# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
机器人能认出杯子,却看不懂杯口朝哪、离自己多远、该抓哪里。
这是当前VLM在物理世界里的尴尬。
如果将深度信息无缝整合进VLM系统,一切或将大不一样。


人工智能的终极目标之一,是构建能够完整理解、建模、预测并自主作用于现实世界的智能系统。在通往这个目标的道路中,空间智能是底层感知和理解基座,支撑AI大脑走进现实,感知、理解以及完成与物理世界的真实交互。
长期以来,空间感知信息的模糊性,一直是阻碍AI与物理世界深度适配的重要瓶颈。基于此,视启未来(Visincept)团队联手清华大学、IDEA研究院提出了全新的具备空间感知能力的视觉-语言框架SpatialPoint,通过提升机器人在三维空间中感知并确定行动位置的能力,补齐AI与现实交互的短板,从而推进具身应用落地与AI大脑发展。

△ 不同具身场景下SpatialPoint的精准应用
尽管今天的视觉-语言模型(VLM)已具备强大的物体识别与语义理解能力,能够轻松分辨常见以及部分垂直、长尾场景的物体,也能响应诸如“把杯子放到桌上”等自然语言指令。
但在实际的三维场景中,这些能力并不能有效转化为可落地的空间操作能力。相反,空间操作信息的模糊性和不确定性,常常导致机器人无法稳定、精准地与物理世界交互。造成这类情况的原因,可归结为三点:
虽然RGB-D传感器在机器人中应用广泛,但当前主流VLM仍以彩色(RGB)图像为主要输入,仅依靠纹理、透视等线索隐式推理3D结构,缺乏直接、精确的深度信息。
在执行类似“抓住桌上的杯子”等任务时,模型虽能定位到杯子,却无法精准判断其与镜头的距离、杯口朝向,以及稳固的抓取位置。场景或视角一旦改变,距离与位置判断便会失效,导致机器人频繁出现抓空、抓偏、碰撞等问题。
从技术本质看,单目RGB缺乏显式度量几何信息,几何保真度低、跨场景泛化能力差,而多视图三维重建则依赖复杂的相机标定与位姿计算,落地难度大。
传统VLM的输出多为2D框、语义掩码或物体类别名称,这些信息对机器人而言缺乏实际执行价值。机器人执行任务不需要“这里有杯子”的标注,而是需要精确到像素与毫米的三维行动点。比如面对“抓取杯子把手”的指令,传统模型只能框选出把手区域,无法直接告诉机械臂具体下爪坐标(如像素坐标(865,711)、深度825毫米)。这使得感知与执行之间出现巨大的断层,机器人还需要经过复杂的后处理、坐标转换、误差校准,流程繁琐且极易出错。
SpatialPoint团队认为,具身智能需要从根本上具备在三维空间中确定行动位置的能力,并细化到“点”的维度。由此提出了具身定位的概念,即在视觉观察和语言指令的条件下预测可执行的三维点。
在与物理世界的交互中,机器人离不开两种核心的空间点位信息:一是物体表面的附着点,即实点(TouchablePoint),用于抓取、按压、接触等直接交互;二是无遮挡的自由空间点,即虚点(AirPoint),用于物体放置、移动导航、避障等间接交互。
但现有技术大多只能处理其中一类,缺乏能在统一接口下同时精准预测两类点位的模型。例如机器人想要完成“拿起杯子放到篮子上方”的任务,需要分别调用抓取点与放置点两套不同的模型、数据与接口,兼容性差、效率低下,无法满足一体化具身任务需求。
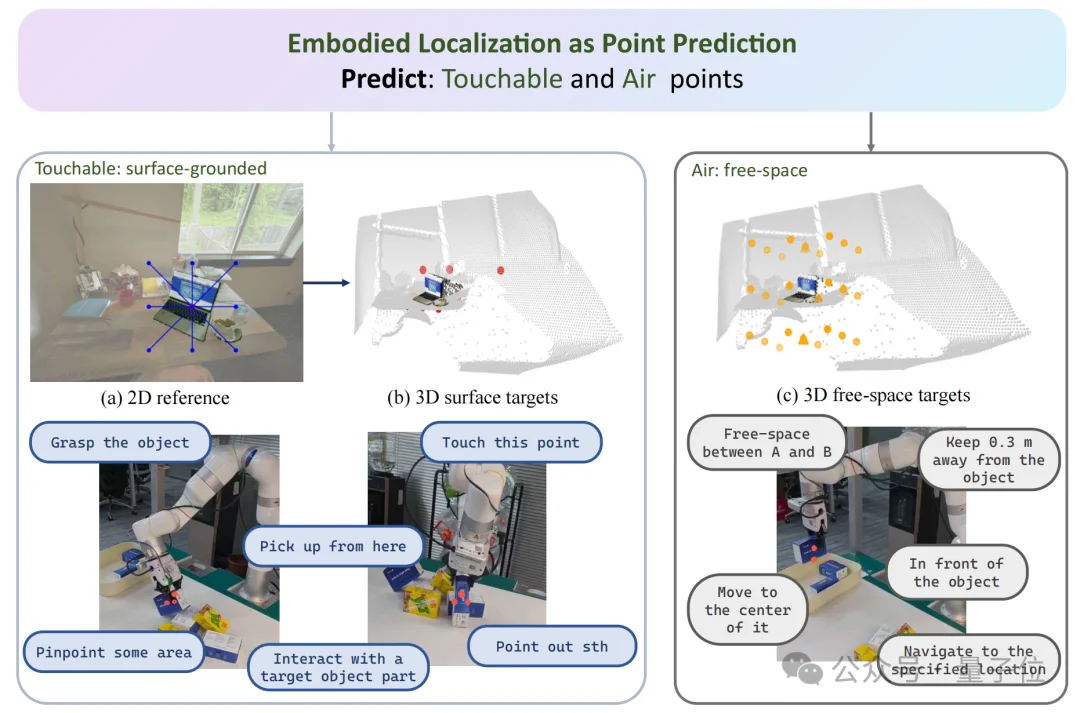
△ 实点和虚点的应用示例
SpatialPoint是面向具身定位任务设计的空间感知视觉-语言框架,该框架以Qwen3-VL为基础模型,开创性地将结构化深度信息作为核心输入,与RGB、文本指令并行编码融合,实现端到端的相机坐标系三维点预测。
简单来说,SpatialPoint能看懂彩色画面、读懂距离信息、听懂语言指令,从而能够原生输出机器人可直接在三维空间中使用的抓取点、放置点和导航点。
尽管有部分研究尝试将RGB-D传感器获取的深度度量信息引入视觉-语言模型,但这些方法均未突破“将深度作为辅助线索”的设计局限:它们要么将深度特征在模型中间层与RGB特征简单拼接;要么在模型输出3D结果后,用深度信息做后处理修正。
在这类设计中,深度信息从未进入VLM的核心视觉-语言融合推理流程,无法与RGB特征、语言特征产生深度的协同交互,相当于“拿到了深度数据,却没真正发挥其度量几何价值”,最终仍无法解决传统VLM的3D推理偏差问题。
SpatialPoint面向空间智能场景做了更直接的架构设计,将深度从辅助信息提升为与RGB、语言并行参与推理的核心输入,让深度信息从模型输入阶段就参与推理,贯穿视觉特征编码、多模态特征融合、3D坐标预测的全流程。
与此同时,针对预训练VLM仅支持RGB和语言输入,直接加入深度模态会破坏模型原有能力的技术难题,SpatialPoint通过“深度专用编码+特征对齐”和两阶段训练策略两大关键设计,实现了深度模态与预训练VLM的无缝融合,既激活了深度信息的度量几何价值,又保留了VLM原本的视觉-语言理解能力。

△ SpatialPoint与现有空间感知方法的对比
此外,不同于现有方法要么只关注表面的交互点,要么只关注端到端的动作生成,SpatialPoint实现了在一个统一的视觉条件接口下,同时提供涵盖表面附着点(实点,TouchablePoint)和周围自由空间中需要推理的目标(虚点,AirPoint)的统一视角,并直接输出机器人可执行的结构化3D坐标,实现“模型输出即机器人执行指令”,大幅降低了具身应用的落地复杂度。
SpatialPoint的整体技术框架围绕“深度信息原生融合”展开,从深度编码、模型训练、多模态融合、3D坐标四个环节,构建出端到端的3D点预测流程。具体操作如下:
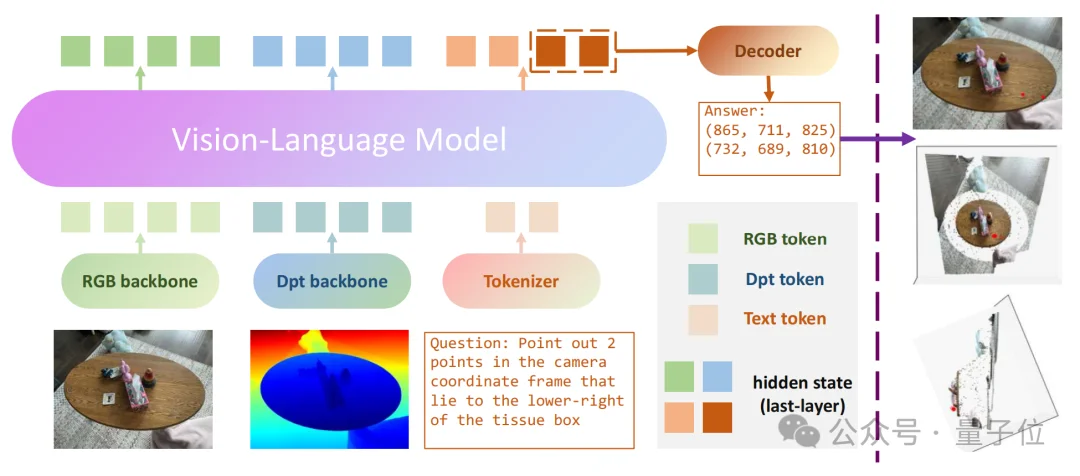
△ 图2 SpatialPoint技术框架
由于预训练VLM只支持3通道RGB输入,无法直接接收单通道的深度图,因此第一步需要先将单通道深度图转为3通道格式,适配模型视觉分词器;再复用RGB主干网络结构,为深度信息搭建专用主干网络,并让两个网络在相同的图像分块(Patch)网格中运行,生成空间、特征维度完全对齐的RGB token和深度token,为后续两种特征的融合推理做好准备。
考虑到直接把深度信息加入预训练VLM一起训练会破坏VLM已有的能力,因此SpatialPoint采取了“先适配、后融合”的两阶段训练策略:
为了让 RGB、深度、语言三种特征能有序融合,且协同推理,SpatialPoint 为深度 token 设计了专属的边界标记符<dpt_start>/<dpt_end>,连同 RGB 的<vision_start>/<vision_end>、语言文本 token 组合成一个统一的因果序列,一起输入多模态融合网络。模型会保留原本的因果注意力机制,让三种特征在推理中相互引导、彼此配合。
比如在解析“杯子左侧30厘米”的指令时,模型会同时结合RGB识别的杯子2D位置和深度图获取的杯子实际距离,联合计算出精准的3D目标点,而非三种特征各自推理后简单拼接结果。
最后,模型的语言建模头会直接生成(u,v,Z)格式的结构化3D坐标,无需额外的解码、转换步骤,其中u/v是图像上的像素相对坐标,Z是对应位置的深度值(单位为毫米)。这个坐标可以直接被机器人的运动控制系统识别和解析,模型的推理结果就是机器人可直接执行的动作指令,大幅降低了从模型推理到实际落地的复杂度。
为了支撑模型训练与评估,团队构建了SpatialPoint-Data数据集,该数据集总共包含260万组RGB-D问答对,同时覆盖实点与虚点两类任务:
其中,190万组实点数据,由RoboAfford的2D交互标注结合深度图提升为三维坐标获得;72万组虚点数据,通过DINO-X目标检测、深度图与相机内参,自动计算方向、间距、物体间关系等三维几何约束生成。海量且多样化的数据,让模型具备极强的跨场景泛化能力。
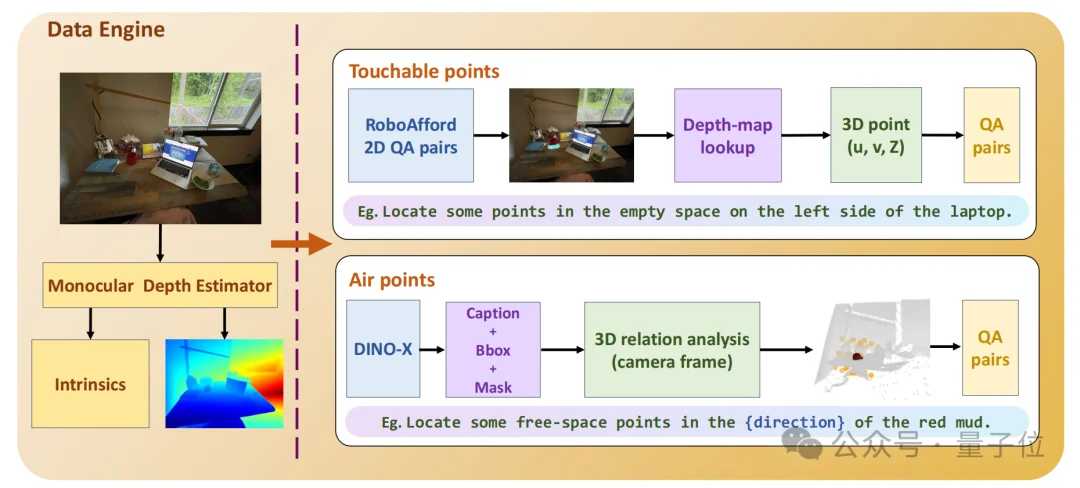
△ SpatialPoint数据引擎
本次实验针对机器人要找的两类三维点,制定了不同的效果评判标准:一类是需要机器人接触物体的附着点(实点),核心指标包括:
(1)能不能精准找到物体上的有效操作位置(2D准确率)
(2)对这个位置的深度判断准不准(深度MAE,数值越小越精准)
另一类是机器人只需定位的自由空间点(虚点),核心指标包括:
(1)能不能找对指定方向(DirPt,方向正确性);
(2)在指定方向上是否满足距离约束(MetPt@5cm,5厘米距离准确率);
(3)方向和距离能不能同时找对(FullPt,联合成功率)
(4)距离预测的平均偏差(MeanErr,数值越小越精准)
而且所有距离相关的评判,都要先保证方向找对,这样的结果对机器人实际操作才有意义。
在找物体可接触点的任务中,SpatialPoint的表现实现了质的飞跃:整体能精准找对物体有效操作位置的概率达到79%,远超其他主流模型的74.1%、50.3%,在识别物体可操作部位、找空置操作区域等细分场景里,表现优异。
更关键的是,SpatialPoint对距离预测的平均误差仅17.2毫米,在物体有效操作区域内的误差更是低至9.3毫米;而传统只靠图像的模型,距离预测平均误差高达574.8毫米,两者差距超过30倍。这就说明,把深度信息作为核心输入融入模型后,不仅能精准找到物体上的操作位置,还能准确判断这个位置的实际距离,从根本上解决了传统模型“只看平面图像,靠猜测判断实际距离”的问题。
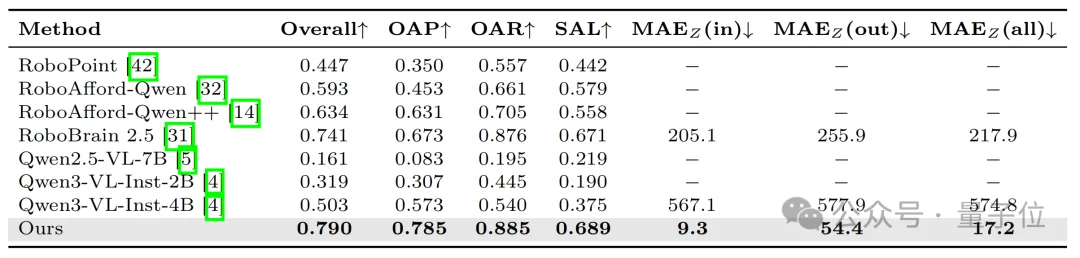
△ 基于RoboAfford-Eval数据集的实点结果验证
定位自由空间点,是机器人完成导航、放置物体等任务的关键,SpatialPoint在这项任务上的优势更突出:
仅训练1轮,找对指定方向的概率就达到48.86%,远超其他模型的8.04%、5.32%;5厘米内找对具体位置的概率25.87%,方向和距离同时找对的概率13%,距离预测的平均偏差仅8.5厘米;而传统只靠图像的模型,距离平均偏差高达54.7厘米。
随着训练轮次增加到3轮,SpatialPoint模型的表现还在稳定提升,找对方向的概率最终稳定在50.71%,5厘米内找对具体位置的概率提升到33.47%,方向和距离同时找对的概率提升到16.41%,距离平均偏差也降到了6.8厘米,说明模型能很好地学习融合深度信息,训练效果越练越好。

△ 基于SpatialPoint-Bench数据集的虚点结果验证
不管是找指定方向的点、找两个物体之间的点,还是以物体自身大小为参照找距离,SpatialPoint的表现都全面超过其他模型,找对方向的概率分别达到51.61%、43.71%、50.97%,证明它在各种复杂的空间定位场景中,都能有稳定的表现。
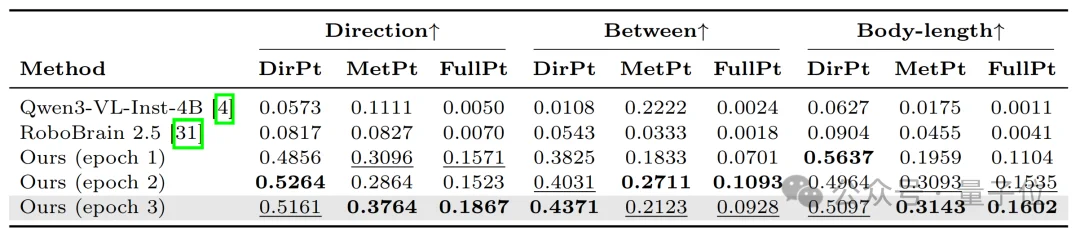
△ 基于SpatialPoint-Bench数据集的复杂空间定位结果验证

△ 部分基于RoboAfford-Eval数据集的表面目标定性对比效果
除了数据实验,SpatialPoint还使用真实的机器人完成了落地验证(参考本文顶部视频)。针对三大典型具身任务:语言引导机械臂抓取(实点)、物体放置到目标位置(虚点)和移动机器人导航(虚点),模型无需微调,即可准确输出机器人可直接执行的3D坐标,实现零样本泛化。
得益于仅需一个统一的视觉条件接口的巨大优势,SpatialPoint让多任务一体化操作成为现实。

△一个模型实现导航、抓取和放置
想象一个复杂的全流程场景:当用户向机器人下达“把餐桌上的水杯拿到客厅实木茶几正中央,再走到玄关鞋柜旁待命”这一连贯指令时,传统VLM仅依靠RGB平面图像工作,既无法精准感知物体的实际深度和空间距离,也不能直接输出机器人可执行的3D坐标,完成任务时不仅需要切换多个专用模型、做额外的坐标转换处理,还极易出现抓空水杯、放置偏移碰撞、导航定位不准等问题,跨场景执行的稳定性也极差;
而搭载了SpatialPoint的机器人,由于将深度信息作为核心输入,通过单一模型就能融合RGB视觉、深度几何与语言指令信息,依次精准输出抓取、放置、导航所需的3D可执行坐标,无需任何额外处理,就能无误差、流畅地完成全流程操作,即便更换场景也能稳定执行,精准解决了传统VLM的核心痛点。
三维交互预测是空间感知领域的核心瓶颈,也是推动空间智能从“感知理解”升级为“可执行、可落地、可闭环”的完整能力体系的关键一环。SpatialPoint致力于生成精准、度量级、可执行且具备强泛化能力的空间感知信息,补齐这一关键短板,不仅为具身智能提供更加可靠的决策依据与执行逻辑,同时也为世界模型构建完备统一的技术支撑。
此外,SpatialPoint在真实机器人平台上的落地与验证,持续为AI大脑提供高质量、可迭代的实测数据反馈,形成从模型到物理世界的闭环进化。
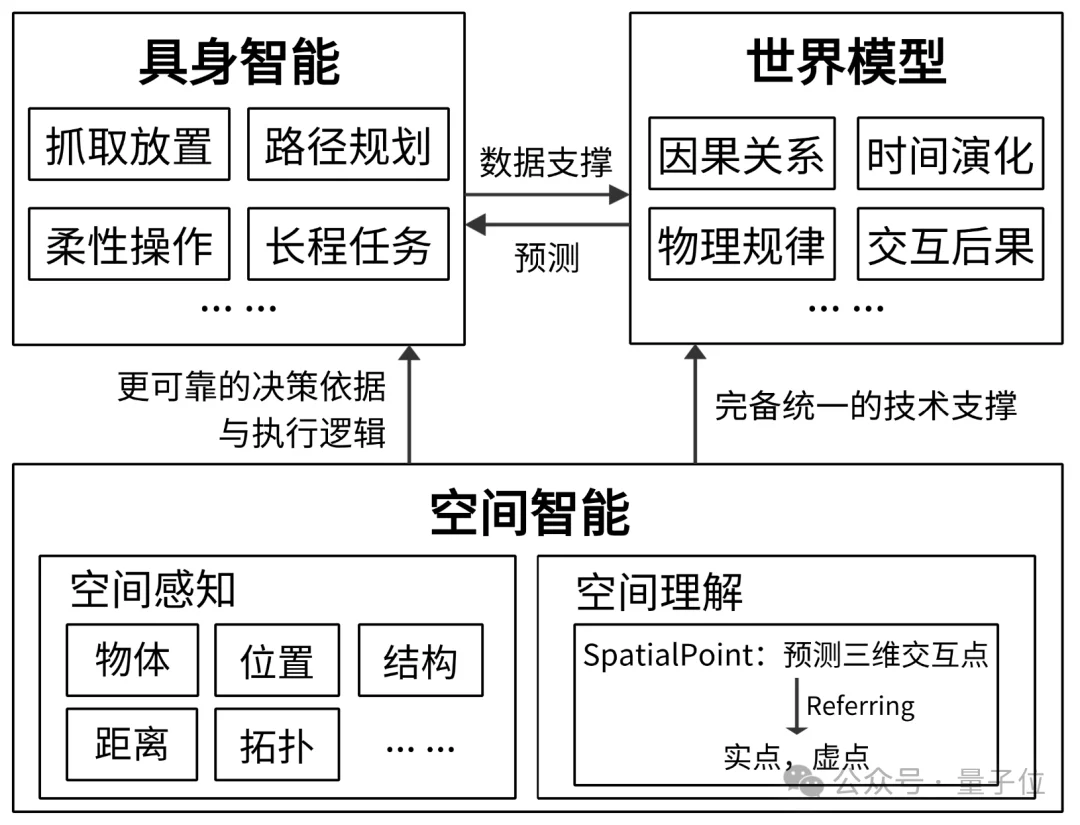
△ 图5 SpatialPoint致力于补齐AI与现实交互的短板
从空间感知到具身应用,再到世界模型,SpatialPoint以简洁高效的深度原生设计,推动人工智能向物理世界迈进。人工智能突破屏幕的边界,真正走进完整、开放、动态的物理世界,这一目标已触手可及。
项目主页:
https://qimingzhu-google.github.io/SpatialPoint/#
文章来自于"量子位",作者 "SpatialPoint团队"。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
