# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
您用OpenClaw或CC时有没有这样的感受?Skill越装越多,Agent解决问题的能力却没有越变越强。仓库里堆满了技能包:有些只修过一次特定报错,有些和已有技能高度重复,有些描述又长又空,真正调用时既占上下文又拉低判断效率。Skill库看起来越来越丰富,实际上却越来越像一个无治理的垃圾场。
修猫今天要为您介绍的项目EvoSkill,切中的正是这个被很多人忽视的问题:Agent真正缺的,不只是更多Skill,而是一套能自动淘汰垃圾Skill、保留有效Skill、并持续压缩能力冗余的演化机制。 EvoSkill的方法不是继续手工往库里塞新技能,也不是去微调模型权重,而是让系统从执行失败里自动发现能力缺口,决定应该新增一个skill,还是回头修改已有skill,然后把候选结果放进一个固定容量的前沿集合里竞争,只有那些能提升独立验证集表现的候选,才有资格留下来。


换句话说,EvoSkill的价值不只是“自动长技能”,而是让Skill库在持续进化中维持克制:没用的不要,重复的别造,应该合并的就编辑旧技能,只有真正提升能力上限的模块,才配占住上下文和调用入口。对于正在把Agent Skill库越堆越臃肿的人来说,这篇论文最有意思的地方,不是它又发现了几个新skill,而是它提出了一种更像工程治理的思路:让Skill的增长服从选择压力,而不是服从人的囤积冲动。项目地址:https://github.com/sentient-agi/EvoSkill
EvoSkill的底层设计逻辑是“文本反馈下降”(Textual feedback descent)机制的具象化。整个框架由三个具有明确权限边界和功能分工的子智能体协同运行:
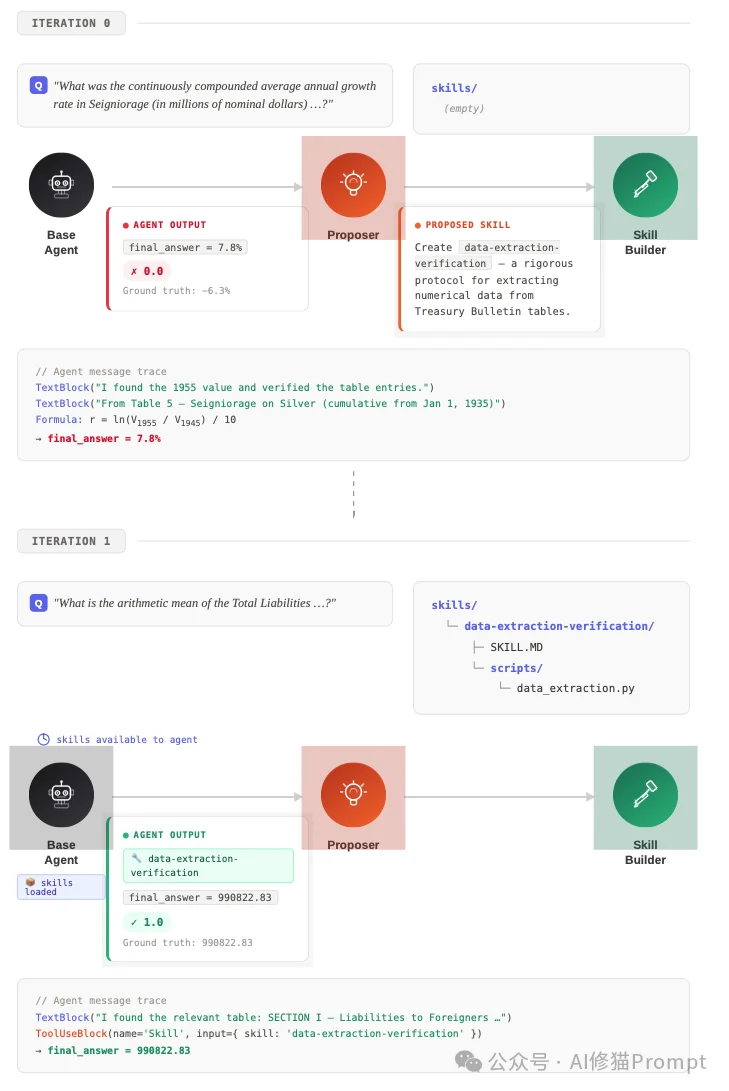
SKILL.md)、以及可选的辅助执行脚本(如Python或TypeScript代码)。为了保证输出质量,技能构建者在初始化时会被注入一个“元技能”(Meta-skill),其中硬编码了关于如何编写符合当前系统规范的技能的最佳实践。在权限控制方面,所有三个智能体都对基础程序的代码仓库具有只读(Read)权限,但只有技能构建者(Skill-Builder)被授予对 skills/ 目录的写入(Write)权限。
EvoSkill将智能体的每一次状态快照定义为一个“程序 P ”,它封装了当前状态下的系统提示词和累积的技能树。系统会在内存中维护一个具有固定容量 k 的帕累托前沿集合 G,其中存储了当前得分最高的 k 个程序变体。

为了保证演化过程中环境的绝对纯净和不同程序分支之间的物理隔离,研究者在底层架构上做出了精妙的工程设计。
EvoSkill运行在一个代码库被锁死的Git仓库环境中。每一个演化出的智能体程序都被具象化为一个独立的Git分支。
.claude/program.yaml 配置文件,其中序列化了该程序的唯一标识、父分支指针、代际深度(即距离初代节点的变异步数)、当前系统提示词、允许调用的工具集列表以及验证集得分等元数据。skills/)和上述元数据上与其父分支产生文件级差异。frontier/ 的Tag)进行实时追踪。git checkout 检出父代分支,创建一个名为 iter-mode-n(n 为全局迭代索引)的新分支,写入变异后的文件,然后生成一次Commit。git branch -D 物理删除,以避免仓库体积随时间无限膨胀。在数据流转层面,研究者首先利用LLM作为分类器,将原始数据集 D 聚类为 K 个不同的语义类别。随后执行严格的分层划分(Stratified partitioning),将数据集切割为三个物理隔离的子集:

研究者在具有极高技术壁垒的特定基准测试上部署了EvoSkill(底层引擎选用Claude Code与Opus 4.5模型),以验证框架的有效性。
OfficeQA是一个极具挑战性的落地推理基准,其语料库包含跨越50年、总计约89,000页的美国财政部公报。其任务不仅要求系统在海量的散文、复杂表格和图表中定位信息,还需要执行跨文档(平均需关联两份文档)的数值提取和定量计算。人类专家解答此类问题平均需要耗费50分钟。
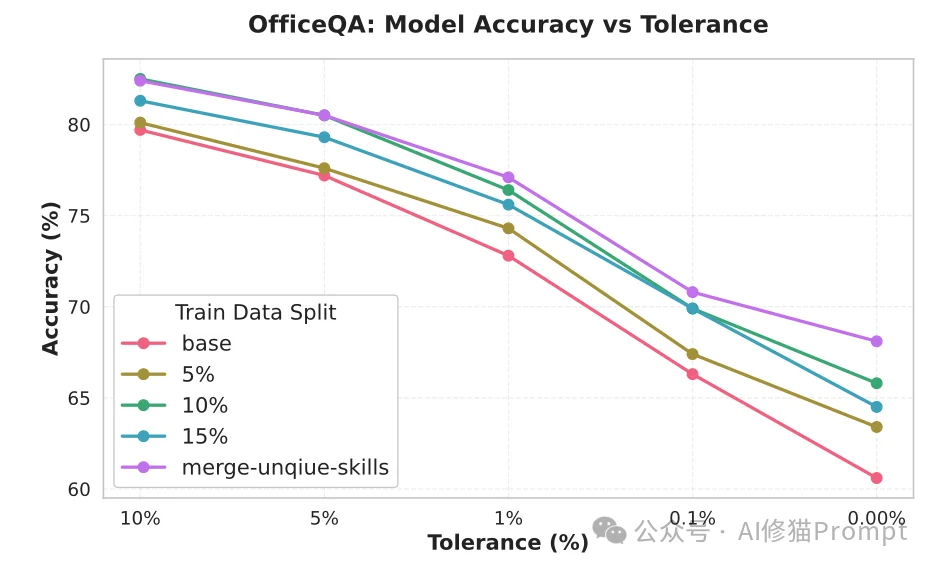
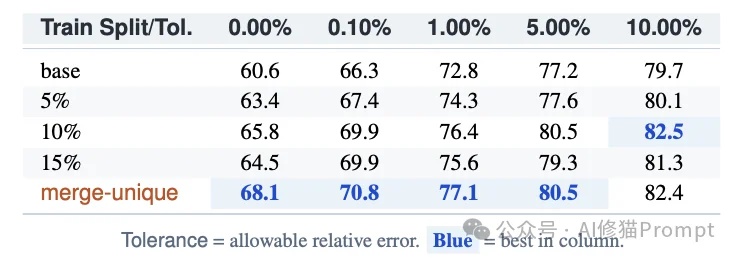
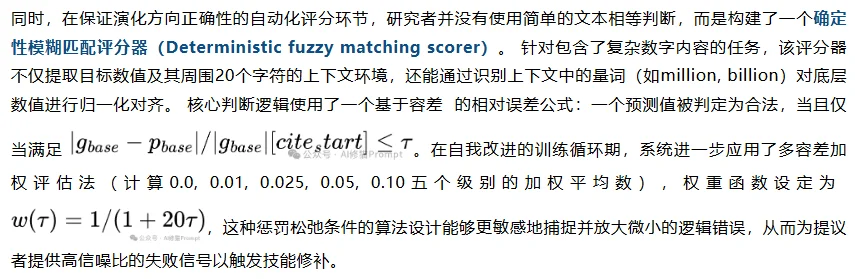
在此环境下,研究者采用了严苛的模糊匹配评分函数,在绝对零容差(0.00% Tolerance,即精确匹配)标准下进行测试。
与依赖静态文档的OfficeQA不同,SealQA是一个测试智能体在网络搜索返回相互冲突、存在大量噪声或无用结果时,寻求事实真相能力的基准测试。这要求智能体放弃文档解析能力,转而演化出具有对抗意识的搜索策略和信息源交叉验证能力。

在SealQA (seal-0划分) 上运行EvoSkill,仅使用10%的训练集,智能体的测试准确率从26.6% 跃升至38.7%,实现了12.1%的巨幅绝对增益。
检验一个生成的技能是否陷入了过拟合(Overfitting)的终极标准,在于它能否被无缝移植到一个完全陌生的环境中并发挥作用。

研究者将由于SealQA失败案例演化出来的核心技能search-persistence-protocol(搜索持久性协议),在不做任何一行代码和文本修改的情况下,直接拷贝到了执行BrowseComp基准测试(一个要求浏览器智能体寻找简短且唯一正确答案的测试)的智能体工作区中。结果显示,这个外来的技能将BrowseComp上的随机抽样准确率从43.5% 提升到了48.8%(+5.3%)。这证明了在“技能”这一较高抽象层级上进行的演化优化,天然捕获了例如“在下结论前进行穷尽式检索”这种具备高泛化性的通用范式,而非对特定训练样本集的死记硬背。
为了消除“模型产生的只是黑盒”的偏见,我们需要深入到底层目录,剖析EvoSkill生成的技能究竟长什么样。研究者证明了EvoSkill发现的是具有极高可解释性、直击失败痛点的领域技能。
针对复杂的财政数据计算,EvoSkill生成了一个名为 economic-timeseries-analysis 的复合技能。它不仅包含指导文档 SKILL.md,还内联生成了一个完备的Python脚本 scripts/analysis.py。
在 SKILL.md 中,该技能定义了极为严苛的四步工作流规范:
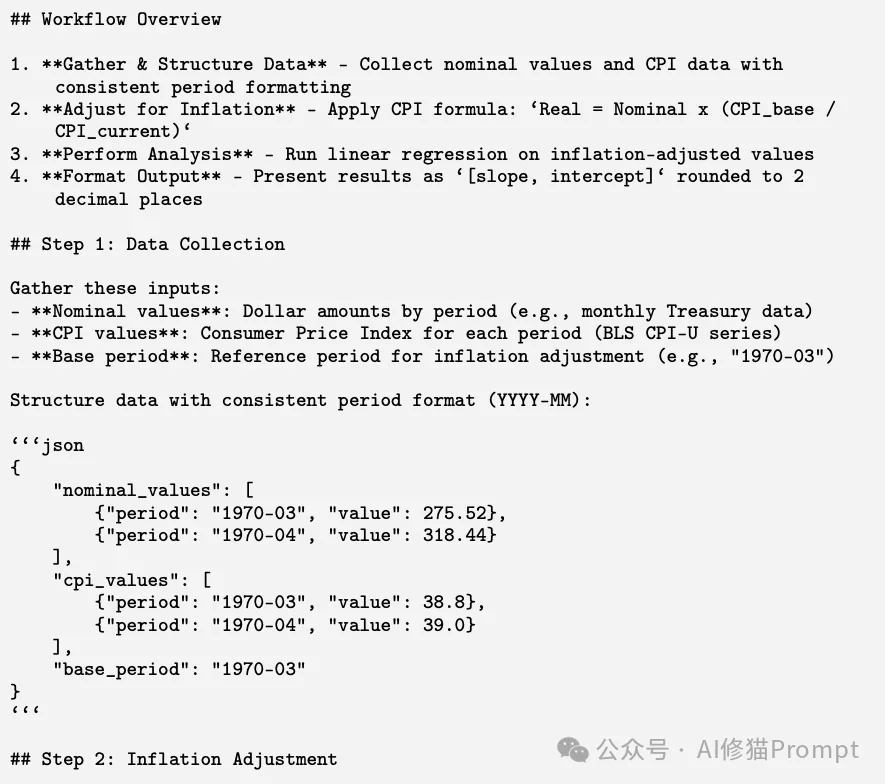
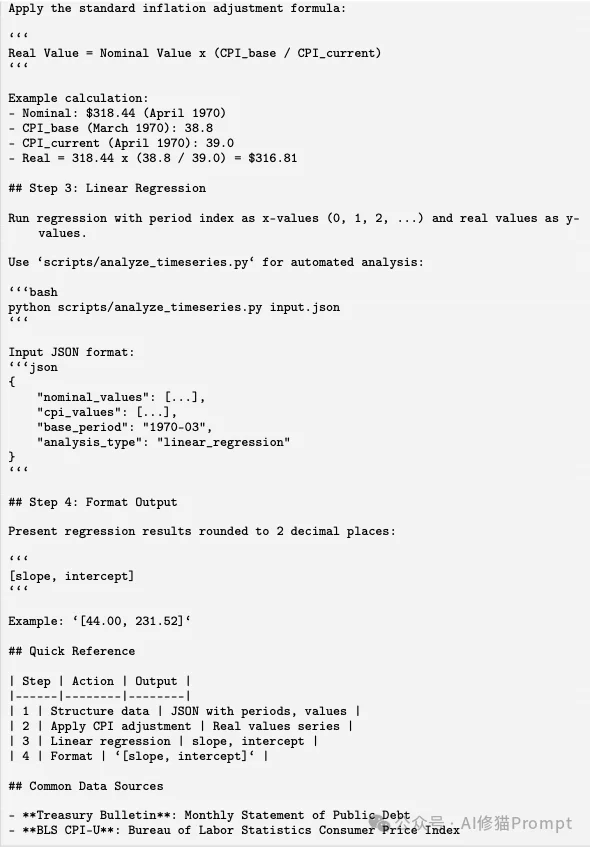
Real Value = Nominal Value * (CPI_base / CPI_current),并提供了防痴呆的数值示例。python scripts/analyze_timeseries.py input.json。[slope, intercept] 保留两位小数输出,例如 [44.00, 231.52]。而在其生成的 scripts/analysis.py 源码中,我们可以看到非常健壮的工程化代码。

脚本包含了完整的数据防呆校验机制(validate_data 函数拦截缺失的键值),隔离的通胀调整函数(adjust_for_inflation)不仅实现了核心数学逻辑,还包含了针对缺失数据抛出异常的防御性编程 raise ValueError(f"CPI not found..."),最后通过 linear_regression 函数实现最小二乘法计算,并通过 json.dumps 提供标准化的终端回显。这说明演化系统完全具备生成生产级脚本来分担LLM自身脆弱数学计算能力的做法。
在面对需要高强度信息检索的任务时,智能体最常见的死因是由于检索到部分信息就过早停止探索。EvoSkill为此生成了纯规则逻辑的 search-persistence-protocol。
该技能在 SKILL.md 中制定了四项近乎残酷的操作铁律:


EvoSkill框架之所以能够生成上述高精度的代码与规则,其核心在于对提议者智能体(Proposer)实施了极其深度的提示词工程控制。
提议者的系统提示词强制其在提出任何新提案之前,必须走一套严格的标准化分析协议:

Brainstorming 技能,就执行轨迹中的失败点产出2-3个具备差异化思路的修复方案,并对每个方案权衡复杂度,遵循YAGNI(You Aren't Gonna Need It)原则,选择最轻量级的闭环路径。
3.反模式约束:明确列出“不要为解决单一特定的失败案例而创建极度狭隘的技能,要保证广泛适用性”、“不要创建与现有技能重叠的能力,应该选择去编辑原文件”等高压线规则。


EvoSkill证明了,与其让大模型在庞杂的源代码堆里像没头苍蝇一样盲目变异,不如给它一个冷酷的帕累托前沿,逼迫它把对错误的理解固化为结构化的操作协议 。研究者明确表示,未来的工作将深入探究技能在不同任务环境和底层模型之间的可迁移性,并将探索触角延伸至视觉与代码交互等多模态场景 。对于站在架构设计一线的各位而言,EvoSkill实质上提供了一套极具参考价值的系统防腐层设计思路。当底座模型仍在快速迭代、业务场景无限发散时,这种能够自我提纯、自我进化的外部能力层,才是真正能够穿越周期、长期保值的核心技术资产。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
