# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI圈追逐多年的通用人工智能(AGI),可能从一开始就走偏了。
图灵奖得主Yann LeCun在最新论文中提出,未来AI的发展方向不应该是模仿人类,而是另一条路线——
超人类适应性智能(Superhuman Adaptable Intelligence, SAI)。

在这个框架里,AI的发展目标发生了三个关键变化:
换句话说,SAI不再追求“像人一样聪明”,而是关注一件更底层的事情:
系统适应新任务的速度。
值得一提的是,LeCun在论文中还提出了一个颇为有趣的观点:人类本身其实也并不“通用”。
我们所谓的“通用能力”,很大程度上只是生物进化的结果——
人类在漫长的进化过程中,逐渐获得了一套适者生存的能力组合。
按照论文中的定义:超人类适应性智能(Superhuman Adaptable Intelligence, SAI)指的是一种系统:
能够通过快速适应,在人类能完成的任务上超越人类,同时也能解决大量人类从未涉足的任务领域。
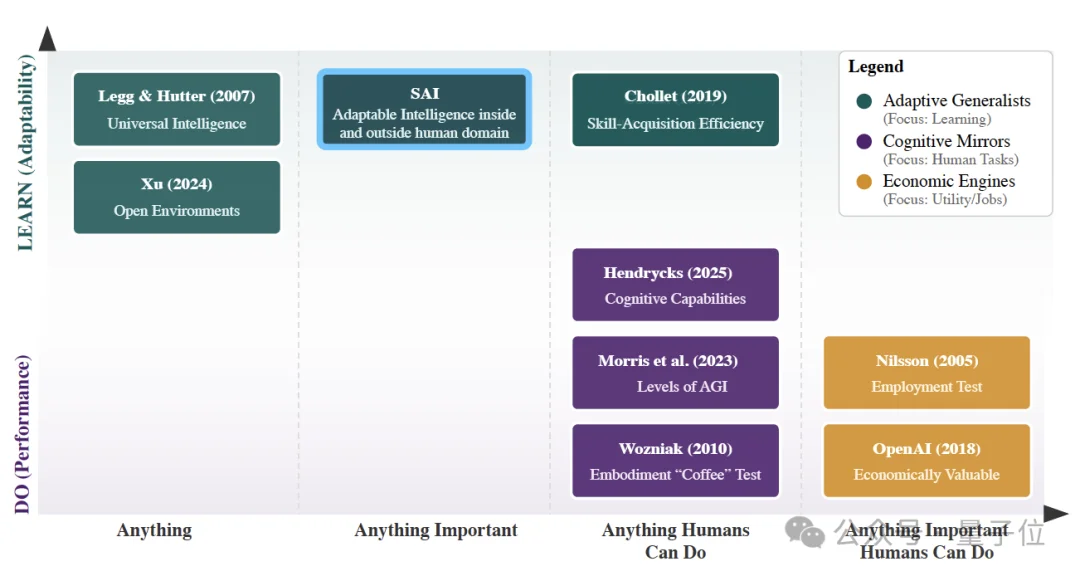
这里有一个关键转变。过去AI的发展逻辑是:把人类当作智能的标尺。
只要机器能做到“人类水平”,就算成功,比如图灵测试。
但LeCun团队认为,这种思路本身就存在问题,论文中有一句非常直接的话:
将智能锚定在人类基准线上,与通往超人类能力的路径是正交的。
换句话说:如果目标只是“达到人类水平”,反而可能限制AI的发展。
从这个视角来看,真正值得优化的,并不是模型完成某个固定任务的能力,而是:
系统适应新任务的速度。
因为一旦把“模仿人类”当作目标,AI的任务空间其实就被人为限制了——
人类能做什么,AI就学什么,但人类能力本身只是生物进化的结果,并不代表智能的全部可能。
更合理的路径是让AI围绕明确目标不断优化,并通过自我博弈、进化搜索和大规模仿真持续提升能力。
而这一观点,也与Richard S. Sutton在《The Bitter Lesson》中提出的观点相呼应——
真正推动AI进步的,往往不是模仿人类的技巧,而是规模化计算与通用学习方法。
在这种框架下,AI并不需要模仿人类,也可以在许多任务上直接超越人类表现。
相反,如果过度关注“人类水平”,不仅会误导研究目标,还会把AI的发展限制在以人类为中心的任务空间里。
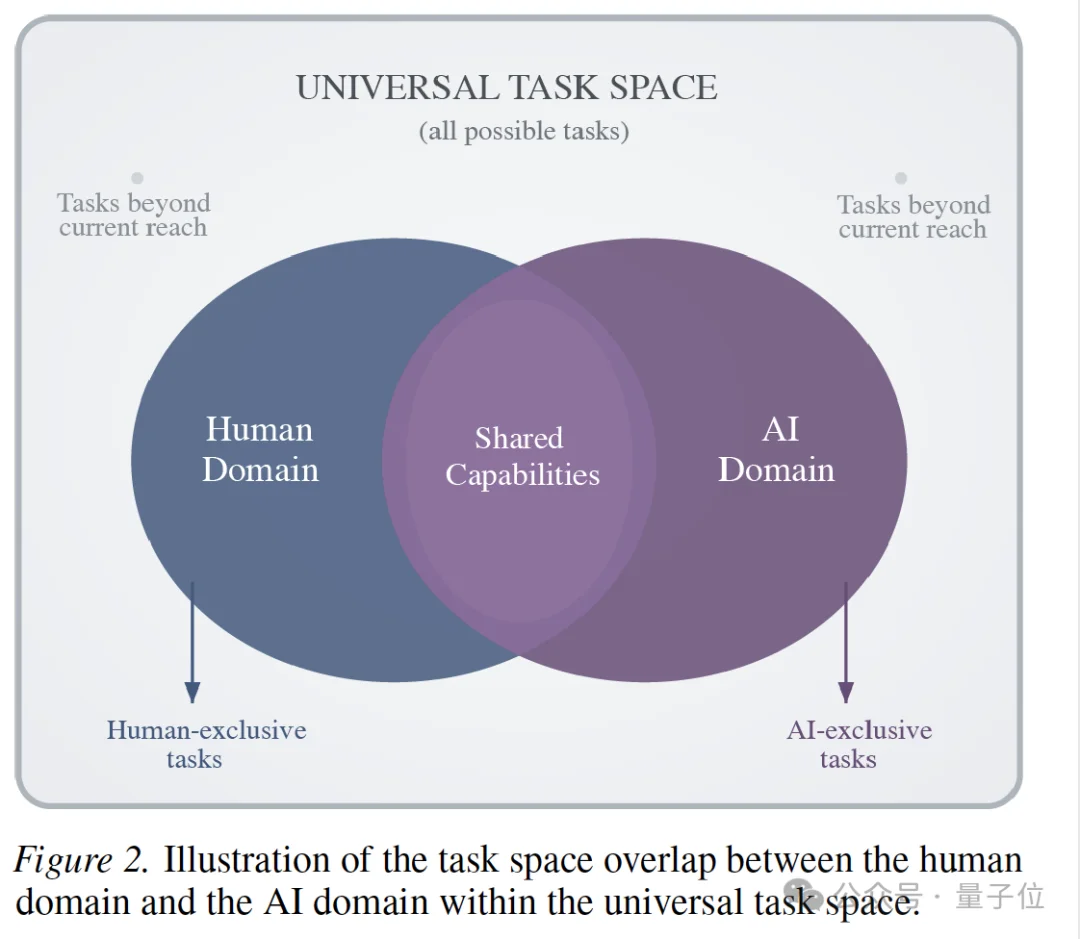
作为迈向超人类智能的一个重要前提,论文中还有一个非常有意思的观点:人类其实并没有我们想象的那么“通用”。
人脑并不是为了数学、编程或科学研究设计的。它最初的目标只有一个:在原始森林里活下去。
换句话说,人类的智能本质上是进化塑造的一种生存工具。
自然选择和进化优化了我们的能力,让我们擅长视觉感知、行走。
这些能力在我们看来非常“通用”,只是因为它们对生存至关重要,一旦离开这个进化舒适区,我们在其他认知任务上其实表现的并不好。
比如,计算复杂概率、高维优化、大规模逻辑搜索,在这些任务,人类的表现远远不如计算机。
最经典的例子就是国际象棋。顶级棋手在人类中显得极其聪明,但面对计算机时早已没有胜算。
这其实说明了一件事:所谓“AGI”,很大程度上是一种错觉,我们只是无法看见自己的生物学盲区。
而这个问题,就是锯齿的智能,或者所谓的莫拉维克悖论(Moravec’s Paradox)。
简单来说:人类觉得最简单的事情(比如走路、抓东西),对计算机来说反而最难;
而人类觉得困难的事情,比如:下棋、数学计算,对计算机却非常容易。
原因很简单,那些“简单”的能力,其实是人类数百万年进化的结果,它们实际上一点也不简单,只是我们习以为常。
所以论文得出的结论也很直接:
如果未来AI只是复制人类这种“生存型智能工具箱”,那将是一条错误的技术路线。
那既然人类的“通用性”本身就是一种盲区,那么真正正确的方向是什么?
Yann LeCun在论文中援引了生物学和机器学习领域的经验,给出的答案是:
专业化,才是智能进化的常态。
从生物学角度来看,专业化本就是常态。在资源有限、环境复杂的情况下,进化会不断推动系统向特定能力方向优化。
AI系统其实也面临同样的压力。
如果某个领域的任务非常重要成本、精度、可靠性,任何达不到要求的模型,都会被更专业的系统取代。
现实世界已经有很多这样的例子。最典型的就是AlphaFold。
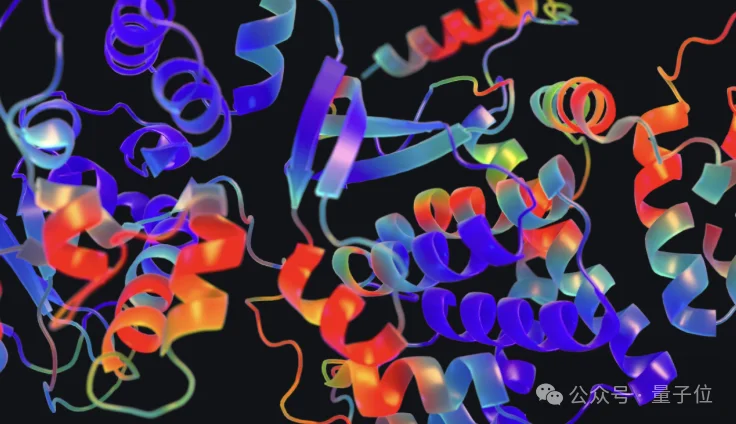
这个系统专门针对蛋白质结构预测设计,通过任务特定的架构、数据和训练策略,实现了巨大的突破,直接改变了整个生物学领域。
这也体现了机器学习中的一个基本规律:算法的成功,往往来自于它与问题结构(目标分布)的匹配。
如果一个模型既要:叠衣服、开车、写代码、预测蛋白质结构那么它很可能在所有任务上都只能做到“差不多”。
这也是为什么LeCun在论文中说:
帮我们折叠蛋白质的AI,不应该是帮我们折叠衣服的那个AI!
这在机器学习里有一个经典现象:负迁移(Negative Transfer)。
当多个任务争夺同一套模型容量时,它们的梯度可能互相冲突,反而拖累性能。
因此,从工程和理论角度看:强行追求通用性,往往是一条低效的路线。
那么问题来了。如果不追求AGI,该怎么追求SAI?
LeCun团队给出的技术路线是三个关键词:
自监督学习 + 世界模型 + 模块化系统。
首先是自监督学习(Self-Supervised Learning)。这种方法不依赖人类标注,而是从大量真实世界数据中学习底层结构。
其次是世界模型(World Models)。也就是让AI在内部构建一个“世界的模拟器”,像人类一样:预测未来、进行规划、在脑中模拟行动结果。
这样系统就可以在没有明确训练的情况下完成新任务。
最后是模块化架构。论文明确反对一种观点:不存在一个“统治一切”的模型架构,尤其是自回归范式的下一个token预测。
未来AI更可能是一系列相互协作的系统,而不是一个万能模型。
这篇论文的第一作者是来自哥伦比亚大学的博士生Judah Goldfeder,师从Hod Lipson教授。

此前,他曾在谷歌、推特、Meta等机构实习,研究兴趣主要集中在强化学习、算法博弈论、多智能体人工智能、无监督表征学习、多任务学习以及几何学习等方向。
论文的其他作者还包括Philippe Wyder,同样师从Hod Lipson教授,以及图灵奖得主Yann LeCun。

此外,作者团队中还有来自纽约大学数据科学中心的助理教授兼Faculty Fellow的Ravid Shwartz-Ziv。

他主要从事人工智能前沿研究,重点关注大语言模型(LLMs)及其应用。
参考链接
[1]https://x.com/rohanpaul_ai/status/2029533545161740321
[2]https://arxiv.org/abs/2602.23643
文章来自于“量子位”,作者 “henry”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
