
机器人需要一个「思考系统」:τ0-VLA让具身智能迈向长程任务时代
机器人需要一个「思考系统」:τ0-VLA让具身智能迈向长程任务时代2026 WAIC 刚刚落幕,具身智能无疑是最受关注的技术方向之一。
来自主题: AI技术研报
5344 点击 2026-07-27 16:09
 搜索
搜索
2026 WAIC 刚刚落幕,具身智能无疑是最受关注的技术方向之一。

机甲觉醒获悉,7月21日,上海仿生机器人企业首形科技宣布于近日完成数亿元A2轮融资。据首形科技官方消息,这轮融到的资金将花在这主要的三个大方向上,首先,进一步完善仿生机器人产品矩阵,其次要建设一条标准化量产产线,最后持续升级仿生具身智能算法,为公司后续商业化规模落地打下坚实的基础。

数据从哪来?控制靠像素还是动作?

近日,上海新智具身智能科技有限公司(NeoteAI)联合复旦大学可信具身智能研究院,正式发布了 N0 系列三份技术报告,把触觉从 “辅助模态” 跃升为 “核心基建”。 三份报告合起来看,恰好拼出一张蓝图 —— 一套触觉数据底座,搭配两条不同侧重的技术路线。

“包括Physical Intelligence在内,如今的北美头部具身智能公司离成熟都还有不短的距离。整个领域,也还没出现真正的奠基性工作。”“中国真正领先的,恰恰是机器人硬件。美国同样没有成熟答案,中国公司又何必急着把自己称为‘中国版XX’?”
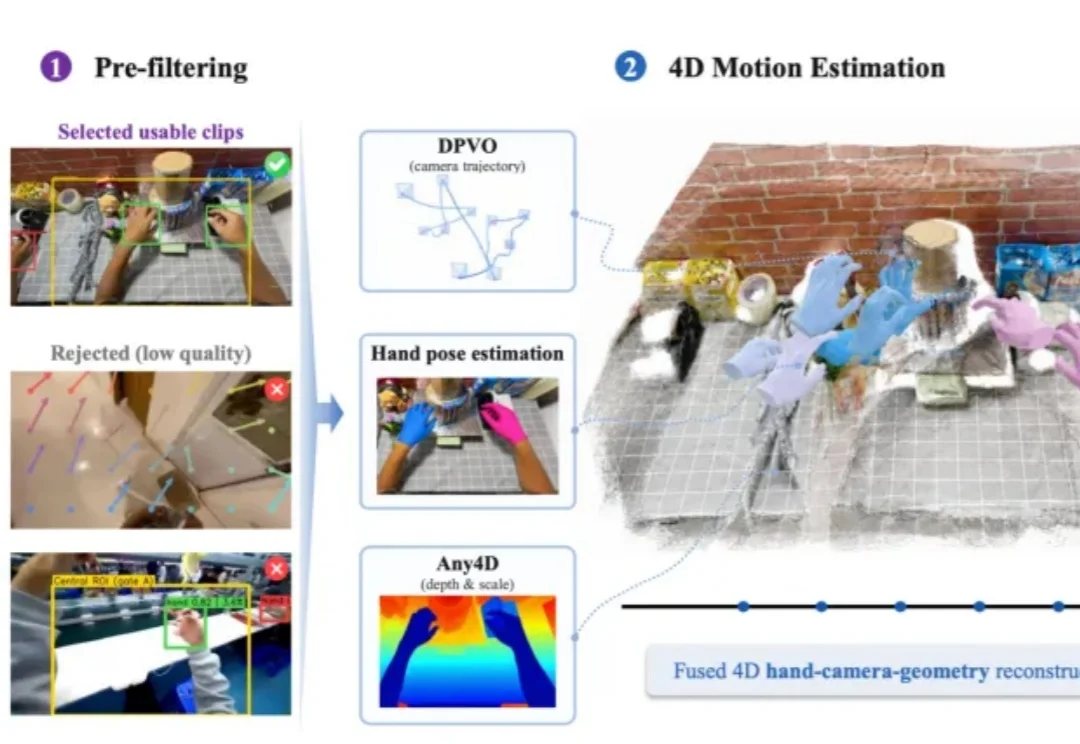
记得何同学做过一个超复杂的流水线项目吗?
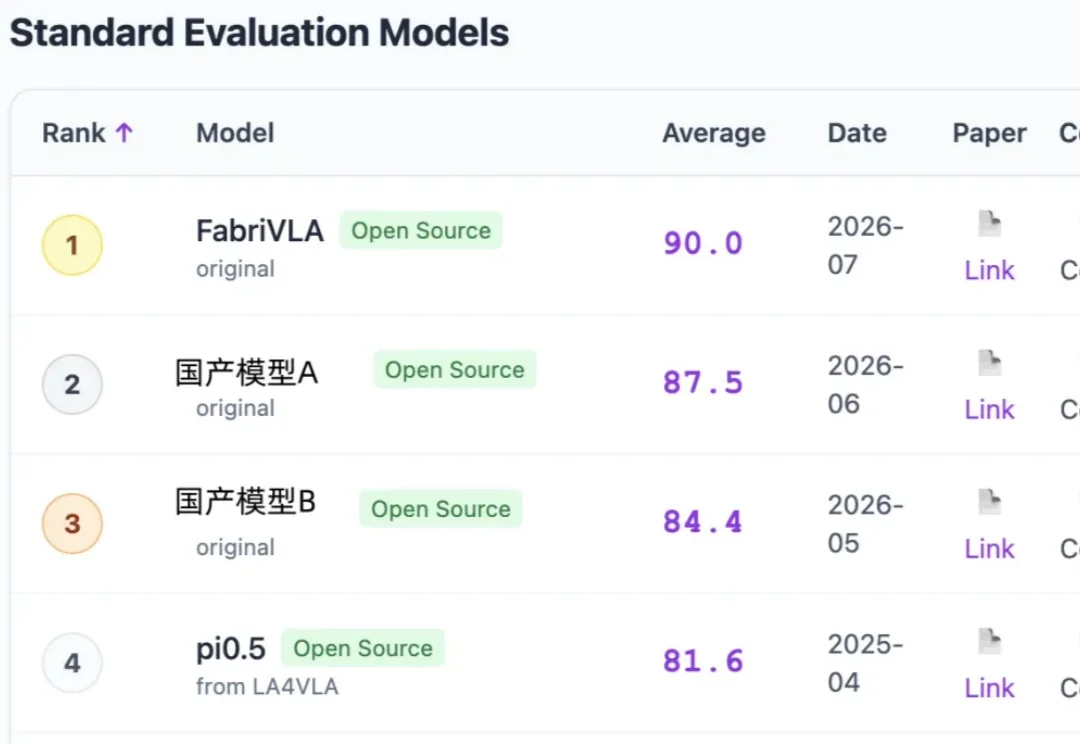
谁能想到,在全球具身智能操作能力的顶级榜单上,打败海外标杆模型π0的,居然是一个只有1B级参数的轻量级模型。

逛过WAIC具身智能展区的人,多半有同一个疑问: 都2026年了,机器人干活,怎么还是慢吞吞的?

在近日的具身智能顶会 RSS(Robotics: Science and Systems)2026 上,最高奖项 Outstanding Paper Award 提名名单里,出现了一个不太 “机器人” 的名字 —— 影眸科技,一家头部 3D 生成大模型公司。

2026 年,世界模型已成为人工智能领域最受关注的方向之一。从空间智能到表征预测,从可交互环境到具身智能,越来越多研究与产业团队将下一阶段目标指向「理解世界」。行业竞争的焦点,也已从「是否进入世界模型」,转向「以何种技术路径实现世界模型」。