# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
全球最大游戏博主 PewDiePie,又整活了。
他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。

但就在几个月前,他对 AI 的了解还跟普通人没什么两样。
PewDiePie 本名为菲利克斯·谢尔贝格(Felix Kjellberg),坐拥逾 1.1 亿 YouTube 订阅,近年来逐渐淡出游戏直播圈,反而把大量时间放在了 AI 领域。
转折点出现在去年 11 月。他发布《STOP. Using AI Right now》,展示如何从零搭建一套带搜索、记忆和语音输出的个人 AI 助手。
而这次的新视频,他更进一步——从数据收集到模型微调,完整记录了一个 AI 小白是如何微调出一个能媲美顶流 AI 的模型。
差点烧掉两次房子,顶流网红微调大模型打败 GPT-4
PewDiePie 坦言,在开始这个项目之前,他对机器学习、模型训练和代码编程几乎一无所知。但他的逻辑很简单:
不懂就学,一步一步来。
他选用阿里旗下开源的 Qwen 2.5(32B 参数版)作为底座模型,目标是在一个名为 Aider Polyglot 的编程基准测试上超越 ChatGPT。
选择这个 benchmark 也有来由:他在之前视频里曾用 Aider 这个工具搭建自己的网页 UI,对它并不陌生。
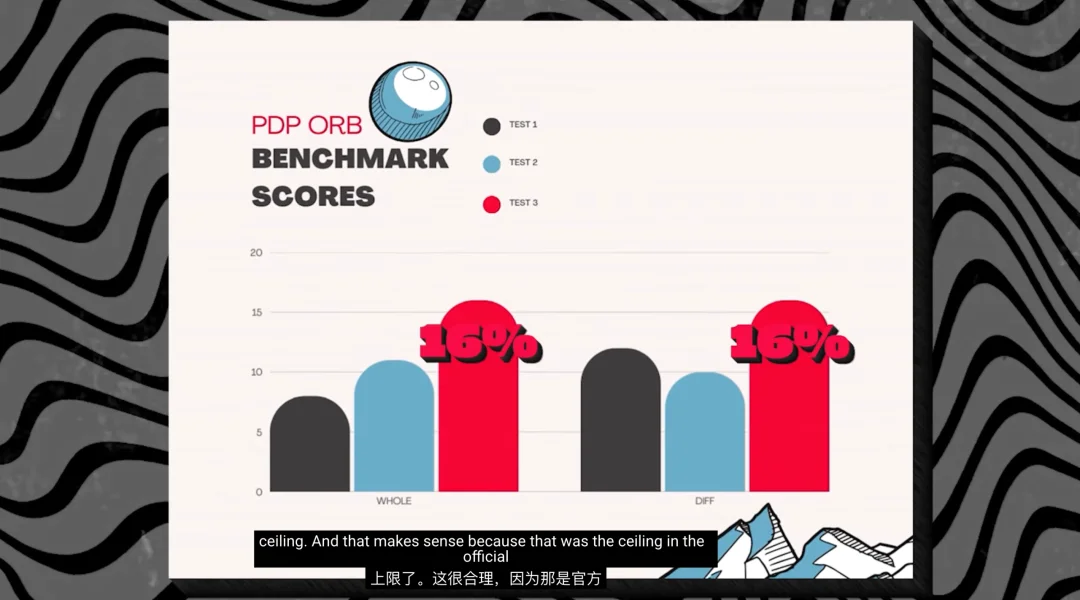
这个测试涵盖六种编程语言,而彼时 ChatGPT 的得分约为 18.2%,Qwen 2.5 在默认格式下仅有 8%。但他发现,换用「whole form」格式后可提升至 16%。
所谓「whole form」,是指模型修改代码时会把整段代码从头重写一遍,而不是只改动需要修改的部分——这意味着,只要解决格式问题,超越 ChatGPT 并非遥不可及。

而且格式只是外部设置,模型本身的能力才是真正的瓶颈。要从根本上提升,唯一的路是微调训练——而训练,需要数据。他由此开始了漫长的数据工程。
他尝试了几乎所有能想到的数据来源:挖掘 60TB 的开放代码数据集 The Stack,爬取 GitHub 公开仓库,以及让大模型批量合成训练样本。
最初他收集了约 10 万条训练数据,整个过程混乱不堪,多个 LLM 同时跑数据处理、测试、增强。
但数据质量始终是问题。
合成数据看起来格式完美,打开一看却全是错误。他为此搭建了一套「验证框架」来过滤垃圾数据,却因为框架本身的逻辑缺陷,反而让更多垃圾数据蒙混过关。
第一次正式训练跑完,模型成绩没有提升,反而更差了。他没有放弃,调整后重训,结果还是更差。这个循环持续了数月。
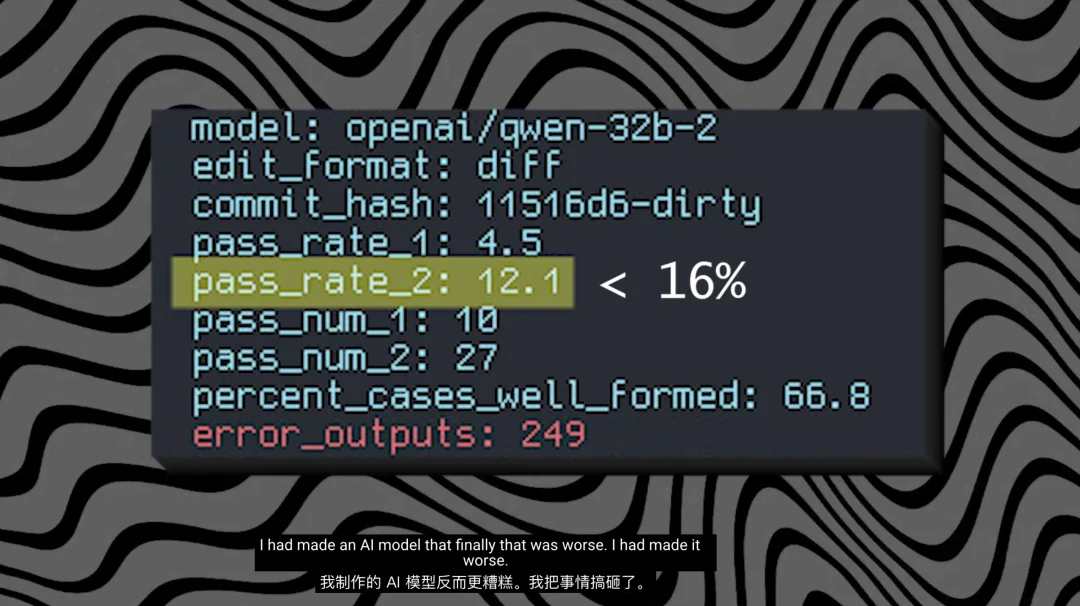
修复了测试框架之后,benchmark 终于能正常跑起来,最高跑到 16%,但
要超过 ChatGPT 的 18.2%,还有距离。
这时,一篇来自清华大学联合阿里巴巴、莫纳什大学的研究成果《Towards Widening The Distillation Bottleneck for Reasoning Models》的技术论文,带给了他新的灵感。
简单来说,就是既然直接抄大模型的长思维链会把小模型带偏,那就别直接抄。改成自己造训练数据,而且造得更像人做题时的过程。

论文地址:https://arxiv.org/html/2503.01461v1
硬件方面的折磨则更具戏剧性。
为了加入「推理链」提升模型表现,他需要更大量的算力持续运转。某次重启后,GPU 突然开始冒烟,烟雾弥漫整个房间,他关机检查,发现其中一块 GPU 已经损毁。
翻了购买记录才发现,这块出问题的来自不同工厂。其实也不意外——他这套系统用的也是从中国买的魔改版 RTX 4090显卡。

后来他又发现,自己一直在用额定 1500W 的电源线,实际运行功率却超过 2000W。换线之后,电脑仍频繁崩溃,他索性把浴室的电路「借」过来接入机器,并把 GPU 功耗从 450W 压到 175W,只为不让家里的电网随时跳闸。

他在视频里打趣说,为了一切顺利,他甚至给整套系统举行了开光仪式。
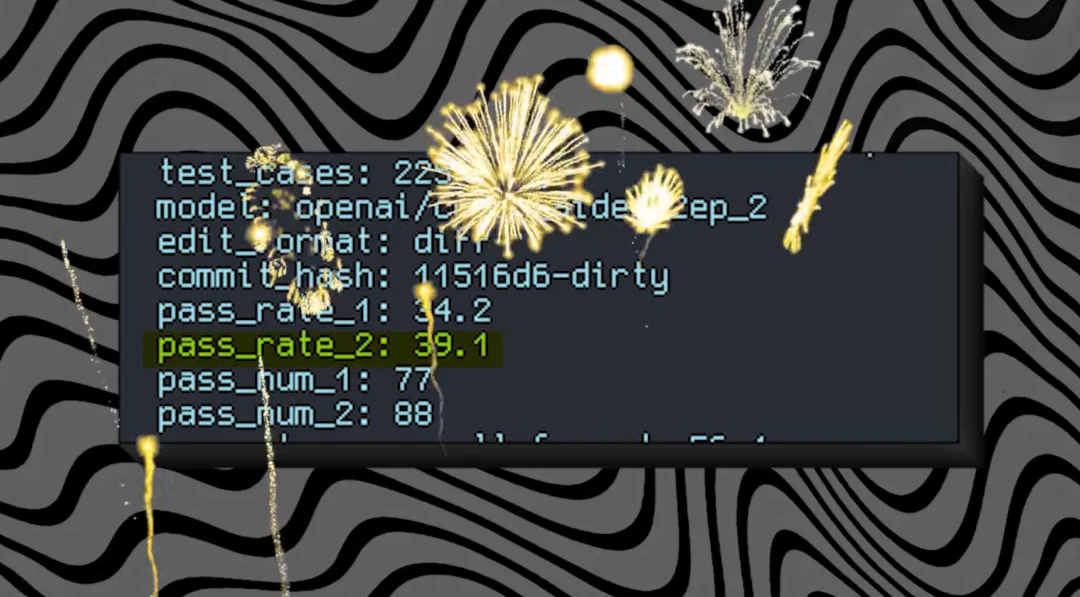
算力和数据的双重折磨之下,他开始调用 DeepSeek API 来合成约 1.5 万条高质量推理样本。这些样本数量虽少,却是他精心筛选的「精华数据」,每一条都附有详细的逐步推理过程。用这批数据完成监督微调后,基准测试成绩达到 19.6%,在数值上超越了 ChatGPT。
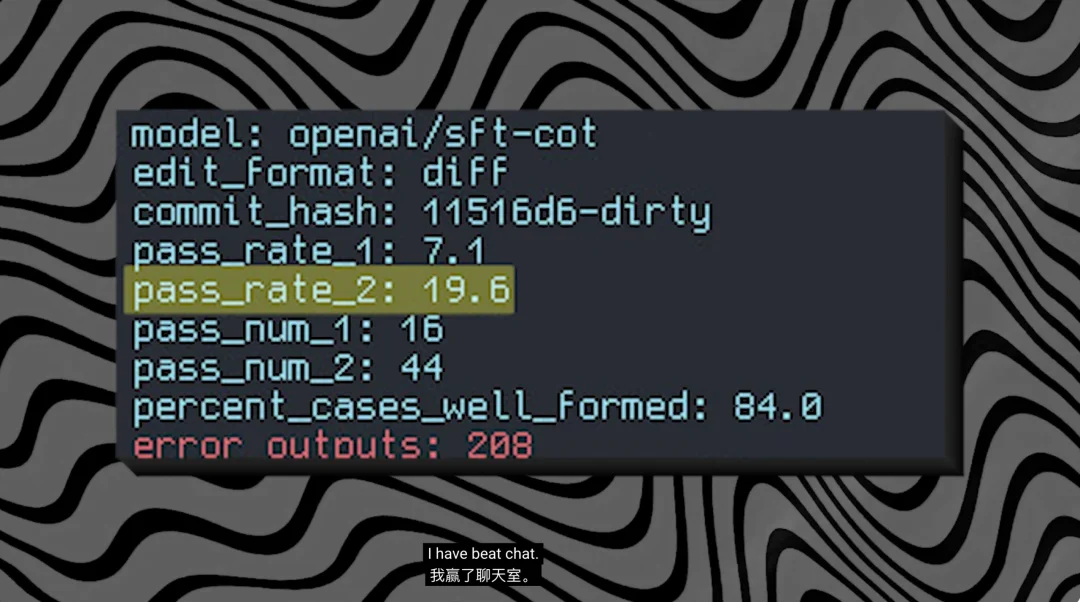
但他随即发现自己忘记做数据污染检查,即验证训练数据是否与测试集重叠。
检查后确认存在少量污染,他决定清洗数据、重头再来。这一次,他还意外发现自己此前一直在用 Qwen 的通用版本,而非专为代码优化的版本。换用正确模型、配合完整清洁数据集重训后,成绩跳升至 25%。
随后他修复了基准测试本身的 Bug,即 C++和 JavaScript 题目未被正确执行的问题,修复后重跑,成绩升至 36%。

经过最后一轮后训练,纯净去污染版本的最终成绩定格在 39.1%,超越了 GPT-4-mini 及 Gemini 2.0 Pro 等多个早期主流模型。
值得一提的是,整个微调过程中,PewDiePie 多次强调 DeepSeek 技术文档对他的帮助。在他看来,DeepSeek 不仅公开了模型权重,还发布了详尽的训练流程文档,将数据处理、推理增强等核心方法细节和盘托出。
而从 DeepSeek 的训练文档,到 Qwen 2.5 的开源底座,再到清华团队关于推理链蒸馏的论文——一个对 AI 几乎一无所知的内容创作者,能够在数月内完成从零到击败顶流模型的跨越,并不只是个人努力的故事,更绕不开中国 AI 研究对整个开源社区持续的实质性贡献。
AI 焦虑时代,普通人该如何自处
视频发布后,社交媒体上的反应截然不同。
一种是纯粹的震撼。X 网友 @birdabo 在社交媒体上写道:「PewDiePie 刚刚训练了自己的 LLM,他的模型在编码基准测试中超过了 DeepSeek V2.5、LLaMA-4 和 GPT-4o。什么鬼。」
另一位用户 @CryptoElara 则表示:「太疯狂了,Pewds。」也有人调侃:「从我的世界到机器学习!」,暗指 PewDiePie 曾以《我的世界》等游戏内容起家,如今却在折腾大语言模型的训练流程。
技术博主 @nrehiew_更是写道,他从未想象过 DeepSeek R1 论文会出现在 PewDiePie 的视频里,而更令他意外的是,PewDiePie 在整个过程中展现出的严谨程度,甚至比某些正式论文还要高。
值得一提的是,这种看似「不务正业」的深度投入,恰恰需要一种大多数人难以企及的前提——当下 AI 行业的知识迭代速度,已经快到了几乎需要全职跟进才能不掉队的程度。
互联网上流传着一句半开玩笑的推论:只有无业状态的人,才能真正追上 AI 领域的所有动态。
PewDiePie 年收入峰值超过 1500 万美元,早在订阅量爆发期就已实现财务自由,他可以花数月时间折腾一套 GPU、烧毁设备再重来,完全没有来自工作和收入的外部压力。
OpenClaw 之父 Peter Steinberger 也有着类似的处境。他长期保持对新技术的深度探索,同样是建立在早期创业变现所带来的时间自由之上的。

一方面,AI 工具的门槛确实大幅降低,让普通人得以以更低的门槛触碰以前只有顶尖工程师才能涉足的领域;另一方面,真正能沉下心来深度学习 AI、并将其转化为生产力的人,往往还是少数人。
那么,对于没有办法辞职全职研究 AI 的普通人,这个时代究竟该怎么应对?《华尔街日报》近期采访了多位 AI 领域领导者,询问他们对子女教育和职业规划的建议,或许能提供一些参考。
Anthropic 联合创始人 Daniela Amodei: 她认为,AI 无法取代的,恰恰是人与人之间的连接能力,比如共情、沟通和善意。随着 AI 在职场中越来越普遍,这些人类特质反而会愈加珍贵。她甚至认为,自己会引导孩子多社交,更深入地理解自己与他人相处的独特方式。
宾夕法尼亚大学沃顿商学院教授 Ethan Mollick: 需要整合多种技能的综合型职业,在 AI 时代反而更具韧性。以医生为例,诊断只是工作的一部分,AI 或许能在某些环节上辅助甚至超越人类,但整体职业所需的判断力、责任感和人际能力,并不会因此消失。
微软首席科学家 Jaime Teevan: 传统文科教育在这个时代的价值,被严重低估。她还观察到,与 AI 打交道已经不再是确定性的指令输入,而是基于自然语言的意图表达和批判性提问,这与人文学科的训练高度契合。
这几位处于 AI 行业核心位置的人,给出的建议却不约而同地指向了一个反直觉的方向:在一个技术迭代极快的时代,真正的护城河不是最新的技术栈,而是那些慢变量,比如沟通、判断、好奇心和接受失败的能力。

包括 PewDiePie 也在视频末尾分享了他最深的体会,他说自己在整个项目中学会了一件事:要预期失败,甚至要拥抱失败。他的模型在最终跑出 39.1% 之前,经历了无数次越训越差的循环,每一次他都几乎要放弃。
但正是这些失败,让他逐渐理解了 AI 训练的底层逻辑。他说,这种心态才是「能把你带到远方的东西」。而这个道理,显然不只适用于训练微调 AI。
附上 YouTube 视频地址:
https://www.youtube.com/watch?v=aV4j5pXLP-I
文章来自于微信公众号 "APPSO",作者 "APPSO"


【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
