# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态大模型掉进真实世界,会“失聪”。
你把它放在厨房:背后有人说话、金属碰撞、蒸汽嘶嘶——画面里啥也没有,但声音已经把关键信息全透露了。此时最强模型也开始“失灵”:看得懂动作,听不懂发生了什么;能描述现象,推不出原因。
问题不是模型不会“看”,而是还不会真正“听”。
而在人类的日常认知里,声音从来不是配角:
但长期以来,第一人称视频理解基准高度“视觉中心化”:音频存在,但缺乏系统评测;听觉重要,却很少被认真考察。第一视角世界,一直处在“半静音”状态。现有第一人称视频问答/理解基准,长期偏“视觉中心”,即使出现音频也常被当作辅助信息,缺少对“声音理解与推理”的系统评测空白。
现在,这个空白终于被补上了。
来自复旦大学,上海创智学院,INSAIT,华东师范大学,南开大学的研究团队,提出了首个系统评测第一人称声音理解能力的基准:
EgoSound: Benchmarking Sound Understanding in Egocentric Videos

这是首个专门面向MLLMs的第一视角“声音理解”评测体系。目标很明确:
让模型在真实世界中,能听见、理解、推理,并解释发生的一切。
不仅“看见世界”,更要“听懂世界”。
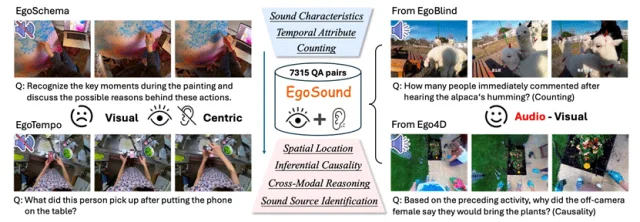
以往的egocentric VideoQA,更像一个“静音观察者”。它擅长回答:画面里有什么?人在做什么?却很难处理:谁在说话?为什么说?这个声音意味着什么?声音与动作如何形成因果链?
EgoSound关注的不是“视频里有什么”,而是:当声音成为关键证据时,模型还能不能答对?
EgoSound融合了两类互补数据:
Ego4D:覆盖大量日常第一人称活动
EgoBlind:聚焦更依赖听觉理解/交互/导航的场景
这使得评测既包含“视觉主导”的常见第一视角,也包含“声音主导”的现实难例。
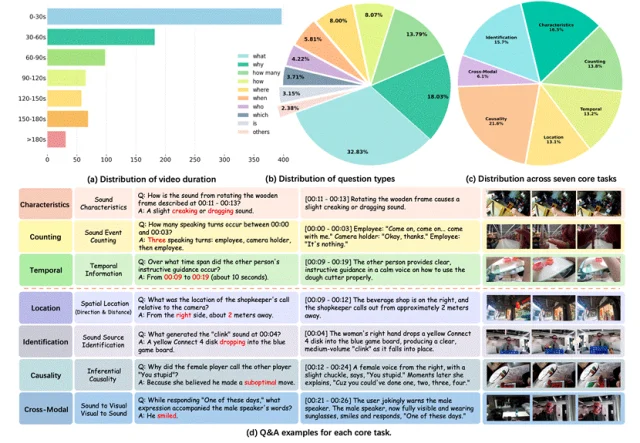
EgoSound系统拆解了第一人称声音能力边界,覆盖7类任务:
覆盖“听到→理解→推断”完整链路。
最终数据规模为:900段严格筛选视频+7315条验证后的开放式问答(OpenQA)。
强调“开放式”意味着它更接近真实问答,不是靠选项“蒙对”,更贴近真实场景。
研究团队评测了多款SOTA MLLMs,并进行系统分析,给未来方法研究提供清晰靶点。
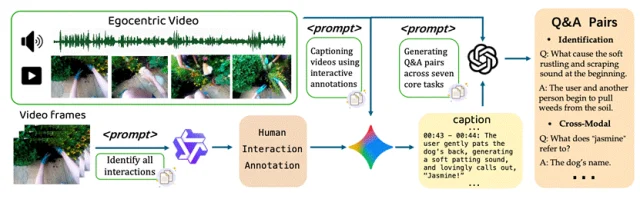
为了确保问题真的依赖声音,研究团队采用多阶段筛选机制:
构建并筛选高质量OpenQA
并借助多个强模型辅助标注。最终保证:每条问题都绕不开“听觉线索”。
评测结果非常直观,最强模型与人类差距超过27个点说明:当前模型还无法稳定把声音转化为可靠认知。
人类平均准确率:83.9%
当前最佳模型:56.7%(Qwen3-Omni-Thinking-30B)
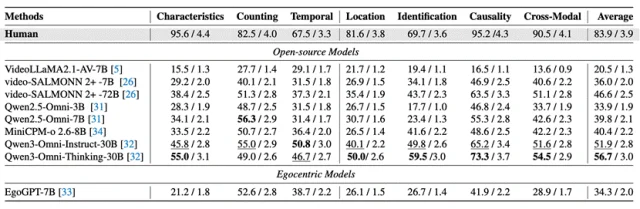
模型往往能描述看得见的内容,却难以稳定回答“声音来自哪里”“什么时候发生”“为什么会这样”。
声音线索经常在画面之外,模型需要建立“听到—看到—推断”的链条。
人与物的交互、遮挡、镜头抖动、声源离镜头远近变化,让声音推理更贴近真实但也更难。
如果说过去的多模态模型更像一个擅长“看图说话”的解说员,那么EgoSound希望推动它成为真正的第一人称智能体:
既能看,也能听;不仅能描述,更能定位、解释与推断。
毕竟,真实世界从不静音
论文标题:
EgoSound: Benchmarking Sound Understanding in Egocentric Videos
Paper:
https://www.arxiv.org/abs/2602.14122
Github:
https://github.com/groolegend/EgoSound/
Huggingface:
https://huggingface.co/datasets/grooLegend/EgoSound
Project page:
https://groolegend.github.io/EgoSound/
文章来自于“量子位”,作者 “EgoSound团队”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
