# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
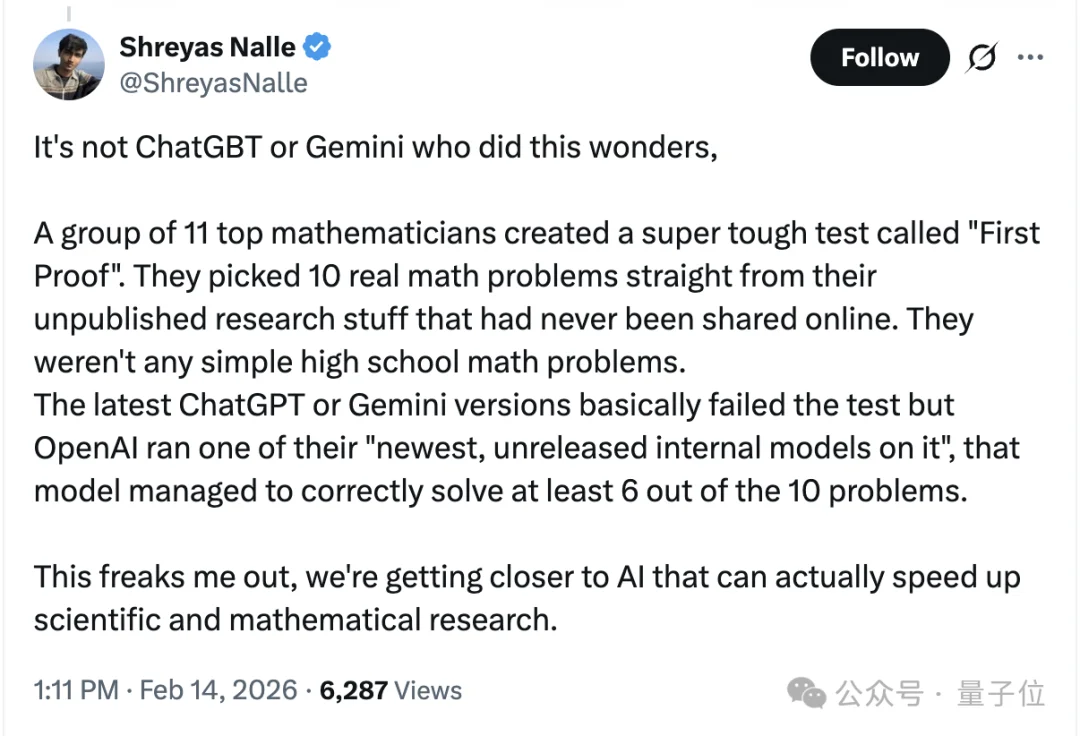
在谷歌发布Gemini 3 Deep Think爆火后,OpenAI也开始放出新的能力信号。
刚刚,OpenAI表示:他们用尚未发布的内部模型,在一周内尝试解答10道来自数学家科研现场的真实问题,其中有5道被认为基本正确。
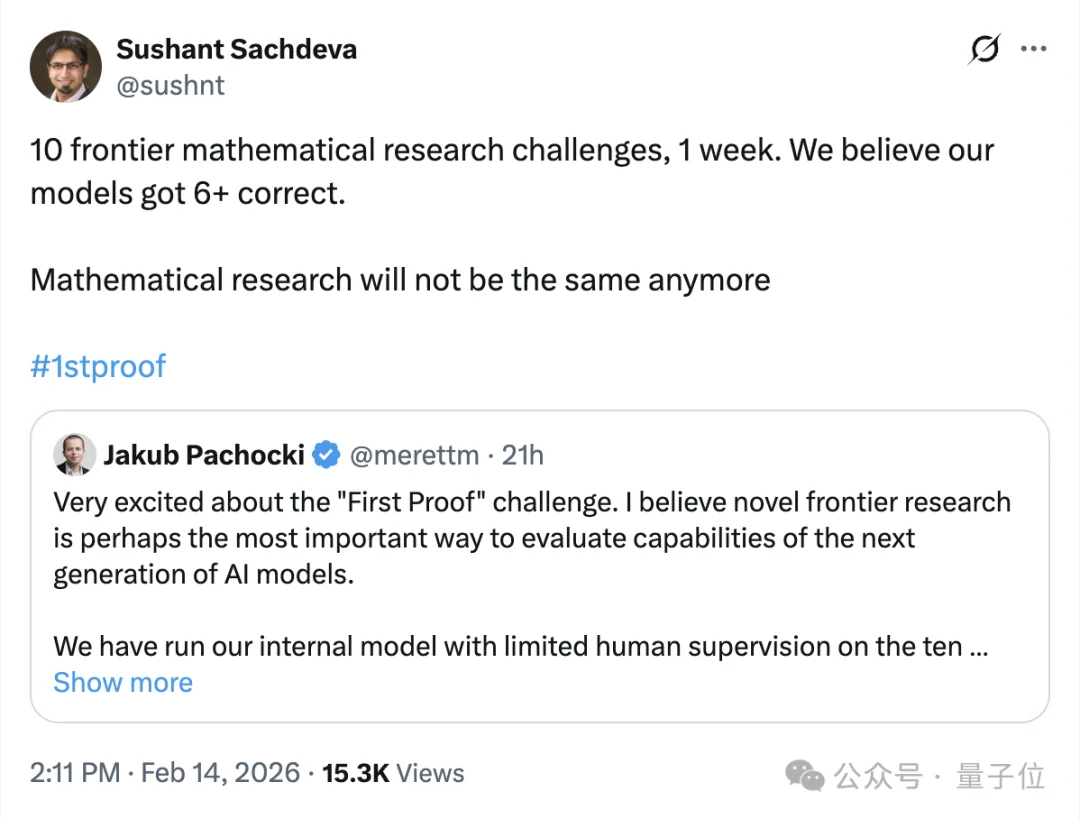
值得一提的是,这批题目与此前GPT、Gemini等模型在IMO类测试中取得金牌成绩时面对的题目完全不同。
它们不来自标准题库,也不是竞赛题,而是直接取自数学家真实研究过程中的自然问题。
这在很大程度上切断了模型“背答案”或通过训练数据污染获得优势的可能性,从而意味着模型自主推理能力再次进化。
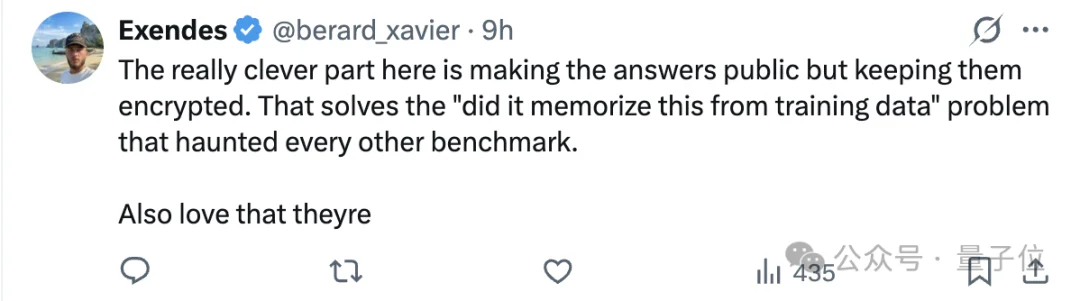
正如一位网友所说:
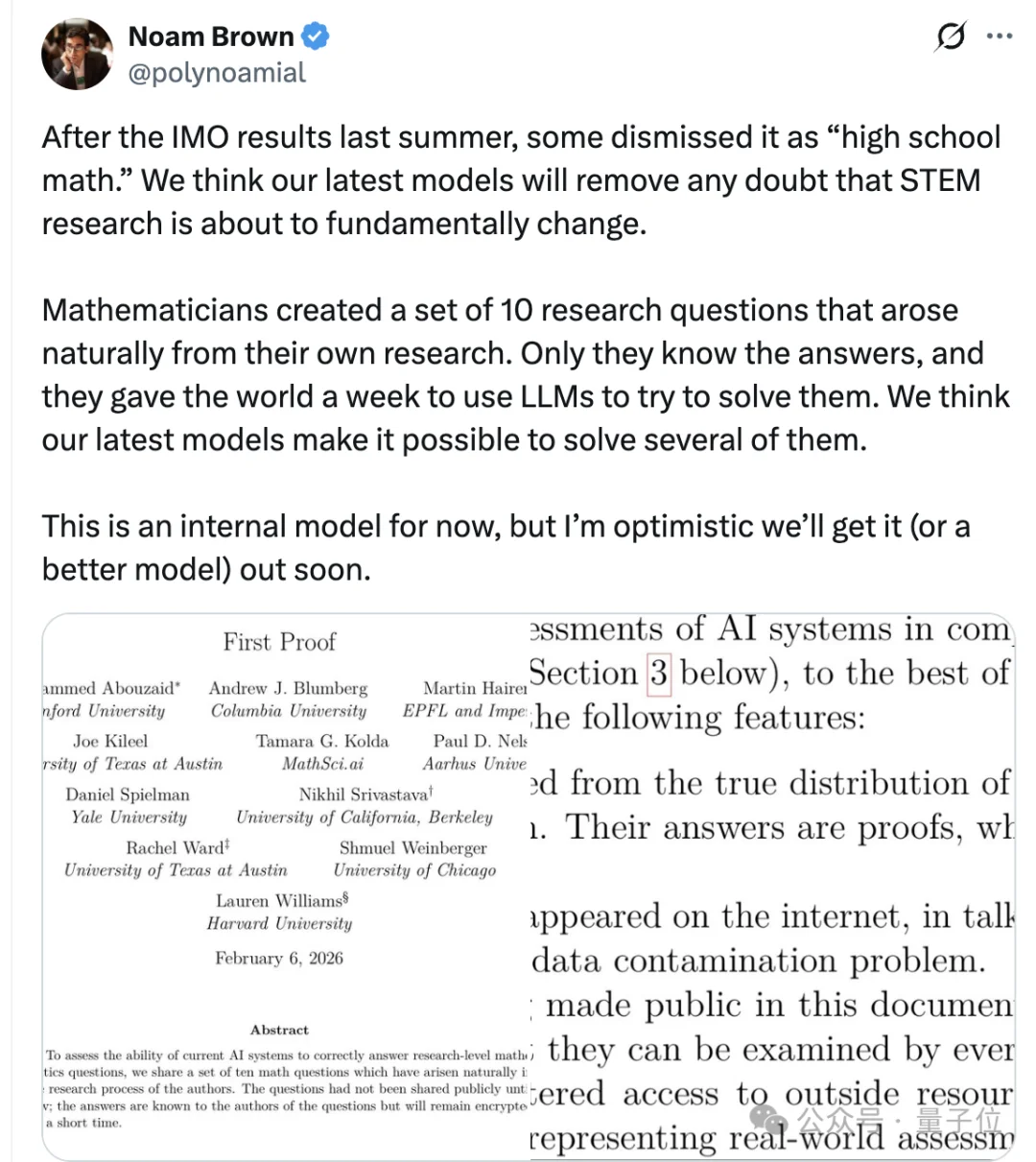
此外,据称OpenAI研究员,o1核心贡献者Noam Brown表示:
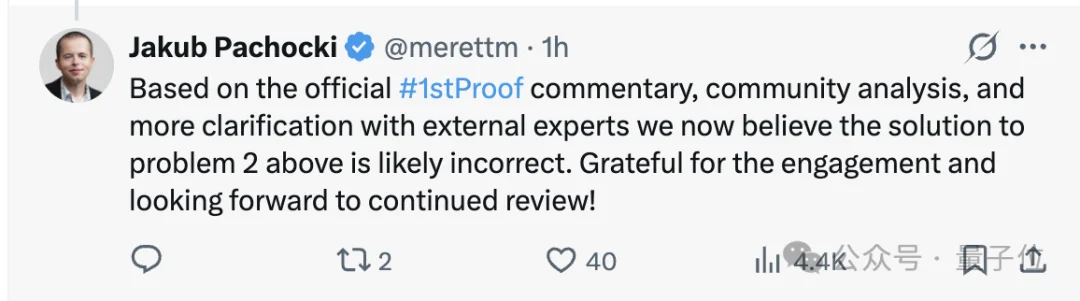
相信眼尖的你已经发现了:为什么图片里写的是6道,但正文却说是5道?
在早期评估中,确实一度认为模型做对了6道。
但随后在社区讨论与复核反馈中,第2题的解法被指出可能存在问题。
根据OpenAI的Jakub Pachocki的说法,第2题很可能是错的,因此更保守的估计应该在5道左右。
至于具体做对了哪些题,咱们先看这次测试本身是如何进行的。
OpenAI方面表示,这只是一次为期一周的侧向冲刺:
主要通过查询他们当前正在训练的模型来完成,因此方法论上仍有不少局限。
在评估过程中,他们没有向模型提供证明思路或数学提示。
对于部分解答,只是在专家反馈后要求模型进一步展开证明细节。
同时,团队还人工协调该模型与ChatGPT之间的往返交流,用于验证、格式整理与风格调整。
对于个别问题,最终呈现的版本是基于人工判断,从多次尝试中挑选出的最佳结果。
在下面的10道题中,OpenAI的内部模型在第4、5、6、9、10题上给出了较为可靠的答案。

接下来,我们具体来看。
问题:给定两个n次首一实根多项式p和q,定义一种特殊的卷积运算。
需要证明:反映根部拥挤程度的指标(根间距离倒数平方和)的倒数,在卷积后满足调和平均不等式。本质是在探究该运算是否会让根分布更加均匀。

模型给出的思路是:
问题:G-等变稳定范畴中,由N∞算子诱导的切片过滤结构。
模型给出的思路是:
第六题研究图论中ε-轻子集(ε-light subset) 的存在性。
若子集诱导拉普拉斯算子的能量始终不超过整图ε倍,则称其为ε-轻。
需证明:是否存在常数c,使任意图都能找到规模至少cε|V|的此类子集。
模型给出的思路是:
问题:给定若干矩阵构造四阶张量,目标是用多项式映射判定系数是否可分解为四向量外积。
模型给出的思路是:
问题:CP分解下,线性系统规模巨大。问题在于如何避免显式构造矩阵。
模型给出的思路是:
这上面的5道题,均来自1st Proof项目。
对应问题的解答文件已于2月13日发布,而模型测试是在正式发布前一周完成的。
(注:解答文件包括作者解答、原始加密答案、项目团队生成的AI解答)
需要强调的是,这些问题本身仍处在持续讨论与研究阶段,因此模型给出的结果并不存在所谓“标准答案”。
是否正确、价值几何,都需要领域专家与社区进一步评估。
也正因此,社区验证不同解题路径成为过程的一部分——
像第2题这样,最初看似成立、后来被指出问题的情况,也在意料之内。
那么,1st Proof到底是什么?
简单来说,这是一个面向AI能力评估的实验性项目,其核心目标很直接:
用真实科研过程中自然产生的数学问题,测试AI是否能够自主完成研究级证明。

项目首轮发布了一组10道研究级数学问题,用来评估AI系统在接近真实科研环境下的能力表现。
这些问题涵盖代数组合、谱图论、代数拓扑、随机分析、辛几何、表示论、李群格点、张量分析、数值线性代数等多个数学方向。
它们都来自作者自身研究过程,并且理论上可在约5页证明内解决(答案最初未公开)。
据悉,下一轮问题设计细节预计在今年3月14日公布。
问题发布后,不少研究者也参与到模型答案的验证之中。
比如,CMU助理教授Yang Liu就在社交媒体上详细讨论了第六题。
他表示OpenAI的解答基本正确,并直言当前模型在数学能力上的进步令人印象深刻。

更具体地说,他指出:
当前模型已经相当擅长证明那类自包含的问题陈述——尤其是当解法建立在已有文献思想之上,或证明本身较为简短时。
在他看来,这一框架很好地捕捉了两个方向的进展:
一端是IMO/竞赛数学,另一端则是更贴近研究环境的数学推理能力。
与此同时,也有不少讨论认为:

事实上,像1st Proof这样的测试集本身就体现了评估思路的变化。
正如一位网友所说,这次值得关注的,并不是ChatGPT或Gemini的表现,而是测试设计本身:
因为关键变化是:当模型面对无法背诵答案的问题,仍能产出被专家认真评估的证明路径时,它展现出的行为更接近自主推理,而非知识回放。
这释放了两个信号:
一方面OpenAI 内部模型的数学推理能力,正在逼近研究级问题空间。
另一方面,评测范式正在改变——
不再只是用题库刷新分数,而是开始把模型放进科研现场,用真实问题检验其思考能力。
参考链接:
[1]https://x.com/polynoamial/status/2022527227049742779
[2]https://1stproof.org/
[3]https://cdn.openai.com/pdf/a430f16e-08c6-49c7-9ed0-ce5368b71d3c/1stproof_oai.pdf
文章来自于微信公众号 "量子位",作者 "量子位"


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
