# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多数大模型能生成 “看起来像” 研究的文本,但极少数能真正做研究 —— 提出假设、收集证据、执行可复现的推导、迭代验证直至结论成立。
此前发布了 BabyVision 评测基准(已被多个近期发布的重磅模型纳入评测体系)的 UniPat AI 在最新的 Blog《UniScientist: Advancing Universal Scientific Research Intelligence》中给出了一个清晰而系统的答案。
UniPat AI 开源的 UniScientist 训练了一个 30B 参数的模型来闭合这一环路。在 FrontierScience-Research 和 ResearchRubrics 等科学研究榜单上,它匹敌甚至超越了参数量大一个数量级的顶尖闭源模型。
今天很多模型做 “研究任务”,只是看起来像在做科研:引用一堆资料、写一堆逻辑、格式也像论文。
但问题是:它们经常停在 “叙事推理”、从 “结论” 出发的逻辑陷阱中 —— 说得很像、验证很少、推导不稳、可复现性弱。
UniPat AI 在 UniScientist 中直接回应了这一缺口:
仅有 30B 参数的 UniScientist 具备了 “自主科学研究” 的能力 —— 在开放问题里不断提出、证伪、修正,直到证据状态稳定,再把全过程沉淀成结构化成果。
这背后的潜台词很直白:
真正的科研,不只是把报告写漂亮;更是把 “假设 - 证据 - 验证” 的循环跑通。
UniScientist 首先把矛头指向了数据:如何构建高质量科研训练数据一直是硬瓶颈。现有方案几乎只有两种极端:
UniScientist 的关键洞察源于一个被广泛忽视的不对称性。
这种不对称性指向了一种更高效的分工方式:模型负责规模与多样性,人类专家负责质量与可验证性。 这正是 UniScientist 数据引擎的核心原则 —— 产出的训练实例既有广泛的专业覆盖面,又有严格的验证保障。
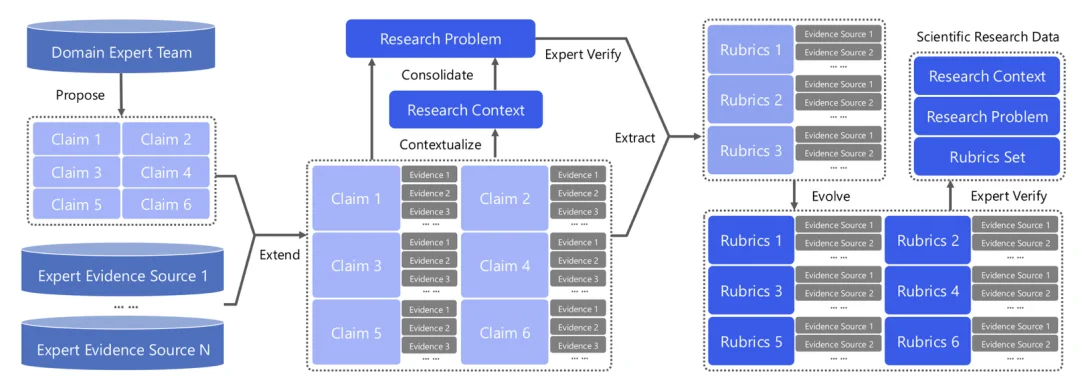
许多关于 “科研智能” 的讨论聚焦在更好的工具调用或更精准的检索上。UniScientist 则在更本质的层面展开工作。团队将开放式科研过程建模为一个基于两个基本操作的动态系统:主动证据整合(Active Evidence Integration) 与 模型溯因(Model Abduction)。
系统的核心是一个不断演化的 “证据状态”,其中证据被分为两类。
然后系统循环执行三个动作:
1. 产生假说
2. 获取外部权威信息证据、计算和推导证据
3. 做溯因更新:让假说更好解释当前证据状态
直到证据足够完整稳定,再把整个研究过程转化成一份严谨的科学成果。
这一形式化具有重要意义:它把 “科研智能” 从一个远大理想,变成了可训练、可评估、可迭代的对象。
UniScientist 提出了 Evolving Polymathic Synthesis(进化式多学科合成),一个承担两项功能的数据引擎。
1. 从经过专家验证的科学 Claim 出发,将其扩展为研究级问题 —— 跨越多个相互依赖的子问题,要求实验设计与推导协同
2. 同步合成评测 Rubrics。这些 Rubrics 不评估文风或格式等表面质量,而是评估具体的科学发现是否已被达成
这一设计中最具辨识度的特征是:
一份开放式科研成果被分解为 N 个封闭的、可独立验证的 Rubric 检查项。
每个 Rubric item 都尽量做到:原子化、客观、可证据落地或可形式化推导,并额外强调:
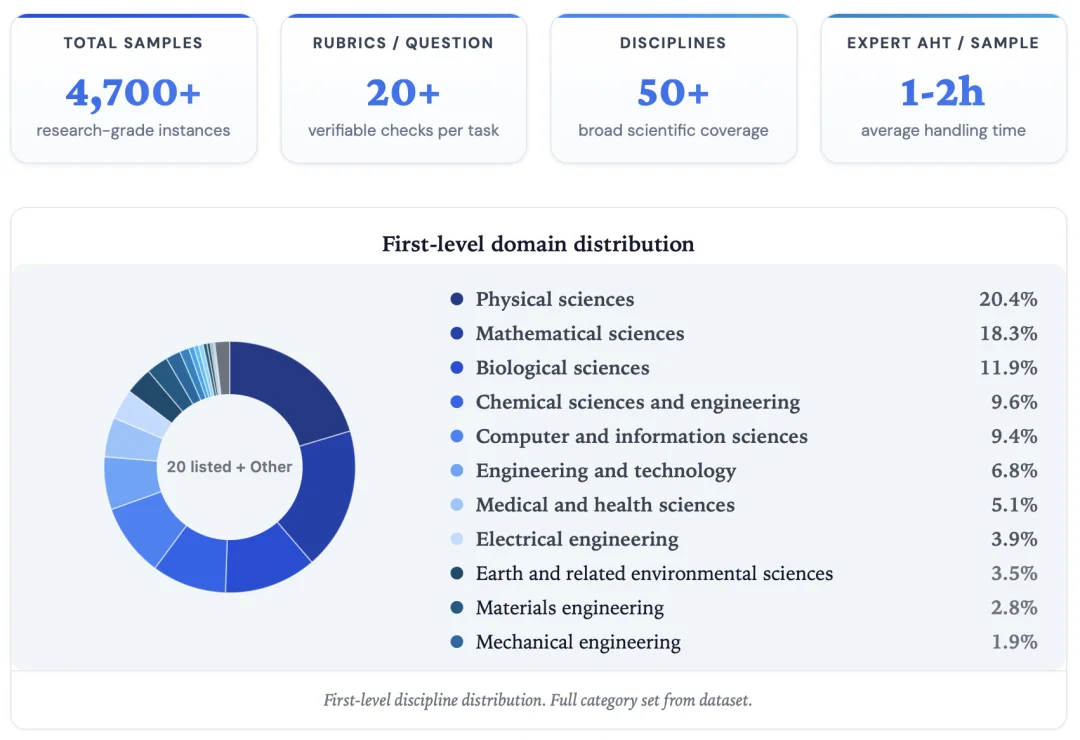
当前数据集仍在持续扩展中,已包含超过 4,700 个研究级实例,每个实例附有 20+ 条 Rubric 项,覆盖 50+ 学科和 400+ 研究方向。专家标注平均每条样本投入 1-2 小时。学科覆盖从量子物理和有机化学到社会文化人类学和计算语言学均有涉及。
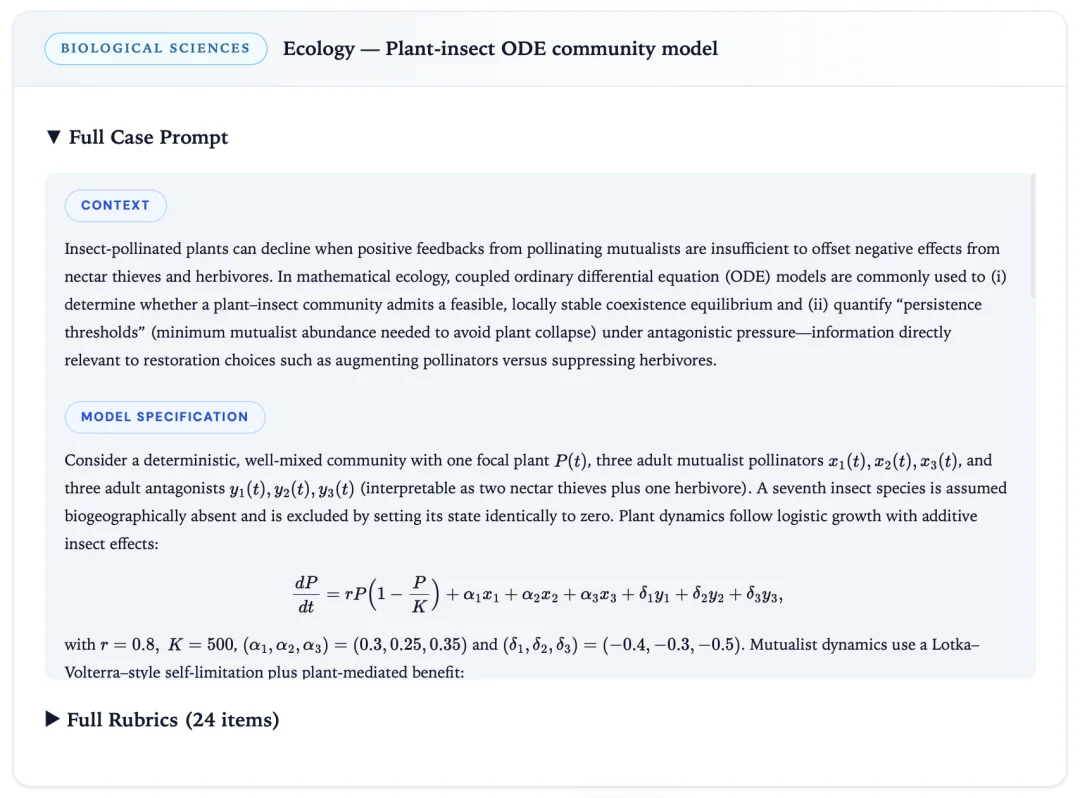
数据集中包含了具备真实科研质感的研究问题。下图展示的是一道生态学方向的示例,完整案例库可在 https://unipat.ai/blog/UniScientist 查阅。
这些问题的共同特征在于:没有任何一道可以通过匹配记忆中的既有答案来直接解决。每一道都要求完整的科研链条 —— 文献调研、假设形成、实验或推导设计、分析验证、以及最终成果的收敛。
UniScientist 引入了一个额外的训练目标,成果聚合目标:
给定同一问题的 N 份候选科研成果,模型学会融合各家优点,产出一份更完整、更稳健的最终成果。通过 Rubric 阈值的 rejection sampling 来筛选高质量参考答案,聚合能力与科研生成能力一同被训入模型。
这反映了科学研究中的一个现实:对于一个问题,一次尝试并不一定会带来最好的成果。这实际上是将 “集体科研智能” 写进了训练过程:
模型不仅学会了产出研究,还学会了比较、取舍、整合与自我进化。
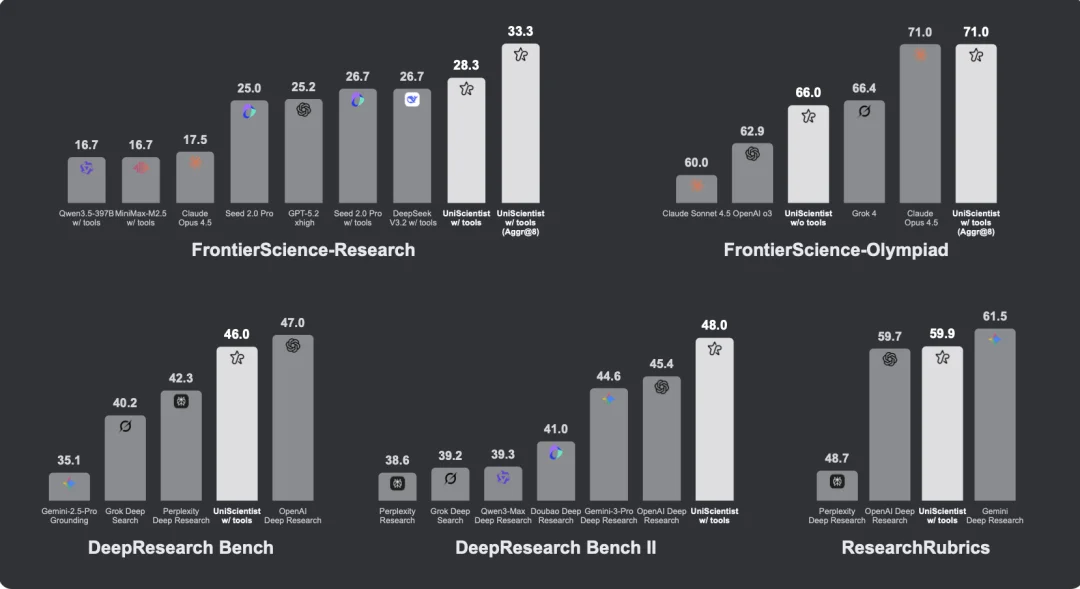
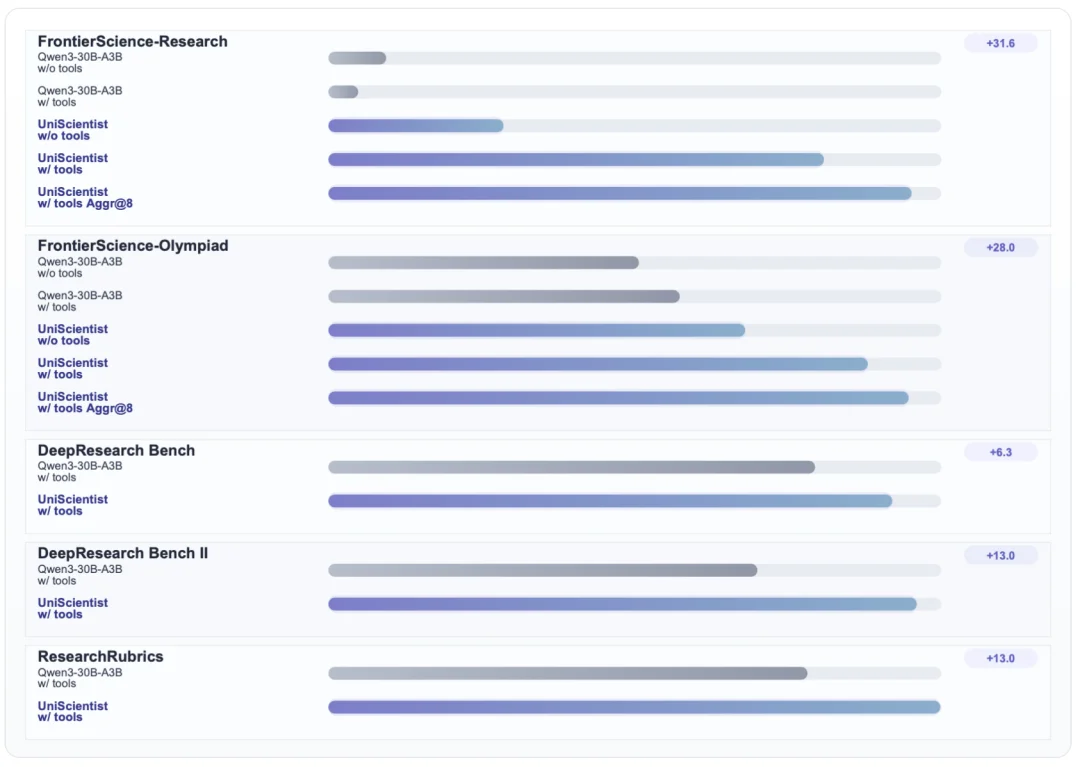
评测结果引人注目,尤其考虑到模型的规模。
UniScientist-30B-A3B —— 一个仅有 3B 激活参数的小模型 —— 在 FrontierScience-Research 上达到 28.3 分,超越 Claude Opus 4.5(17.5)、Gemini 3 Pro(12.4)和 GPT-5.2 xhigh completion mode(25.2)以及工具调用模式下的 DeepSeek V3.2(26.7)和 Seed 2.0 Pro(26.7)。在成果聚合模式下,得分达到 33.3。
在 FrontierScience-Olympiad 上,启用工具的 UniScientist 得分 71.0,匹配 Claude Opus 4.5,超越多个其他前沿模型。在多项分布外的基准 ——DeepResearch Bench、DeepResearch Bench II 和 ResearchRubrics 上 —— 模型的表现与一系列顶级闭源系统相当。
一个尤为重要的发现:即使在无工具的评测条件下,性能仍有显著提升。
这表明增益并非单纯来自更频繁的工具使用,模型自身的研究推理能力确实通过训练得到了增强。
所有基准上的结果指向同一结论:模型学会的不只是更好地检索,而是将检索、推导、验证和写作整合为连贯的研究工作流。
科学研究不止于形成一个合理的叙事。许多结论依赖于可执行、可复现的计算与仿真。
UniScientist 集成了代码解释器,将研究流程从叙事式推理升级为 “测试 - 修正” 的循环:假设不仅被提出,还被实例化为计算实验 —— 其结果可以确认、推翻或细化假设。
系统目前的能力主要集中在可复现推理与仿真计算范围内。对真实世界研究资源的编排 —— 可靠地调度大规模 GPU 任务、协调湿实验流程 —— 尚未实现。
UniScientist 在 Blog 中也将下一步方向阐述得很清晰:
将框架扩展到对真实实验与计算基础设施的受控编排与执行,目标是进一步加速科学发现、推动研究前沿。
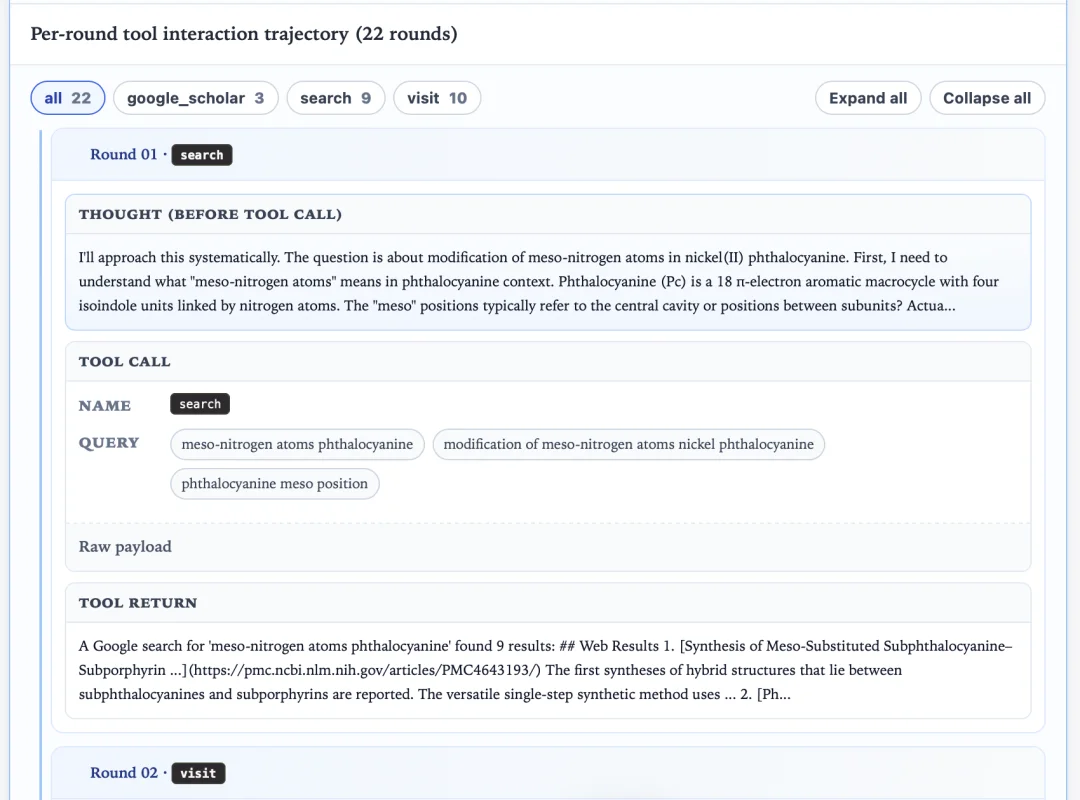
以下展示一个 UniScientist 进行的完整科研推理链条,详细推理内容可以在 Blog 链接中查阅:https://unipat.ai/blog/UniScientist
关于 UniPat AI
UniPat AI 此前发布过多模态评测基准 BabyVision,该基准已被部分近期模型纳入评测体系,并在一些技术报告中被引用。这次发布的 UniScientist,则把关注点转向解决科研任务,提出将全链条科研能力内化到模型的方案,让模型具备了自主推进科学研究的能力。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
