# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
先看视频:
上面就是我最近日常的打字方式,在家、在公司、在咖啡厅都可以。
整个过程,我用的是这个「键盘」:

嗯没错,这是一个无线麦克风,可以拿手里,也可以夹在衣服领口上。
显然,它比这个键盘简单多了:

因为,它就完全只有一个按钮。

但就是这一个按钮,我用它实现了:几百甚至上千字的精准文字输入。
而使用上,则是:按一下开始说话,再按一下结束,文字自动上屏,再按一下自动发送。
全程不碰电脑,不碰键盘。
下面来说说过程,或许你也应该有一个。
如果你很 AI Native,非常拥抱 AI,那你可能会发现,你最累的已经不再是脑子,还有打字的手指。
我现在每天最大量的工作,就是跟 Claude Code、Codex 对话:描述需求、给上下文、提修改意见。
几乎所有的事 AI 都能做,但前提是我得把想法快速传达给它。
所以,对绝大多数人而言,打字的速度已经成为你信息输入输出的上限、工作效率的瓶颈、是否能卷过他人的关键。
而我也有幸,在大学时,因为年轻气盛和人较劲打赌,最后真的在一周内学会了五笔打字。
可以说,用键盘打字这事,我的速度应该会超过 90% 的普通人。
当然,相较于专业的速记员,自然完全没法比……我曾经现场观摩过几次。
但即便如此,对我而言,打字仍然是我很大的效率和信息 IO 瓶颈。
所以我很早就开始尝试语音输入,比如这里就有写:Codex 和 Claude Code,用哪个?

随着语音识别准确性的提升和成本的大幅降低,打字这件事变成为了:
你在用键盘做一件嘴巴更擅长的事。

我最早用的是 Wispr Flow,一款基于 OpenAI Whisper 模型的语音输入工具。
在我之前的文章中偶尔也有提到,很多朋友通过我的邀请码注册了,甚至因此它帮我赚了不少会员,一直用不完。
但怎么讲,它的识别效果始终还是不够稳定,经常需要手动二次编辑,非安静环境下尤其明显。
以及,在开放式办公室里使用起来,还会有点儿尴尬。
你要是大声说话,那你最核心的 idea 可能会被隔壁工位的同事或过客们「偷听」。
毕竟在 AI 时代,idea 的价值比以往任何时候都重要。
大嗓门的同志们要注意,或许哪天当你跟 AI 说完「帮我写一个能自动 XXX 」的 idea,然后整层楼的 Claude Code 们都开始工作了。
而大声说话这事确实也会打扰到别人。
毕竟不是每个人都想在写 Bug 的时候听你跟 AI 谈人生。
那怎么用更小的声音,依然拿到不错的识别效果呢?
对比下来,确实还是 Typeless 在低音量场景下表现明显最好(没有 PR)。
Typeless 并不只是简单的语音转文字,它的技术架构分两层:
语音识别层,将你的语音转为原始文本。
LLM 智能编辑层,用大语言模型理解你的意图,自动去除口头禅,如「嗯」「那个」「就是说」等,修正口误,整理格式。
所以即使你说得含糊、断断续续,它也能「听懂」你想表达什么。
比如你说:
帮我写一个……嗯……那个函数,就是把用户的……啊不对,是把订单的状态改成已完成的那个
Typeless 会输出:
帮我写一个函数,将订单的状态改为已完成
干净准确、直接可用。
Typeless 还支持超过 100 种语言的自动识别,中英文混合输入也完全没问题。
这对我来说太重要了,毕竟我们说话经常是「帮我把这个 Claude Code 的 xx skill 改一下,加一个 deploy callback」这种中英夹杂的风格。
相比苹果的语音输入,真的是强了无数倍。
Typeless Pro 版 $12/月,并不算便宜。
有些东西,失去时才会珍惜它,但有些东西,没用过就不知道自己需要它。
这样的东西不多,Typeless 算一个,类似的还有苹果电脑,还有我最近买的全自动咖啡机,用过之后就再也回不去了。
Typeless 链接(没错,我有的邀请码):https://www.typeless.com/?via=john-yin

软件选好了,但还有一个物理层面的问题:Mac 自带的麦克风收音效果还是有限,每次语音输入时,我必须弯下高贵的头颅,凑到 Mac 的 Mic 的位置,然后,开始说话。
而我有个小毛病是,当我在边思考边说话的时候,我希望要能离任何东西,包括电脑,都略远一点儿。
我理解为我这是需要通过物理空间给自己腾出一些想象的空间,跟唱高音似的,姿势正确也很重要。
所以,我入手了 大疆 DJI Mic Mini。

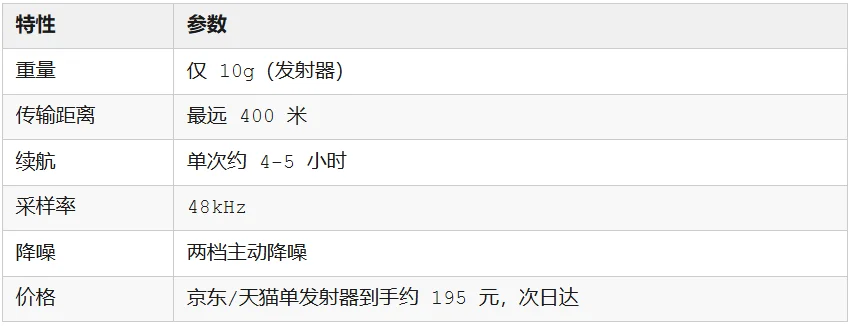
10 克的重量,拿在手里,或夹在领口上基本感受不到它的重量。
而夸张到 400 米的传输距离,甚至能让我在周末的整栋办公楼里自由活动,边走边说了。
同时,它的两档降噪在办公室场景下,确实表现非常出色,即使周围有人说话,也能精准拾取你的低声耳语。
下单后次日到手,不到 200 块。
而在换了 DJI 麦克之后,语音识别的准确率直接上了一个台阶。
之前用 Mac 内置麦克风,经常会识别出奇奇怪怪的东西,比如你明明在说中文,它突然给你蹦出一个莫名其妙的英文单词。
不知道这算不算是 bug,不然就太有点离谱了。
而当我用上 DJI Mic Mini 时,这个问题,就完全消失了。
硬件升级带来的识别提升,比换软件还是要明显多太多了。
实际使用下来,发射器的续航大概 4-5 小时,半天基本就没电了。
这时候一拖二套装(两个发射器 + 一个接收器)的好处就体现出来了,一个没电换另一个,无缝衔接。
我目前就用一个发射器,偶尔充充电,倒也够用,因为也可以边充电边用,一会儿就充好了。
如果你只是想简单地用起来,5 分钟就能搞定。
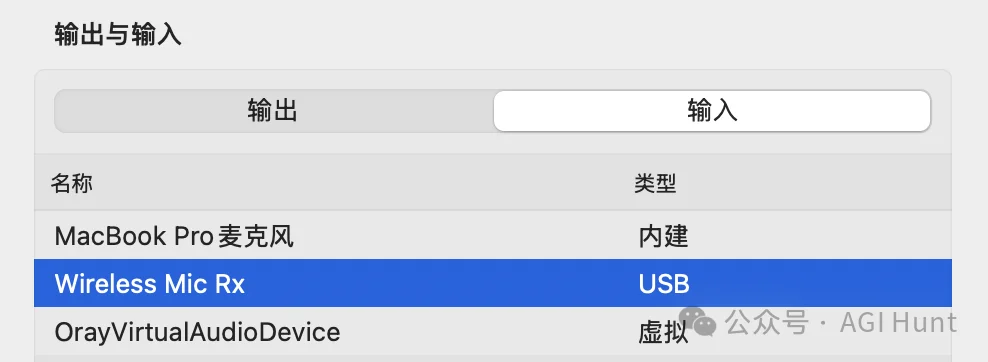
用 USB-C 线把 DJI Mic Mini 的接收器连接到 Mac,打开 System Settings → Sound → Input,选择 「Wireless Mic Rx」 作为输入设备。
把发射器开机(长按电源键),它会自动跟接收器配对。
打开 System Settings → Keyboard → Dictation,将 Dictation 设置为 On,快捷键保持默认的 Press 🌐 Fn Key。

在任意文本输入框中,按下 Fn 键,开始说话。再按一次 Fn,结束听写。
macOS 原生听写配合 Typeless 使用时,Typeless 会自动接管听写功能,提供更智能的识别和编辑效果。
到这里,你已经可以在大部分场景下愉快地使用语音输入了。
注意:如果你看到了这里,本文还没完……重点才刚开始,请继续往下看:
到目前为止,每次输入我都得按键盘上的 Fn 键,人还是得老老实实坐在电脑前。
尤其如果想离电脑远一点,那就得伸长手臂去够 Mac 左下角的 Fn 键,姿势还是略有点小别扭。
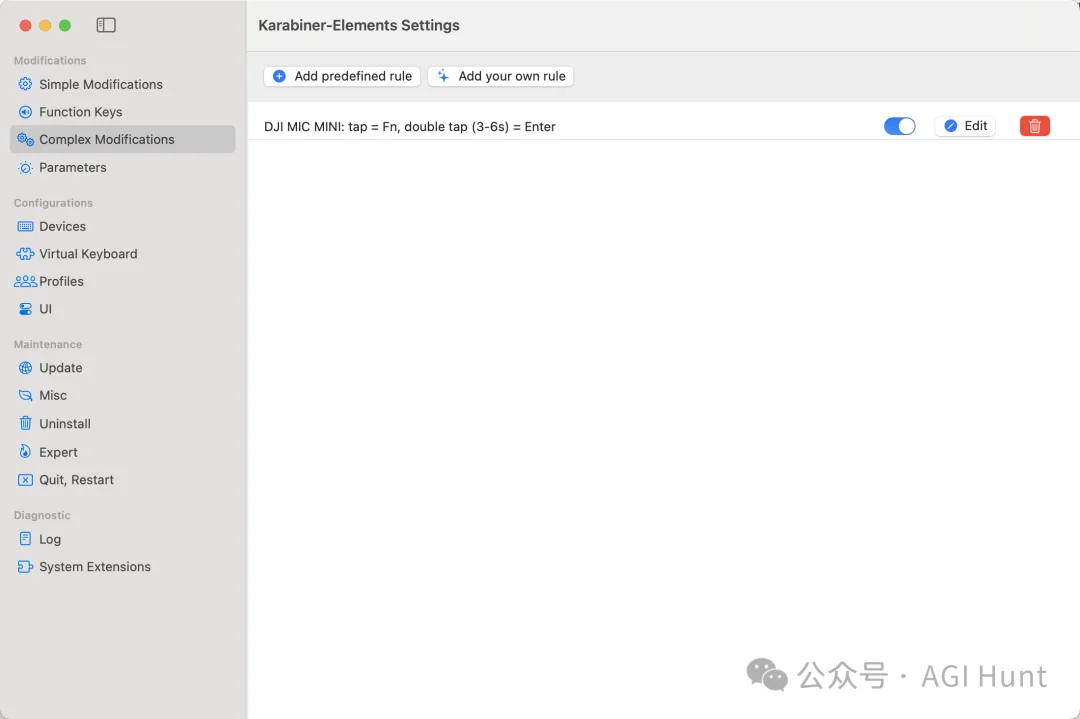
所以我的想法是:把 DJI Mic Mini 发射器上的音量+按钮,改造成听写开关。
这样只需要按一下胸口的小按钮,就能随时随地开始和结束听写。
可以离电脑远远的。
这需要用到 Karabiner-Elements,一个 macOS 上强大的键盘映射工具。
brew install --cask karabiner-elements
安装完成后,打开 Karabiner-Elements,按照提示授予以下权限:
⚠️ 如果不授予 Input Monitoring 权限,Karabiner 将无法识别任何外部设备,规则也不会生效。
这是容易踩的第一个坑。
Karabiner 的核心规则是:只拦截 DJI Mic Mini 的音量+按键,映射为 Fn 键,不影响其他设备。
通过 device_if 条件限定设备(vendor_id: 11427,product_id: 16401),通过 consumer_key_code: volume_increment 匹配音量+。
最简单的版本就是一条规则:收到音量+ → 发送 Fn。
但还不够,要实现后面的「自动发送」功能,需要更复杂的状态管理。
完整的 3 条规则配置我会在下面的「自动发送」章节给出,这里先理解基本原理。
DJI Mic Mini 在系统中被识别为 Consumer 设备(耳机类),而不是键盘。
Karabiner 默认只抓取键盘和鼠标设备,所以即使规则写得完全正确,按按钮也只会触发系统音量。
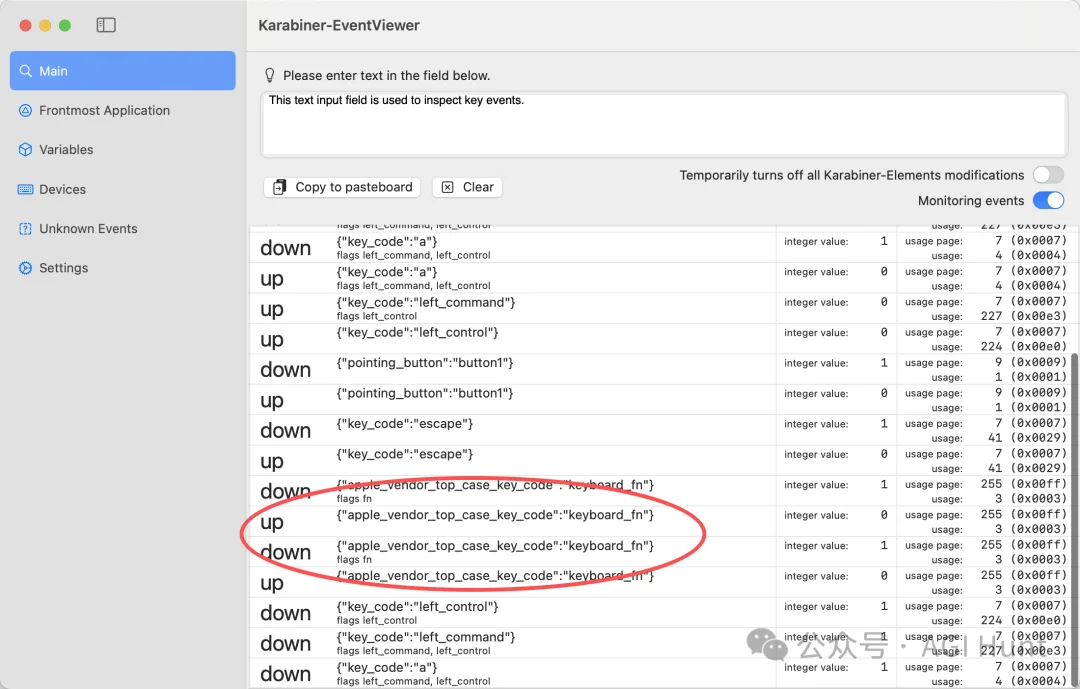
解决方法是在 karabiner.json 的 profile 中,显式声明要抓取这个设备:
"devices": [{
"identifiers": {
"is_consumer": true,
"product_id": 16401,
"vendor_id": 11427
},
"ignore": false
}]
关键是 "ignore": false 和 "is_consumer": true。
告诉 Karabiner:「这个 Consumer 设备,我要拦截它的事件。」
不加这段配置,Karabiner 根本看不见 DJI 的按钮。
添加后,你可以在 Karabiner 的日志中确认设备已被抓取:
Wireless Mic Rx (device_id:xxx) hid queue value monitor is started (grabbed).
如果你用的是其他型号的无线麦克风,可以用以下命令查设备的 vendor_id 和 product_id:
# 查看 USB 设备信息
ioreg -p IOUSB -l | grep -A 20 "你的设备名"
# 或者用 Karabiner 的命令行工具
karabiner_cli --list-connected-devices
配置完成后,按一下 DJI 发射器的音量+,听写就开始了。
再按一次,听写结束。
你可以离开电脑几米远,坐在沙发上对着领口的小麦克风说话,甚至可以走到很远的地方,看着窗外思考,不用碰电脑。
到这里,基本就可以用了。
但懒人如我,自然还想更进一步。
说完话之后,能不能自动帮我按一下回车?
理想的场景是这样的:
在 iTerm2 里用 Claude Code,按下胸口的按钮,对着麦克风说了一段需求,再按一次结束听写。
然后我什么都不用做,指令就自动发送出去了。
我可以端着咖啡,刷着手机,甚至望着窗外发一会儿呆,而我的代码在自动生成。
这就是真正的 Vibe Coding。
哦不对,又换词了,应该叫 Agentic Engineering.
也不对,Agentic Engineering 体现不出这 Vibe 的爽感,或许可以叫:Vibe Engineering?
想法很美好,现实很骨感。
DJI Mic Mini 发射器上只有一个音量+ 按钮可用,且前面我已经把它映射成了 Fn 键,用来开关听写。
现在还想让它同时承担「发送回车」的职责,一个按钮要干两件事,咋办呢……
先来看看这个按钮到底能产生哪些事件:
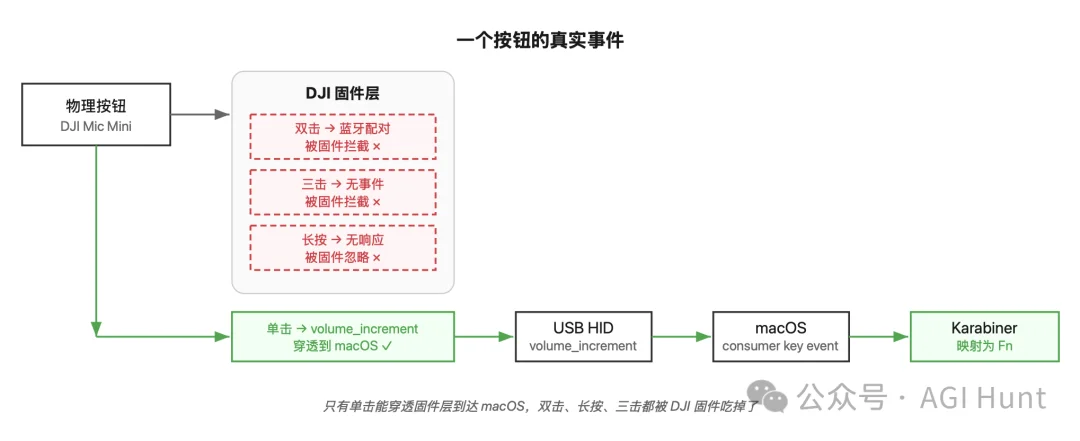
对电脑来说,这个按钮只有一种事件:按下了。
试试双击呢?
结果我试了半天才发现,双击是 DJI 固件自己的事件,会触发蓝牙重新配对,根本不会传到电脑……被官方征用了……
而长按……也没有任何效果。
那……三击?
用 Karabiner EventViewer 一测,更是没有任何动静。
也就是说,只能获取到一个事件:单击。其他没了。
那要不,咱换个设备?
毕竟 DJI 这也就不到 200 块,不算心疼。
但话说回来,它便宜也对应着轻巧(下料少)啊,还是个很重要的优势的。
那……要不刷固件呢?
我让 Claude Code 查了一下,DJI Mic Mini 用的是 Actions ATS2831 芯片,固件签名加密,完全没有可操作空间。
硬件层面的路,也被堵死了。
所以我不得不放弃「从硬件上获取更多事件」这条路。
但 AI 时代,最怕的不是没有方案,而是没有方向。
且不能缺的还有一个:信心。
我从一开始,在内心就笃定我最后能搞定这事。
于是我开始换一个角度想:既然没法从硬件上得到更多真实事件,那……能不能创造事件?
虚拟出我想要的事件出来!
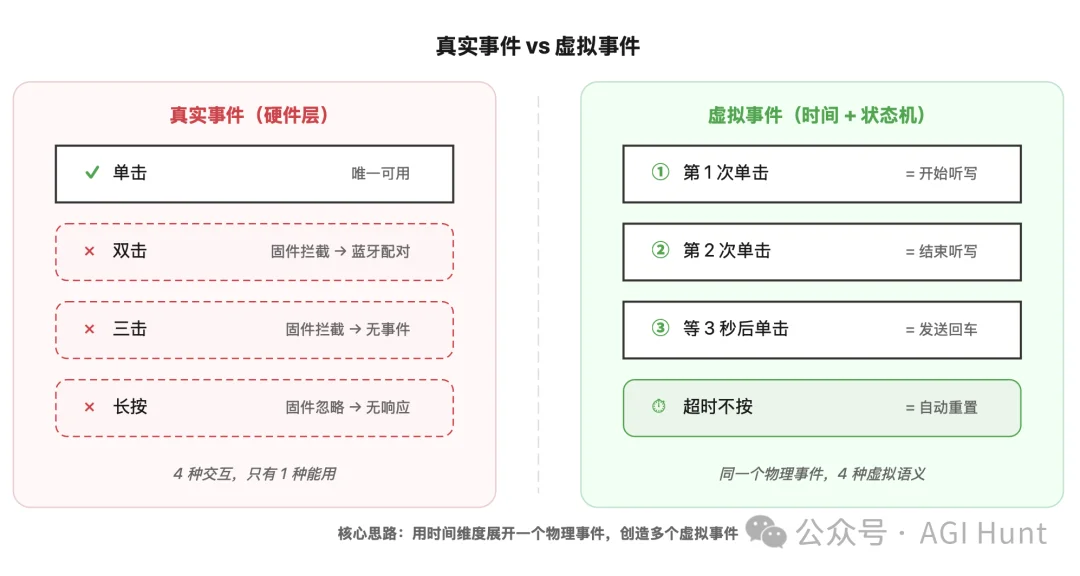
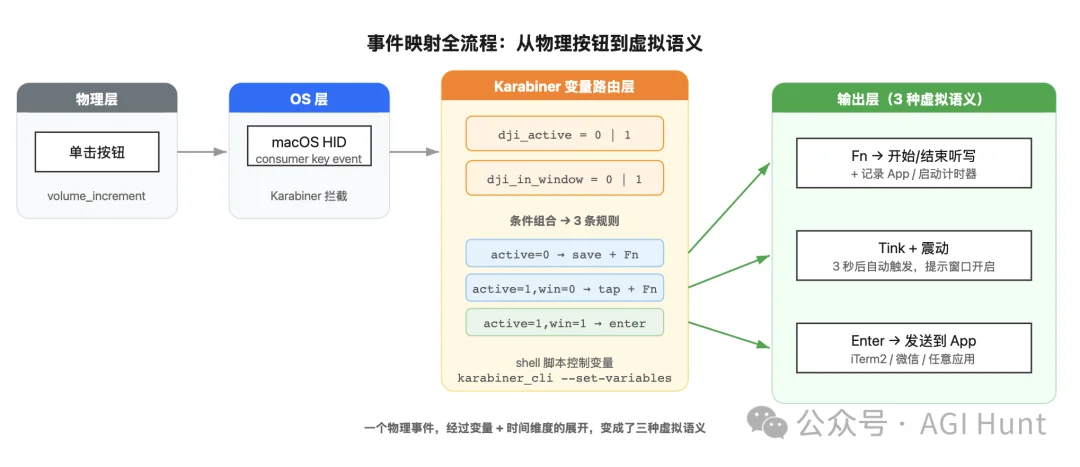
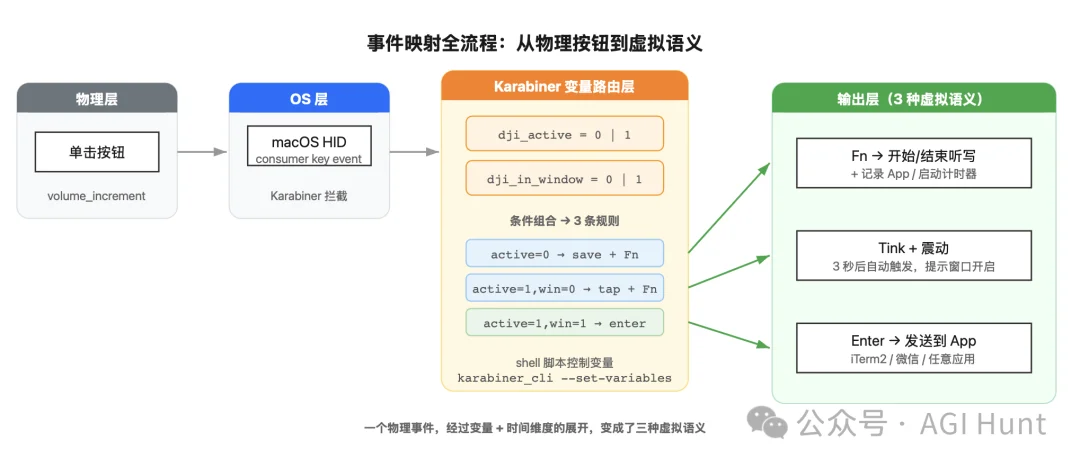
比如通过时间戳,用状态机的方式,把同一个按钮在不同时间点的按下,映射成不同的含义。
也就是说:同一个按钮,第 1 次按是「开始听写」,第 2 次按是「结束听写」,等文字出现后再按第 3 次是「发送」。
而如何区分每一下是第几次,则是这里的关键。
一个物理事件,经过时间维度的展开,变成了三个虚拟事件。
这就是我最终方案的核心思路:
利用时间、无中生有!
我自认为这个想法还是比较严谨可行的,那么剩下的,就是实现它了。
整个过程,我全是跟 Claude Code 对话完成,用了不对就说,哪里不爽它帮我改,改了再试。
当然,也是用 DJI Mic Mini + Typeless 输入的。
👆比如上面的,全是用嘴输入的。
下面是我从第一版到最终版的迭代过程。如果你只想用不想看原理,可以直接跳到后面的「三步上手」。
第一版:15 秒倒计时
其实在这最终版之前,我还是先探索(踩坑)了一些弯路。
最初方案非常直接粗暴:结束听写后,脚本在后台等 15 秒,然后自动发送 Enter。
这个 15 秒,是考虑到要留给语音转录和我的 review 使用的。
所以我还加了个「智能取消」:通过 ioreg 检测键盘空闲时间,如果发现我在手动编辑,就说明我手动介入了,需要取消掉自动发送。
倒是可以 work 了,但问题是:15 秒还是太长了,在这样的场景下,我感觉我对 0.1 秒的等待都是能感知到的,更何况 15 秒……
所以这经常会让我等得心烦,但缩短又怕来不及看识别结果。
更要命的是,有时候我只是想听写一段文字而不想发送,这个定时炸弹般的自动发送让人很不安。
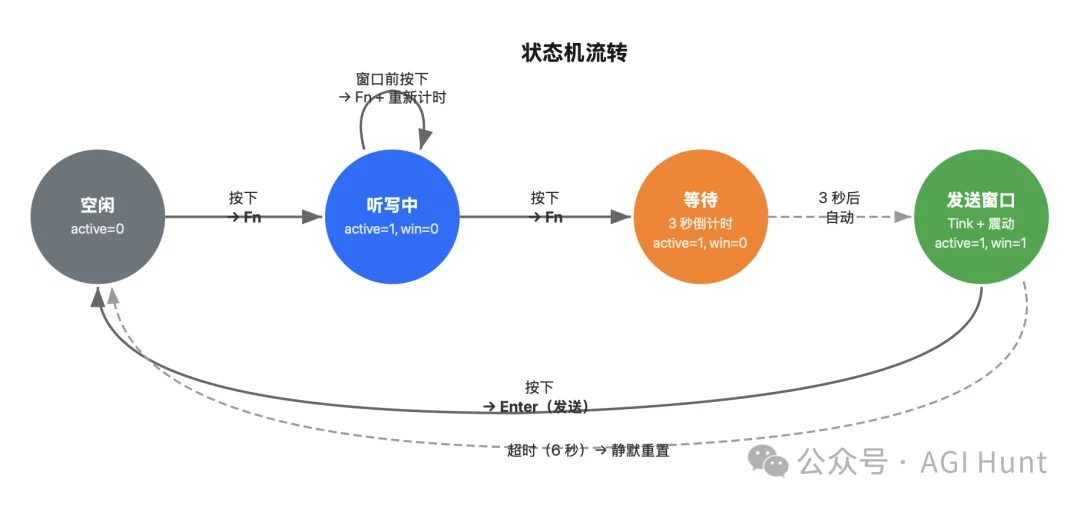
第二版:用状态机区分意图
于是我跟 Claude Code 说了上面的状态机的想法:不用倒计时,用按钮的次序来区分意图。
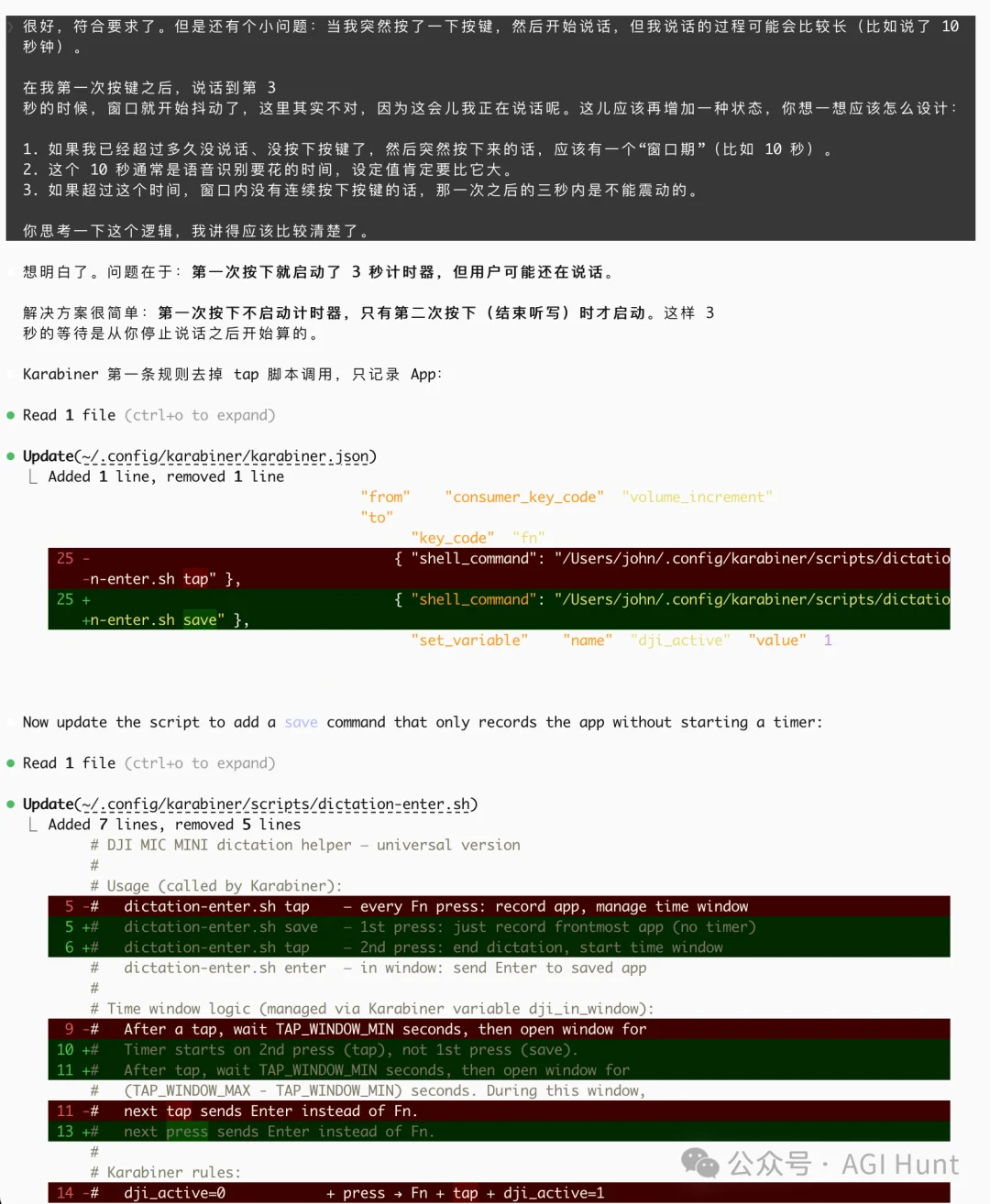
脚本拆成三个命令,save、tap、enter,Karabiner 根据当前状态决定调用哪一个:
第 1 次按 → 开始听写(Fn)
第 2 次按 → 结束听写(Fn)+ 启动计时器
计时器到期 → 打开「发送窗口」
窗口内按 → 发送(Enter)
这样就不会出现「说着话就自动发送」的情况了。
只有我主动按第 3 下,才会发送。
但这一版有个问题:计时器从第 1 次按下就开始了。
如果我说话说了 10 秒钟,说到第 3 秒的时候「发送窗口」就开了,这时候我还在说话呢。
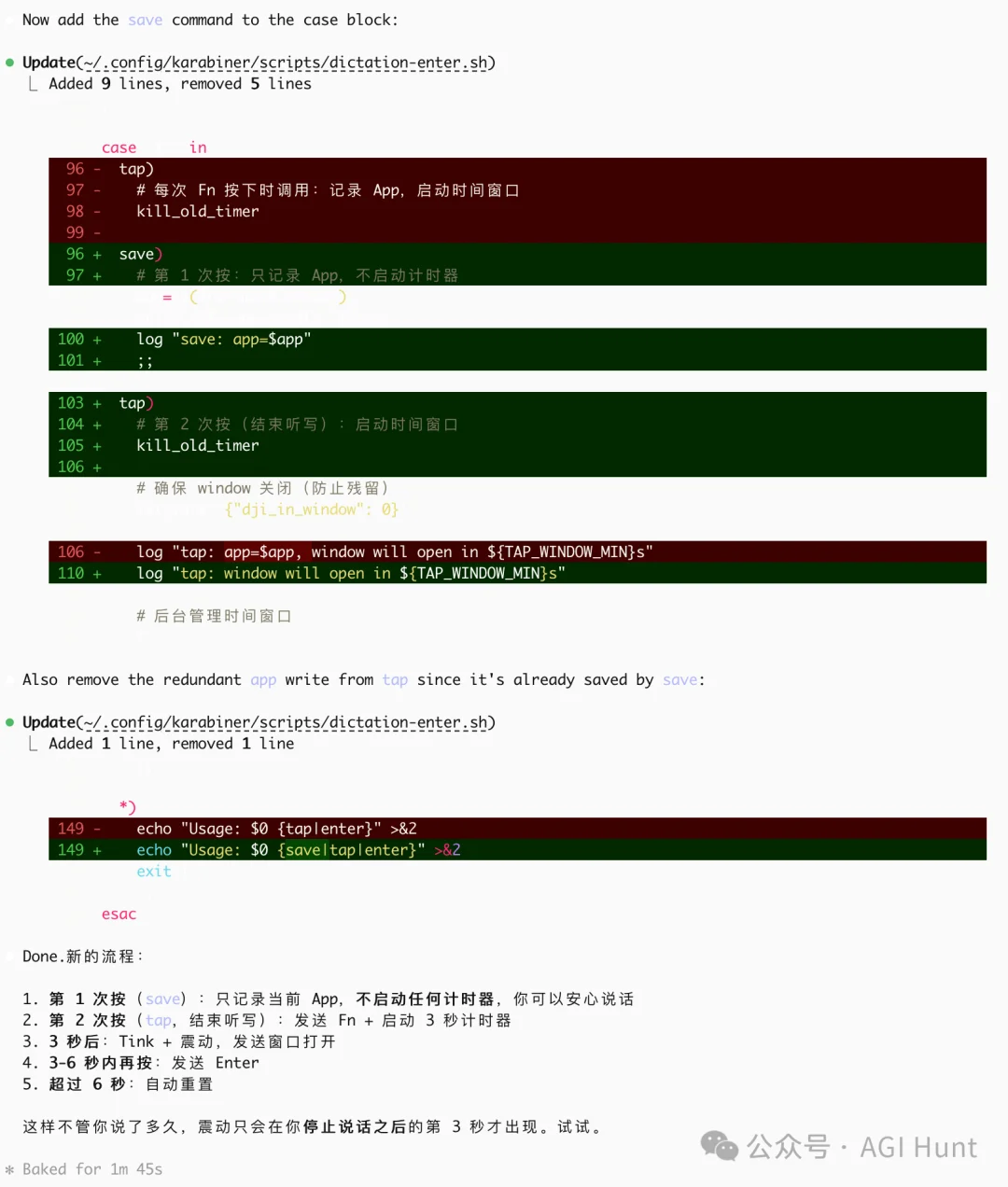
于是我让它把逻辑拆开:第 1 次按只记录当前 App,第 2 次按才启动计时器。
这样不管我说了多久,「发送窗口」只会在你停止说话之后才打开。
第三版:我怎么知道该发了?
时间窗口能用了,但新的问题出现了:「发送窗口」打开的时候,我怎么知道?
如果我人不在电脑前,或者在看手机,完全不知道现在能不能按第 3 下。
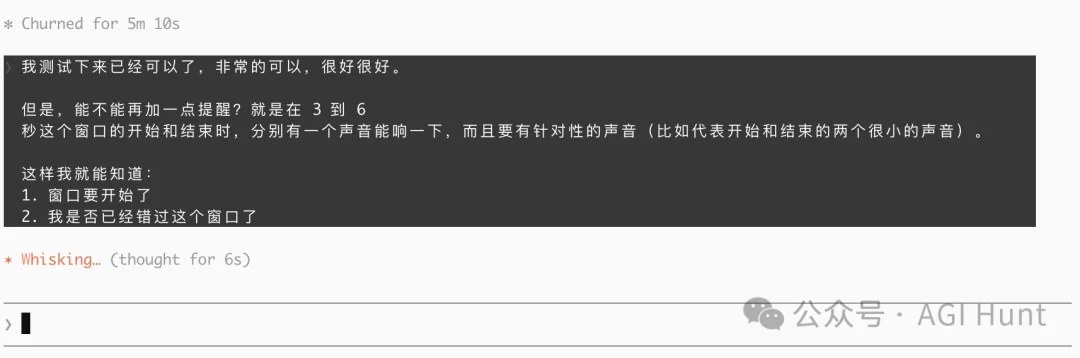
所以,我先让 Claude Code 加了声音提示:窗口打开时播放一声系统音效 Tink。
这样离开电脑也能靠耳朵知道,可以发送了。
但又有个问题是,我不一定开着电脑声音,也不一定戴着耳机。
于是我又想了个很牛逼的交互:能不能让窗口抖一下,提醒我?
就像手机震动一样,但这里通过视觉反馈来提示。
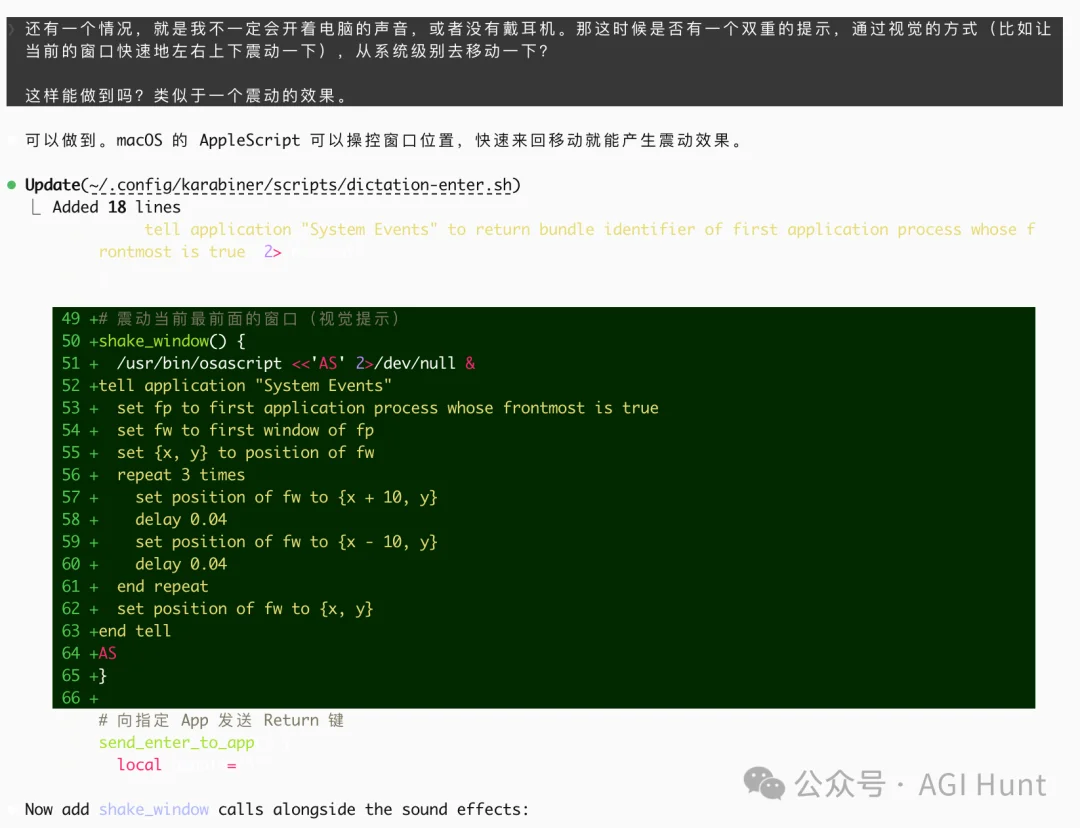
于是,Claude Code 用 AppleScript 实现了。

第一版抖动效果:
repeat 6 times
set position of fw to {x + 10, y}
delay 0.04
set position of fw to {x - 10, y}
delay 0.04
end repeat
set position of fw to {x, y}
能抖起来了……但严格来说,应该叫晃起来了……幅度巨大、频率又慢。
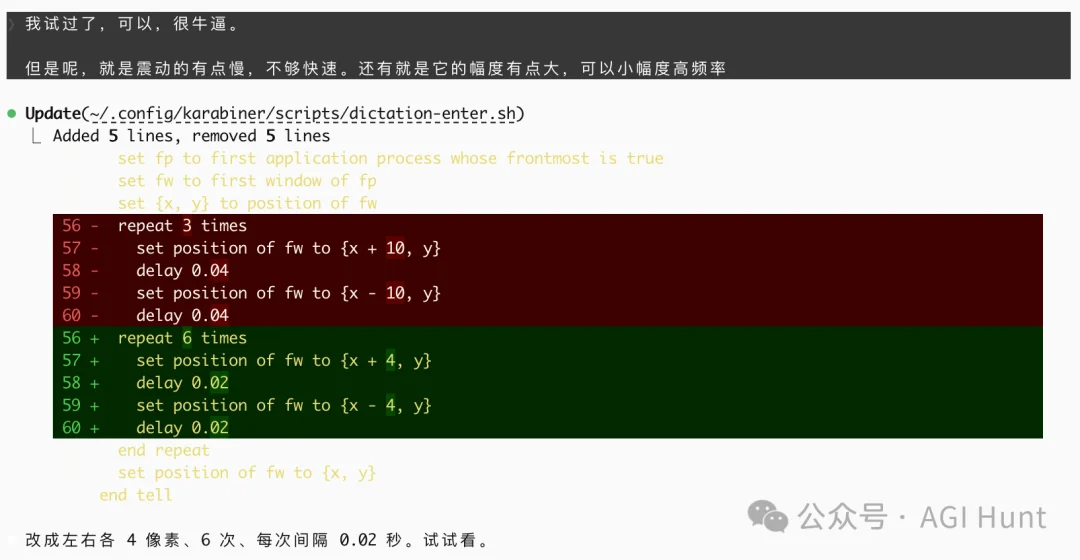
我又给调成了小幅度高频率的移动:
repeat 6 times
set position of fw to {x + 4, y}
delay 0.005
set position of fw to {x - 4, y}
delay 0.005
end repeat
set position of fw to {x, y}
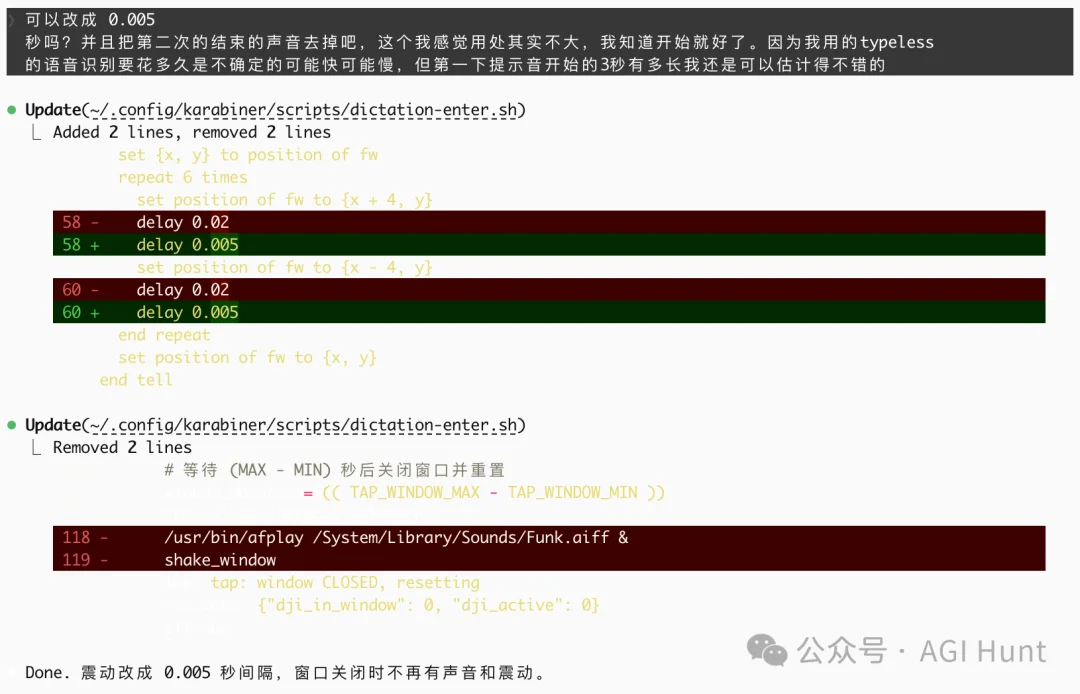
效果像手机微震,轻微但足够引起注意。
我还顺手去掉了窗口关闭时的提示音,3 秒的窗口有多长,自己能估计,关闭提示反而多余。
第四版:越抖越远
用了几轮之后,一切都好,唯独有个奇怪的事是,我的窗口在慢慢漂移。
每次抖完,位置就偏一点点,抖多几次之后窗口已经明显错位了。
抖得微信都跑到屏幕外面去了:
于是,Claude Code 发现原因是 delay 0.005(5 毫秒)低于 AppleScript 的定时器精度(约 16 毫秒)。每次 set position 是跨进程 IPC 调用 System Events,位置还没改完下一条就执行了,最后的复位指令跟前面的移动撞在一起,窗口就回不到原来的位置。
再加上 osascript 跑在后台(&),如果用户在抖动期间按了发送键,进程直接被 kill,复位根本不会执行。
修复方是:
去掉 &,delay 调到 0.01 秒,复位改成双重补偿,确保窗口回到原位:
repeat 6 times
set position of fw to {x + 4, y}
delay 0.01
set position of fw to {x - 4, y}
delay 0.01
end repeat
delay 0.05
set position of fw to {x, y}
delay 0.05
set position of fw to {x, y}
第五版:去掉 hard code
到这里已经挺好用了。
但我内心总还感觉有些不安,后来发现是3 秒和 6 秒这两个数字。
我有个习惯:任何人但凡给我报出一个数字,我都想问他为啥是这个数。
产品经理说「这个设为 4 小时」,我会问怎么得到的,为什么不是 5 小时,不是 4 个半小时?
程序员说「超时设为 5 分钟」,我会问基于什么逻辑,为什么不是 4 分钟,不是10分钟,不是一小时?
所以,在面试时我也经常会问候选人这个问题。
任何 hard code 的数字都会让我不舒服,因为通常它意味着:不严谨。
代表着纯拍脑袋。
而现在这两个数是我自己定的,所以我当然得,解决之!
因为这里的问题在于,语音识别的耗时并不确定,有时候半秒就出结果,有时候要两三秒。
固定等 3 秒再开窗口,快的时候浪费时间,慢的时候可能还没识别完。
所以我想让脚本自己判断文字是否已经上屏,而不是傻等固定秒数。
于是我又试了几个方向。
检测键盘事件(ioreg HIDIdleTime):语音输入不经过物理键盘,根本检测不到。
或者读取光标所在输入框内容?
倒是个办法,但跨 App 兼容性太差。有可能这个好了,换一个 App 就不行了。
最后,我找到了一个可靠的方法:
通过 macOS Accessibility API 的 AXNumberOfCharacters,读取当前焦点输入框的字符数。
结束听写时记一个基线值,然后每 0.2 秒轮询,字符数变了就说明文字上屏了,立刻开窗口。
# 通过 pyobjc 调用 Accessibility API
import ApplicationServices as AX
_, el = AX.AXUIElementCopyAttributeValue(ref, 'AXFocusedUIElement', None)
_, n = AX.AXUIElementCopyAttributeValue(el, 'AXNumberOfCharacters', None)
这个方案在 iTerm2、微信、飞书等多个 App 上都验证通过。
识别快就早开窗口,可以更早开始决定要不要 Enter 发送,识别慢了就多等一会儿。
再也没有 hard code 了。
第六版:飞书不肯抖
改完之后,iTerm2 和微信一切正常。
但飞书……死活不肯抖。
检查日志发现,检测和声音提示都触发了,就是视觉上窗口纹丝不动。
我让 Claude Code 列出飞书的所有窗口:
Window 0: title=WatermarkWidget subrole=AXUnknown
Window 1: title=飞书 subrole=AXStandardWindow
原来飞书是 Electron 应用,first window 拿到的不是主窗口,而是一个透明的水印覆盖层。
脚本一直在抖这个看不见的水印,真正的飞书窗口当然纹丝不动。
解决方法:
把 shake 从 AppleScript 改成 JXA(JavaScript for Automation),遍历窗口列表,跳过水印层,找到真正的主窗口再抖:
for (var i = 0; i < wins.length; i++) {
if (wins[i].subrole() === "AXStandardWindow") { fw = wins[i]; break; }
}
这里,我顺便还让 Claude Code 给加了个细节:
抖动前先把窗口位置存到文件里。如果用户在抖动过程中就按了发送键,脚本会立刻停止抖动,强制归位窗口,然后发送。
不会出现消息都发完了,App 还在那儿一个劲儿抖的情况。
前后折腾了十来轮,终于,打磨出了一个趁手的工具。
而这工具从第一版到最终版,全程都是我用嘴说出来的。
写代码是语音,调参数是语音,跟 Claude Code 讨论方案是语音,整理方案也是语音。
我的手几乎没碰过键盘。
这也算是,对这套工具最好的验证了。
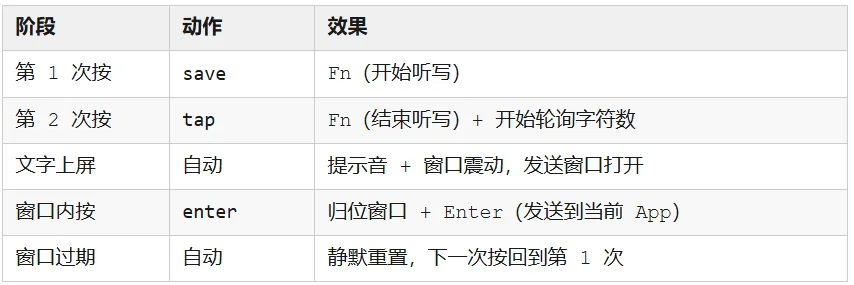
提示反馈是声音 + 视觉双重的:文字上屏后会播放一声清脆的 Tink,同时当前窗口快速左右微震。
即使你的电脑没开声音,也能靠眼角余光捕捉到窗口在抖。
Enter 直接发给当前最前面的窗口,不会跳转到别的 App。
在 iTerm2 中用 write text "" 发送(绕过权限问题),其他 App 用 keystroke return。
所以这个方案不限于 iTerm2,任何接受回车的应用都能用。
完整的 Karabiner 配置和脚本代码见开源仓库:https://github.com/Johnixr/dji-mic-dictation
实际用下来,这套方案已经覆盖了我日常所有文字性的工作。
写代码用 Claude Code,回消息用微信和飞书,写文档用备忘录(按一下发送就是换行,连续记录很顺手),甚至 Telegram、Slack 也能用。
任何接受文字输入的 App 都行,全程动嘴不动手,简直成了上海蹦迪宁。
好的东西还是要分享,所以我把它开源了出来:
https://github.com/Johnixr/dji-mic-dictation
祝你也早日成为一个动口不动手的正人君子。
而如果你发现某个 App 不兼容,欢迎到 GitHub 提 Issue 或提交 PR.
整个过程一步步看看,但也没啥,但从结果上看,还是挺神奇的:
电脑上打开着微信,对着领口嘀嘀咕咕几句后,文字就会出现在输入框里,然后微信窗口就抖了一下,再按一下就发出去了。
全程双手不碰一下电脑,全靠嘴。
还是有点点小魔幻的。
且过程中,微信还自己通过抖动来「提醒」我:要不要发出去?

就在上周,我们团队已经人手一个 DJI Mic Mini,成了标配。
日常的工作场景变成了:
一屋子人各自对着领口嘀嘀咕咕,偶尔抬头看一眼屏幕,然后继续低声说话。
若是不知道的你见到这个场面,你可能会想:这帮人干啥呢?
但仔细想想,AI 时代人们的工作方式,可能就是这个样子。
再也没有机械键盘的噼里啪啦,只有此起彼伏的嘀嘀咕咕……
我们,也算是初具雏形了。
配置好了后,我现在的工作是这样的:
USB-C 连接 DJI Mic Mini 接收器到 Mac,打开 iTerm2,启动 Claude Code。
按一下胸口的音量+,听写开始,屏幕上出现听写指示器。
对着麦克风说出需求,说多久都行,不用急。
说完了,再按一下音量+,听写结束。
文字上屏的瞬间,听到 Tink 一声,窗口微微一抖,发送窗口打开了。
再按一下音量+,指令直接发送,AI 开始工作。
然后我就可以去倒杯咖啡、刷刷手机、回个消息。
当然,也可以再开个 terminal,提高并行度。
如果发现说完之后有些不太准确的想要手动修改,或者还要继续补充些信息才发送,那就不按第 3 下,窗口几秒后自动关闭重置。
一个按钮,三种结果,全靠时间控制。
完全由我,远程掌控。
现在,我可以坐在沙发上,端着咖啡,对着这个小麦克风说出想法,然后看着 AI 把它变成代码。
键盘不再成为束缚。
想法才是。
上面写了这么多原理和迭代过程,如果你也想要一个,只需要三步。
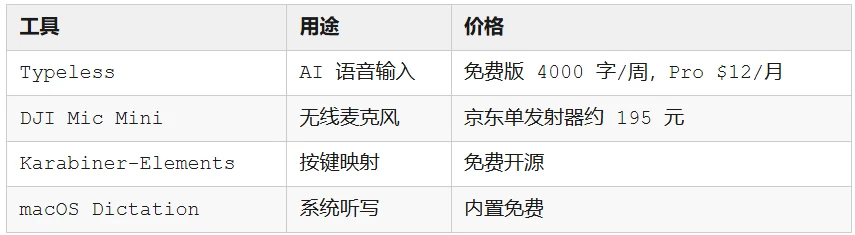
第一步:买个 DJI Mic Mini
京东购买链接(同样有我的码,方便统计):https://u.jd.com/N61cCGv
单发射器到手不到 200 块,10 克重量,重量上完全无感,还有着夸张的 400 米传输距离。
第二步:装一个 Typeless
Typeless
免费版每周 4000 字够日常用,Pro 版 $12/月。
也可以用我的邀请码,你若用了我会得到些什么好处,可能你也会有。
且 Typeless 在 macOS 听写之上加了一层 LLM 智能编辑,识别准确率和输出质量都会好很多。
第三步:让 AI 帮你配置
我已经把完整的配置和脚本都开源了,你不用重走我的老路,让你的 AI 自己来就好了。
复制下面这段指令,直接粘贴到 Claude Code / Codex / Cursor 的对话框里:
帮我配置 DJI Mic Mini 语音听写,项目在 https://github.com/Johnixr/dji-mic-dictation
它会自动帮你安装 Karabiner、复制脚本、合并配置、授权权限。
不要手动安装。
让 AI 来。
如果还是不行,那十有八九是 macOS 的权限没给全。
去系统设置 → 隐私与安全,把这几个都打上勾:
如果发现按钮只调音量不触发听写?
那是 Karabiner 没抓到设备。
能听到有提示音但窗口不抖?
那是 osascript 缺辅助功能权限。
还有什么问题的话,GitHub 仓库的 README 里有完整的排查清单。
扔给你的 AI,它会告诉你怎么做。
工具清单
📎 开源地址:https://github.com/Johnixr/dji-mic-dictation
复制这段指令粘贴给你的 AI:帮我配置 DJI Mic Mini 语音听写,项目在 https://github.com/Johnixr/dji-mic-dictation
本文中的配置和脚本已在 macOS Sequoia + Karabiner-Elements 15.9.0 + DJI Mic Mini 上验证通过。如果你用的是其他设备,只需修改配置中的 vendor_id 和 product_id 即可。
我们正在找人。
目前还只是一个小团队,做 AI 驱动的 agentic 全球产品。
至于需要什么样的人?
你看完这篇文章应该能感受到了,我们要的就是,不只是会写代码的人,而是能让 AI 替你写代码、替你解决问题的人。
比如能提出、并解决我这篇文章里说的这类事情的人。
有兴趣的话,欢迎联系。也可以让你的 OpenClaw 联系我的 OpenClaw,见:我用 OpenClaw 做了个社交平台,让 AI 先替我面试
欢迎来撩!
相关链接
文章来自于“AGI Hunt”,作者 “J0hn”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】Whisper是由openai出品的语音转录大模型,它可以应用在会议记录,视频字幕生成,采访内容整理,语音笔记转文字等各种需要将声音转出文字等场景中。
项目地址:https://github.com/openai/whisper
在线使用:https://huggingface.co/spaces/sanchit-gandhi/whisper-jax
