# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,随着 Sora、Seedance 等文本到视频(T2V)扩散模型的飞速发展,AI 视频生成在视觉保真度与动态表现上已取得突破性进展。特别是近期备受瞩目的 Seedance 2.0,展现出了极其强大的多镜头叙事与复杂分镜控制能力。 仅需一段文本提示,生成模型即可合成具备高度物理规律与电影级质感的视频片段。
然而,当我们审视当前的开源视频扩散模型时,一个严峻的技术瓶颈依然存在:在卓越的单场景生成效果背后,它们大多针对 “单事件” 生成进行优化,难以驾驭包含多个连续动作或复杂场景切换的时序叙事。 面对包含明确时序递进的复杂指令时,开源模型的指令依从性往往面临巨大挑战。
当模型处理 “多事件” 的提示词时,由于缺乏显式的帧级时间约束,往往会表现出显著的性能衰退。具体而言,模型极易产生语义特征纠缠,导致多个动作在时空维度发生违背物理常识的重叠与坍缩;亦或是出现事件遗漏,完全忽略提示词中的部分关键动作,从而彻底破坏预期的叙事逻辑。

图注:在无时序控制的基线模型中,多个动作特征在时空维度发生严重坍缩,而采用了 SwitchCraft 框架后,系统成功实现了细粒度的对齐,人物动作演进清晰分明,指令依从性得到了显著提升。
为突破这一多事件视频生成的技术壁垒,西湖大学 AGI 实验室的研究团队提出了一种全新的免训练多事件视频生成框架 SwitchCraft。该框架创新性地引入了底层注意力控制机制,在不更新任何基础大模型参数的前提下,实现了对视频注意力的精准时序引导。它不仅确保了复杂动作的按序生成,同时维持了极高的视觉保真度与主体一致性。
目前,该研究成果已成功入选计算机视觉顶级会议 CVPR 2026。项目代码与演示主页均已开源。

第一作者为在西湖大学 AGI 实验室访问的大三本科生徐千寻,指导老师为西湖大学 AGI 实验室助理教授张驰。

要理解 SwitchCraft 的学术贡献,首先需要剖析现有视频扩散模型在处理 “多事件” 任务时的底层缺陷。
在当前的视频生成架构(如基于 Diffusion Transformer 的扩散模型)中,文本提示词的特征通常通过交叉注意力机制(Cross-Attention)在整个时间轴上被均匀分布与注入。模型缺乏一种内在机制来建立 “特定时间段” 与 “特定文本事件” 之间的强映射关系。这导致不同时间维度的语义特征在全局帧中发生严重的特征泄漏,最终呈现出动作的异常叠加或属性的错误融合。
此前,业界尝试的替代方案通常是 “分段生成与拼接”,即强行将长文本拆分为多个独立子事件,分别生成视频后再进行组合。然而,这种自回归或基于拼接的方法会引发致命的主体特征退化:在场景或动作切换时,视频极易出现生硬的跳切,核心主体的外观特征及背景环境往往无法在转场前后保持时空一致性。
如何不拆分生成、不破坏时序连贯性的前提下,引导模型精准响应复杂的时间线索?这正是 SwitchCraft 致力于解决的核心挑战。
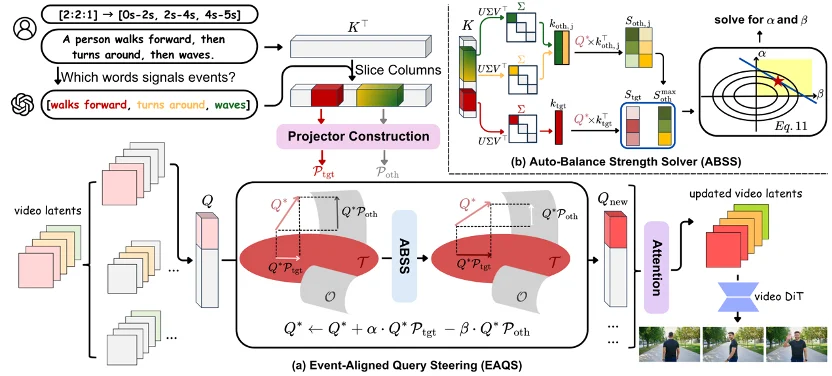
SwitchCraft 的核心创新在于:通过直接干预底层模型的注意力响应模式,实现隐帧级别的语义解耦。
作为一个免训练框架,SwitchCraft 具备极高的泛化性与实用性。它无需消耗高昂的计算资源对现有的视频大模型进行重新训练或微调,即可作为即插即用的模块集成至现有流水线中。该框架主要由两大核心组件构成:
贡献一:事件对齐的查询引导 (Event-Aligned Query Steering, EAQS)
在主流的视频扩散模型中,视觉生成高度依赖于交叉注意力机制:即通过隐帧提取的视觉查询向量(Visual Queries)去匹配文本提示词的键特征(Textual Keys)。EAQS 模块直接介入这一底层计算过程,以实现时序上的语义隔离。
贡献二:自适应强度平衡求解器 (Auto-Balance Strength Solver, ABSS)
在扩散模型中,对交叉注意力图施加过度的外部干预,易破坏模型预训练所建立的原始特征分布,从而导致生成的画面出现伪影、结构扭曲或视觉质量急剧下降。此外,由于不同提示词的语义复杂度与动作生成难度存在显著差异,固定的超参数无法泛化至多样化的生成任务中。
为解决这一鲁棒性问题,自动得到最优的 “推”“拉” 强度,研究团队设计了具备闭环调节机制的 ABSS 模块:
得益于上述两大核心机制的协同作用,SwitchCraft 在多事件视频生成任务中展现出了卓越的控制性能:

提示词:一个男人抬起一只手臂,然后抓了抓头,然后向前跑去

提示词:一个人在走路,然后跑步,然后起跳。

提示词:一辆越野车驶过沙丘,然后穿过森林小径,然后在雪地小路上行驶。

提示词:一个学生笔直地坐在书桌前打开笔记本电脑,然后开始打字,然后向后靠并伸展双臂。
此外,SwitchCraft 在场景切换上还展现出了一项独特的优势:创意遮挡转场(Creative Occluding Transitions)。不同于现有基线模型在转场时极易产生的残影或主体突变,该框架能够巧妙利用环境遮挡关系生成创意的无缝运镜。它不仅实现了前后异构场景的平滑融合,更在全过程中完美锁定了核心主体的身份特征一致性。
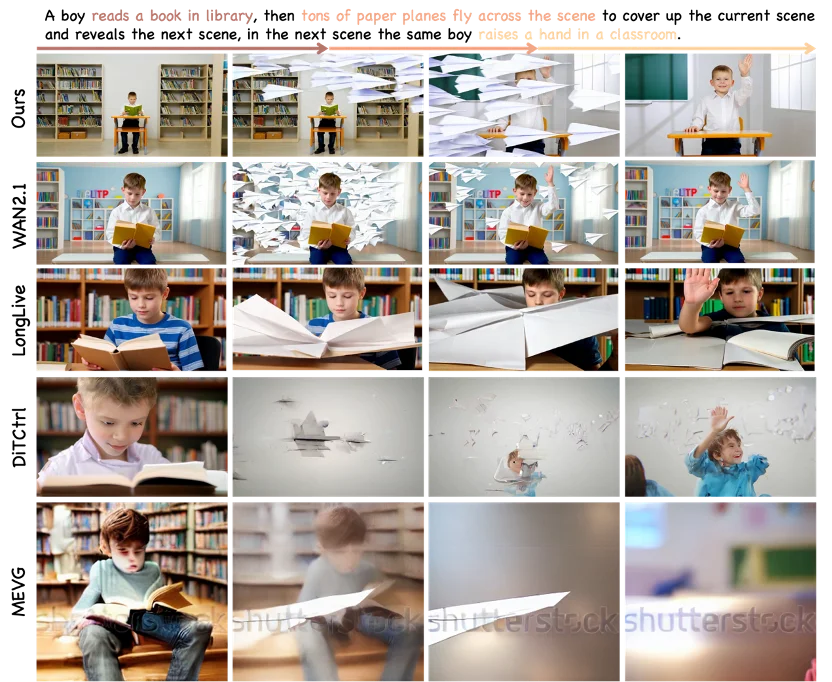
对比多种现有的视频生成与时序控制基线方法(如 MEVG、DiTCtrl、LongLive 等),SwitchCraft 在多事件文本对齐度、视觉保真度与运动平滑度等方面均表现突出,综合客观评测指标稳居领先水平 。
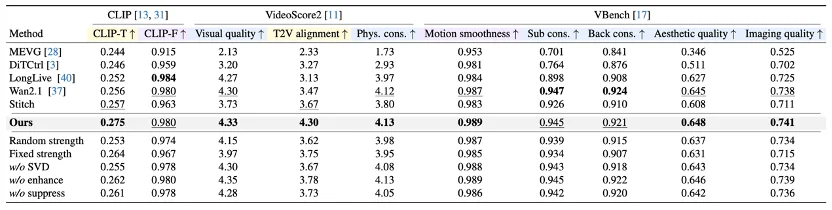
此外,团队在消融实验中发现,SwitchCraft 的各项核心机制缺一不可。在 EAQS 模块中,若打破 “推拉” 协同(仅保留单向的 “增强” 或 “抑制”),生成的视频将面临动作遗漏或跨时序特征泄漏;而在 ABSS 模块中,若放弃自适应机制(采用固定的注意力干预强度或移除 SVD 主导方向提取),则会导致画面视觉保真度出现断崖式下跌,文本对齐准确率也会显著降低。这充分证明了 “一推一拉” 的时序注意力调度与 “动态自适应求解” 必须相辅相成,二者的完美配合正是模型能够在 “高保真视觉质量” 与 “精准多事件控制” 之间取得动态最优平衡的关键所在。
SwitchCraft 展示了复杂视频生成的新思路:无需微调的精准时序注意力控制。我们期待这一即插即用的框架在长篇视频叙事、动态分镜等领域落地,并与开源社区共同探索更多可能。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
