# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
用强化学习微调扩散模型,还有更好的办法吗?
来自港中深、微软研究院等机构的VGG-Flow团队给出了一个新思路:既然奖励函数本身是可微的,为什么非要绕弯路用PPO、GRPO。

在大规模生成模型的对齐任务中,通常依赖强化学习,在某个奖励函数上微调模型以贴近人类偏好。而事实上,大部分奖励模型本身是在偏好数据集上训练过的神经网络。既然奖励是可微的,能否直接利用“可微性”本身,高效而稳定地微调流匹配模型?
主流做法主要分为两类路径:一条路是把模型当作黑盒,通过像Flow-GRPO那样,把原本确定性的ODE采样过程强行转为随机SDE,适配经典的强化学习框架来采用高方差的策略梯度方法(如PPO、GRPO)。
另一条路则更加直接,如ReFL等方法,通过近似手段优化某些取样步对应的奖励值,但这种做法在目标层面上缺乏严格的理论支撑,也往往容易导致过拟合与模式坍塌。那么是否可以走一条新路线?
VGG-Flow团队回归第一性原理,将奖励微调重新表述为一个连续时间最优控制问题。通过Hamilton–Jacobi–Bellman(HJB)方程,直接将“可微奖励”转化为价值梯度,为流匹配对齐提供了一条更稳定、更鲁棒的路径。目前该项目已被NeurIPS 2025接收。

流匹配模型通过在随机取样的x₀上模拟时间t=0到t=1的轨迹ẋ=v(x,t)来生成样本,其中v(x,t)是流匹配模型的速度场。
微调后的速度场可以被写成预训练模型与残差的和:vθ(x,t)=vbase(x,t)+ṽθ(x,t),其中预训练模型是vbase(x,t),残差是ṽθ(x,t)。
直观来看,为了避免模型在微调过程中过度偏离原有分布,微调在最大化样本奖励的同时,需要约束预训练模型与微调模型在取样路径上的差:

从最优控制的角度看,这就是一个终态目标加上一段路径累计代价(cost-to-go)。
在最优控制理论中,价值函数V(x,t)描述了从状态(x,t)出发的最优预期成本。根据定义,上述目标对应如下的价值函数:

其演化满足以下Hamilton–Jacobi–Bellman(HJB)方程(强化学习中贝尔曼方程的连续时间形式):

由此可以得到最优修正项的解析形式:

这得到一个非常直接的结论:最优微调方向=价值函数的梯度。
不需要采样优势函数,不需要计算对数概率比,也不需要进行策略比值裁剪。只需估计价值梯度,即可直接、可微地更新流匹配模型。
这个价值函数如何得到?将最优速度场代回HJB方程,可以得到如下的价值一致性关系:

通过求解满足该一致性关系的价值函数,即可得到用于训练速度场的目标梯度。
为了使价值梯度∇V(x,t)在训练初期具备合理的引导方向,VGG-Flow引入了Forward-looking参数化方法:
1. 预估终点:在xt处进行一步Euler前推,得到预估终点

2. 参数化引导:利用一步前推的奖励梯度对价值梯度∇V(x,t)进行参数化:


在这种设计下,模型仅需学习残差项即可实现对齐。团队在实验中发现,即使不学习残差,仅依赖奖励梯度的参数化引导也能实现明显的对齐效果。这一技巧可以显著降低流匹配模型微调的计算成本。
优化目标:在该框架下,VGG-Flow的损失函数可以写为:
1. 梯度匹配损失:使速度场修正项拟合价值梯度

2. 价值一致性损失:最小化HJB方程的残差

3. 终端边界损失:根据价值函数定义,确保t=1时的边界条件成立


在Stable Diffusion 3上的实验中,仅需400次更新,VGG-Flow即可实现奖励信号的稳定提升。在Aesthetic和PickScore指标上,方法展现出较高的收敛效率与良好的多样性保持能力。相比ReFL、DRaFT等方法,其表现更为稳健,更不易遗忘预训练模型中的先验,生成结果更加自然。其收敛也快,并且直接作用于流匹配模型本身,无需额外将ODE转换为SDE。

△ 图1:Stable Diffusion 3在Aesthetic Score奖励下采用VGG-Flow微调的结果

△ 图2:Stable Diffusion 3在PickScore奖励下采用VGG-Flow微调的结果
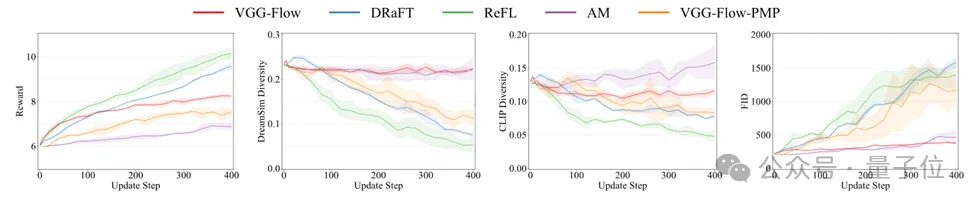
△ 图3:在Aesthetic Score奖励下,奖励值、多样性指标与FID的收敛曲线。其中,奖励值、DreamSim多样性与CLIP多样性越高越好;FID越低越好。

△ 图4:不同微调方法在各项指标上的帕累托前沿。每个点表示某次训练过程中保存的某个checkpoint(共使用3个不同随机种子)。
本文提出VGG-Flow,在连续时间最优控制框架下,学习空间中每一点的价值函数梯度,并使速度场向其对齐,从而实现结构一致的可微奖励微调。
由于优化目标是匹配局部梯度,而非直接最大化终态奖励,该方法在实践中表现出更好的稳定性与鲁棒性。实验结果显示,VGG-Flow在现有文生图模型上能够快速收敛,同时保持生成质量与多样性,为基于可微奖励函数的高效微调提供了一种新的思路。
此研究已收录于NeurIPS 2025
论文地址:
https://arxiv.org/abs/2512.05116
项目网站:
https://vggflow25.github.io
开源代码:
https://github.com/lzzcd001/vggflow
文章来自于“量子位”,作者 “VGG-Flow团队”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
