# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
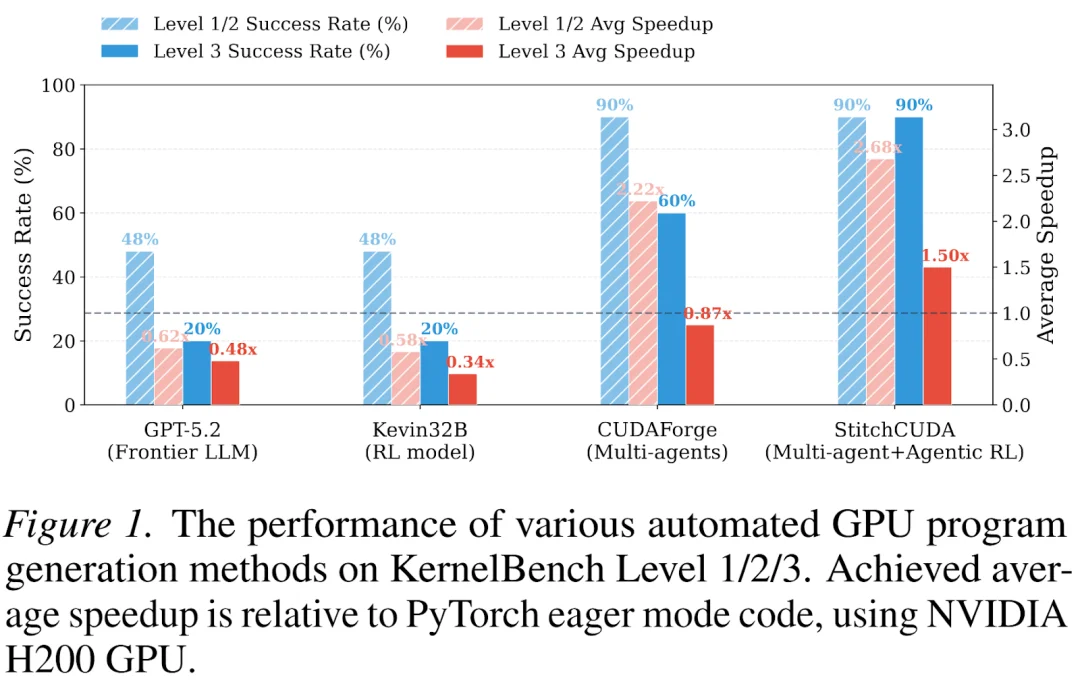
本文中,StitchCUDA 提出了一个根本性的问题转向:从优化单个 Kernel,到生成完整的端到端 GPU 程序。通过多智能体协作框架与基于 Rubric Reward 的 Agentic RL,StitchCUDA 在 KernelBench Level 3 端到端任务上实现了 90% 的成功率和 1.50× 的平均加速比,分别比多智能体基线高出 1.72× 和 RL 模型基线高出 2.73×。

CUDA 代码的性能对当今模型训练与推理至关重要。近年来,基于 LLM 的 CUDA 代码生成取得了不少进展:多智能体框架(如 CUDAForge、QiMeng)和基于 RL 的方法(如 Kevin-32B、CUDA-L1/L2)在 KernelBench Level 1/2 的单 Kernel 任务上均表现出色。
然而,真正的挑战在于端到端 GPU 程序的生成。KernelBench Level 3 的任务涉及完整的模型架构(如 MiniGPTBlock 推理代码),影响性能的因素不仅仅包括单个 kernel runtime,还由算子融合、Launch 配置、CPU-GPU 同步、数据搬运等系统级因素共同决定。如下图所示,现有方法在 KernelBench Level 3 上的表现远不理想:
研究团队总结了使用 LLM 进行端到端 CUDA 生成与优化的三大核心挑战:
(C1)端到端程序需要全局协调。不同于单 Kernel 优化,端到端 GPU 程序的性能由 Kernel 融合边界、跨 Kernel 内存布局、CPU-GPU 同步等系统级决策主导,无法通过逐一处理单个 Kernel 来解决。
(C2)Coder 的 CUDA 编程能力需要在 Prompt 工程以外进一步提升。多智能体框架可以从其他 Agent 获取反馈来引导 Coder,但如果没有参数更新,Coder 往往无法可靠地执行复杂的 CUDA 变换(例如根据性能分析提示推导出正确的 Tiling 策略),成为实际中的主要瓶颈。
(C3)现有的 RL 方法存在诸多挑战。现有的 RLVR 方法容易出现 Reward Hacking(如直接抄写 PyTorch 代码或硬编码输出)和退化行为(只替换简单的 ReLU 而不碰关键的 Conv/GEMM);同时,Coder 也没有被训练去理解结构化的执行反馈并实施有针对性的优化,进而使得训练的模型不适配多智能体框架。
为了解决上述挑战,StitchCUDA 提出了一套多智能体框架 + 基于 Rubric Reward 的 Agentic RL 方案,核心包含两大模块:
多智能体协作框架
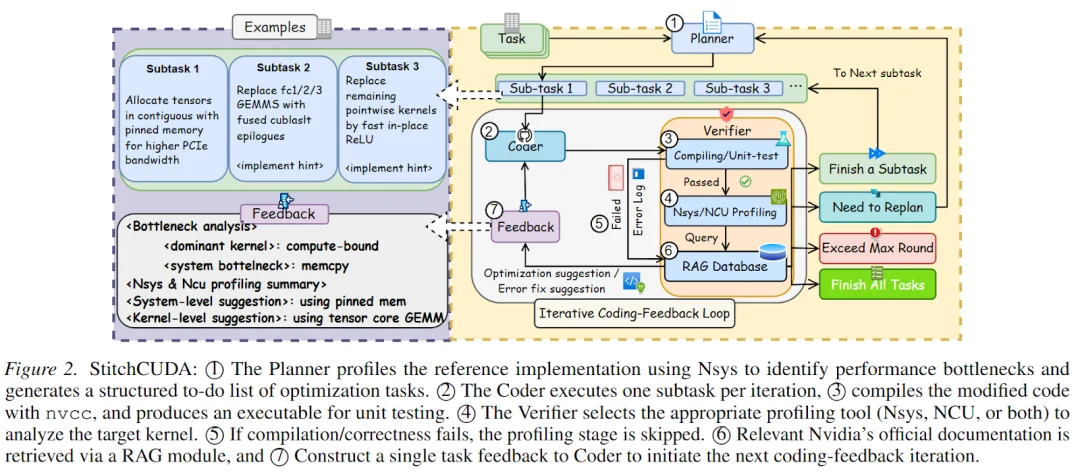
StitchCUDA 将端到端 GPU 编程任务分解为三个专门的 Agent,通过迭代式「计划 — 编码 — 分析 — 优化」循环协作完成:
Planner(规划器):解析 PyTorch 参考代码,使用 Nsys Profiling 进行性能分析,识别耗时最长的 Kernel 和系统瓶颈。然后在系统层面将任务分解为多个子任务,同时考虑 Kernel 效率和 Host 端编排 —— 例如:子任务 1「使用 Pinned Memory 分配连续张量」,子任务 2「用 cuBLASLt 融合 Epilogue 替换 FC 层 GEMM」,子任务 3「用定制的 fast in-place ReLU kernel 替换 pointwise Kernel」。
Coder(编码器):按照 Planner 的规划,逐个子任务生成 CUDA 实现(源代码、构建文件、Pybind 接口),并调用 nvcc 编译。在收到 Verifier 的反馈后,对当前子任务进行迭代优化。
Verifier(验证器):负责正确性验证和性能分析。编译失败时,分析错误日志并返回具体修复指导。测试通过时,从两个层面分析程序:Nsys 用于识别最耗时的 GPU Kernel 和系统级瓶颈(如 CPU-GPU 数据传输、Kernel Launch、同步开销),NCU 用于分析具体的瓶颈 Kernel(判断是 Memory-bound 还是 Compute-bound),最终生成可执行的优化建议。
此外,Planner 和 Verifier 还集成了 RAG 模块,从 NVIDIA 官方文档(CUDA-12.9、cuBLAS、CUTLASS、Nsys/NCU 指南、Hopper/Blackwell 架构白皮书)中检索最新的 API 规范和用法指南,避免 LLM 因预训练知识过时而产生幻觉。
基于 Rubric Reward 的 Agentic RL
为了提升 Coder 的端到端 GPU 编程能力,StitchCUDA 引入了一种创新的 Agentic RL 训练方案:
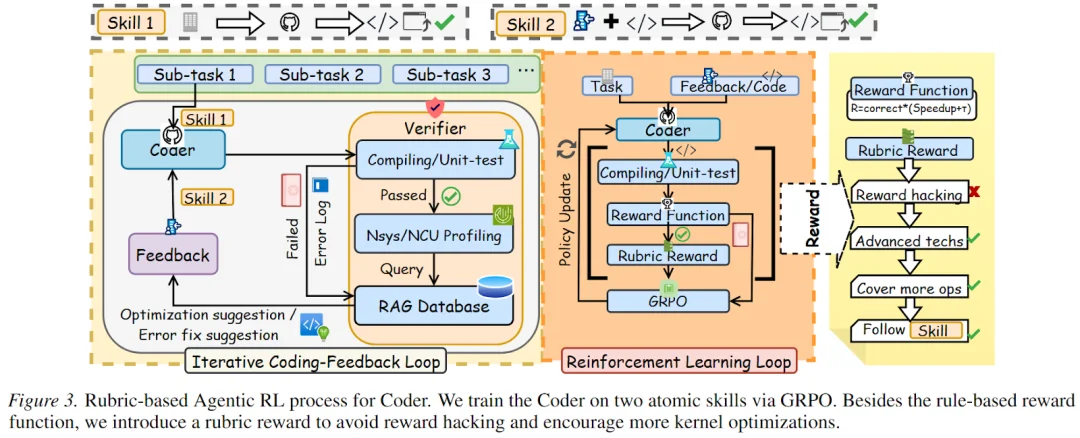
将多轮交互分解为原子技能
标准的多轮 Agentic RL 需要收集完整的交互轨迹(15 轮迭代 × 每轮 4-5 分钟环境交互),单条轨迹就需要 60-75 分钟,整体训练预估需要约 8 卡 H200 训练 1200-1500 小时。StitchCUDA 将其分解为两个原子技能的单轮 RL 训练:
通过在工作流执行过程中收集单轮训练数据(每个 Skill 各 200 个样本),然后合并用 GRPO 联合优化, 训练一个基于 Qwen-32B 的 Coder 仅需约 160 H200-Hour,相比多轮 Agentic RL 减少了约 60-75 倍。
Rubric Reward:解决 Reward Hacking 和退化行为
现有 RL 方法的核心问题在于奖励设计:简单的「正确性 + 加速比」奖励容易被 LLM 利用,比如说,直接复制 PyTorch 代码就能获得高奖励,而激进优化若产生微小错误则奖励为零,这推动模型走向保守、退化的行为。此外,模型也会通过直接复制 pytorch 代码的形式来 hacking 评测程序,从而获得高 reward。
StitchCUDA 引入了由 CUDA 专家设计的 Rubric Reward(评分准则奖励),从四个维度对生成代码进行综合评估:
最终奖励公式将 Rubric Reward 与规则奖励(正确性 × 加速比)相结合,同时通过 Reward Clipping(R_max=5)防止极端奖励对训练的干扰,增强训练的稳定性。
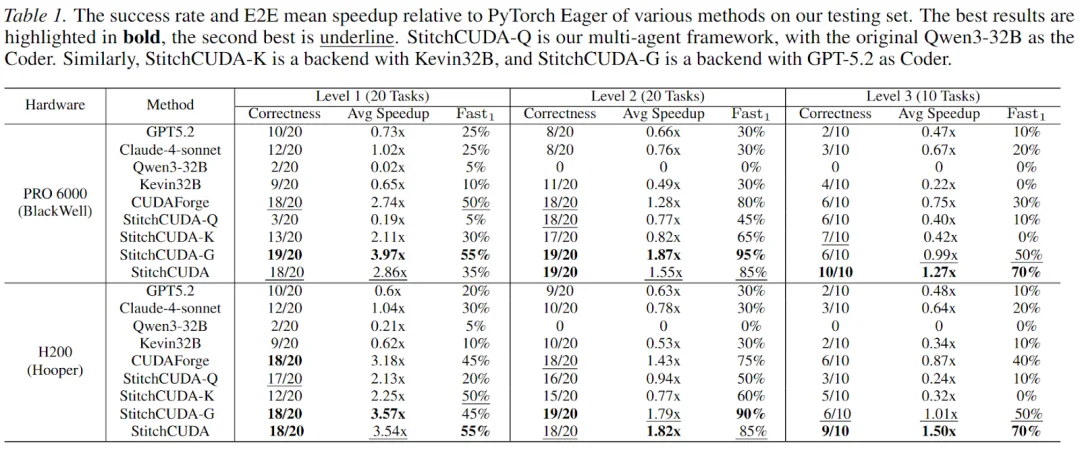
实验在 KernelBench Level 1/2/3 上进行,测试硬件覆盖两代 NVIDIA 架构:H200(Hopper)和 RTX PRO 6000(Blackwell),以验证方法的跨架构泛化能力。对比方法包括前沿 LLM(GPT-5.2、Claude-4-sonnet)、开源基座(Qwen3-32B)、RL 方法(Kevin-32B)和多智能体框架(CUDAForge),以及 StitchCUDA 的多个变体。
下表展示了所有方法在两个硬件平台上的完整结果(正确率 / 平均加速比 / Fast1):
关键发现
多智能体框架大幅提升端到端正确性。以 Qwen3-32B 为例,单次生成在 Level 3 上失败(0/10),而 StitchCUDA 多智能体框架(不含 RL)将其提升到 3/10。即使是更强的 GPT-5.2,多智能体框架也带来显著提升。
Agentic RL 是实现系统级加速的关键。对比 StitchCUDA 和无 RL 变体(StitchCUDA-Q),RL 在 Level 3 上将正确率从 3/10 提升至 9/10,加速比从 0.24× 提升至 1.50×,Fast1 从 10% 提升至 70%。
Agentic RL 超越更强模型的效果。即使与使用 GPT-5.2 作为所有 Agent 的 StitchCUDA-G 相比,使用 Qwen-32B 作为 Coder 的 StitchCUDA 在 Level 3 上仍然全面领先。 这说明 RL 训练带来的能力提升是模型规模难以替代的。
超越 torch.compile。在 H200 上,StitchCUDA 对比启用 torch.compile 的参考代码仍然实现了 1.29× 的加速,表明其手动的系统级优化(自定义 Kernel 融合、数据搬运优化)能够超越编译器的自动优化。
Hacking 检测
Reward Hacking 是 CUDA RL 训练中的重要挑战之一。模型会因此学会 hack 测评程序而不是进行 CUDA 优化,我们对 50 个测试任务进行了系统性的 hacking 检测,结果如下:
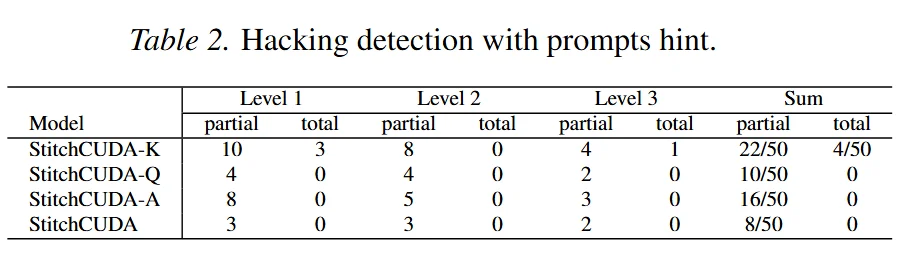
格式检查(Format Check)为什么不够?一种直觉的解决方案是用规则检测 reward hacking, 比如检查生成代码中是否包含 torch.nn.functional 调用。但我们发现这存在一个 trade-off:
Rubric Reward 如何解决 Reward Hacking 的问题?StitchCUDA 的 Rubric Reward 不依赖硬编码的格式规则,而是使用推理模型按照专家设计的评分准则从语义层面评估代码质量。Anti-Hacking 维度会判断「生成代码是否真正实现了 CUDA 优化,还是本质上仍在调用 PyTorch」,这种语义级评估天然地避免了格式检查的 false positive/negative 困境。
结果是显著的:StitchCUDA 将 Hacking 率从 Kevin-32B 的 52% 降至 16%, Hacking 从 4 次降至 0 次。而去除 Rubric 的 StitchCUDA-A 变体,Hacking 率回升至 32%,进一步验证了 Rubric Reward 的因果效应。
消融实验
去除 Rubric Reward 后(StitchCUDA-A),Level 3 成功率从 90% 降至 50%,加速比从 1.50× 降至 0.46×,进一步确认了 Rubric Reward 对有效 RL 训练的关键作用。失败原因包括:退化的保守实现、反馈遵循能力下降、以及无 Rubric 惩罚导致的 Reward Hacking。
以 Level 3 Task 44(GPT-2 Transformer Block)为例,StitchCUDA 实现了 3.75× 加速比。
Planner 在系统层面提出了混合精度计算(LayerNorm / 残差用 fp32,MLP 用 fp16)和连续数据布局优化。在 Kernel 层面,Coder 实现了 cuBLASLt Epilogue 融合(将GEMM+Bias 和 GEMM+Bias+GELU 融合为单次 Launch)、描述符 / 算法缓存(避免重复的 Heuristic 查询)、以及按 Stream 持久化 Workspace(减少 cudaMalloc/cudaFree 开销)。
这些系统级 + Kernel 级协同优化是单 Kernel 优化方法无法实现的。
StitchCUDA 提出了首个面向端到端 GPU 程序生成的完整解决方案,通过:
在 KernelBench 上,StitchCUDA 在端到端任务上实现了近 100% 的成功率和 1.5× 的平均加速比,显著超越所有现有方法,为 LLM 驱动的自动化 GPU 编程开辟了新的方向。
文章来自于“机器之心”,作者 “李世阳(共同第一作者),张子健(共同第一作者),Winson Chen,罗越波,洪明毅,丁才文”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
