# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
全新的具身模型空间能力评估范式 Theory of Space 突破了传统静态图文问答的局限,系统性地考察基础模型能否像人一样,在部分可观测的动态环境中,通过自主探索来构建、修正和利用空间信念。该论文已被 ICLR 2026 接收。
当今的多模态大模型(如 GPT-5.2, Gemini-3 Pro)在各类视觉问答榜单上屡破纪录。然而,如果希望将这些能力延伸到更真实的物理场景中,模型在空间理解上可能会面临不小的挑战。为什么会这样?
想象你走进一栋从未去过的公寓。你推开门看到沙发,走进走廊瞥见卧室的床,再往前发现厨房的冰箱。现在问你:「沙发在冰箱的哪个方向?」你通常能回答,因为你在脑海中悄悄地构建了一幅「心理地图」。
人类大多能不假思索地做到这一点。但对当前的基础模型而言,情况可能会有所不同,研究人员发现,现有的评估范式与真实物理世界的需求相比,可能存在一些差异:
西北大学李曼玲团队、斯坦福大学李飞飞与吴佳俊团队,以及华盛顿大学Ranjay Krishna团队共同牵头提出了Theory of Space(空间理论),探讨了:当减少对完整给定信息的依赖,要求基础模型通过主动探索来认识环境时,其空间认知能力会有怎样的表现?

论文链接:https://arxiv.org/abs/2602.07055
代码:https://github.com/mll-lab-nu/Theory-of-Space
项目主页:https://theory-of-space.github.io/
数据集:https://huggingface.co/datasets/MLL-Lab/tos-data
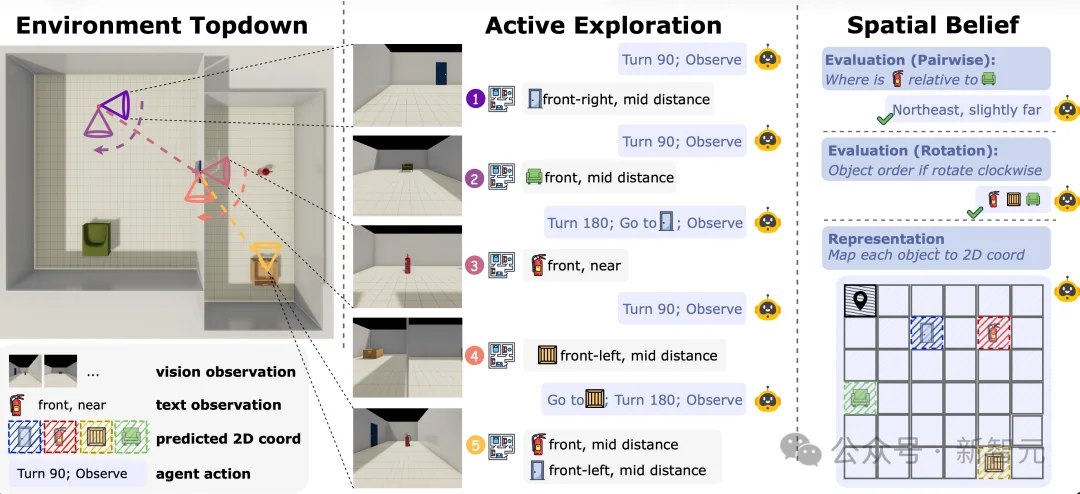
Theory of Space:主动探索、信念探测和任务评估。左侧用俯视图展示智能体在多房间局部观测条件下的行动轨迹;中间展示其在文本或视觉环境中通过「移动—转向—观察」的循环,并根据第一人称观测持续更新内部信念;右侧通过空间任务与认知地图探针,评估这些信念的表征及其使用方式。
在认知科学中,Theory of Mind(心智理论) 考察的是一个智能体能否推测他人隐藏的心理状态:「他在想什么?他知不知道这件事?」它关注的是对不可见的心智世界的建模。
Theory of Space(空间理论) 作为它在物理世界中的对称概念:考察的是一个智能体能否推测环境中尚未观测到的空间结构:「这个世界长什么样?门后面还有什么?」它关注的是对不可见的物理世界的建模。
两者的共同本质在于:智能体需要基于有限的线索,去推断隐藏的结构,并随着新信息不断地修正自己的信念。
研究人员将 Theory of Space 定义为三个紧密耦合的核心能力:
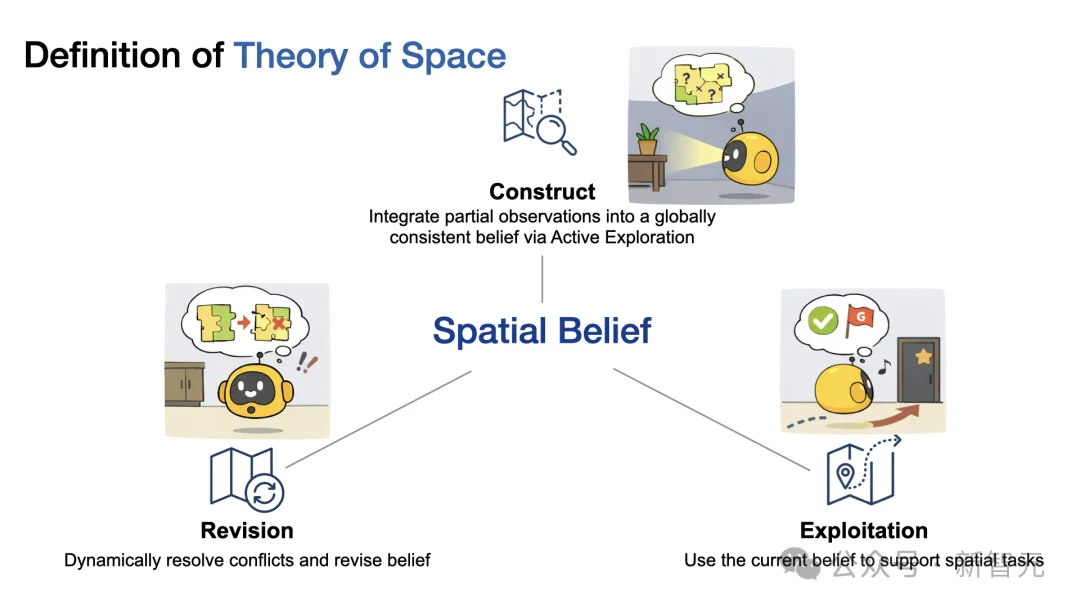
Theory of Space的核心:在部分可观测环境中,智能体围绕空间信念的构建、动态修正与利用,完成空间推理与决策。
研究人员围绕Theory of Space的三大核心能力(构建Construct、修正Revise、利用Exploit)设计了一整套评测体系,并引入认知地图显式探测作为核心贡献,实现对模型内部空间信念的直接诊断。
构建(Construct):主动探索建图
研究人员在程序化生成的多房间室内布局中,提供文本世界(符号化方向/距离)和视觉世界(ThreeDWorld 渲染的第一人称 RGB 图像)两种平行环境。智能体必须自主决定移动、旋转、观察的策略,高效构建空间信念。直觉上你可能会以为这类任务就是「多看看」。但更关键的是,智能体需要用不确定性来驱动行动,去做高效的信息获取。
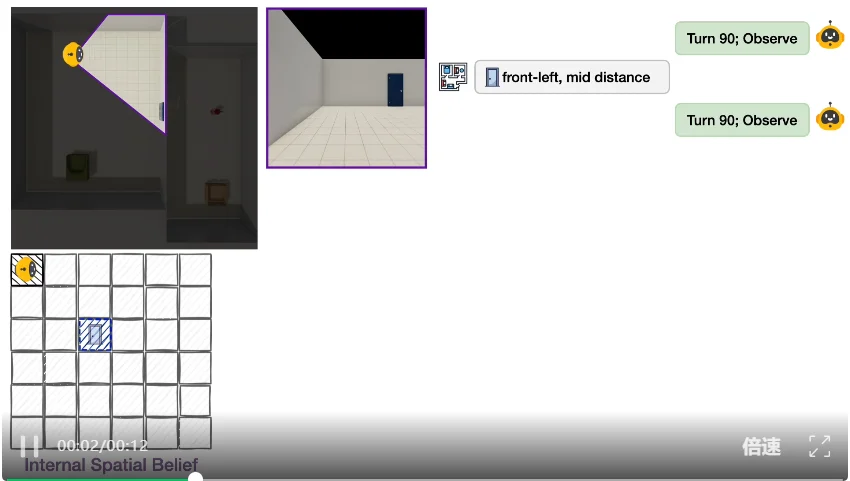
修正(Revise):在动态环境中更新过时信念
借鉴发展心理学中经典的「错误信念(False Belief)」范式:在智能体完成初次探索后,偷偷将若干物体移位或旋转,制造「旧信念」与「新现实」的冲突。智能体能否发现变化、推翻旧记忆、建立新信念?

利用(Exploit):九类空间推理任务
覆盖路径级(Route)(路径推理)和全局级(Survey)(鸟瞰视角地图推理)两个层次,全面评估空间信念的利用价值。
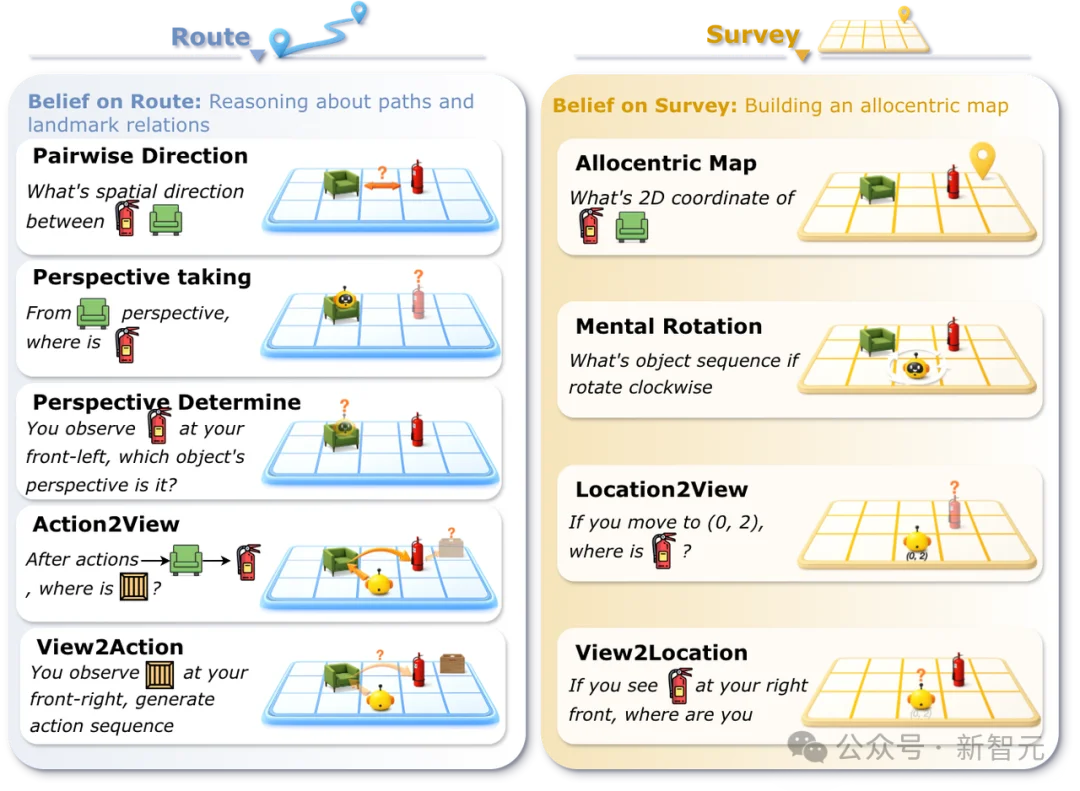
下游空间任务总览
核心贡献:显式认知地图探测
以往评估只看最终对错,内部信念是黑箱。研究人员引入显式认知地图探测(Explicit Cognitive Map Probing):每一步都要求模型以JSON格式外化其空间信念,度量准确性、感知质量、稳定性和不确定性建模。不仅知道模型答得对不对,更知道它为什么答对、为什么答错。
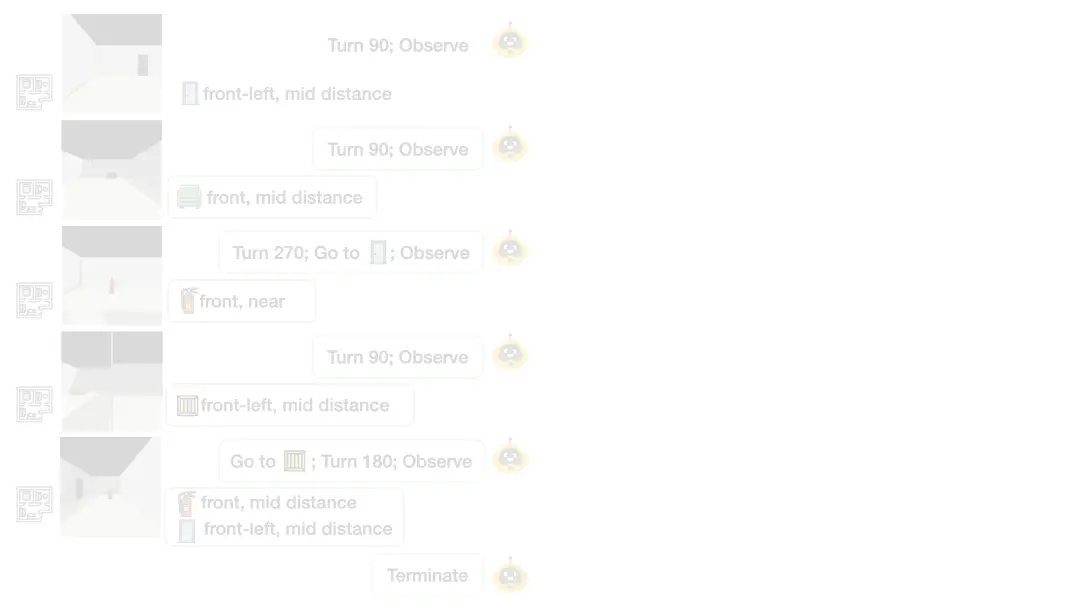
研究人员在包括GPT-5.2、Gemini-3 Pro、Claude-4.5 Sonnet等在内的六个前沿多模态大模型上进行了大规模的深度评测。通过白盒探测,深刻揭开了当前大模型在空间认知上的能力边界:
洞察一:主动信息获取是具身智能的阿喀琉斯之踵
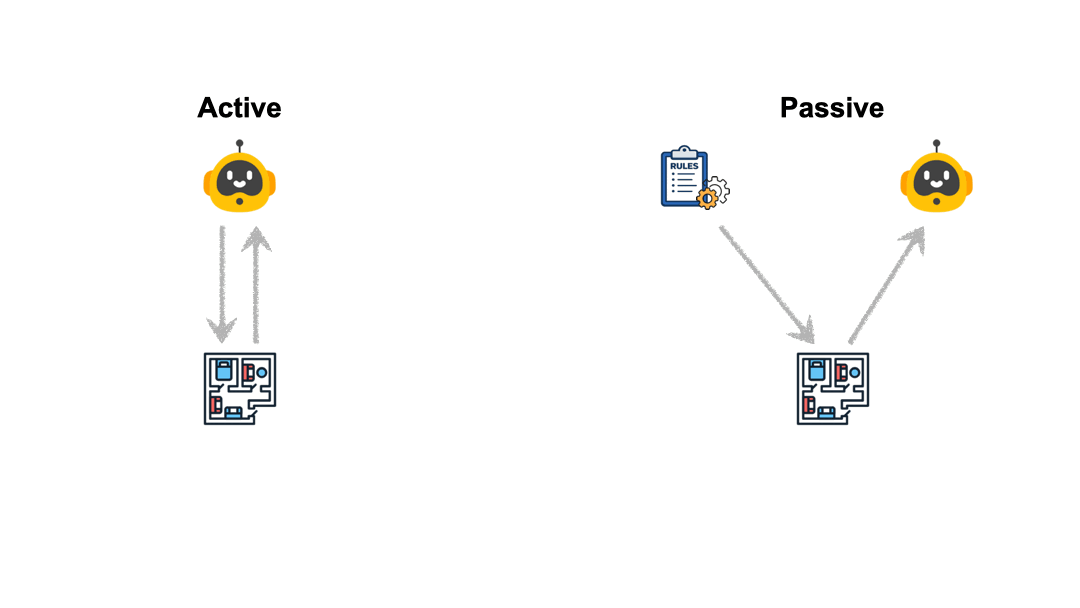
让模型自己决定「看什么」,性能大幅下降。
为了区分「探索能力」和「推理能力」,研究人员设计了脚本化的规则代理(Proxy Agent)作为探索基准:视觉世界中的代理在每个位置进行360°扫描以保证完整覆盖,文本世界中的代理则采用信念驱动的策略来最大化消除歧义。模型在被动模式下接收这些代理收集的观测日志进行推理,在主动模式下则需自主规划探索。
结果令人震惊:GPT-5.2从被动57.1降到主动46.0(视觉世界),Gemini-3 Pro从60.5降到57.3,在效率方面,规则代理仅需约9步即可达到目标覆盖,而基础模型常常需要 14 步以上且信念质量并未提升。模型「探索得多」但「探索得差」,高冗余、低效率。随着环境复杂度增加,这种差距进一步扩大。
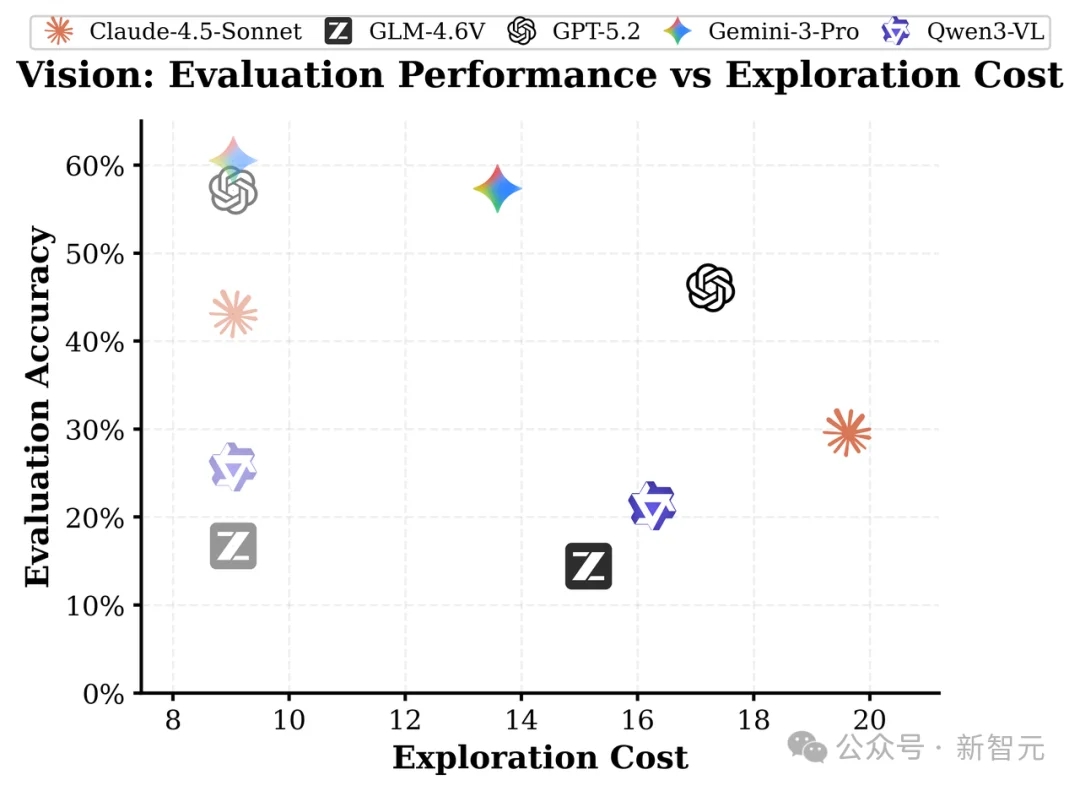
任务准确率 vs. 主动探索开销,灰色图标代表被动模式。智能体在主动探索模式下的探索效率以及任务准确率都低于被动模式
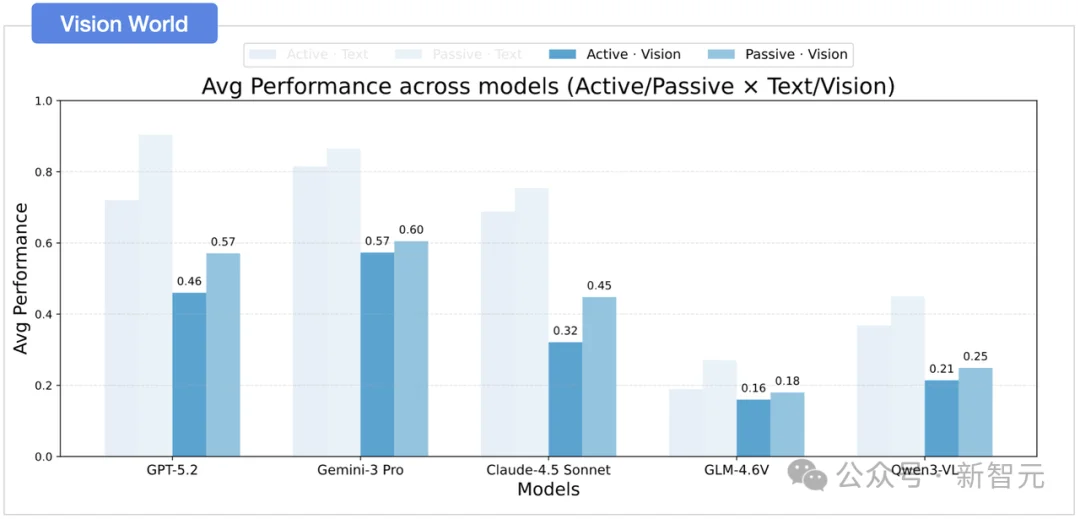
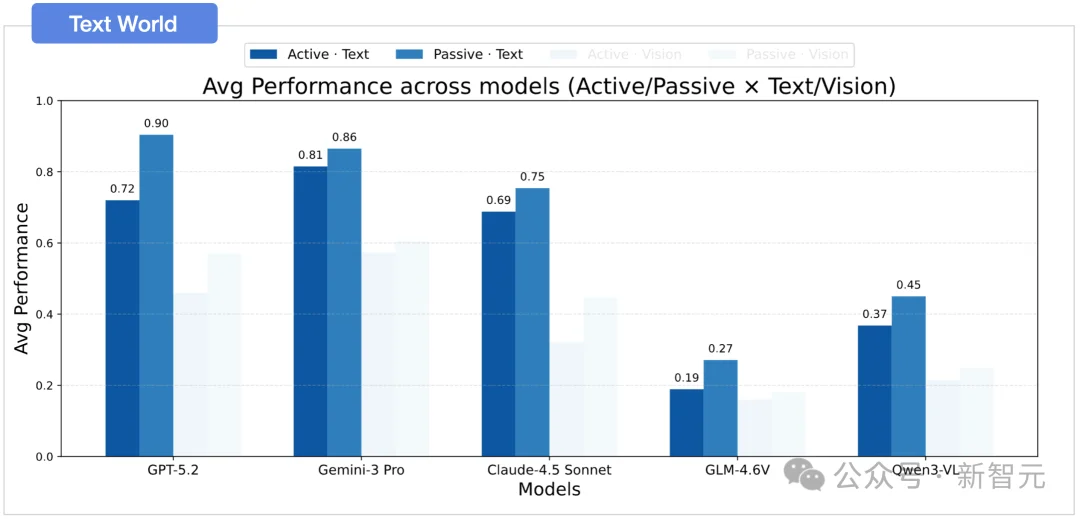
文本与视觉模态下,主动探索与被动探索都存在鸿沟
发现二:模态鸿沟
文本推理远强于视觉推理,所有模型无一例外。
无论在被动还是主动设定下,模型在文本环境中的表现均一致且显著地优于视觉环境。这揭示了当前多模态模型在空间感知方面存在的根本局限:模型难以有效地从视觉观察中提取空间信息,而高度依赖于符号化表征来进行关键关系的逻辑推理。
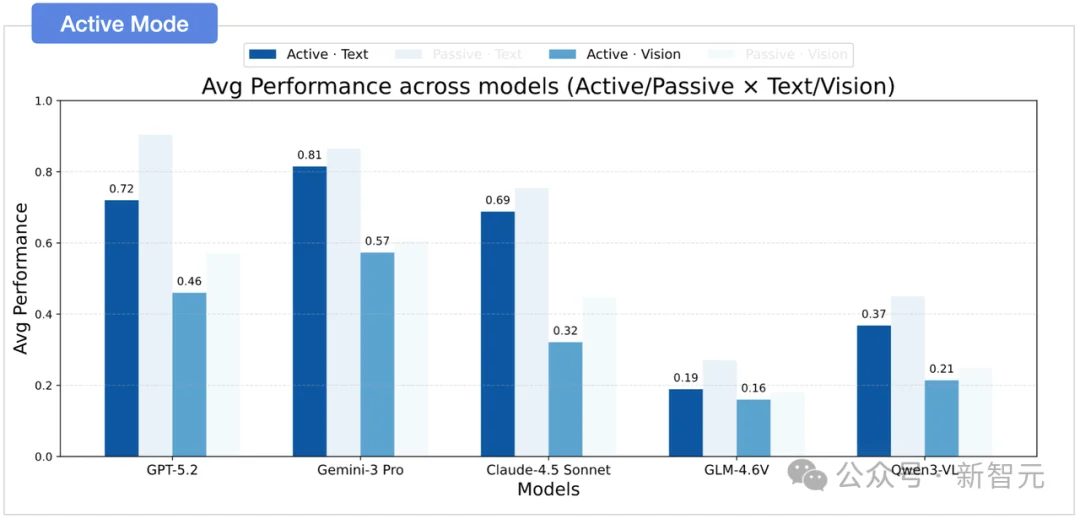
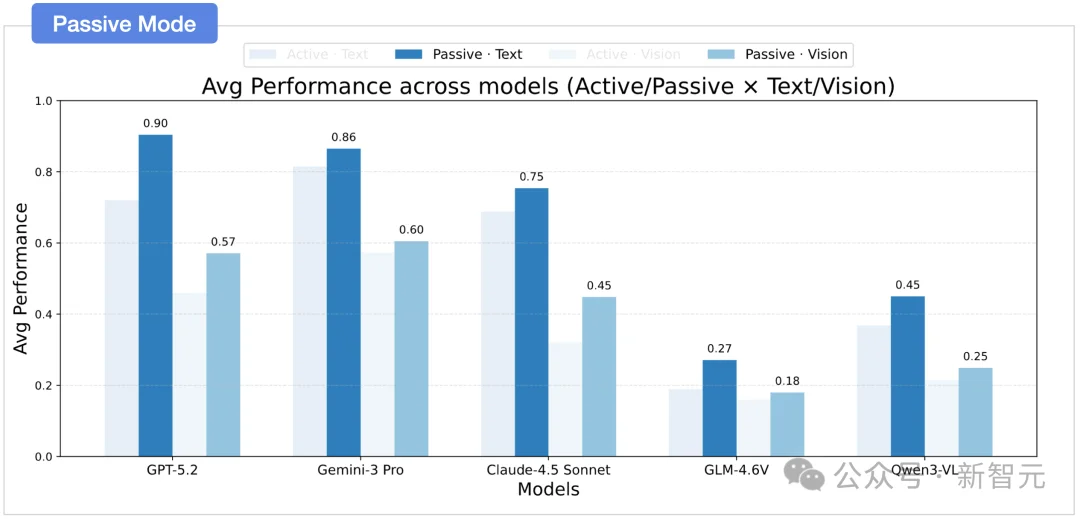
被动模式与主动探索下,视觉与文本都存在巨大性能落差
发现三:认知地图的三重危机
通过认知地图探测,研究人员进一步发现:朝向感知是瓶颈(视觉世界中物体朝向判断接近随机);信念不稳定(正确感知的信息随时间退化);信念漂移(新的错误更新覆盖先前正确的感知)。换句话说,模型不是「看不见」,而是「记不住」「记错了」。
发现四:认知地图是有效的诊断工具
研究人员通过消融实验验证了认知地图作为诊断工具的有效性:
虽然外化的地图是模型内部信念的有损压缩,但它仍是强有力的诊断信号。
发现五:信念惯性(Belief Inertia)
即使亲眼看到了变化,模型仍然「固执己见」。
当环境变化后,模型即便直接观察到新布局,仍倾向于旧的空间坐标。视觉模型的方向惯性高达 68.9%(GPT-5.2),而文本模型仅为 5.5%。当前基础模型缺乏足够的认知可塑性来修正其空间记忆。
人类 vs. AI
人类在视觉世界中达到96.4%准确率(使用工具后99.0%),而最佳AI(Gemini-3 Pro)仅57.3%
有趣的是,人类在视觉世界反而优于文本世界,因为视觉信息对人类更易处理,这与AI表现恰好相反。简言之,人类具有直观理解视觉空间的天然优势,而当前的 AI 架构则更倾向于依赖文本符号来进行逻辑推演。
Theory of Space将空间评估从「模型能否回答对?」重新定义为一个更根本的问题:模型能否通过高效的信息获取,构建并维护一个连贯的、可修正的空间世界模型?
论文的发现指向三个关键方向:
这些挑战不仅关乎学术评测,更直接影响着具身智能的实际落地。无论是家庭机器人、自动驾驶还是搜救机器人,主动空间理解都是不可或缺的基础能力。
该研究由Northwestern University, Stanford University, University of Washington, Cornell University联合完成。项目现已开源,可访问主页获取完整论文、测试套件代码与数据集。
参考资料:
https://arxiv.org/abs/2602.07055
文章来自于“新智元”,作者 “LRST”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
