# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
上周有个朋友跟我吐槽,说他们线上跑的 Agent,单次任务 token 消耗到了六位数。
我问他,六位数里有多少是有用的?
他想了想说,可能一半都不到。大量 token 花在"把之前的废话再喂回去"上面。工具调了二十多次,其中至少七八次是因为参数填错了在重试。
这不是个例。做 Agent 的人迟早会碰到一个不浪漫的问题——贵。
步骤越多,上下文越长,工具调得越勤快,成本就滚雪球一样往上翻。跟普通的 LLM 推理不一样,Agent 有循环。第 n 步的输出变成第 n+1 步的输入,token 是复利式膨胀的。
最近刷到一篇综述,把这件事讲得挺清楚。
上海 AI Lab 联合复旦、中科院、上交大、清华等 9 所高校,发了一篇《Toward Efficient Agents: Memory, Tool Learning, and Planning》。35 页正文,200 多篇引用,还配了项目页和一份持续更新的论文清单,基本把 2023 到 2026 这条线索串起来了。
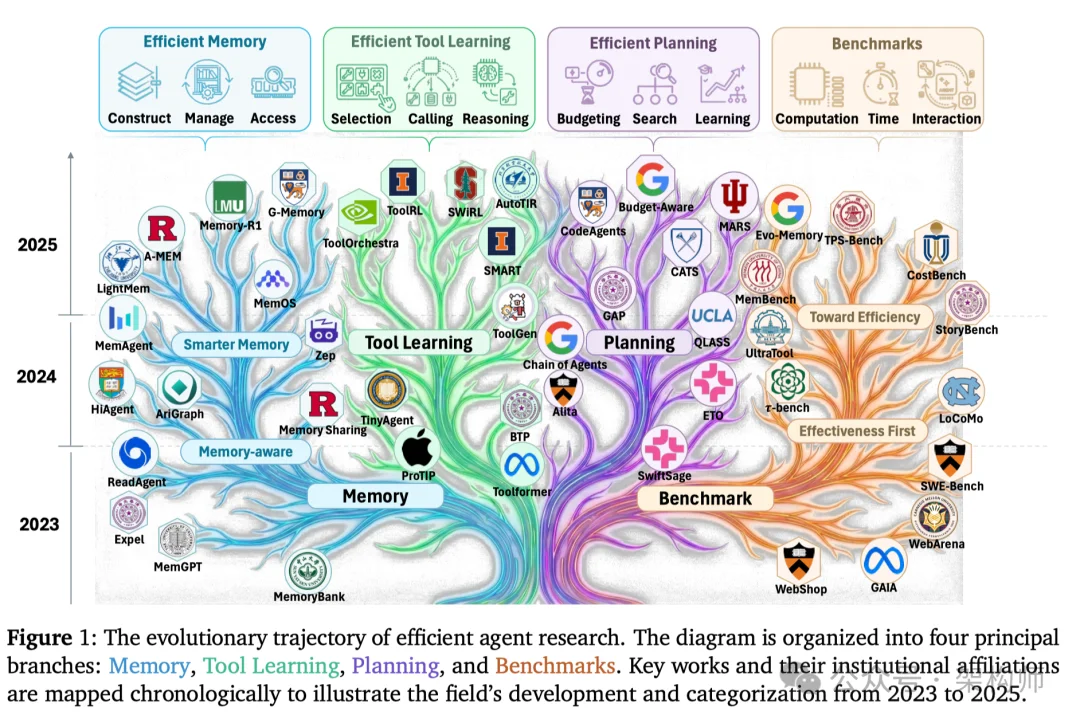
我不打算复述论文结构。更想从工程角度把里面最值钱的东西拎出来,配上我自己踩过的坑。
高效 Agent 不是换个更小的模型。
它是系统优化问题。单位成本下成功率更高,或者同等成功率下成本更低。
论文给了一个度量框架,我觉得很清楚。效率有两种看法:固定预算比效果,固定效果比成本。把不同方案画在"效果-成本"平面上,看谁更靠左上角。这就是 Pareto frontier 的直觉版本。
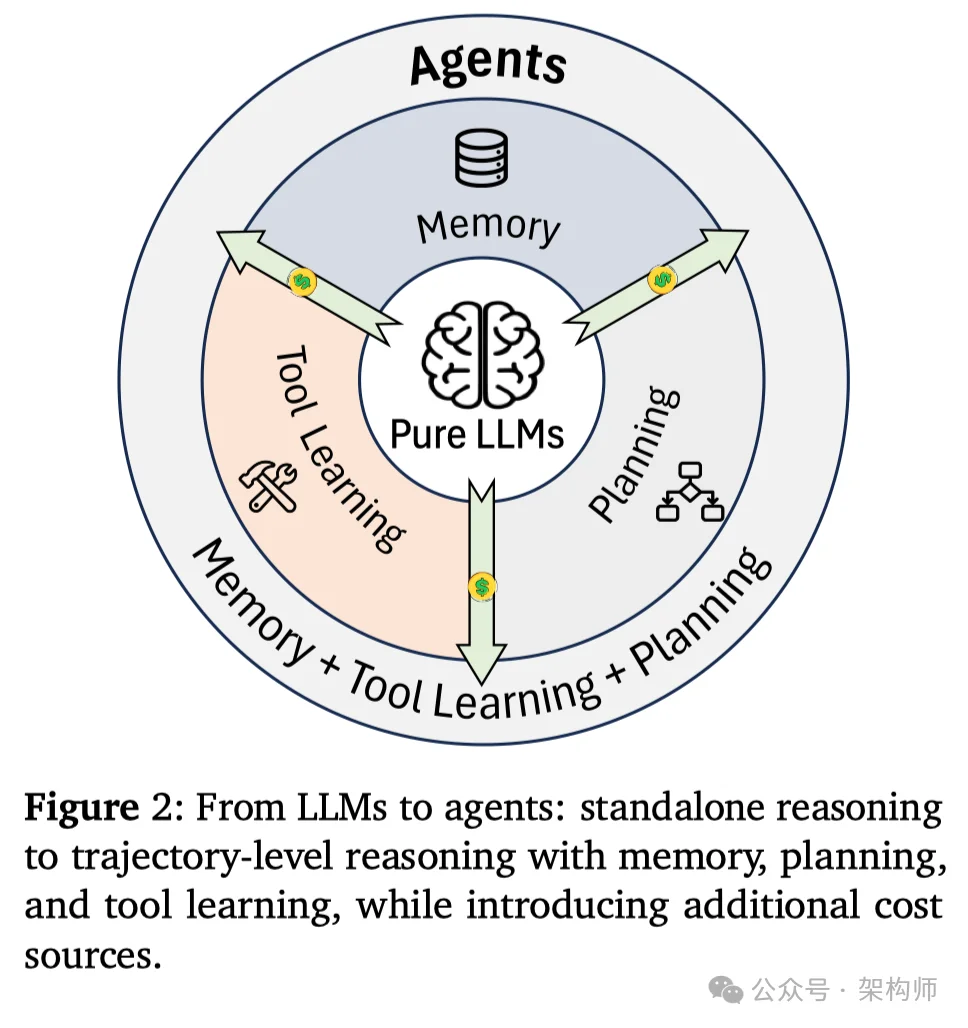
三个最有杠杆的地方:记忆,工具学习,规划。
如果你只能做一件事,先把可观测性补上。token、步数、工具调用次数、失败原因。看不见的东西没法优化。
很多人提到效率,第一反应是上量化、降参数、用更小的模型。这些管用,但它们解决的是模型推理成本。
Agent 的成本结构不一样。
论文里给了一个公式,挺直白的:
Cost_LLM ≈ α × N_tok
Cost_Agent ≈ α × N_tok + 工具调用成本 + 记忆读写成本 + 失败重试成本
翻译成人话:Agent 的账单 = 模型推理 + 工具调用 + 记忆读写 + 失败重试。
后面三项在实际系统中经常占大头。但很少有人认真测量过。
更麻烦的是循环效应。每一步输出变成下一步输入,上下文复利膨胀。工具调用引入外部 I/O 和等待时间,延迟叠加。多 agent 协作如果不管通信拓扑,轻松变成 O(N²) 的对话风暴。
所以这篇综述的切入点很工程:别在模型层面死磕,把效率拆到三个组件里去改。
Agent 的第一个效率坑,经常出在信息管理。
我见过不少系统,上下文里一大半内容跟当前决策毫无关系。之前的工具输出、早已过时的中间推理、重复的指令,全塞在 prompt 里重新跑一遍。
这就像你每次出门都把全家的衣服塞进背包。不是不行,就是累。
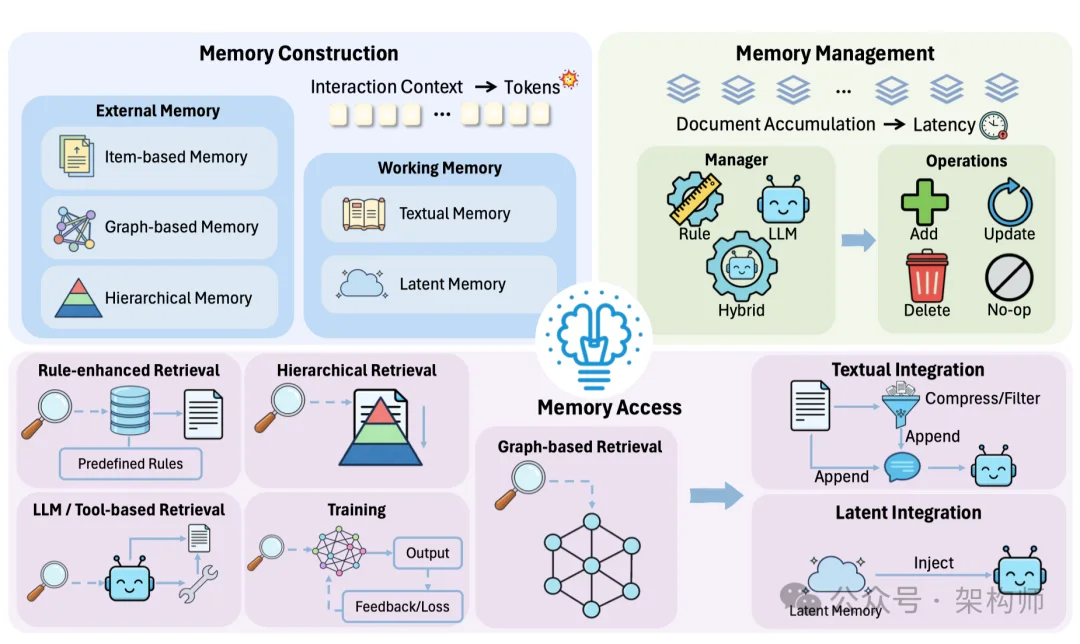
论文把记忆效率拆成三件事:构建、管理、访问。
构建:什么值得写进记忆?
工作记忆有两种省法。
第一种是文本压缩。把多轮对话和过程信息,压成可以继续推理的紧凑状态。COMEDY 从对话里提取关键事件和用户画像,压成紧凑表示。AgentFold 把交互历史折叠成多尺度摘要加最新完整轮次。
第二种是隐式记忆。不把信息写回文本,用更紧的表示承载。Titans 在测试时更新神经记忆模块,只在预测误差高的时候才写入。相当于给写入装了个门控,不是每一步都要记。
外部记忆的关键是"不要什么都存"。MemoryBank 用艾宾浩斯遗忘曲线做时间衰减,重要记忆强化,不重要的自然淡出。Zep 构建时序感知知识图谱,事实边带有效期,过期的事实不会再被检索出来。
层次化记忆是另一个方向。MemGPT 借鉴了操作系统的虚拟内存分页。prompt 被分成系统指令、可写工作上下文和消息缓冲区,溢出就换页到外部存储。跟你电脑的内存管理是一个思路。
LightMem 的设计我挺喜欢的,在线阶段做快速更新,离线"睡眠"阶段做整合。跟人的记忆巩固过程很像。
管理:记忆也会过期、冲突、冗余
写进去不代表一直有用。
规则型管理便宜但呆板,比如 FIFO、TTL。LLM 驱动型让模型自己决定增删改,效果好但成本高。混合型最实用,轻量规则做初筛,LLM 只处理需要判断的少数条目。
工程上最关键的是写入门控。不是每一步都要写记忆。写入本身也花 token。
我的做法是定义触发条件:失败重试前、阶段切换时、上下文超阈值时。给每条记忆打标签——约束几乎永不删,中间推理用完就清。
访问:检索不是越多越好
检索 top-k 越大越好,这是外部记忆最常见的效率误区。
你检索回来的内容越多,塞进 prompt 的无关信息越多,模型的注意力越分散。
如果你在做 RAG 加 Agent,建议把"检索预算"变成显式参数。每个任务一个 retrieval_budget。每次检索都要回答两个问题:为什么要查?查到的东西能改变什么决策?
回答不了,这次检索就是在烧钱。
第二个效率坑。
模型不太确定一件事,就调个工具。调完发现还不够确定,再调一次。中间参数填错了,重试。重试又带出新的工具调用。
一个任务下来,工具调了二十几次,其中一半以上对最终结果没贡献。
先选对,再调用
工具越来越多的时候,让 LLM 在一堆工具描述里反复读说明书,光是那些描述就占了几千 token。
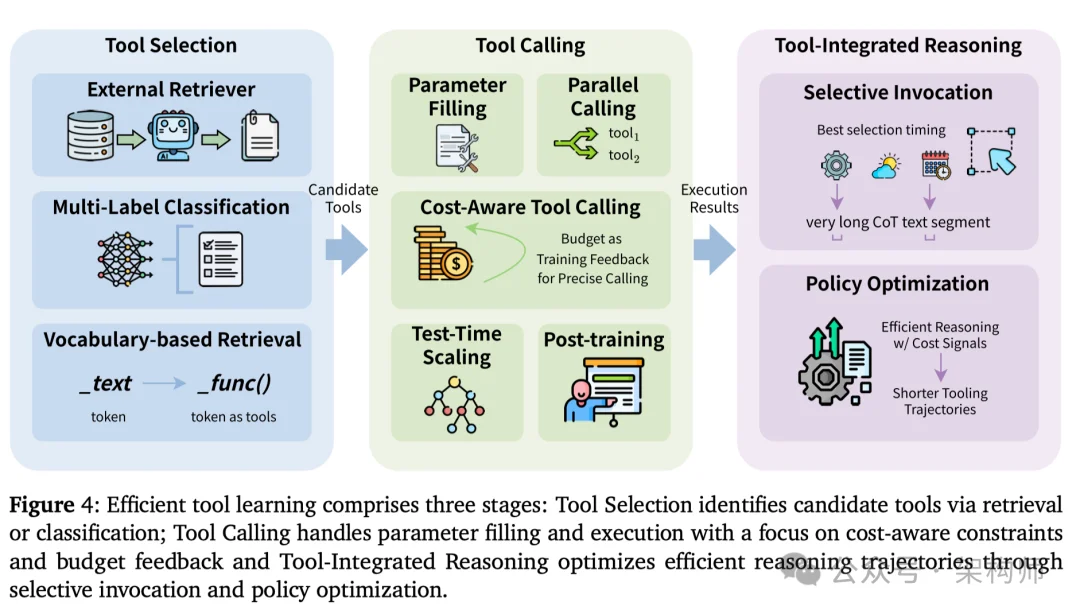
论文梳理了三种工具选择范式。
外部检索器,独立模型嵌入查询和工具描述算相似度,适合工具池动态变化。多标签分类,固定工具集当分类任务来做。词汇检索,把工具嵌入为特殊 token,几乎零额外开销但泛化性受限。
TinyAgent 的做法挺聪明,用一个轻量的 DeBERTa-v3 编码器做工具预测,直接把需要塞进 prompt 的工具描述量砍掉一半。
工程上我倾向的方案是:先用规则加检索把候选集缩到三到七个,再交给 LLM 做最终选择。
把"调用一次"做成"可靠的一次"
工具调用的真实成本,大部分来自失败后的重试链条。
几个立刻能做的事。
就地填参。别让模型先生成一大段解释再提取参数,直接输出结构化参数并校验。CoA 用符号抽象替代中间步骤,推理时间降了 30%。
并行调用。能并行就别串行。我在实际系统中试过,把独立的查询类工具从串行改并行,端到端延迟直接降到接近单步。
成本感知。BTP 把工具调用建模为背包问题,给定预算约束选性价比最高的工具组合。这比"想到了就调"有章法得多。
用 RL 训练模型减少冗余调用。ToolRL 的做法是在奖励函数里加工具调用惩罚,调用越少、成功率不变,奖励越高。这比在 prompt 里写"请少调工具"有效多了。
让"是否调工具"变成可控决策
当工具变成推理链的一部分,最常见的问题是模型在工具和文本之间来回横跳,步骤越来越长。
核心要区分两件事。什么时候必须调——需要外部事实、需要执行、需要验证结论。什么时候不该调——内部推理足够、调了也不会改变结论、预算紧张。
你做过线上 Agent 就会发现,很多"高频工具调用"其实只是模型缺乏不确定性表达。它不确定一件事,不会说"我不确定",而是默默调个工具。
把"不确定就调工具"改成"先估计置信度再决定是否调用",成本往往降一大截。
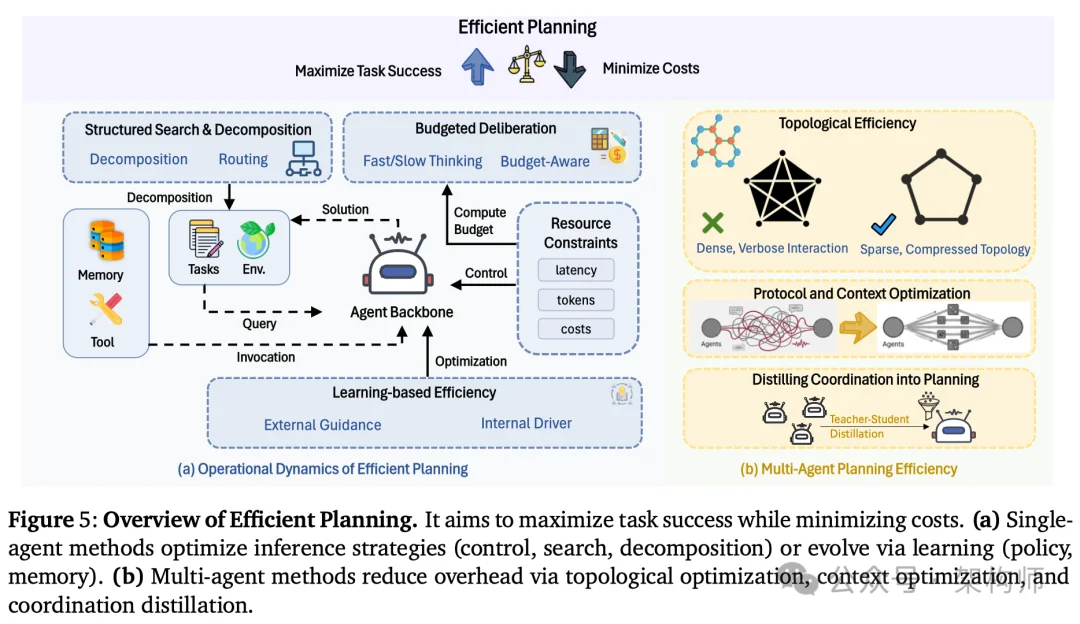
第三个效率坑——规划越复杂,轨迹越长。
把上限写进系统
没有预算约束的 Agent,天然倾向于多想一会儿、多试一次。对它来说多试一次没有代价。但对你的账单来说有。
把这些上限变成硬约束:max_steps、max_tokens、max_tool_calls、max_retries。
更关键的是,系统在快到上限时应该自动切换策略。从探索转为收敛,从高成本工具转为低成本工具。SwiftSage 借鉴了认知科学的双过程理论,简单任务走快速启发式,碰到困难才启动复杂规划器。
搜索不是免费的
规划能力来自搜索。候选方案的生成、分支和回溯。但搜索一旦失控,成本指数增长。
两个关键词。分支要少,用启发式减少无效分支。回溯要贵,回溯前必须产出失败原因和下一次要改的变量。
Reflexion 把失败经验转化为文本反馈,下一次尝试时作为约束注入。这比盲目重试有效率得多。
先拆对,再执行
ReWOO 把规划和执行解耦。先一次性生成完整计划,再批量执行。每一步执行时不需要把前面所有步骤的上下文重新塞进来,token 消耗大幅下降。
VOYAGER 在 Minecraft 里构建可复用技能库,遇到相似任务直接调用已有技能,不用从头规划。GAP 用图表示识别可并行动作,规划不再是线性链条,而是可以并行执行的 DAG。
多 agent 协作:通信不是越多越好
多 agent 能提升覆盖面,但如果每个 agent 都把自己的完整思考发出来,你得到的不是协作,是噪音。
Chain-of-Agents 用顺序传递替代广播。AgentDropout 动态淘汰贡献度低的 agent,运行着运行着团队就缩编了。Cut the Crap(名字很直白)做的就是通信剪枝。
还有一个取巧的思路。MAGDI 把复杂的多 agent 交互图蒸馏到单个学生模型里。部署时根本不需要跑多个 agent,一个模型就够了。用训练时间换运行时成本。
论文的评测部分梳理了几个对工程很有用的指标。
Cost-of-Pass:完成一次成功任务的期望成本。注意,失败的轨迹也算钱。
Cost Gap:实际执行路径相对最优路径的偏差。CostBench 定义了这个指标,用来衡量你多走了多少冤枉路。
一个更实用的视角:把不同方案的成功率和成本画在同一张散点图上。右下角的方案(成功率高但成本也高)未必比左边的(成功率稍低但成本低很多)更适合上线。
这张图可以当排查清单。每个箭头都能花钱。
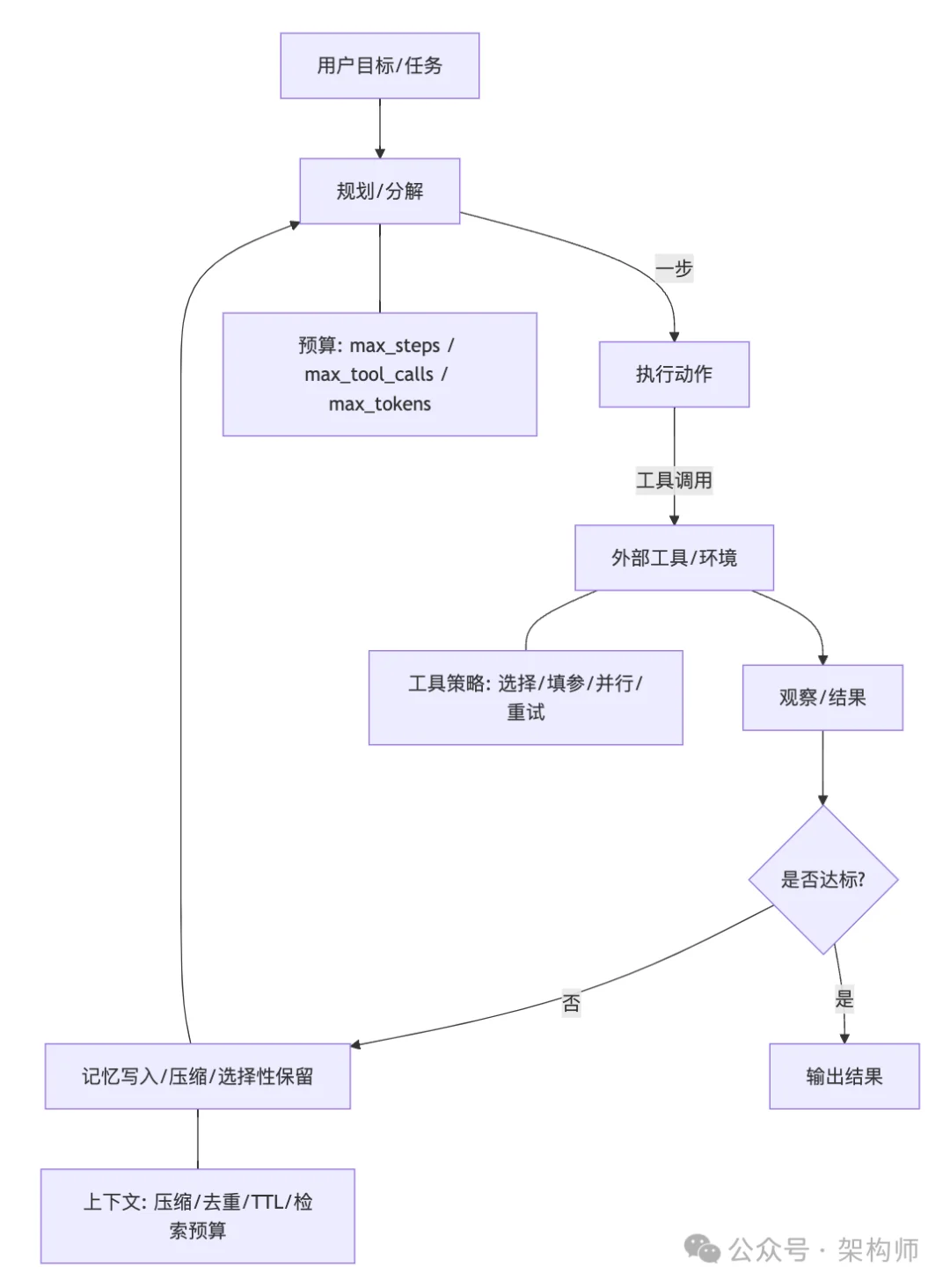
效率来自把主循环做成可控、可停、可复用。不是某个模块的单点优化。
如果你在做线上 Agent,按"能立刻省钱也能立刻提升稳定性"的顺序排:
很多优化最后没省钱,是因为没想清楚自己在省哪一类成本。

我的经验是先把重试链条砍掉,再讨论更精细的推理策略。重试是最贵的,也最伤稳定性。一个参数校验失败引起的重试循环,消耗的 token 可能比整个正常流程还多。
上下文越来越长,但你说不清哪几段是必须的。典型的把日志当记忆。
工具调用次数很高,但每次调用前没有明确目的。多数时候只是模型在逃避不确定性。
规划步骤增加了,成功率没上去。大概率是搜索失控,或者评估函数不可靠。
为了"更稳"每一步都加检索和验证。结果稳定了,但成本翻倍,SLA 反而更差。
快速诊断的方法:把一次失败的轨迹拉出来,问三件事。
失败前最后一次有价值的信息增量发生在哪一步?从那一步到失败之间发生了多少次无效工具调用?上下文里有多少段是下一步绝对用不到的?
答案通常很直观。
智能体潜在推理。 把推理过程从自然语言 token 转移到连续隐表示。现在 Agent 每一步都要用自然语言想出来再说出来,这本身就是巨大的 token 开销。如果推理可以在隐空间完成,只在需要行动时才转换成文本,token 消耗会断崖式下降。
多模态 Agent 的效率。 做 Web Agent 需要截屏理解,每一步都要重新编码视觉历史,计算量巨大。怎么做视觉上下文的压缩和复用,还没怎么被认真研究。
部署感知设计。 很多论文里的"多 agent 系统",实际上是一个模型扮演多个角色。真正的多模型部署和单模型角色扮演,资源消耗完全不一样。做产品的人应该挺有共鸣。
如果你是工程师:先把工具调用的失败重试链条打断。参数校验、幂等设计、可恢复错误处理,比加提示词有效得多。把检索预算和上下文预算写成显式参数,别让模型自由发挥。
如果你带团队或做平台:统一一套效率指标面板,把成本和效果放在同一张图上讨论,别靠感觉。工具接入做成产品——工具描述、示例、参数 schema、成本等级、fallback,都要可维护。
参考
文章来自于“架构师”,作者 “若飞”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
