# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Tanay Jaipuria 本周写了一篇很有意思的文章,核心论点只有一句话:每家 AI 应用公司最终都会垂直整合,变成全栈公司。
问题不是"要不要整合",而是往哪个方向整合。
向下,吃掉模型层。向上,吃掉服务层。两条路都通向"全栈",但长出来的公司完全不一样。这篇文章让我想到了一个更根本的问题:在 AI 时代,"只做应用"这件事,可能根本就不是一个稳态。

Tanay Jaipuria (@tanayj) 原文:AI Applications and Vertical Integration
Tanay 把一个能交付结果的 AI 产品拆成了三层:

这当然是简化的。模型底下还有芯片、基础设施、数据系统。但这个简化是有用的,因为它把一个关键问题暴露了出来:
传统的"应用公司"只占中间那一层。
想象你开了一家餐厅,但食材靠别人供应,外卖靠别人送——你只负责中间的烹饪。如果供应商涨价了,你没办法。如果外卖平台抽成太高了,你也没办法。你被夹在中间,上下都不是你能控制的。
AI 应用公司现在面临的就是这个困境。模型层被 OpenAI、Anthropic、Google 控制;服务层被人力和行业 know-how 控制。只做中间的编排,迟早会被上下两头挤压。
所以,几乎所有跑出来的 AI 应用公司都在往上或往下扩张。没有人愿意只做中间商。
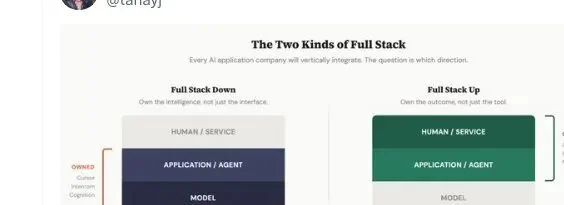
Tanay 的原图:Full Stack Down(向下拥有智能)vs Full Stack Up(向上拥有结果)
第一条路:应用公司向下整合,吃掉模型层。
这在编程和客服两个赛道上表现得最明显。
Cursor 上周发布了 Composer 2。这不是一个微调版本——它基于 Kimi K2.5 做继续预训练,加上长程编码任务的强化学习,直接定位为 frontier-level coding model。Cursor 的技术报告里写得很清楚:
"Composer 2 uses Kimi K2.5 as a base model, then extends it with continued pretraining plus reinforcement learning on long-horizon coding tasks."
同一周,Intercom 发布了 Fin Apex。CEO Eoghan McCabe 的措辞更直接——他管这叫"垂直模型的时代"。Apex 现在处理 Intercom 几乎所有英文客服对话和邮件。不是辅助,是直接处理。
除了 Cursor 和 Intercom,Cognition、Harvey、Sierra 也在做类似的事情。它们不再只是调用模型 API,而是在训练、调优、路由模型本身。
为什么?
因为这是 AI 公司手里最强的飞轮。
逻辑很简单:产品越好 → 用户越多 → trace 越多 → 训练数据越好 → 模型越强 → 产品越好。这个循环一旦转起来,就是真正的壁垒。别人拿不到你的 trace,就训不出你的模型。
trace 是什么?就是用户使用 AI 产品时留下的完整痕迹——prompt、输出、编辑、接受、拒绝。每一次交互都是一条训练数据。Cursor 坐拥全球最大的编码 trace 数据库,这个数据量级是 OpenAI 的通用模型很难覆盖的。
还有两个次要原因。
成本和速度。规模上来之后,COGS 非常可观。一个经过 fine-tune 的小模型,在特定场景下性能够用,但成本可能只有通用大模型的十分之一,速度快好几倍。对于 Intercom 这种每天处理数百万条客服消息的公司,这不是优化,是生存。
差异化。如果一个赛道里所有人都在调同样几个模型的 API,你凭什么比别人强?智能层没有差异,产品层的差异就很脆弱。今天你的 prompt engineering 领先,明天竞争对手就能抄走。但你训出来的模型,别人抄不走。
第二条路正好反过来:应用公司向上整合,吃掉服务层。不卖软件,卖结果。
"You do not just sell software into a workflow. You own the end-to-end process and provide an outcome or service to the end customer."
这个概念不新。Chris Dixon 2015 年就写过"全栈创业公司"。但当时的问题是:服务经济学太难看了。人力密集、毛利低、扩展不了。你卖软件可以 90% 毛利,卖服务能有 30% 就不错了。
AI 改变了这个等式。
以前做不了"卖结果"是因为最后一公里太贵了。你需要雇人来做质检、审核、收尾。AI 把这个成本压下来了——不是降了 20%,是降了一个量级。于是,很多原来不值得做的"全栈服务"赛道,突然变得有吸引力了。
Tanay 列举了几个很有代表性的例子:
Crosby AI 把软件、AI 和律师组合在一起。CEO Ryan 管这叫"Neofirm"——新型事务所。不是给律师卖工具,是直接替你做法律服务。
WithCoverage 和 Harper 在做 AI 原生保险经纪。不是给保险经纪人装个 AI 插件,是自己当保险经纪人。
Mechanical Orchard 做 AI 原生的软件现代化服务。不是卖迁移工具,是帮你把整个遗留系统迁完。
这些公司的共同逻辑:AI 很强但不是 100%。一家拥有端到端结果的公司,既有动力持续改进 AI(因为每 1% 的自动化率提升都直接增加毛利),又能在 AI 做不到的地方用人来补。客户不用操心最后一公里。
当你的 Agent 能完成 90% 的工作时,为什么不干脆承诺 100% 的交付,把剩下的 10% 也吃掉?
那 10% 往往是最值钱的部分。
最有意思的是,这两条路最终可能殊途同归。
向上整合的公司在做服务的过程中,积累了大量行业特有的数据和 trace。这些数据太有价值了——迟早会用来训练自己的模型。于是它们也向下了。
向下整合的公司一旦模型足够强,自然会想:既然 Agent 已经能做 95% 的工作,为什么不直接卖结果?收费从"每月 $X 订阅"变成"每个案子 $Y",客单价翻几倍。于是它们也向上了。
最终状态:一家公司同时拥有底层智能、中间编排和上层交付。三层通吃。
这也解释了为什么模型公司自己也在做应用。OpenAI 做 ChatGPT 和 Codex,Anthropic 做 Claude Code,Google 做 Gemini。它们从底层往上吃。应用公司从中间往两头吃。最后大家在同一个战场相遇。
想想看:Cursor 现在有自己的模型,有自己的 IDE,还有 Cursor for Business。如果哪天 Cursor 说"我们帮你管整个开发团队"——卖的不再是工具,而是软件开发服务本身——你会觉得意外吗?
我不会。
如果接受这个框架,一个让人不安的推论就浮出水面了:
"只做应用层"不是一个稳态。
你在中间层做了一个很好的 AI 产品。用户喜欢,增长不错。然后呢?
从下面,模型公司在往上吃你。OpenAI 今天发布了一个新功能,你的核心差异化一夜之间被 default 掉了。Claude 更新了一个能力,你精心设计的编排逻辑突然变得多余了。
从上面,你的客户在问:你能不能帮我做完整件事?不只是给我一个工具,而是帮我搞定结果?如果你不做,隔壁那家"全栈服务"的公司就会做。
被夹在中间,就像开餐厅但不种地也不送外卖。上游一涨价,下游一抽成,利润就被挤干了。
这也是为什么我们看到那么多 AI wrapper 公司活不过两年。不是因为它们做得差,而是因为中间层本身就是一个不稳定的位置。如果你不主动扩张,别人会替你完成这个"挤压"过程。
那到底该往哪个方向整合?
Tanay 的文章没有给出明确的建议,但从他列举的案例和分析中,可以提炼出一个判断框架:
向下整合的前提是:你有足够多的 trace。
没有用量就没有数据,没有数据就训不出有差异化的模型。Cursor 能做 Composer 2,是因为全世界有几百万开发者每天在用它写代码——这些 trace 的规模和质量是独一无二的。如果你的产品日活只有几千,向下整合的意义不大。
向上整合的前提是:你理解行业的最后一公里。
AI 做不到的那 10% 往往是合规、审核、信任、人际关系。这些东西不写在代码里,写在行业经验里。Crosby AI 的创始人自己就是律师,WithCoverage 的团队来自保险行业。外行很难做这件事。
两条路的共同点是:都需要飞轮。
向下的飞轮:用量 → trace → 模型 → 产品 → 用量。
向上的飞轮:交付 → 数据 → 自动化率 → 毛利 → 投入 → 交付。
决定胜负的不是起点,而是飞轮转得多快。
1.纯应用层是一个过渡态。如果你的产品只是在别人的模型上包了一层 UI,你要么往下做模型,要么往上做服务。中间层不是安全地带。
2.trace 是新时代的数据护城河。不是通用数据,是特定领域的用户行为 trace。这也是为什么做 AI 产品要尽早获取用户——不只是为了收入,更是为了训练数据的积累。
3.AI 让"卖结果"变得经济可行。以前服务经济学太差,现在 AI 把最后一公里的成本压下来了。"Services-as-Software" 不再是一个概念,而是一个正在发生的商业模式变革。
4.模型公司、应用公司、服务公司最终会在同一个战场相遇。OpenAI 从底层往上,Cursor 从中间往下,Crosby AI 从顶层开始。三年后,你可能分不清谁是谁。
5. 这不是未来的事。Cursor 已经发了自己的模型,Intercom 已经宣布了"垂直模型时代",Crosby AI 已经在卖法律服务。垂直整合正在发生,而且速度比预期快得多。
相关链接:
• 原文:Tanay Jaipuria - AI Applications and Vertical Integration
• Cursor Composer 2 Technical Report
• Chris Dixon - Full-stack Startups (2015)
数据来源:Tanay Jaipuria (@tanayj)
文章来自于"深思SenseAI",作者 "深思SenseAI"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
