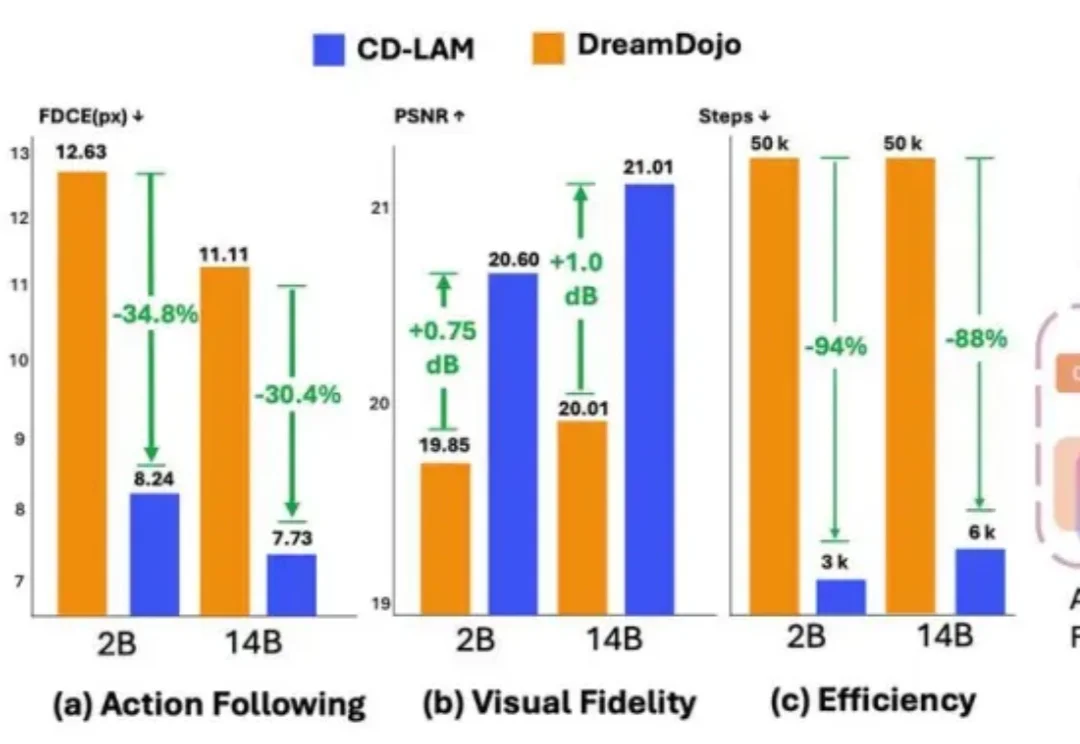
世界模型迎来因果升级:CD-LAM仅用几千步微调即可显著增强动作控制
世界模型迎来因果升级:CD-LAM仅用几千步微调即可显著增强动作控制人类可以轻松想象一个还没做出的动作会带来什么:手一松,杯子会掉;往前一推,抽屉会合上。动作尚未发生,大脑已经预演了可能的结果。对机器人来说,具身世界模型(Embodied World Model)会根据当前观察和未来的动作,预测动作执行后的未来画面。
来自主题: AI技术研报
5744 点击 2026-07-28 10:33
 搜索
搜索
人类可以轻松想象一个还没做出的动作会带来什么:手一松,杯子会掉;往前一推,抽屉会合上。动作尚未发生,大脑已经预演了可能的结果。对机器人来说,具身世界模型(Embodied World Model)会根据当前观察和未来的动作,预测动作执行后的未来画面。
这家公司是Fireworks AI,按现在流行的话说,Fireworks AI是一家Token工厂。既不训练前沿大模型,也不做面向消费者的AI应用,只做推理,帮企业把开源模型微调好、托管好,然后按调用量收钱。今年GTC大会上,黄仁勋和Lin Qiao有场对谈,老黄直言,“In a lot of ways, you're the TSMC of AI factories.”

来自上海交大、马来亚大学、CMU、MBZUAI、KIT和KAUST的团队提出VisNec(Visual Necessity Score,视觉必要性分数),用一个分数衡量每条训练样本里“图像到底起了多大作用”,被ECCV 2026收录。

做大模型RL微调,你是不是也踩过这些坑?

不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。
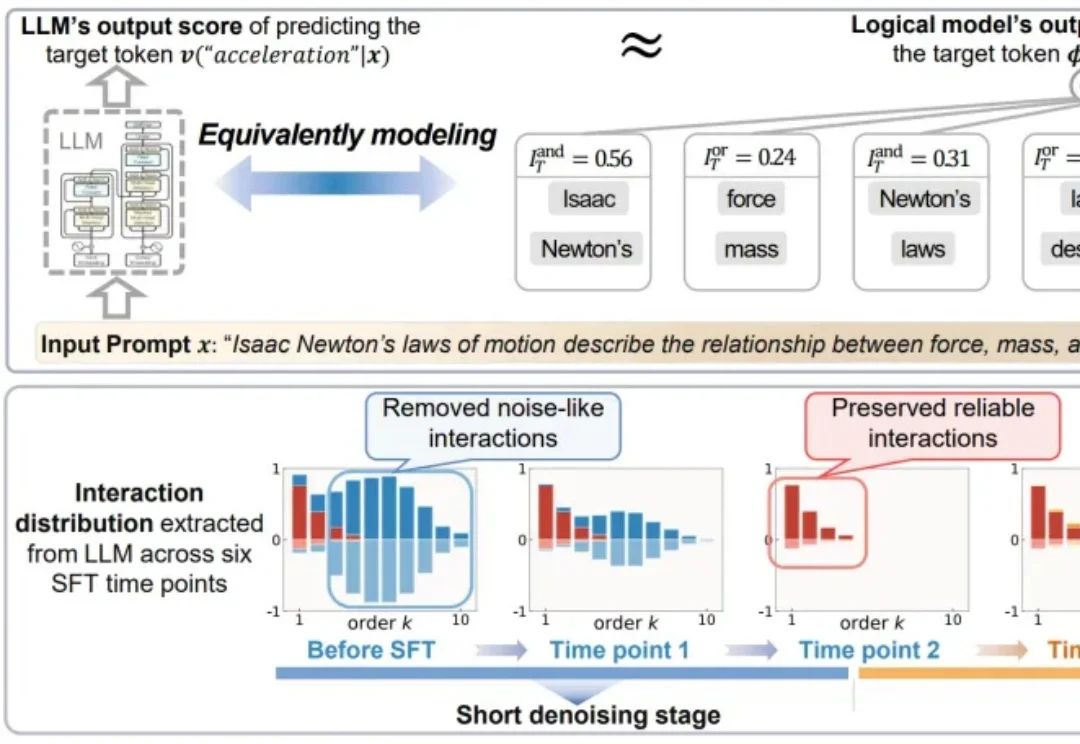
长期以来,监督微调(Supervised Fine-Tuning,SFT)一直是深度神经网络中最常用的模型适配手段。在中小规模的传统神经网络中,SFT 通常能够稳定提升下游任务表现。

最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。
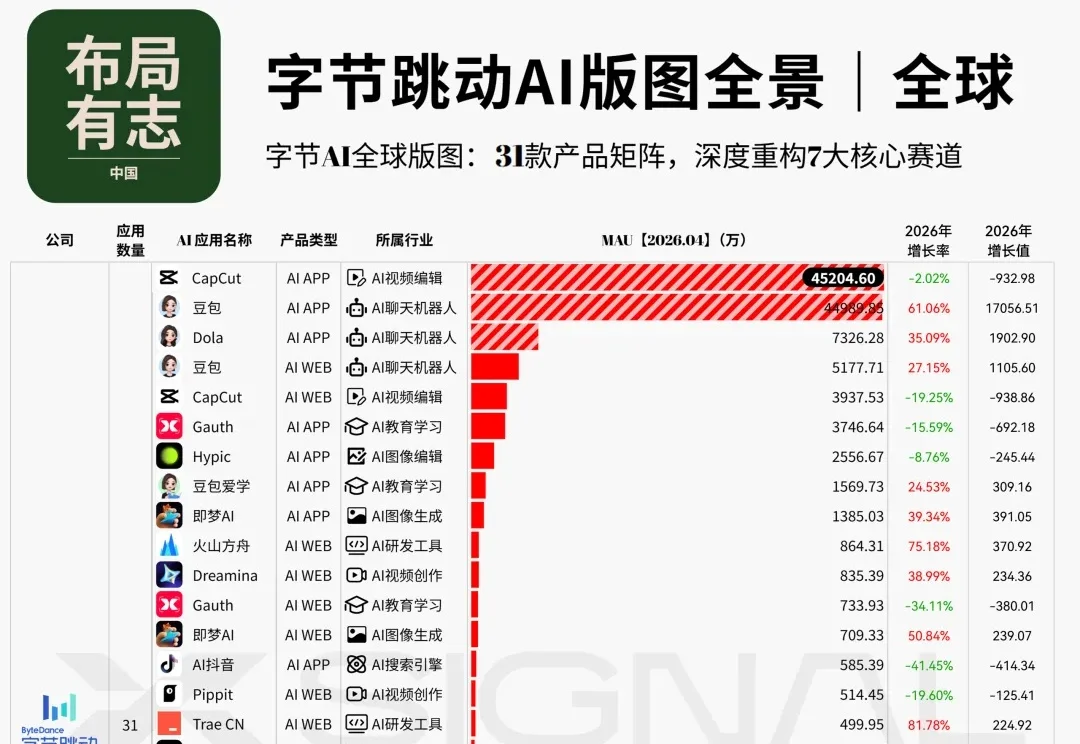
字节跳动计划在今年将其在人工智能基础设施上的支出大幅提升惊人的25%。这意味着将投入2000亿元人民币,这可不是一个边缘性的微调,是一次由不断升级的存储芯片成本以及字节跳动想要主导AI领域的雄心共同推动的巨大升级。
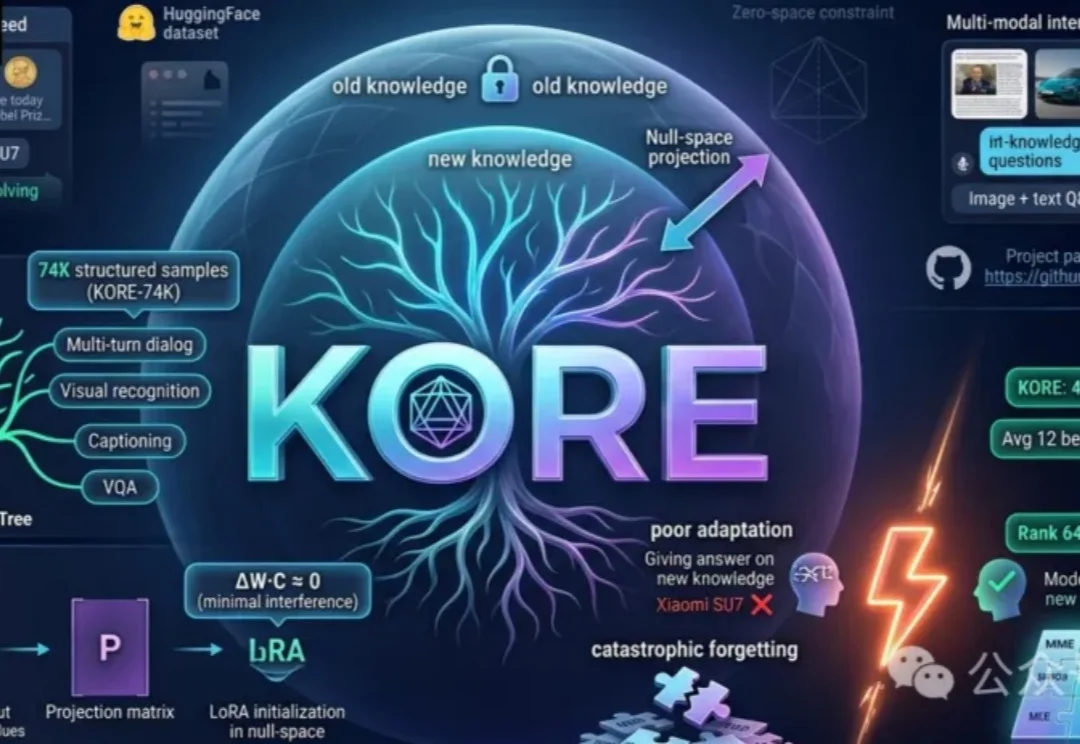
中科大团队首先推出动态多模态知识注入基准MMEVOKE,解构遗忘机制,并在此基础上提出全新双阶段框架KORE。通过「知识树」自动增强与「零空间」协方差约束微调,为大模型终身学习开辟了全新路径。