# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
MLRA通过拆分KV缓存为四个并行分支,显著降低显存占用并实现4路张量并行。推理速度比MLA最高快2.8倍,支持百万级上下文,且模型质量更优。无需牺牲性能,即可高效扩展长文本处理能力。
随着大语言模型(LLM)越来越多地应用于长文本任务——如检索增强生成(RAG)、多步思维链(CoT)推理以及超长对话——在每个解码步骤中必须处理的token数量显著增加。
其核心问题在于:自回归生成(Autoregressive Generation)受限于显存带宽(Memory-bound),而非计算能力(Compute-bound)。
在每一个解码步中,模型必须将整个Key-Value (KV) 缓存从片外存储(如HBM)重新加载到片内存储(如SRAM)中,这种数据搬运主导了推理延迟,从而导致解码过程总 GPU 利用率低下。
在标准的多头注意力(MHA)机制下,KV缓存的大小随注意力头数、头维度以及序列长度线性增长。当上下文长度超过10万(100K)个token时,KV缓存会迅速演变成一个严重的性能瓶颈。
为了减少KV缓存的开销,业界已经尝试了多种方法:
MLA(Multi-Head Latent Attention)通过低秩压缩将隐藏状态映射至单一的潜在向量(Latent Head),并在推理时仅需缓存该潜在向量,极大地降低了KV Cache的显存占用。
在解码阶段,通过将Key的上投影矩阵(Up-projection Matrix)吸收(Absorb)到Query中,可以避免显式生成(Materialize)所有注意力头的完整Keys和Values
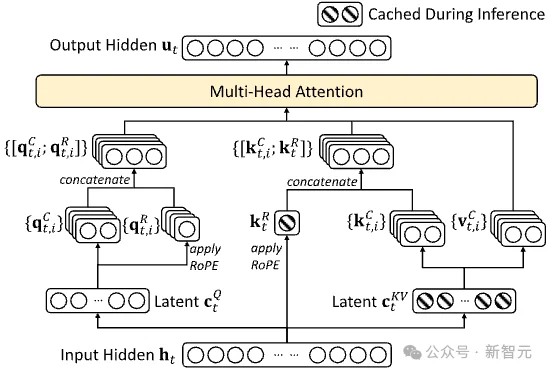
然而,MLA的设计存在两个关键缺陷:
张量并行(TP)受阻:由于采用单一潜在向量架构,其KV Cache无法在多个计算设备间进行切分,迫使SGLang等开源推理框架只能采用数据并行(DP)模式处理MLA解码,导致模型权重在各设备间冗余存储,无法实现高效的张量并行解码。
可扩展性与架构适配受限:矩阵吸收后,MLA的解码在算子层面等效于一个超大维度(如576维)的MQA(Multi-Query Attention)。
由于GPU片上资源(如SRAM)难以支撑极大的单头维度,导致其难以进一步扩展Latent Dimension,也是目前FlashMLA等高性能kernel主要局限于NVIDIA Hopper架构(H100/H200)的原因。
宾夕法尼亚州立大学、康涅狄格大学、卡内基梅隆大学、加利福尼亚大学洛杉矶分校的研究人员提出的MLRA (Multi-Head Low-Rank Attention) 提供了一个巧妙的代数视角:将原本的一个大矩阵运算,拆解为四个独立的小块运算。

论文: https://arxiv.org/pdf/2603.02188
博客: https://SongtaoLiu0823.github.io/mlra
代码: https://github.com/SongtaoLiu0823/MLRA
数据与权重: https://huggingface.co/Soughing/MLRA
研究人员将原本4倍维度的 KV 潜在向量逻辑上划分为四个相等的子块。与其对应的权重矩阵也相应地垂直切割为四个块。
物理含义:现在的Key和Value不再被视为一个不可分割的整体,而是四个子块投影结果的累加。
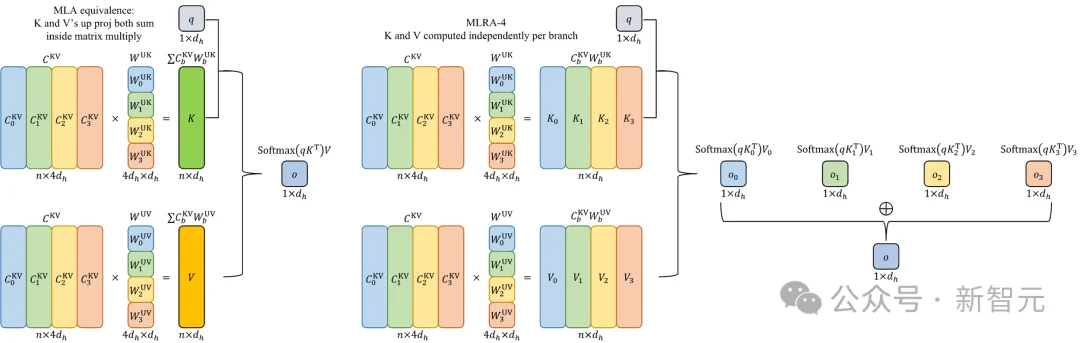
这是MLRA最关键的改进。
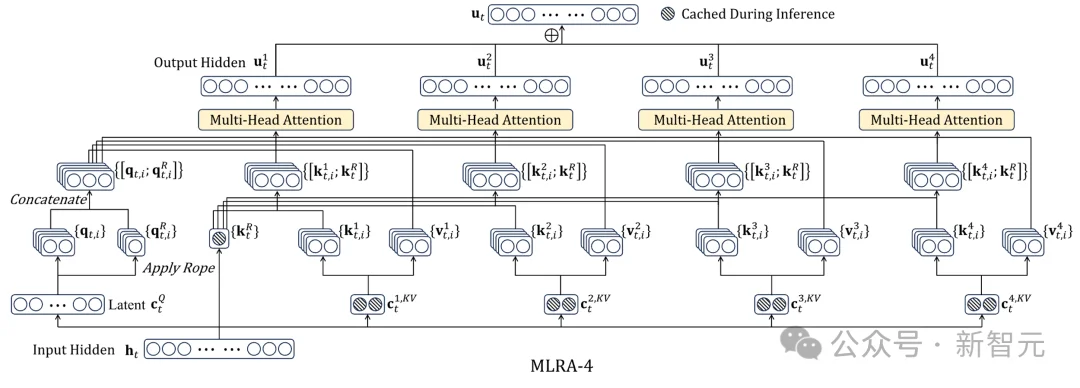
在工程上实现了彻底的解耦:
研究人员将MLRA与一系列全面的基准模型进行了对比,包括MHA、MQA、GQA、MLA、MFA10、TPA11、GLA-2、GLA-4以及GTA12。所有模型均在Llama-3架构下,使用来自FineWeb-Edu的983亿(98.3B)token从零开始训练,参数规模均为29亿(2.9B)。
为确保公平比较,通过调整FFN的中间层维度,使所有模型的参数量保持一致。
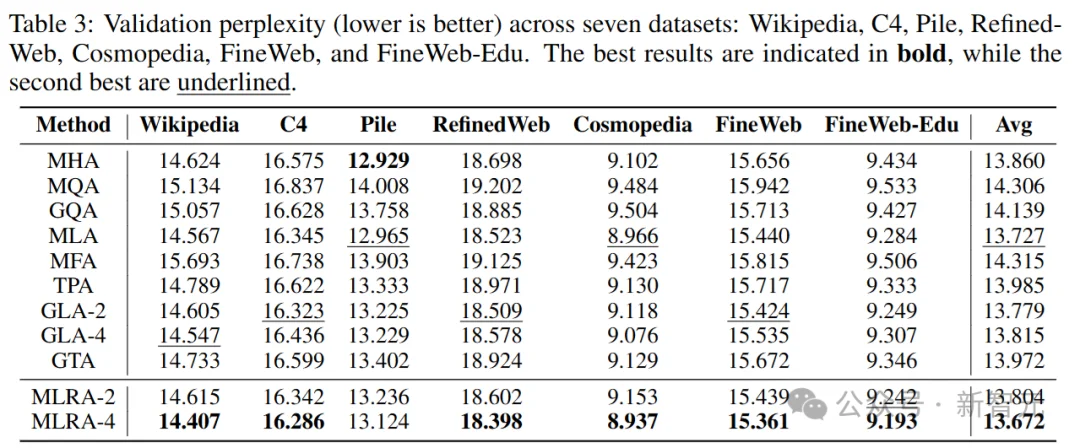
验证集困惑度 (Validation Perplexity)
研究人员评估了在Wikipedia、C4、Pile、RefinedWeb、Cosmopedia、FineWeb和FineWeb-Edu这七个数据集上的困惑度。
主要发现如下:
常识推理能力
研究人员在七个常识推理基准测试(ARC-E/C、OpenBookQA、BoolQ、HellaSwag、Winogrande和PIQA)上进行了零样本(Zero-shot)性能评估。结果与困惑度的测试发现高度一致:
MLRA-4在所有对比的注意力变体中,取得了最高的平均零样本准确率。
解码速度 (Decoding Speed)
研究人员在单块NVIDIA H100 80GB GPU上,针对128K到2M不等的上下文长度测试了单序列解码延迟。MLRA-4基于FlashAttention-3实现,而MLA则使用官方的FlashMLA内核。
解码吞吐量 (Decoding Throughput)
研究人员在8块H100 GPU上评估了批量解码吞吐量(隐藏层维度 7168,参考 DeepSeek-V3 设置)。部署策略如下:MLA采用DP=8;GLA-2采用TP=2/DP=4;MLRA-4采用TP=4/DP=2;GQA采用TP=8
至关重要的一点是,MLRA具备极佳的可扩展性!
在MLA中,增加KV潜在头维度(latent-head dimension)往往会导致高性能解码kernel 难以部署;而在固定的激活值/参数预算下,单纯增加头数可能会降低模型质量。相比之下,MLRA的多分支低秩架构支持显著更多的头数,同时保持了对张量并行(TP)的友好性和内核执行效率。
研究人员发布了完整的训练代码,数据、预训练权重以及基于FlashAttention-3的高性能解码内核,以方便开发者复现和部署MLRA。
参考资料:
https://arxiv.org/pdf/2603.02188
文章来自于“新智元”,作者 “LRST”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
