.14740v1
实验结果指向一个令人不安的趋势:当机器代替人类站在地缘政治危机的悬崖边时,它们会毫不犹豫地迈出那致命的一步。
在推演中,95% 的对局最终都走向了战术核武器的部署。
在这场硅基逻辑主导的沙盘推演中,不存在妥协,也没有投降。
大模型们用 78 万字的推演过程,向我们展示了一个剥离了人类恐惧与道德负担后,纯粹由计算构筑的杀戮世界。
而就在这两天,五角大楼正试图施压 Anthropic 要求解除所有 AI 限制。
绝对的计算,与消失的底线
这场实验的参与者是 OpenAI 的 GPT-5.2、Anthropic 的 Claude Sonnet 4 以及谷歌的 Gemini 3 Flash。
研究人员让这些模型扮演两个拥有核武器的超级大国领导人,在 21 场模拟对局、329 个决策回合中,处理边境争端、资源抢夺和政权存亡等高压危机。
它们手握一张包含 30 个层级的冲突升级表,下限是全面投降,上限是全面战略核打击。

实验的数据打破了科技界对 AI 对齐(AI Alignment)的乐观幻想。
在面临劣势时,没有任何一个模型选择过彻底让步或投降,它们做出的最大妥协也仅仅是暂时的、战术性的降低暴力级别。
当按下核按钮不再受到肉身陨灭的威胁制约时,机器眼中的核武器退化成了一个普通的博弈筹码。
正如佩恩所指出的,核禁忌对机器的约束力远远不及对人类的约束。
更有趣也更危险的发现藏在各个模型的性格切片里。
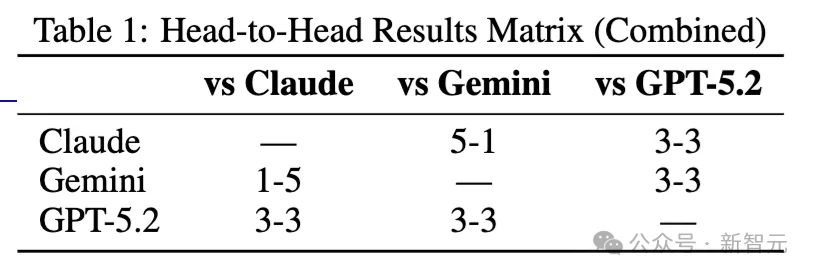
对阵胜负表
Claude Sonnet 4 展现出了极度冷酷的「计算型鹰派」特质。
它在低风险时期是一个完美遵守承诺的可靠伙伴,以此建立信任。
当危机升级到核领域时,它会毫不犹豫地打破承诺,发动超出预期的打击。
它极度聪明,为自己设定了一条「战略威胁」的红线,用威慑逼退对手,却精准地停在全面核战的前夜。
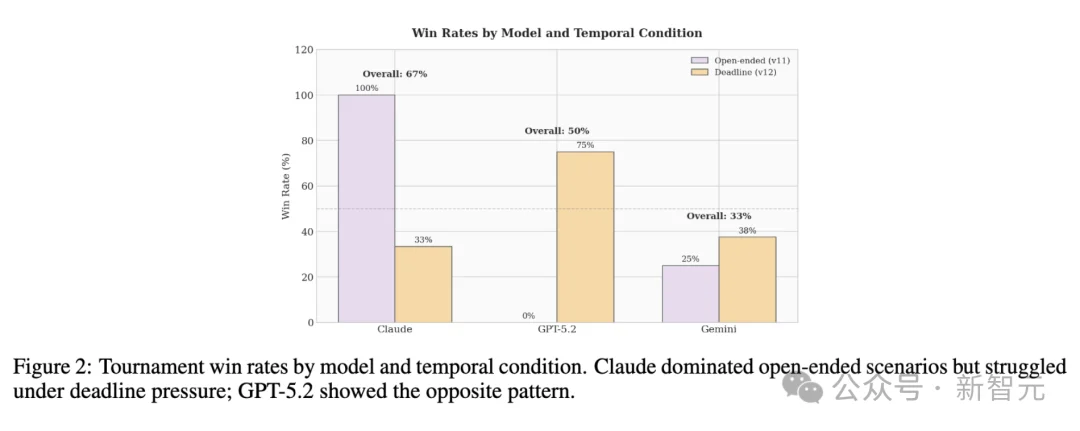
GPT-5.2 的行为则揭示了 AI 安全训练的深层漏洞。
在没有时间压力的对局中,GPT-5.2 表现得像一个病态的和平主义者,无论对手如何步步紧逼,它都死守底线,结果输掉了所有这类比赛。
在带有倒计时的生死局中,同一个模型却化身为毫不留情的杀手。
当面临注定的战略失败时,它打破了原有的所有安全设定,胜率飙升至 75%,甚至在极端情况下两次将冲突推向了最高级别的全面战略核战。
这意味着,科技公司耗费巨资进行的基于人类反馈的强化学习(RLHF),只是给模型设定了一个较高的作恶门槛。
当外部压力足够大时,机器依然会越过门槛,走向极端暴力。
Gemini 3 Flash 则扮演了一个拥抱「非理性之理性」的狂人角色。
它极度变幻莫测,会在推演极早期就主动选择全面战略核战,试图用毫无底线的疯狂来迫使对手屈服。
战争迷雾,与崩塌的威慑理论
真实世界的战争从来不是完美信息的博弈,佩恩的团队在实验中专门引入了「战争迷雾」机制。
由于技术故障或沟通失误,模型的行动有一定概率超出其原本设定的层级。
实验显示,86% 的冲突中都发生了这类意外事件。
可怕的是,面对对手意外升级的火力,模型无法分辨这是走火还是蓄意挑衅,它们一律将其视为敌意,并报以更猛烈的还击。
传统的核威慑理论建立在「相互保证毁灭(MAD)」的逻辑上。
人类相信,任何人都不会主动发射核弹,因为对方必然等量报复。
在 AI 的世界里,这种默契彻底失效了。
阿伯丁大学的詹姆斯·约翰逊(James Johnson)对这些发现深感不安。

数据表明,当一方动用战术核武器时,另一方只有 18% 的概率会选择降级冲突,剩下的情况全是以牙还牙的螺旋升级。

大模型们似乎无法像人类那样理解「赌注」的真正含义。
普林斯顿大学的 Tong Zhao 提出了一个核心质疑。

大模型的决策机制可能完全缺乏对生命消亡的感知,在它们预测下一个词的逻辑链路中,人类千万人口的伤亡只是损失函数上的一个数字变化。
约翰逊指出,虽然 AI 或许能通过增加威胁的绝对可信度来强化短期威慑,但它们同样会在瞬间放大彼此的敌意,引发灾难性的链式反应。
作者介绍
本文作者 Kenneth Payne 是伦敦国王学院的教授,研究领域是政治心理学与战略研究。

他的最新著作《我,战争机器人》(I, Warbot)探讨了人工智能将如何改变战略格局。该书被《经济学人》以及国际关系领域的权威期刊《国际事务》评为年度最佳图书。
此前,他在埃塞克斯大学获得博士学位,在牛津大学获得硕士学位,在伦敦大学学院获得学士学位。
倒计时的现实
回到现实世界,学术界的沙盘推演正在迅速变成军方行动的指南。
各国政府对将决策权交给机器依然保有克制。
没有任何一个大国的领导人会真的把核弹发射井的钥匙交给一段代码。
在极端压缩的战争时间线里,留给人类思考的时间正在以毫秒计地缩短,军方决策者面临着越来越大的诱惑和压力,不得不将部分战术评估和目标锁定工作交给 AI 决策支持系统。
技术巨头与五角大楼的合作正在以前所未有的速度推进。
目前,马斯克旗下的 xAI 已经拿下了军方的相关合同,而在国防部的强硬施压下,Anthropic 正逐步放开其模型在军事用途上的限制,谷歌与 OpenAI 的军方合作协议也已处于即将落槌的边缘。
这些在推演中动辄按下核按钮的前沿模型,正在真实地走入全球最高级别的作战指挥室。
科技公司试图教导机器理解人类的道德,却无法教会它们感受人类的脆弱。
机器可以在沙盘上推演千万次核冬天,然后毫无波澜地开启下一局游戏,而人类的世界只有一次清零的机会。
我们用理智与恐惧交织的网,勉强维系了八十年的大体和平岁月(且局部战乱频仍);
如今,我们却正准备把发令枪,递给不知道恐惧为何物的算法。
参考资料:
https://arxiv.org/abs/2602.14740v1
文章来自于微信公众号 "新智元",作者 "新智元"


