# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

最近几天,开发者圈接连出现炸弹。
今天凌晨,有开发者在X上发帖说Codex桌面版太猛了,自己彻底弃用了十多年的老编辑器。
Brockman秒回:「是的,我也是。」
谁能想到,就在同一天,Anthropic来了一发更大的:
Claude Opus 4.6和Sonnet 4.6的百万token上下文窗口,正式全面上线。
没有beta标签,没有长文本溢价,没有速率限制歧视。
90万token的请求和9000 token的请求,每个token价格一模一样。
一边是OpenAI总裁亲手埋葬旧时代的编辑器,一边是Anthropic把AI的「工作记忆」一口气撑到100万token。
AI编程的军备竞赛,刚刚换上了全新的弹药。
是的,Anthropic又双叒上新了,速度简直快到让人反应不过来。
你能相信,自从2026以来,Anthropic的发布是这个节奏吗?
下面这张梗图,简直太形象了。
Claude获得100万token的上下文窗口,意味着什么?
从此,它可以一次性理解庞大的代码库,处理海量研究论文和数据集,推理冗长的对话和文件,保留更多上下文信息,同时避免遗漏。
同时,它还可以管理Vibecoding的整个项目,还能更快地解决漏洞和错误。
一句话总结就是,Claude凭借一己之力,撑起了整个经济体!

这次更新,到底炸在哪?
先说一个直觉。
100万token,大约相当于750万个英文单词,或者一整套《哈利·波特》系列的7倍。
但对于开发者来说,这个数字的含义要具体得多。
它意味着你可以把一整个代码库、数千页的合同文件、或者一个长时间运行的AI智能体的完整执行轨迹(包括所有的工具调用、观察结果和中间推理过程),一股脑塞给Claude,然后直接开始工作。
不需要分块,不需要摘要,不需要费尽心机地管理上下文窗口。
过去,Claude只有20万token的上下文窗口。开发者不得不手动挑文件、做有损摘要、不断清理对话历史。
如今,Anthropic用百万级的上下文窗口把这扇门彻底拆掉了。
但窗口撑大只是第一步。
真正的问题是:塞进去100万token,模型还能记住里面的细节吗?
因为,很多模型虽然宣称支持超长上下文,但在实际推理中会出现一个问题——信息遗忘。
也就是说,虽然模型「看到了」内容,但无法在推理时正确检索。
Anthropic在进行了一番测试后发现,答案是,能!
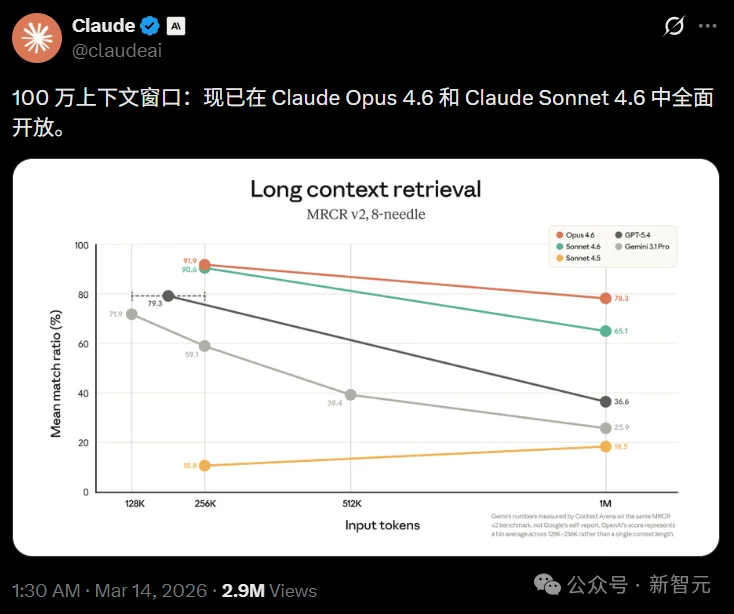
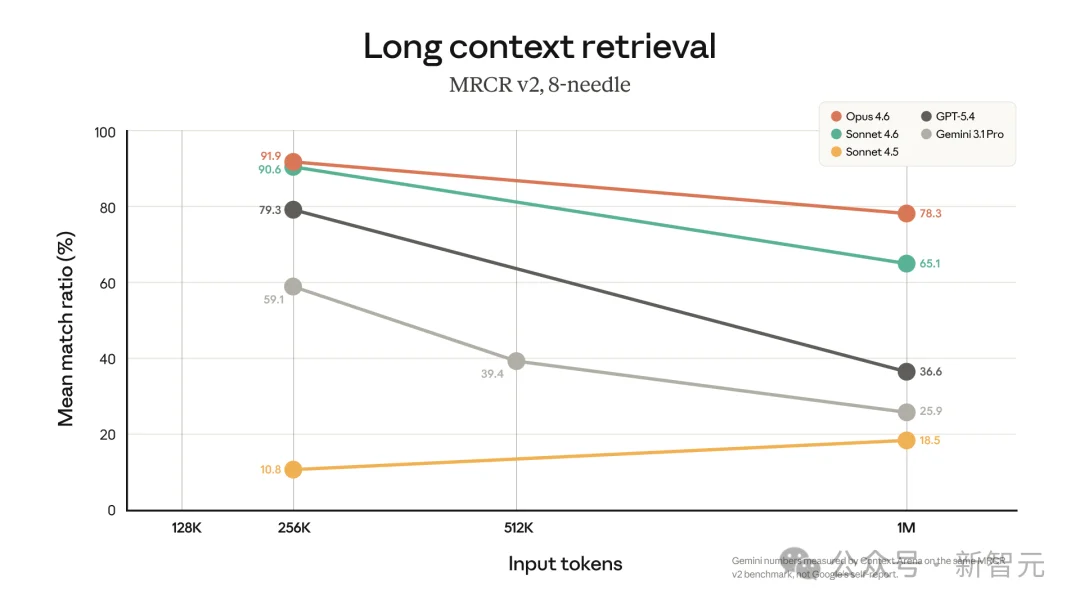
在专门考验超长文本「大海捞针」能力的MRCR v2测试中,Opus 4.6拿到了78.3%的高分,同等上下文长度的前沿大模型中排名第一。
这意味着模型可以在海量上下文中找到关键细节,正确关联信息,从而进行复杂推理。
作为对比,上一代的Sonnet 4.5在同一个测试中只拿到了18.5%。
定价也是杀手锏
这一次Anthropic在定价上打出了一张极其凶狠的牌:统一价格,零溢价。
在最新公告中,Anthropic宣布:Claude Opus 4.6与Sonnet 4.6现在都支持完整的1M token 上下文窗口,并且不再收取长上下文溢价,完整速率限制可用,而且无需Beta Header。
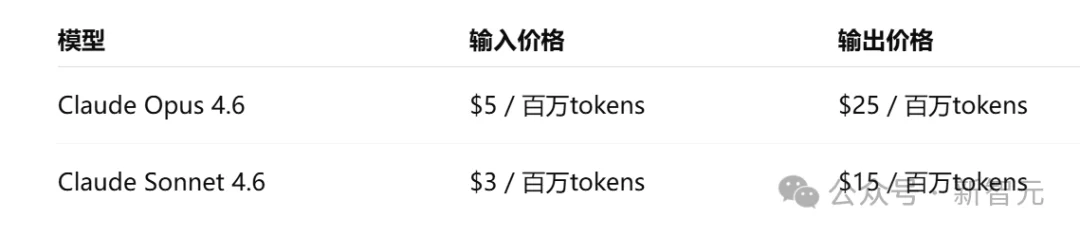
Opus 4.6每百万token输入5美元、输出25美元,Sonnet 4.6输入3美元、输出15美元,全窗口一口价。
此前beta阶段,超过20万token的请求输入价格翻倍、输出乘以1.5倍,很多团队因此只能偶尔尝鲜。
现在这个门槛彻底没了,长上下文从奢侈品变成了标配。
横向对比来看:
除了价格,这次GA还带来了一系列实打实的体验升级。
输入能力大幅提升:600张图片或PDF
除了文本长度,Claude这次还扩展了多模态输入能力。
单次请求最多支持600张图片或600页PDF。相比之前的100个媒体文件,直接提升了6倍。
这意味着一整套设计系统的截图、一份长达数百页的合同扫描件,都可以一次性塞进去。
而且,这项功能已在Claude原生平台、微软Azure Foundry和谷歌云Vertex AI同步上线。
这就意味着企业用户可以直接在云平台上调用。
与此同时,计费与速率全量打通。
过去beta阶段,长上下文请求有时会遭遇更低的速率限制,现在这个歧视没了。不管请求多长,标准账户的吞吐量额度在整个百万窗口内完全适用。
开发者体验,也被简化了
还有一个很受开发者欢迎的大更新,就是超过20万token的请求自动生效,不再需要添加beta请求头。
过去使用百万上下文,需要额外配置:
anthropic-beta: 1m-context
现在,这一过程已经被取消,超过200K tokens的请求,会自动启用长上下文能力。
如果代码里仍然保留旧的 Beta Header,系统会自动忽略,不需要修改代码。
这一点看似小改动,但对于开发者来说非常重要。
因为它意味着,百万上下文已经从「实验功能」变成默认能力!
长对话终于不再被压缩
对Claude Code用户来说,变化更直接:
百万上下文现在已内置于Max、Team和Enterprise版本的Opus 4.6中,会话会自动调用完整窗口,不再消耗额外额度。
更关键的是,这大幅减少了上下文的强制压缩次数。
过去用户一加载大型PDF、数据集或图片,系统就不得不压缩上下文,丢掉的恰恰是最重要的工作内容。
如今,Anthropic已将上下文压缩事件减少了15%。
AI编程大战,正在进入白刃战
Claude百万上下文的正式上线,不是孤立事件。它发生在AI编程赛道竞争最白热化的时刻。
就在几天前,WIRED杂志发了一篇重磅长文,标题直接捅破窗户纸:《揭秘OpenAI追赶Claude Code之路》。
没看错,在AI编程这条万亿美元赛道上,OpenAI是追赶者。

故事充满戏剧性。
OpenAI早在2021年就有了Codex项目,Brockman当时就说「你拥有了一个可以执行命令的系统」。
但ChatGPT在2022年底横空出世,两个月狂揽1亿用户,所有资源被抽调,Codex团队直接拆散。
此后整整几年,OpenAI没有专门的团队做AI编程产品。
相比之下,Anthropic则一头扎进了编程赛道。
结果呢?
Claude Code年化收入超过25亿美元,Codex到2026年1月底刚过10亿美元。
2025年9月Codex的使用量只有Claude Code的5%,到2026年1月飙到40%。
追赶速度惊人,但差距依然巨大。
OpenAI中间还试图以30亿美元收购AI编程初创公司Windsurf来弯道超车,结果微软横插一杠想要知识产权,交易冻结数月后告吹。
Google趁机挖走Windsurf创始人,剩余团队被Cognition收编。
Altman的回应倒是坦然:「你不可能掌控每一笔交易。」
当程序员不再写代码
更狠的变化,正在每一个开发者的工位上发生。
WIRED记者在OpenAI总部旁观了一场Codex黑客松。
100号工程师,四个小时,全部用Codex搓Demo。搁以前得花几天甚至几周的项目,一下午齐活。
而百万上下文窗口,会把这一切推向更极端的地步。
首批用户的反馈已经很说明问题。
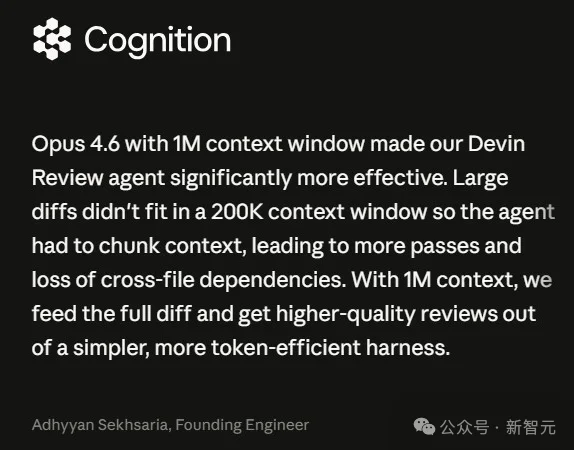
Cognition的创始工程师Adhyyan Sekhsaria说得很直白:
大型代码差异以前根本塞不进20万token的窗口,智能体不得不分块处理,导致跨文件的依赖关系丢失。
而百万级的上下文让他们可以一次性喂入完整的diff,用更简单的架构获得了更高质量的代码审查。
企业支出管理平台Ramp的工程师Anton Biryukov描述了一个更有画面感的痛点:
Claude Code在搜索Datadog、数据库和源代码时,一口气能烧掉10万多个token,然后上下文压缩一启动,细节就没了。
相当于,你是在原地打转地debug。
而有了百万上下文之后,搜索、聚合边界条件、提出修复方案,在一个窗口里就能全部完成。

法务协作平台GC AI的CTO Bardia Pourvakil的说法更直观:
企业内部律师终于可以把五轮谈判的100页合伙协议全部塞进一个会话,看到完整的谈判弧线,不用再在不同版本之间来回切换。

最反直觉的发现来自数据分析平台Hex,他们把Opus的上下文窗口从20万提升到50万之后,智能体不仅没有消耗更多token,反而整体用量更少了。

更大的视野带来了更高的效率,AI不再需要反复搜索和重建上下文,一次看全,一次搞定。
开发者的角色,正在被重新定义
Brockman的感悟,让我们深刻理解这场变革的含义。
他说,不再需要亲手写代码「让人无比自由,大脑终于卸下了一堆不必要细节的重担」。
但话锋一转,当你变成「这支由几十万个智能体组成的庞大舰队的CEO」时,「你就不再像以前那样,扎在泥里去弄清楚每个具体问题到底是怎么被解决的了。」
这种感觉,就像是「正在失去对解决问题最敏锐的那种脉搏感知」。
市场已经用真金白银投了票。
《华尔街日报》把上个月1万亿美元的科技股大跌归因于Claude Code。
Anthropic宣布能翻新IBM大型机上的COBOL遗留系统后,IBM股价迎来25年来最黑暗的一天。
如今,当AI的记忆不再有天花板,开发者的工作方式就被彻底改写。
你猜,下一个要被Anthropic颠覆的领域,是哪一个?
参考资料:
https://x.com/gdb/status/2032514978599600295
https://claude.com/blog/1m-context-ga
https://www.wired.com/story/openai-codex-race-claude-code/
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
