# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人的智能能力主要由推理能力和长期记忆能力构成。近年来,大模型的推理能力一直处于快速发展过程,但大模型的长期记忆能力一直受限于上下文长度,无法取得突破。在历史上,曾经有多种路线进行尝试,但都无法突破扩展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。近期,《MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens》的工作进入我们的视野。
文章中提出了一种新的记忆架构,MSA(Memory Sparse Attention),通过记忆稀疏注意力机制、实现超长上下文外推的文档级旋转位置编码(Document-wise RoPE)、KV 缓存压缩与内存并行,以及支持复杂推理的记忆交错(Memory Interleave)机制,实现了 100M 长度的大模型长时记忆框架,在主流的长文本问答、大海捞针等评测上,取得了业界领先的结果。并且,当长度由 16K 增加到 100M 时,模型的得分只下降了 9%,体现了非常强的扩展能力。
这个方法可以看作是大模型的一个记忆插件,为我们解决长期记忆问题提供了一个新的思路和方向。在今天 OpenClaw 引发的 Agent 爆发时代到来之际,这篇文章有望成为开启 “记忆即服务”(Memory-as-a-Service)新纪元的里程碑。

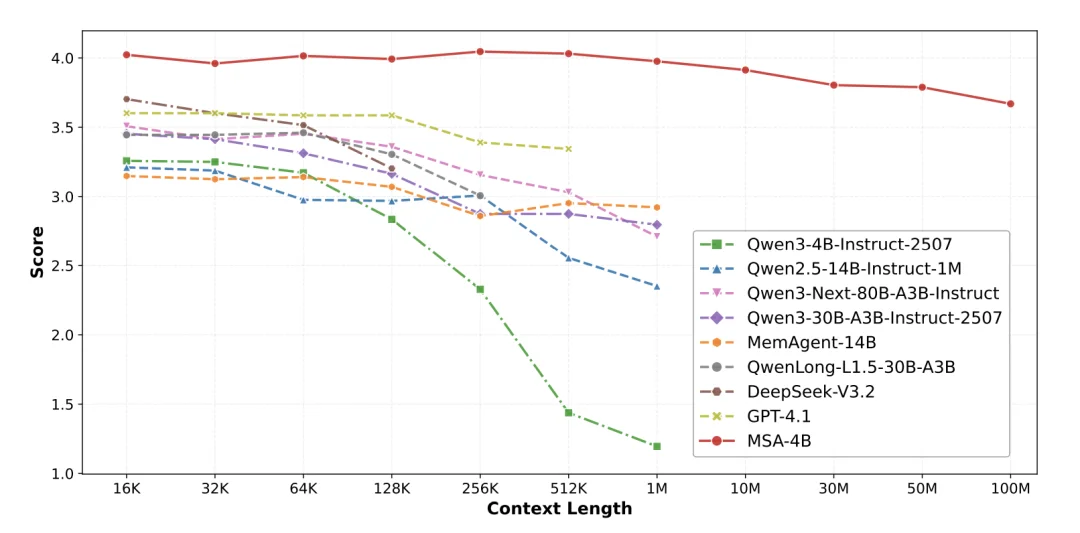
图 1 MSA-4B 的长文本问答得分随上下文长度衰减显著优越(论文原图)
近年来,大型语言模型(LLM)的能力边界不断拓宽,但在模拟人生(Life Long)级别的长时、细粒度记忆方面,始终面临着一道难以逾越的鸿沟。无论是需要通读并理解长篇小说的文学分析,还是要求在多轮对话中保持人格一致性的数字孪生,抑或是需要追溯漫长历史记录的 Agent 系统,都对模型的有效上下文长度提出了近乎苛刻的要求。然而,主流 LLM 受限于全注意力机制(Full Attention)的二次方复杂度,其有效上下文窗口长期被限制在百万(1M)Token 左右,与人类一生约数亿 Token 的记忆容量相去甚远。
为了突破这一瓶颈,学界和业界探索了三条主要的技术路线,但每条路线都在试图解决问题的同时,陷入了新的困境,形成了一个难以调和的 “不可能三角”:
1. 参数化记忆(Parameter-Based Memory):通过持续训练或微调将知识 “烧录” 进模型参数。此方法精度高,但扩展性差,更新成本高昂且易发生灾难性遗忘。
2. 外部存储记忆(External Storage-Based Memory):以检索增强生成(RAG)为代表,将记忆外置于向量数据库。此方法扩展性好,但其 “检索 - 生成” 两阶段分离的非端到端特性,导致检索精度成为性能瓶颈,难以进行深度语义对齐。
3. 潜状态记忆(Latent State-Based Memory):利用模型内部的隐藏状态(如 KV 缓存)作为工作记忆。此方法语义保真度高,但面临着效率与容量的直接冲突。基于 KV 缓存局部保留的方法(如利用 Attention Sinks 机制的 StreamingLLM)精度高但扩展性受限;而基于线性注意力的方法(如 RWKV, DeltaNet)虽然实现了线性复杂度,却因有损压缩而在超长上下文中精度严重下降。
正是在这一背景下,《MSA》一文提出了一个极具雄心的目标:设计一个端到端可训练的、能以线性复杂度扩展至亿级 Token、同时保持高精度的潜状态记忆框架。MSA 的出现,旨在正面挑战并打破上述 “不可能三角”,为 LLM 赋予真正意义上的 “终身记忆”。
MSA 的革命性并非源于单一技术的突破,而是一套环环相扣、系统性的架构创新。这套 “创新栈” 协同工作,共同构成了其高性能的基石。
2.1 核心基石:记忆稀疏注意力 (Memory Sparse Attention)
MSA 的核心思想是在 Transformer 的注意力层引入一种可微分的、基于内容的稀疏化机制。它不再让模型在推理时关注所有历史记忆,而是设计了一个高效的 “路由”(Routing)模块,动态选择最相关的记忆子集参与计算。
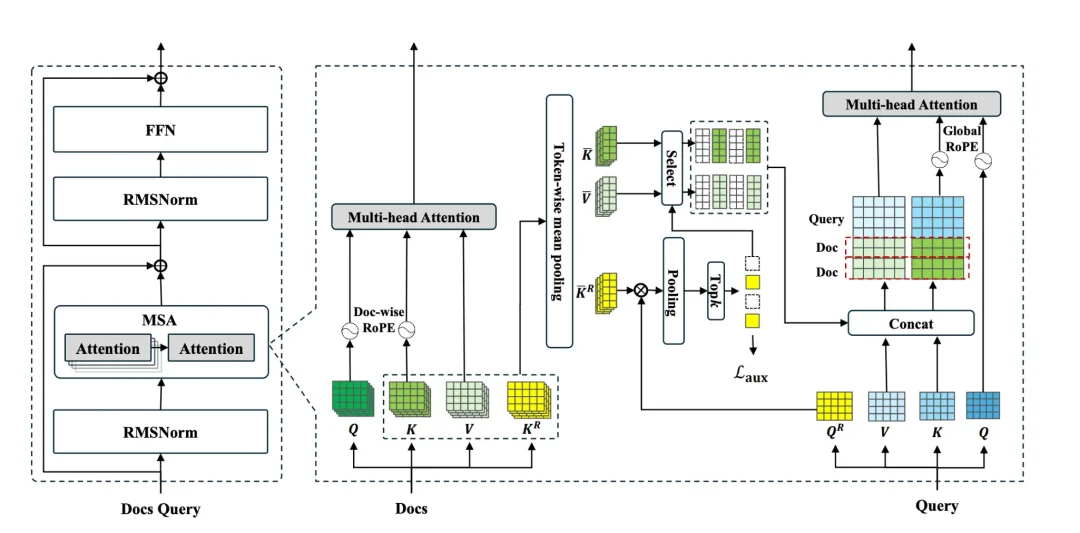
图 2:记忆稀疏注意力架构 Memory Sparse Attention layer(论文原图 )
这张图是 MSA 技术实现的核心,展示了一个高度优化的 Transformer 层如何将海量外部记忆(Docs)与当前查询(Query)高效融合。其流程可分解为左右两个协同工作的模块。
左侧是标准的 Transformer 外壳。 整体上,MSA 层被包裹在一个标准的 Pre-Norm Transformer 模块中。它取代了传统的自注意力(Self-Attention)层,其输出与输入通过残差连接(Residual Connection,图中的⊕符号)相加,随后经过 RMSNorm 归一化和 FFN(前馈网络)层处理。这一设计确保了 MSA 可以作为即插即用的模块,无缝集成到现有的大模型架构中,无需对整体架构进行颠覆性改造。
右侧是 MSA 的 "双重路由" 稀疏注意力机制。 这是创新的核心,通过一个精巧的 "双重路由" 机制,实现了从海量文档中 "优中选优" 的过程,避免了对所有记忆进行暴力全量计算。
这一机制的独创性在于,它将 RAG 系统中的 "检索" 步骤,内化为了一个可端到端训练的神经网络模块。与依赖外部、固定的相似性度量(如向量余弦距离)的 RAG 不同,MSA 的路由器是在训练过程中与生成任务共同优化的(通过一个辅助的对比学习损失 L_aux),这意味着它能学会一种更符合模型内部 "世界观" 的、与最终任务目标更对齐的检索策略。这从根本上解决了 RAG"检索" 与 "生成" 目标不一致的核心痛点,是其实现高精度的关键。
2.2 扩展性关键:文档级旋转位置编码 (Document-wise RoPE)
要实现从较短的训练文本(如 64k)到亿级推理文本的成功外推,一个核心挑战是如何处理位置信息。如果采用传统的全局位置编码,当推理时的文档数量远超训练时,位置索引会发生剧烈偏移,导致模型 “水土不服”,性能急剧下降。
MSA 为此提出了一个简洁而高效的解决方案:为每个独立的文档(或记忆单元)分配一套独立的旋转位置编码(RoPE)。这意味着,无论记忆库中有多少文档,模型在 “阅读” 每个文档时,其内部的 “坐标系” 都是从 0 开始的、稳定不变的。这种设计将文档的内部相对位置与其在全局记忆中的绝对位置解耦,使得模型在训练时学到的位置感知能力,可以无损地泛化到包含海量文档的推理场景中。这正是 MSA 能够实现惊人外推能力(Extrapolation)的理论基础。
2.3 工程化落地:KV 缓存压缩与内存并行 (KV Cache Compression & Memory Parallel)
理论上的可行性必须通过工程实现才能转化为现实。在亿级 Token 的尺度下,即便经过压缩,KV 缓存的存储需求也高达上百 GB,远超单个 GPU 节点的显存容量。MSA 通过一套精巧的 “内存并行” 策略解决了这一物理瓶颈。
这种 “快查(GPU)慢取(CPU)” 的策略,优雅地将存储瓶颈从有限的 GPU 显存转移到了海量的 CPU 内存,使得在标准硬件(如 2 张 A800 GPU)上运行亿级 Token 的推理成为可能。这不仅是工程上的创举,更是该技术能够走向实际应用的前提。
2.4 复杂推理能力:记忆交错 (Memory Interleave)
对于需要整合多个分散在不同文档中的证据才能回答的复杂问题(即多跳推理),单次的 “检索 - 生成” 循环往往力不从心。为此,MSA 引入了记忆交错机制。
该机制允许模型进行多轮次的 “生成式检索 → 上下文扩展” 循环。在第一轮,模型根据原始问题,首先生成它认为最相关的文档 ID 序列;随后,系统获取这些文档的原文,并将其追加到原始问题之后,形成一个新的、更丰富的 “中间问题”;在下一轮,模型基于这个新问题,再次生成新的文档 ID…… 如此循环往复,直到模型认为积累的证据足够充分,便停止生成文档 ID,转而生成最终答案。
这种迭代式的推理链,模拟了人类侦探办案时 "发现线索 A → 顺藤摸瓜找到线索 B → 整合 AB 形成完整证据链" 的思考过程。它赋予了 MSA 动态规划其信息搜集路径的能力,是其在多跳问答(Multi-hop QA)任务上表现出色的重要原因。
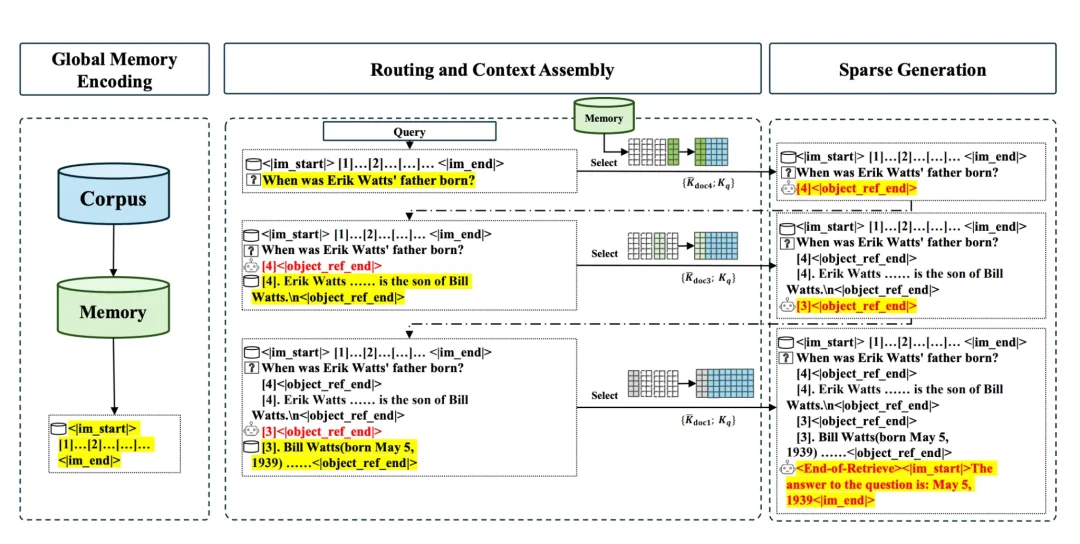
图 3:三阶段流程图 — Three-Stage Inference Process with Memory Interleave(论文原图)
这张图以一个具体的多跳问答案例("埃里克・瓦茨的父亲何时出生?")为例,完整展示了记忆交错机制在推理时的三阶段工作流程。
第一阶段:全局记忆编码(Global Memory Encoding,图左)。 这是一个离线预处理步骤。整个知识语料库(Corpus)被一次性编码,生成一个庞大的 KV 缓存,即全局 "记忆"(Memory)。这个记忆库通常存储在成本更低的 CPU 内存或 SSD 中,等待被实时查询调用。这一阶段的计算成本是一次性的,与后续的推理次数无关。
第二阶段:路由与上下文组装(Routing and Context Assembly,图中)。 这是推理的核心循环,图中以三步迭代为例展示了完整的证据链构建过程。
在第 1 轮迭代中,用户提出初始问题(埃里克・瓦茨的父亲何时出生?)。模型使用这个问题作为 Query,通过 MSA 的路由机制,从全局 Memory 中检索到第一个最相关的证据块:Erik Watts ...... is the son of Bill Watts(埃里克・瓦茨是比尔・瓦茨的儿子)。此时上下文中只有 "谁是埃里克的父亲" 这一信息,尚不足以直接回答问题,模型因此生成一个中间引用标记 [4]<object_ref_end>,表示已定位到文档 4,并将其内容纳入上下文。
在第 2 轮迭代中,上下文已扩展,包含了第 1 轮获取的证据。模型在内部生成一个新的、更具体的查询需求(即 "比尔・瓦茨何时出生?"),并再次调用 MSA 路由机制,这次检索到了包含比尔・瓦茨出生日期的证据块:Bill Watts born May 5, 1939(比尔・瓦茨,生于 1939 年 5 月 5 日)。模型再次生成引用标记 [3]<object_ref_end>,将文档 3 的内容追加到上下文中。
第三阶段:稀疏生成(Sparse Generation)。 当证据链完整后,上下文同时包含了 "埃里克的父亲是比尔" 和 "比尔的生日是 1939 年 5 月 5 日" 两条关键证据。模型在最后一次生成步骤中,输出特殊标记 < End-of-Retrieve>,宣告证据搜集结束,随后整合所有证据,生成最终的、高确定性的答案:The answer to the question is: May 5, 1939(答案是:1939 年 5 月 5 日)。
这张图直观地揭示了记忆交错机制的本质:它将 "推理" 与 "检索" 深度交织,使模型能够像一位经验丰富的研究员一样,从一个模糊的初始问题出发,通过逐步发现、逐步聚焦的方式,最终锁定精确答案。这种能力对于解决真实世界中那些答案分散在多个文档中的复杂问题,具有不可替代的价值。
论文通过一系列详尽的实验,从多个维度验证了 MSA 架构的有效性。我们将核心数据可视化并进行解读。
3.1 惊人的扩展性与鲁棒性
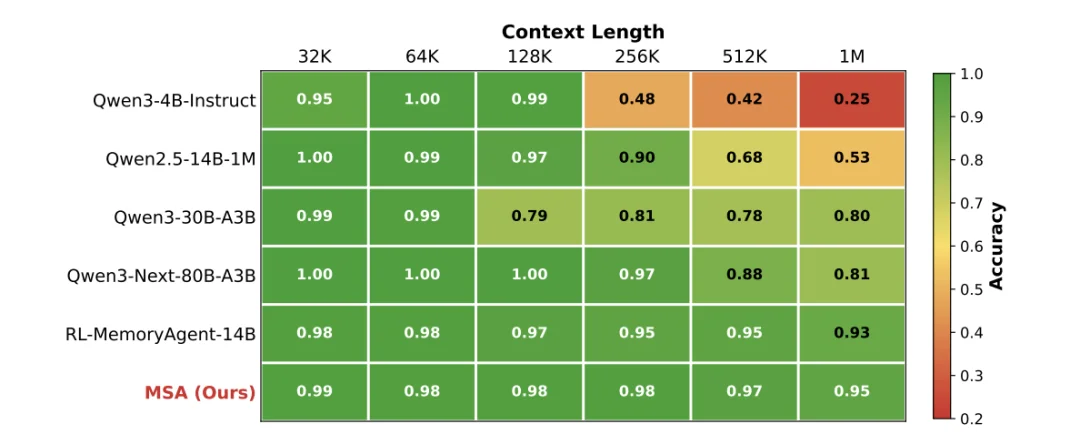
图 4:在 “大海捞针”(NIAH)测试中,MSA 在上下文从 32K 扩展至 1M 时,准确率仅从 99% 下降至 95%,表现出极强的稳定性。相比之下,其他长上下文模型则在256K后显著衰减(论文原图)。
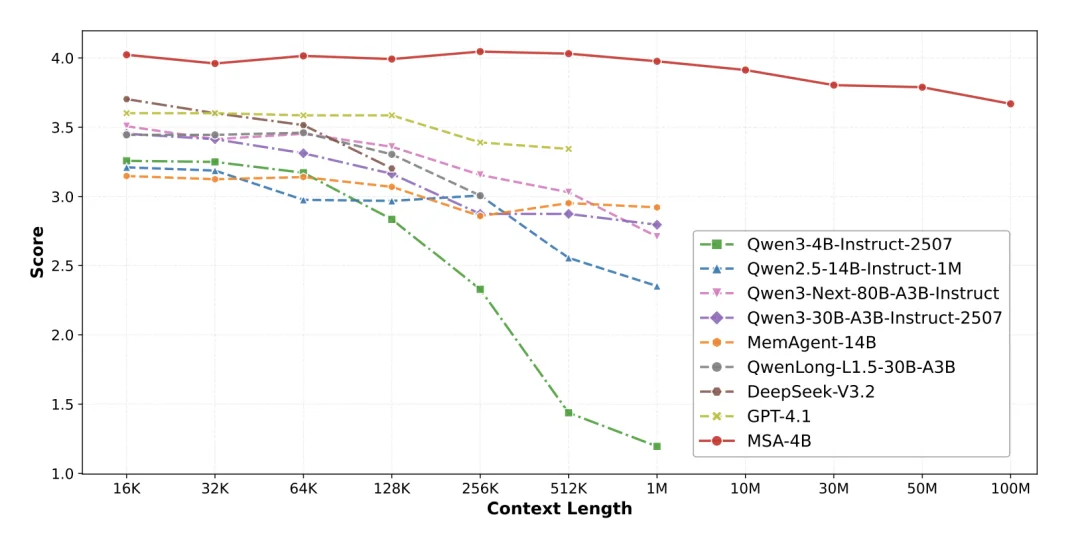
图 5:论文原图,在更极限的 MS MARCO 问答测试中,将记忆规模从 16K 扩展至 100M(跨越 4 个数量级),MSA 的性能评分仅从 4.023 下降至 3.669,衰减率不足 9%。这直观地证明了其架构在抵抗大规模无关信息(噪声)干扰方面的卓越鲁棒性。
3.2 端到端优化的威力
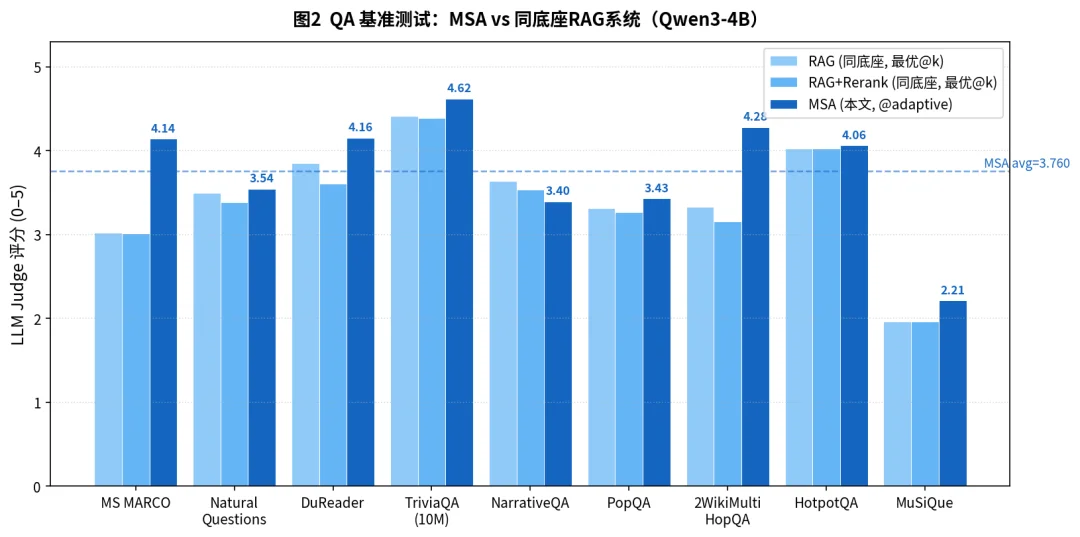
图 6:在 9 个 QA 基准测试的平均分上,4B 参数的 MSA 模型(平均分 3.760)显著优于基于同样 4B 底座构建的、包含重排器(Reranker)的复杂 RAG 系统。甚至在多个数据集上,其表现超过了由 SOTA 的 KaLMv2 检索器和 235B 参数的 Qwen3 巨无霸模型组成的顶级 RAG 系统。这充分证明了 MSA 端到端优化带来的高精度优势。
3.3 各组件的不可或缺性
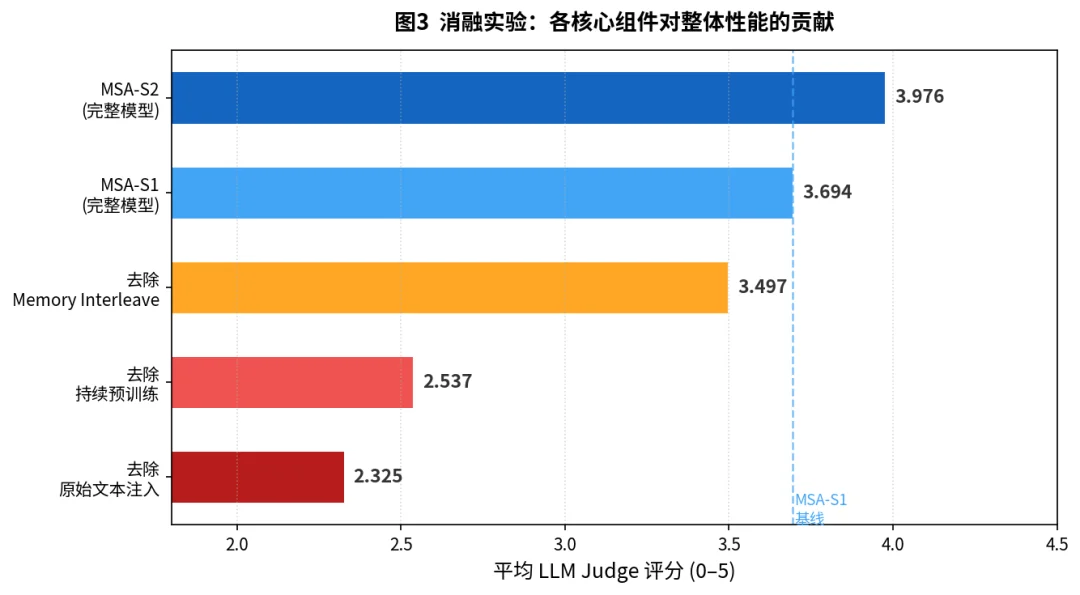
图 7:消融实验清晰地量化了每个创新点的贡献。与基线模型 MSA-S1 相比,移除 “记忆交错” 机制导致在多跳问答任务上性能大幅下降;移除 “持续预训练” 中的辅助路由监督,则让模型几乎丧失了有效的检索能力;而移除 “原始文本注入” 则造成最严重的性能滑坡,说明最终的精确回答仍需依赖原始文本的细节。这证明了 MSA 是一个设计精巧、各部分缺一不可的有机整体。
综合上述分析,我们可以总结出 MSA 论文的核心独创性与价值点:
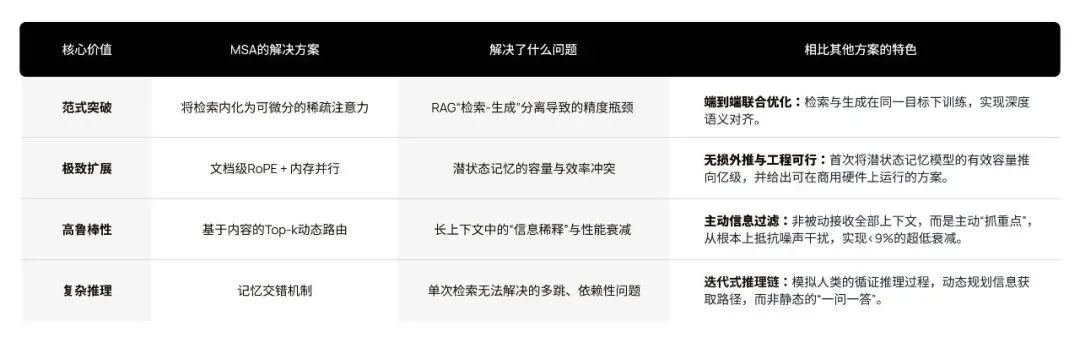
总而言之,MSA 的真正价值,并不仅仅是发布了一个性能强大的长上下文模型,而是为 AI 记忆领域提供了一套全新的、被完整验证过的、兼具扩展性、精度与效率的技术基础设施。 它证明了,我们不必在 RAG 的 “低精度” 和全注意力的 “高成本” 之间做出痛苦的妥协。通过将稀疏化思想与神经网络的端到端学习能力巧妙结合,构建一个独立的、可扩展的、与 LLM 兼容的 “记忆层” 是完全可行的。
这为未来 AI 生态的发展描绘了一幅激动人心的蓝图:记忆可以作为一种独立的、可插拔的服务,与各种推理核心(LLM)自由组合,用户的数据和 “记忆资产” 不再被锁定在任何单一的模型或厂商中。从这个角度看,MSA 不仅是一篇优秀的学术论文,更可能是一个开启 “记忆即服务”(Memory-as-a-Service)新纪元的里程碑。
为完整理解 MSA 研究背后的驱动力,有必要将其置于出品方 EverMind 及其母公司盛大集团(Shanda Group)的宏观战略背景下进行审视。EverMind 是盛大集团创始人陈天桥在 AI 领域深度布局、长期孵化的核心团队之一,使命是攻克 AI 的长期记忆难题,走向AI的自我演化(Self Evolving)。
根据近期 Bloomberg 与钛媒体 对陈天桥的专访,盛大集团的 AI 战略并非聚焦于当前主流的 “生成式 AI”,而是旨在构建一个更具开创性的 “发现式 AI(Discoverative AI)” 生态。其终极目标是让 AI 辅助人类发现新知识、解决如疾病、能源等根本性问题,而非仅仅模仿和重组已有信息。在这一宏大愿景中,两大技术基石被置于核心地位:
MiroMind:专注于推理(Reasoning)。该团队致力于通过可验证推理(Verifiable reasoning)等路径,让模型学会像科学家一样主动向外部世界求证、修正假设,从而实现真正的推理可靠性与洞察发现。
EverMind:专注于记忆(Memory)。该团队的使命是为 AI 打造一个可无限扩展、高保真、且独立于任何特定模型的长期记忆系统。只有当 AI 拥有了稳定可靠的记忆底座,才能在其上进行有效的、跨越时空的复杂推理与知识创造,走向AI的自我演化(Self Evolving)。
因此,EverMind 与 MiroMind 共同构成了盛大集团‘发现式 AI’蓝图的核心驱动力,分别对应着 “记忆” 与 “推理” 这两大认知科学的核心支柱。本文所介绍的 MSA 架构,正是 EverMind 团队践行‘记忆即服务’理念的核心技术成果。其底层设计与技术路线,不仅是对现有长文本瓶颈的突破,更深刻印证了盛大集团在构建独立、自主、可控 AI 基础设施上的长期投入与坚定决心。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
