# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前企业 AI 落地的主要瓶颈往往不在模型能力,而在数据质量:大量企业数据仍以 PDF、Excel、扫描件等非结构化形式存在。而传统 OCR 只能识别文字,难以理解复杂文档结构;多模态模型在解析长文档时仍容易出现错误。随着 OpenClaw 等 agent 开始进入生产流程后,这些解析误差可能在自动化决策链中被进一步放大,高保真数据变得更加关键。
Reducto 聚焦“数据准确性”这一客户核心诉求,以文档解析 API 的形式提供 Agentic OCR 能力,将复杂文档转化为 LLM 可稳定理解的结构化输入,本质上构建了一层面向 LLM 或 AI 应用的数据摄取 infra。去年,Reducto 在 6 个月内连续完成由 Benchmark 与 a16z 领投的两轮融资,估值达到 6 亿美元。
但随着多模态模型能力持续提升,一个关键问题也随之出现:Agentic OCR 是否会成为独立的数据摄取层,还是最终被基础模型能力所吞并?
目前在简单文档场景中,基础模型已对 Reducto 构成竞争威胁。虽然在复杂文档场景,Reducto 的护城河仍然稳固,但如果模型未来能够直接稳定理解复杂文档结构,那么 Reducto 的价值会被进一步压缩。
01.
Thesis
Reducto 的亮点
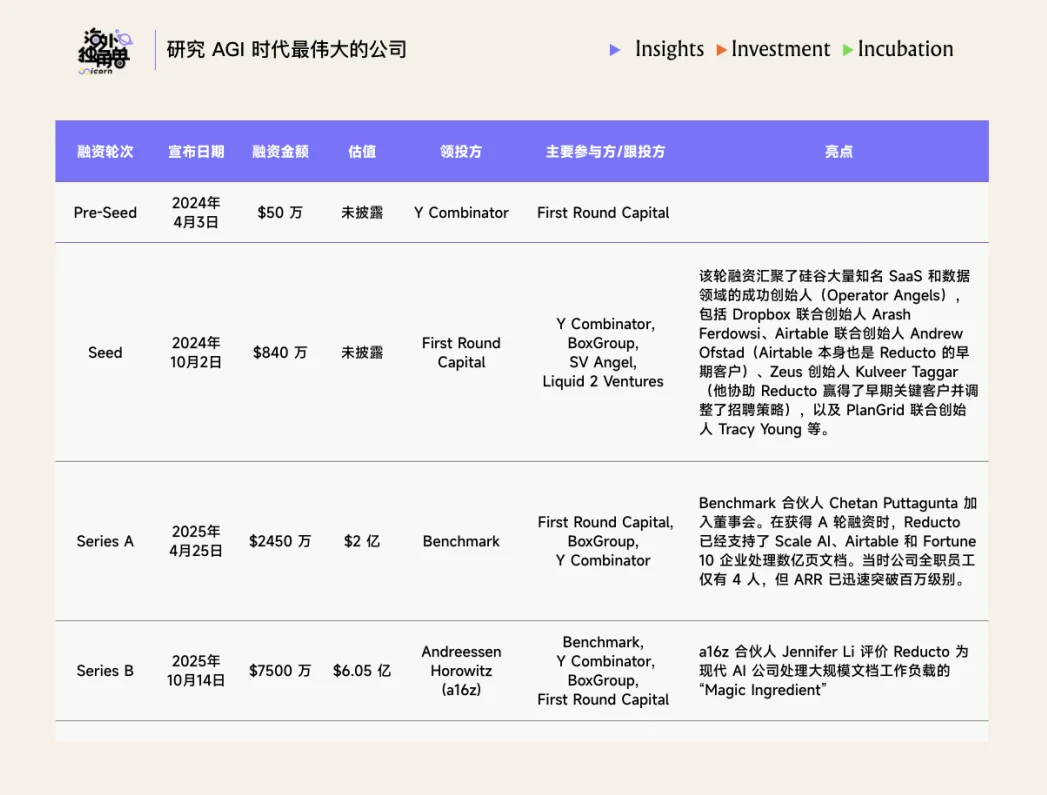
Reducto 在去年 6 个月内接连完成分别由 Benchmark 与 a16z 领投的两轮融资,估值翻了 3 倍,达到 6 亿美元。我们认为,Reducto 切中了 AI 应用走向生产环境过程中的“精确数据摄取”瓶颈。
1. 行业痛点明确,非结构化数据摄取是 AI 落地瓶颈
随着企业 RAG 从 PoC 走向生产环境,OpenClaw 这类能自主执行多步任务的 agent 兴起,业务对数据解析的要求已经从“能用”变为“必须准确”,因为微小解析错误也可能在自动化决策链中被放大。但目前企业 AI 落地的最大阻碍并非模型不够聪明,而是输入的数据不准确:企业约 80% 的数据是非结构化的 PDF、Excel 和扫描件,传统 OCR 难以理解复杂版式,多模态大模型直接读取长文档又容易产生幻觉,工程师往往需要花大量时间修复解析错误。
Reducto 作为连接企业数据与大模型之间的数据摄取层,在数据进入 LLM 前完成版面理解、逻辑关联和结构化清洗,本质上充当大模型生态的“数据编译器”,可以解决“garbage in, garbage out”的问题。
2. 团队聚焦“数据准确性”这一客户核心诉求,凭借 Agentic OCR 技术成功切入市场。
在文档处理领域,客户最关注的就是数据摄取的准确率。区别于简单的“OCR+大模型”拼接,Reducto 战略性地放弃了广度,选择利用团队自身在计算机视觉领域的深厚技术实力,精准抓住了“准确性”这一制胜关键:他们构建了“CV 版面解析、VLM 语义理解、Agentic OCR 多轮自纠错”的三层专有架构,使得 Reducto 在处理复杂图表、多栏排版等高难度场景时,效果好于传统竞品和直接调用大模型。
目前,Reducto 的客户包括垂直领域的 AI 公司(如 Harvey)、AI 数据标注公司(如 Mercor)以及用 Reducto 来处理 PB 级资产的 Fortune 10 企业。
长期风险
但长期来看,Reducto 的终局究竟能否演化为更广义的非结构化数据基础设施,还是继续深耕高精度文档解析这一垂直赛道,仍有待观察。
1. 模型多模态能力的提升是 Reducto 的最大威胁
尤其是在简单文档场景(电子生成的 PDF、格式规整的财务报表),随着 Gemini 等多模态大模型视觉能力的飞速进化,大模型直接处理文档的准确率正迅速逼近甚至反超 Reducto,且大模型的使用成本较低,导致 Reducto 的独立生存空间被严重压缩。未来高精度“文档提取”也存在被底层模型商品化(Commoditization)的风险。
2. 较高的定价一定程度上限制了 Reducto 获取更大市场份额
虽然 Reducto 相比 Unstructured.io,性价比相对较高,但相比云厂商和开源大模型,Reducto 定价较贵(处理成本可达传统云厂商 AWS Textract 的 10 倍)。企业在面对海量文档时,极高的成本会迫使客户混合使用多个工具,从而可能限制了 Reducto 获取更大市场份额。
此外,大企业有严格的数据合规要求,作为一个纯托管的 API,Reducto 虽然可以“开箱即用”,但目前缺乏允许客户自带模型微调(BYOM)的机制,难以满足一些企业极度细分场景的定制化痛点。
02.
传统 OCR 在 AI 时代的局限
在企业构建 RAG 系统、Agent 或自动化工作流时,将非结构化文档转化为结构化数据是不可逾越的第一步。这一环节的数据质量,直接决定了下游 AI 应用的准确率上限。然而,在海量复杂的现实数据面前,传统的数据摄取方式正面临着技术与商业的双重困境。
在技术上,过去的文档处理供应商高度依赖固定的“模板”(如针对特定银行账单的规则),这种系统极其脆弱,部署和维护成本也很高。面对现代企业排版多样的非结构化数据,例如文件中的双栏排版及边缘行号,或医疗记录、法律合同中的图文混排,传统 OCR 工具和简单的 PDF 解析库往往会出现严重的失真。

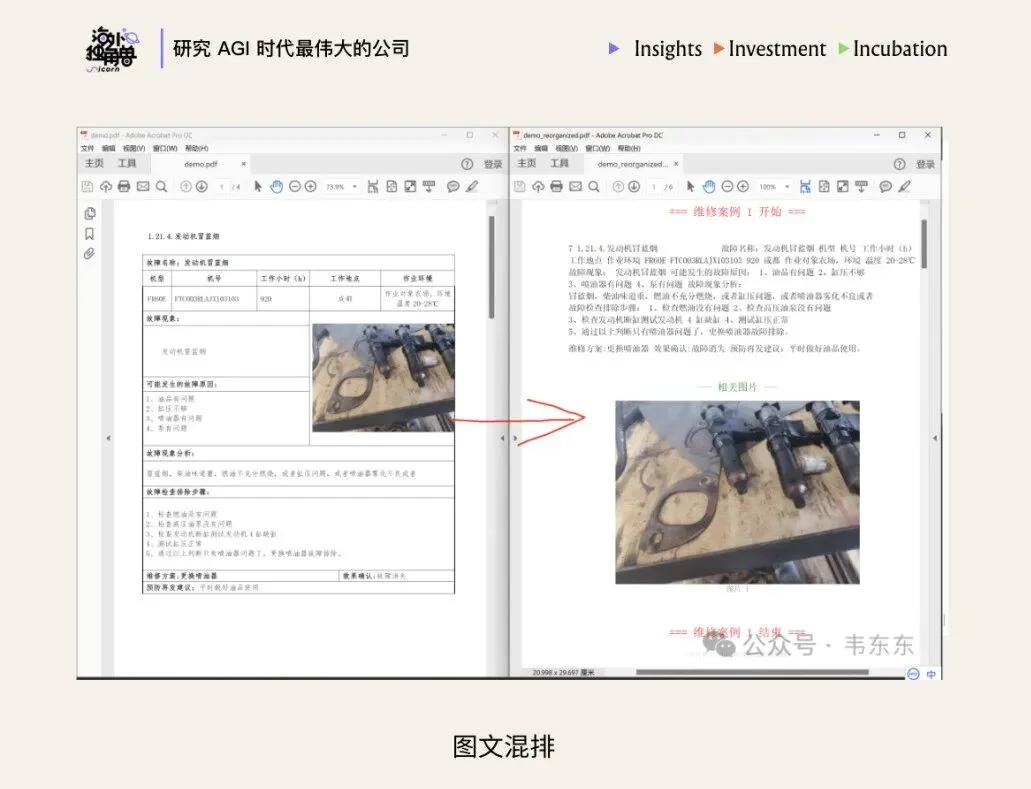
这一阶段的微小错误与结构丢失,不仅会在端到端的自动化流程中不断复合和放大,更会在商业上给企业带来实质性的业务损失。
• 客户提交的资料往往是包含图片、传真、合同的“大杂烩”,由于机器无法精准解析,企业只能高度依赖人工梳理。Reducto CEO 在访谈中表示,以某大型保险公司为例,由于严重的人力瓶颈,每 10 份大型理赔申请中仅能人工审核 3 份,高达 70% 的申请被直接搁置。
• 因为底层传入 LLM 的数据质量太差,许多 AI 开发者被迫花了很多精力在文档清洗。例如 CEO 曾在访谈中以一家 AI legal 公司为例,这家公司将大量宝贵时间耗费在修复基础的文档解析错误上,影响了核心 AI 业务的研发。
因此,当前客户在评估数据摄取工具时,最关注准确性,这主要体现在两个维度:
1. 面对极其复杂的版面(如嵌套表格、跨页图表、多栏混合排版)时,工具提取结果的结构保真度与业务关键字段的准确性有多好;
2. 能否直接输出符合大模型 RAG 工作流需求的干净结构化数据(如 JSON/Markdown),从而最大限度地降低企业内部的工程开发与人工干预成本。
03.
Reducto 的产品
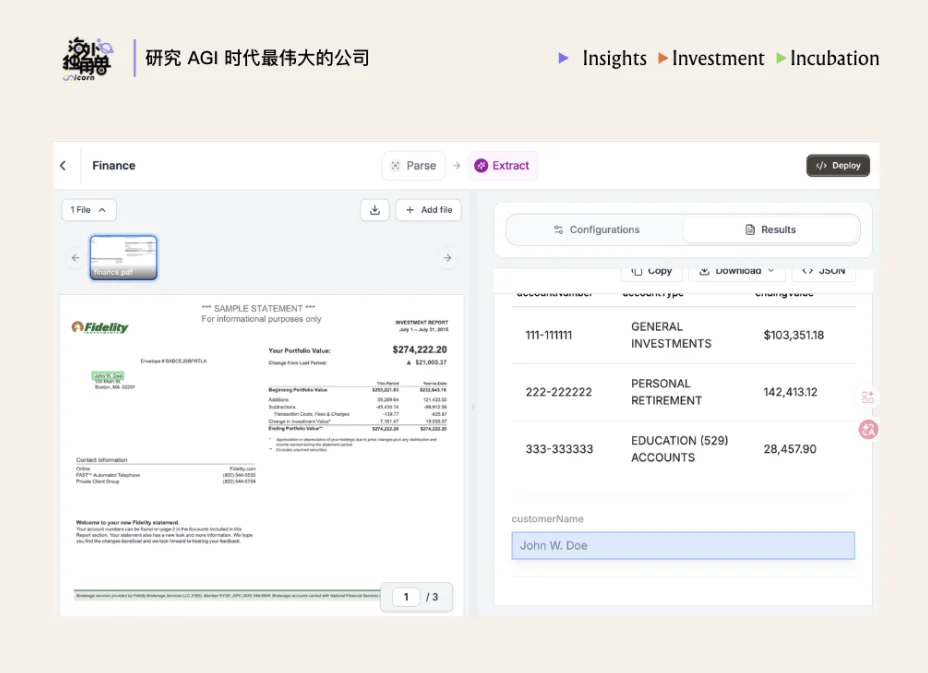
Reducto 成立于 2023 年,产品形态最初是一个读取和解析各种类型文档的 API,如今已经发展为一个更全面的“数据连接层”,可以整合和处理各种非结构化的人类数据。除了最初的文档解析功能外,Reducto 还扩展出了许多新的能力,例如编辑文档、提取结构化信息、对内容进行拆分和分类等。Reducto 产品最大的优势就在于文档解析精度非常高。


去年 6 月,Reducto Studio 正式发布,相比直接调用 API,Studio 提供了更直观的交互界面,客户可以在同一页面中对比原始 PDF 与解析后的 JSON 结构,更方便地理解解析效果并进行参数调试。
从产品形态上看,如果公司希望构建一个完整的数据平台,仅依赖 API 往往只能服务开发者群体,而提供一个统一的界面入口,则能支持更广泛的用户行为,从而降低使用门槛并扩大平台的使用人群。
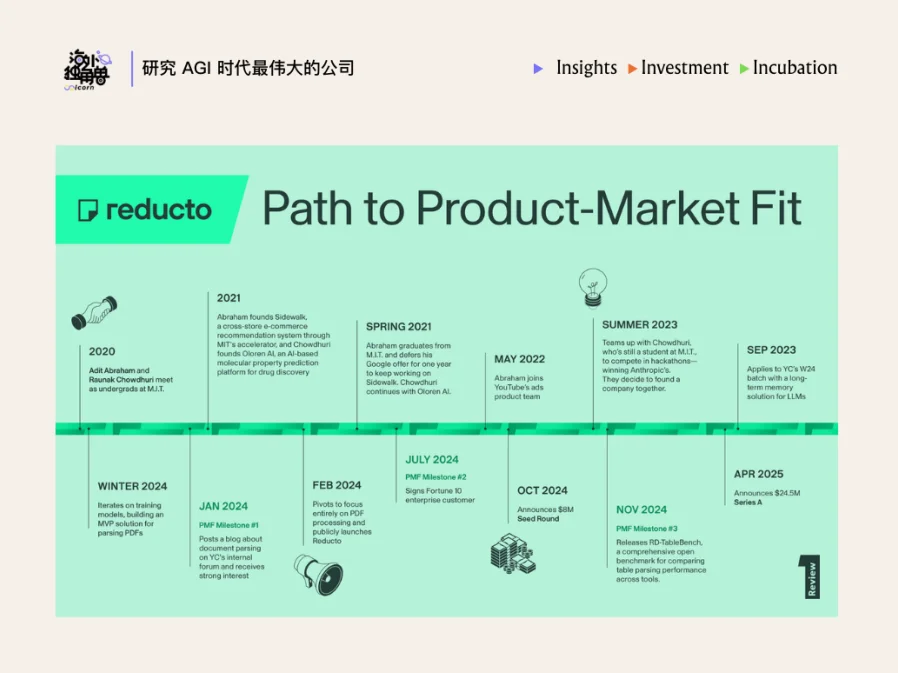
发展历程
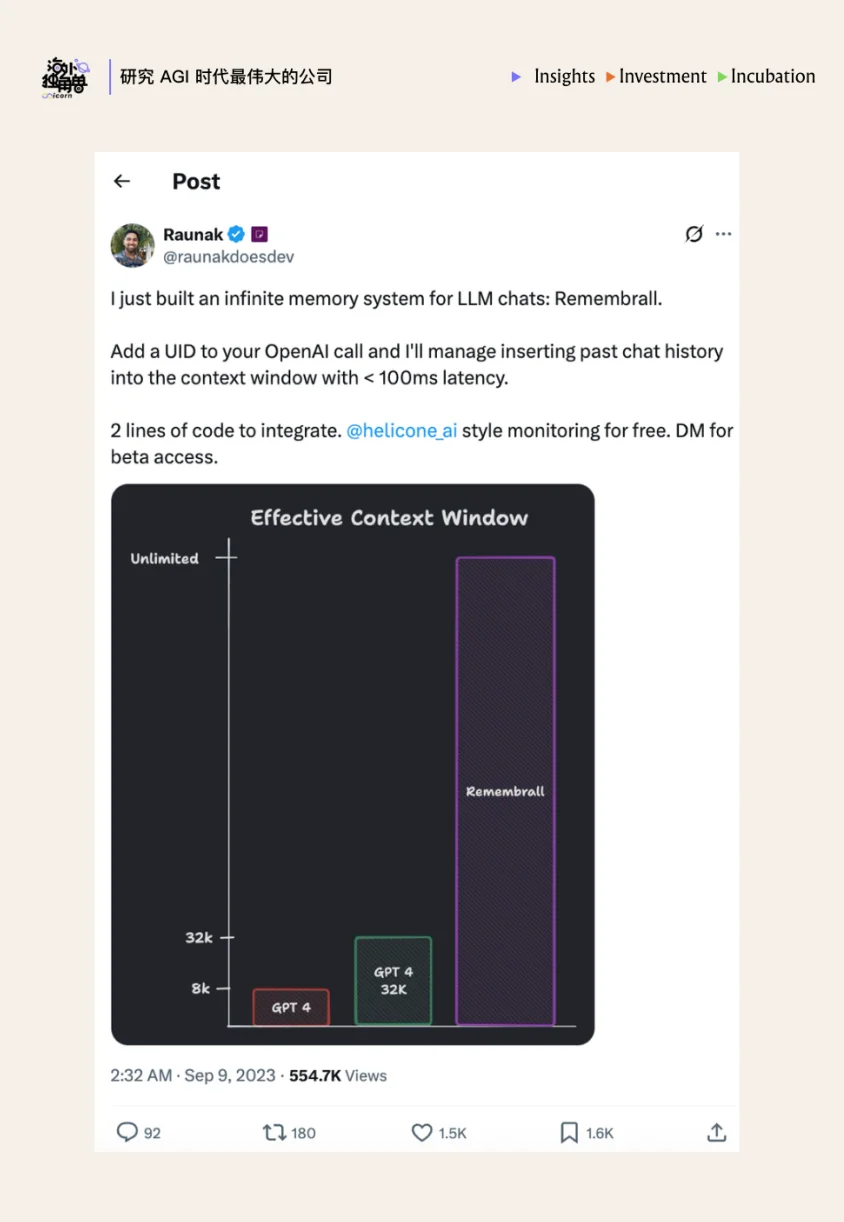
在创立 Reducto 之前,两位创始人 Adit Abraham 和 Raunak Chowdhuri 合作推出了 Remembrall 这个项目,它的核心功能是为 LLM 提供长期记忆。尽管 Remebrall 在社交媒体上迅速走红,但缺乏 PMF:个人爱好者只愿意为这个“玩具”支付极低的费用,而真正的企业产品团队并没有迫切的业务刚需。
转型契机来自于用户的反馈:部分用户询问在管理聊天记录时,能否同时处理上传的 PDF 文件。为了验证这个需求,两人花了一个周末草草拼凑了一个只能进行简单文档版面分割的测试网页,出乎意料的是,AI 开发者们认为它的效果甚至优于市面上的老牌成熟产品,并表示非结构化数据解析正是他们构建应用时最大的痛点与瓶颈。因此团队果断转型,将全部精力投入到了 Reducto 的研发中。
当时市场上已有其他处理非结构化数据的产品,且多数选择支持多种文件格式(部分产品支持的格式已经从原来的 35 种增至目前的 64 种)。但 Reducto 团队在接触客户时发现,企业核心业务中高频使用的文件类型通常只有两三种,这占了总工作量的 80-95%。部分竞品由于支持的格式过多,导致在处理核心格式时的准确率受到一定影响。
因此 Reducto 在初期没有选择横向扩展文件格式,而是集中技术资源提升 PDF 和图像这两种核心格式的解析准确率。此外,团队搭建了一个公开的测试平台,允许用户直接上传难以处理的复杂 PDF 进行测试,直观的解析结果帮助他们有效转化了早期客户。在积累了一批对精度要求较高的客户后,Reducto 才开始逐步扩展支持的其他文件格式。
值得注意的是,早期 Reducto 没有开放自动化的自助注册,也没有专职销售团队,而是由创始人逐一进行客户接入。这种方式既便于深入了解客户需求,也有助于在初期控制系统流量,保证 infra 的稳定性。
04.
为什么客户为 Reducto 买单?
Reducto 采用按页计费的 API 使用量定价模式(usage-based pricing),定价分为标准解析与高精度解析两档。企业客户通常签订年度合同并享受折扣,中小客户则按月按量付费。
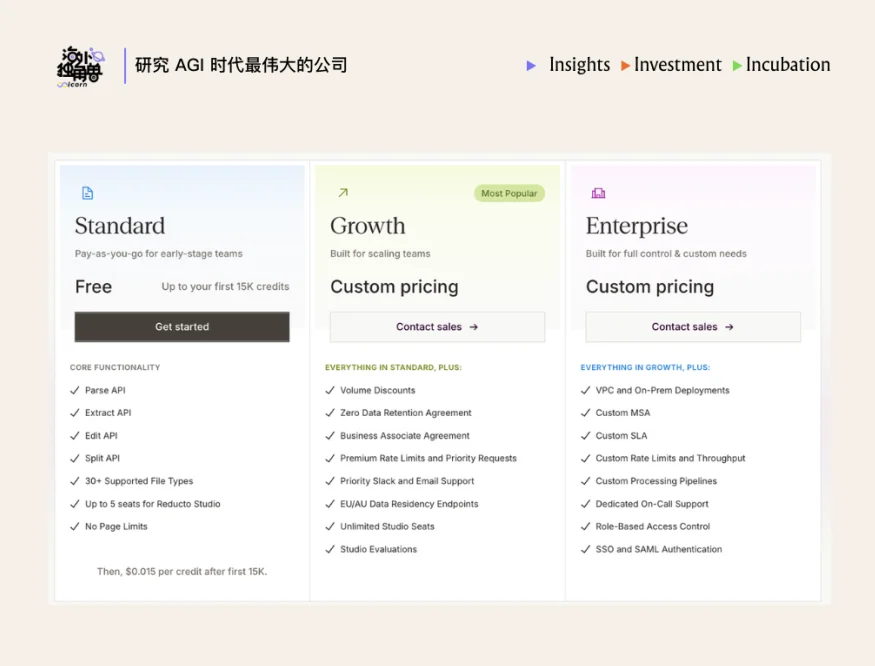
目前 Reducto 的客户覆盖面非常广,主要可以分成以下三类:
• 垂直领域的 AI native 公司,例如法律科技领域的明星公司 Harvey、Legora,以及金融领域的 Rogo 等,这类客户通常对 domain knowledge 的要求非常高,对数据解析的准确性、结构化能力以及对复杂文档格式的支持要求都非常严格。
• 数据标注或 LLM 数据 infra 公司,例如 Scale AI、Mercor 等。随着模型对训练数据的质量标准的提高,这类客户对数据处理的标准也不断提高。
• 全球头部企业巨头,包括 FAANG 级别的科技巨头、财富前十(Fortune 10)的顶级企业,以及全球规模最大的几家对冲基金。

从处理量来看,CEO 在访谈中表示,截至 2025 年 10 月,Reducto 的累计处理页面量较半年前增长约 157%,同时月处理量较 2025 年 6–7 月增长 5 倍。
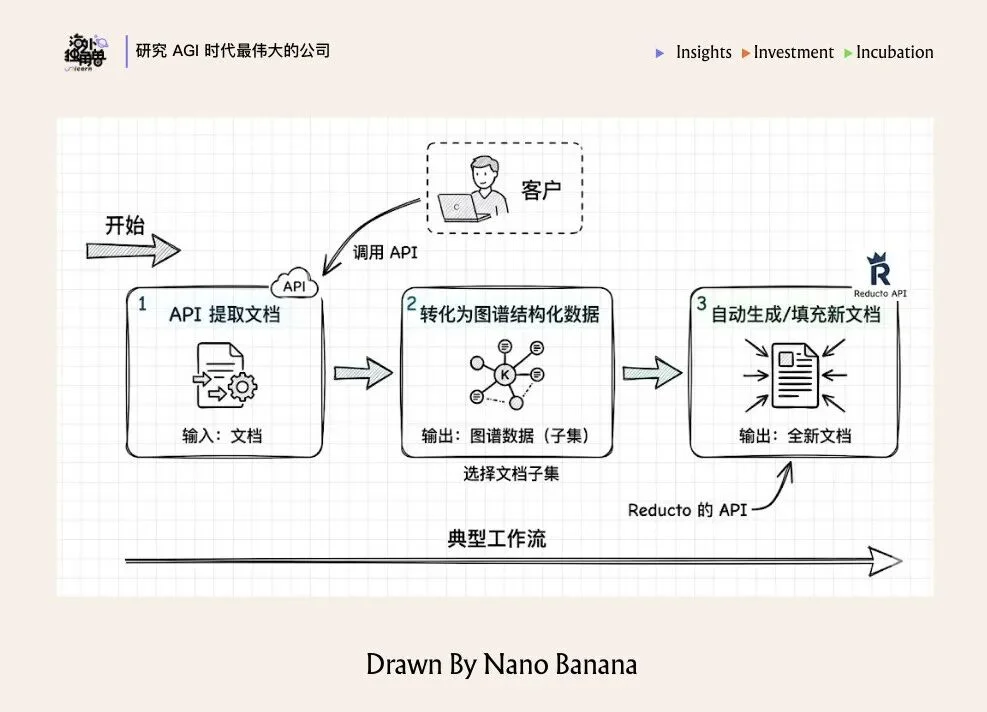
典型工作流和 use case
目前有高达 40% 的客户会同时使用 Reducto 的两个或多个 API 端点构建工作流。典型工作流是:客户首先调用 API 提取文档,然后将文档的子集转化为“图谱结构化数据”,最后再利用这些结构化数据,通过 Reducto 的 API 自动生成/填充一份全新的文档。
Reducto 早期在医疗、金融、保险和法律四大领域获得了大量业务,因为这些行业对数据提取有着“零错误容忍”的极高要求,随着业务拓展,Reducto 目前已经深入到了各行各业:
• 金融投资:全球规模最大的对冲基金之一利用 Reducto 一次性解析 PB 级别的历史研报和文档资产,将分析师十几年积累的庞大非结构化数据,转化为可供 AI 检索与推理的数字金矿。
•供应链与企业运营:物流供应商使用 Reducto 处理格式极度混乱的提货单和采购清单。这类单据自由度极高,员工甚至常把表格当 Word 随意排版填词,而 Reducto 仍能精准提取出结构化信息。
• 教育科技:客户利用 Reducto 读取学生用手机拍下的家庭作业,即使是字迹极其潦草且包含复杂数学方程式的照片,也能被成功解析,为下游 AI tutors 提供高质量的数据摄入。
•冷门场景:有客户直接使用 Reducto 解析高度专业且复杂的“土壤分析实验室报告”。这种超乎团队测试预期的偏门用例,在未经专门定制训练的情况下,依然达到了最佳解析效果。
05.
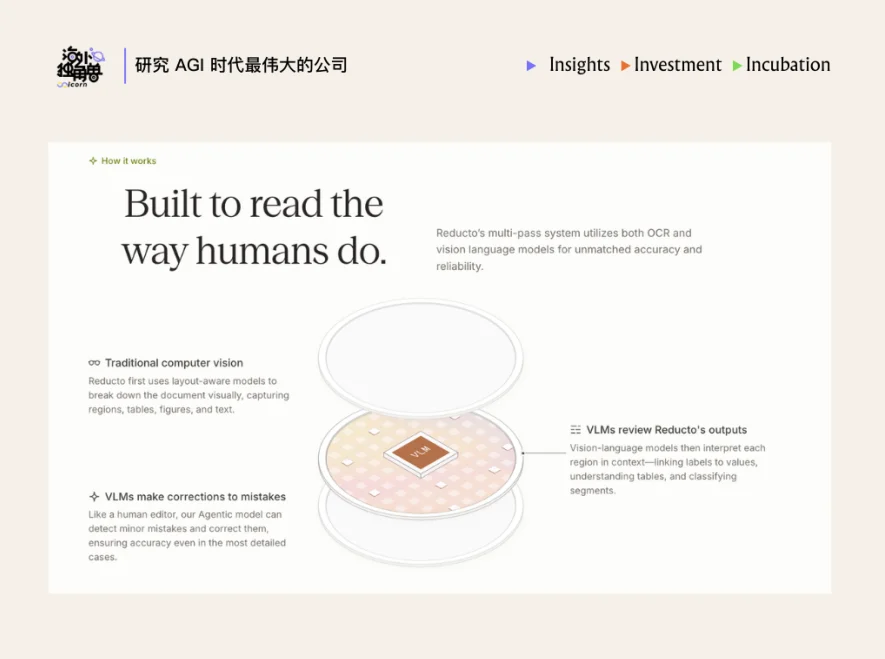
Agentic OCR 如何实现极高的识别精度?
为了保证数据提取的极致准确率,Reducto 摒弃了传统的“单次提取(Single-shot)”路线与端到端模型,转而构建了一种全新的三层混合架构:
1. 基于计算机视觉的版面解析:系统首先从视觉上对输入的 PDF、扫描件或电子表格进行分割,模型会精准识别出表格、标题、图表、文本块等不同区域,并提取保留所有视觉区块的空间坐标。
2. VLM 的上下文审查:在完成视觉分割后,系统会调用专门的 VLM 来结合上下文解释每个区块。VLM 会赋予区域文本标签、语义含义及层级关系(例如分析表格的合并单元格、提取图表数据或链接表单键值对),并为提取的内容输出初始的置信度评估分数。
3. Agentic OCR 多轮自纠错引擎:这是 Reducto 最核心的技术壁垒。当第二层输出的置信度低于既定阈值时,Agentic OCR 会在后台触发自动化的审查与重新处理循环。系统会调整版面假设或切换提取策略,通过递归对齐不断修正错位、幻觉等错误,直到结果通过最终验证。
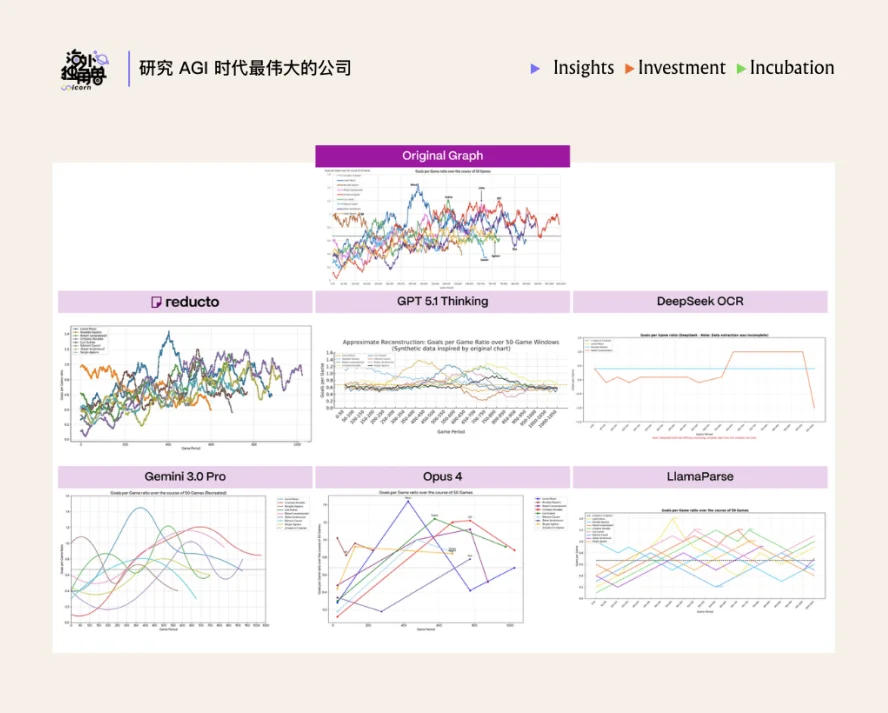
在这套强大的三层架构支撑下,Reducto 攻克了行业内两大极具挑战的技术盲区:
• 复杂图表的提取
为了解决精确提取复杂图表信息,比如金融研报中布满拐点的折线图,在 Agentic OCR 阶段,Reducto 在提取数据后,会在后台重新渲染出图表,并与原图进行交叉比对,反复修改错误的数据点,直到专门的验证模型(Verifier model)判定结果合格为止。同时,为避免验证模型在微小误差上陷入循环,Reducto 采用组件级多模型协同:训练多个轻量模型分别解析坐标轴、刻度、图例和数据序列,再统一对齐,从而在保证精度的同时提升稳定性。
CEO 表示,虽然这种机制模拟了人类审查员的工作流,在一定程度上牺牲了处理速度并增加了系统延迟,但这是目前业内唯一能让机器提取的图表数据真正达到“商业可用”级别的解决方案。
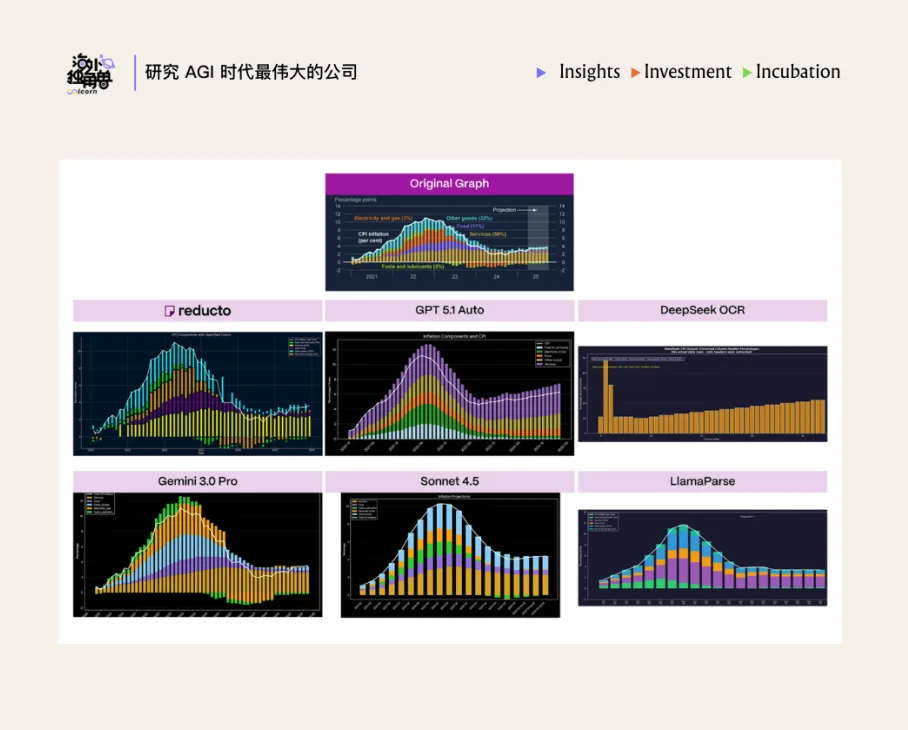
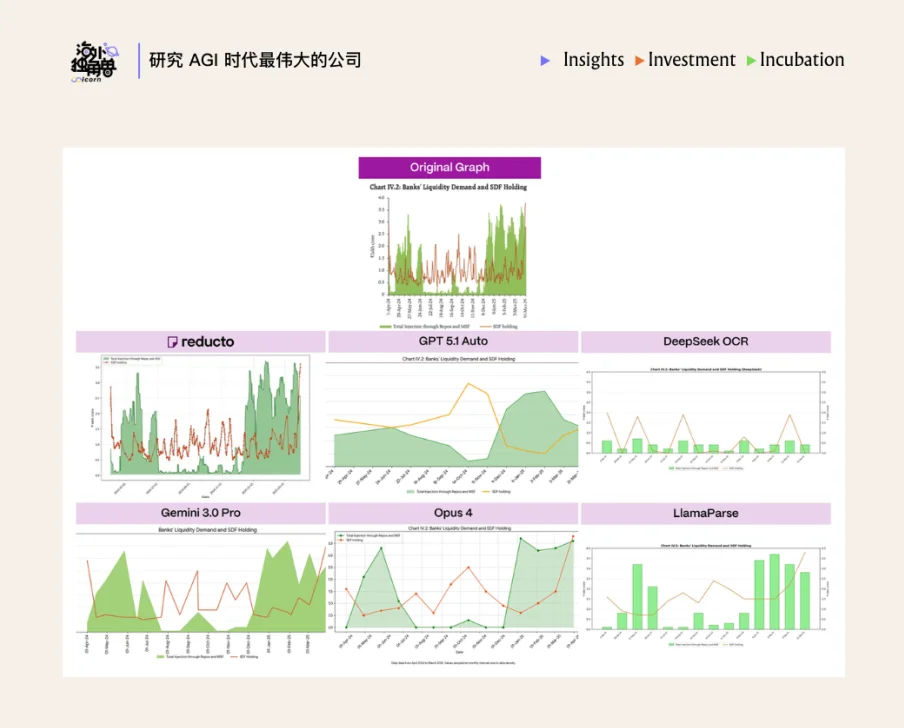
• 电子表格的解析
现实中的 Excel 和 CSV 往往结构混乱,空列、缺失值或随意排版让计算机难以判断表格边界,因此,传统的硬编码规则(例如“遇到空白就切分”)根本无法应对这种自由度极高的数据结构。Reducto 选择通过第一层的版面感知能力与第二层的 VLM 语义理解结合,能够在没有任何排版规范提示的情况下,依然能够精准地拆分、关联和解析极度混乱的电子表格。
06.
Reducto 的竞争优势是否长期存在?
文档解析市场的竞争激烈,目前 Reducto 的竞争对手可以大致划分为以下四类:
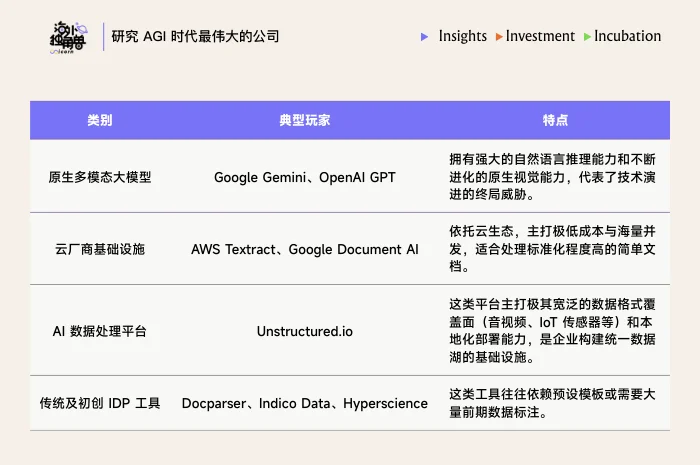
综合来看,虽然 Reducto 凭借在复杂文档解析上的极致精度成功切入市场,但 Reducto 的竞争优势是否可持续是一个很难回答的问题,也是公司今天面临的最大挑战。
• 在复杂文档场景(扫描件、手写内容、复杂表格、多栏排版、专业符号),Reducto 的护城河在近期内仍然稳固。这类文档在医疗、政府、法律、金融等监管行业中大量存在,而这些行业的数字化转型周期漫长,短期内不会消失。
• 但在更广阔的简单文档场景(电子生成的 PDF、格式规整的财务报表),基础模型的威胁已经是现实。随着多模态 LLM 能力的持续提升,Reducto 在这一细分场景的差异化空间将持续收窄。
模型的多模态能力提升
这是 Reducto 长期生存的最大变量与直接威胁。随着基础模型多模态能力的飞速迭代,“单独提取文本”这种简单文档场景正面临被模型原生能力彻底商品化的风险。
比如,金融软件公司 Ascend 发现,直接使用 Google Gemini 2.5 Flash 处理文档的准确率比 Reducto 高出约 30%,且成本便宜了 20 倍,在延迟上,两者也相对接近,因此他们正在考虑在未来完全替换掉 Reducto。
但 Reducto 现阶段的生存空间和护城河,其实是建立在复杂文档场景以及企业实际应用大模型时的“工程泥潭”之上。Ascend 产品负责人也提到,虽然直接调用大模型 API 成本低,但这意味企业需要自行构建庞大的预处理和后处理管线。例如,面对一份 100 页的长文档,企业需要自己编写代码进行分块并发处理;同时还要处理大模型的幻觉问题,针对低置信度的数据或错误的输出格式进行手动清洗。
对于敏捷的初创团队,搭建这套管线可能需要 2 到 3 周的开发时间,但对于有着严格合规和安全审查的大型企业而言,自行拼凑、测试并持续维护这套管线往往需要数月的时间,并且每次底层模型版本更新都需要重新适配。因此,相比之下,Reducto 的价值在于它作为一个“开箱即用”的黑盒编排层,可以将这些繁琐的脏活累活全部封装,方便企业使用。
比如医疗初创 Docsum 的 CEO 就提到,如果不使用 Reducto,他们需要耗费至少 0.5 个全职工程师去搭建日志、排查解析错误和维护内部工具,这相当于每年至少 $75000 美元的隐性人力成本,因此虽然 Reducto 的 API 调用费昂贵,但总体拥有成本(TCO)还是有性价比的。
云厂商基础设施
传统云厂商是 Reducto 最常被拿来对比的玩家,也是绝大多数企业在引入 Reducto 之前使用过的工具。在客户访谈中,几乎每一位受访客户都曾评估或使用过 AWS Textract 或 Google Document AI。
面对这类玩家,Reducto 的核心劣势在于极其高昂的定价。Scale AI 的团队成员在访谈中提到,Reducto 的处理成本大约是 Textract 的 10 倍(Textract 需要花费约 1 美元处理 1000 页,而 Reducto 需要花费约 1 美元处理 100 页)。对于只需处理海量简单标准化文档的基础业务,Reducto 高昂的溢价往往被企业视为缺乏性价比。
然而,云厂商工具在面对复杂排版时往往表现不佳。当文档中包含嵌套表格、合并单元格、缺乏网格线的财务报表或多栏学术论文时,Textract 等传统 OCR 极易丢失数据的空间层级和结构逻辑,输出毫无关联的纯文本乱码。数字医疗公司 eHealth4everyone 的研究员指出,Reducto 在结构化 JSON 输出的质量上远超 AWS Textract 和 Nanonets,极大地简化了下游的语义检索工作。
AI 数据处理平台
在这一领域,Unstructured.io 是 Reducto 最强劲的对手。
但两者的竞争并非完全的零和博弈,而是有“广度”与“精度”的路线区别:Unstructured.io 覆盖了极其广泛的数据类型,包括音频、视频、HTML 甚至是 IoT 传感器数据。而 Reducto 则战略性地放弃了广度,将技术资源全部倾注于文本、复杂 PDF 和表格解析的极致精度上。
在大型企业的实际部署中,这种差异直接促成了“混合管线”的架构。
• Scale AI 将开源版本的 Unstructured.io 作为首轮路由处理器(First-pass processor),用于广泛的基础数据处理,将包含复杂表格、脚注和图像的困难多模态文档(如 PDF、PPT)专门分流给 Reducto,以获取最高保真度的结构化提取结果,随后再存入向量数据库。
• 全球最大啤酒酿造商 AB InBev 的全球分析总监认为 Reducto 是“福特”,高效、性价比高,而 Unstructured.io 是“法拉利”,技术更全面,能处理文本、图像、音频、视频、IoT 传感器数据等 50-100 种格式,但相比之下,价格更贵。他们的策略是用 Reducto 覆盖 70-80% 的纯文本场景,用 Unstructured.io 处理剩余的多模态复杂场景,并计划在 12 个月内将 Reducto 扩展至所有文本工作流,到那时 Reducto 的预算占比将从 15% 翻倍至 25%。
传统及初创 IDP 工具
与 Docparser、Indico Data 等文档处理工具相比,Reducto 在开发者友好度和灵活性上更具优势。Indico Data 往往需要用户提供大量带标签文档进行模型微调,冷启动较慢;而 Reducto 可通过 prompt 直接定义字段与格式,在无需专门训练的情况下提取复杂版面信息。医疗软件公司 Medallion 的测试显示,在低质量扫描件和复杂文档场景下,Reducto 的解析准确率比 Docparser 高约 20%。
此外,Reducto 团队提供了“白手套”级客户支持,在竞争中赢得了极高的企业信任度,比如 Reducto 会直接在企业客户的 Slack 频道中进行分钟级技术响应。
07.
团队与融资
Reducto 由 Adit Abraham 和 Raunak Chowdhuri 于 2023 年联合创立。团队非常精简,截⾄ 2025 年 4 ⽉,公司 ARR 已突破百万,但当时全职员⼯仅有 4 ⼈。B 轮融资后,团队规模仍维持在 12 ⼈左右。团队绝⼤多数成员为⼯程师和研究员,很⻓⼀段时间内,Adit Abraham 都是唯⼀的销售⼈员。

• Adit Abraham (Co-Founder & CEO)
Adit Abraham 2022 年本科毕业于 MIT,主攻机器学习。他曾在 Google 担任产品经理,负责搜索与广告业务,再之前在 MIT Media Lab 以及初创公司 BlinkAI 担任机器学习研究员。此外,他还曾创立了 Sidewalk。作为 CEO,他不仅把控公司愿景,还展现出极强的企业级销售落地能力,在公司极早期就凭借“白手套”服务成功拿下了 Fortune 10 级别的头部客户。
Sidewalk 是由 Adit Abraham 在 MIT 时创立的一家公司,主要做电商合作与交叉销售平台,帮助面向相似客群的品牌建立合作关系,在结账或购买流程中推荐彼此的产品,从而增加订单价值和获客渠道。
• Raunak Chowdhuri (Co-Founder & CTO)
Raunak Chowdhuri 2024 年本科毕业于 MIT,专业方向为 AI 与机器人技术。他在计算机视觉领域发表过学术论文,获得了过百次的学术引用。在创立 Reducto 之前,他曾担任计算化学初创公司 Oloren AI 的 CTO,并在 MIT 无人驾驶感知团队担任 ML 研究员,以及在 MIT 林肯实验室担任 ML 顾问。
目前 Reducto 共完成了四轮融资,累计融资金额达 1.084 亿美元。Y Combinator、Benchmark、BoxGroup 和 First Round Capital 等老股东都参与了多轮融资,CEO 表示公司两年内实际消耗资金其实不到 800 万美元,B 轮时银行账户仍有超过 1 亿美元现金。
文章来自于微信公众号 “海外独角兽”,作者 “海外独角兽”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
