# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
什么情况?!世界模型成果这几天扎堆上线了。
就在刚刚,成立恰满一个月的阿里ATH(Alibaba Token Hub)事业群,发布全球首个主动式实时交互的世界模型产品。
名也挺有趣的,叫HappyOyster(快乐生蚝)。
据官方介绍,HappyOyster搭载原生多模态架构,背后是支持多模态输入与音视频联合生成的流式生成世界模型,核心主打漫游(Wander)、导演(Direct)、创造(Create)、分享(Share)。
怎么个漫游法,请看VCR:
输入生成滑雪场景的Prompt,HappyOyster立马给你造一个可交互小世界。你用WASD和上下左右方向键,就能实时控制角色位移、调整镜头视角,沉浸式穿梭在雪场里。
那“导演”又是什么玩法?
导演即实时AI视频导演引擎。传统AI视频是“输入prompt→等渲染→拿到一个固定成片”。HappyOyster让用户可以在视频生成的任意节点,用文字指令实时控镜头、调角色、改剧情走向。
画面即时响应,实现“边拍边改”:

至于“创造”,指的是把生成体验从“生成一段视频”,进化到“创造一个世界”。你不再是旁观者,而是能深度参与、全程掌控的创造者。
最后,你亲手创建的世界还能分享,让别人进来探索、二次创作。
不过,有一个坏消息:HappyOyster现在还需要申请邀请码才能体验。
但好消息是,量子位已经抢先解锁,这就带大家先来尝个鲜。
一张图总结Wandering漫游、Directing导演这两个核心玩法:
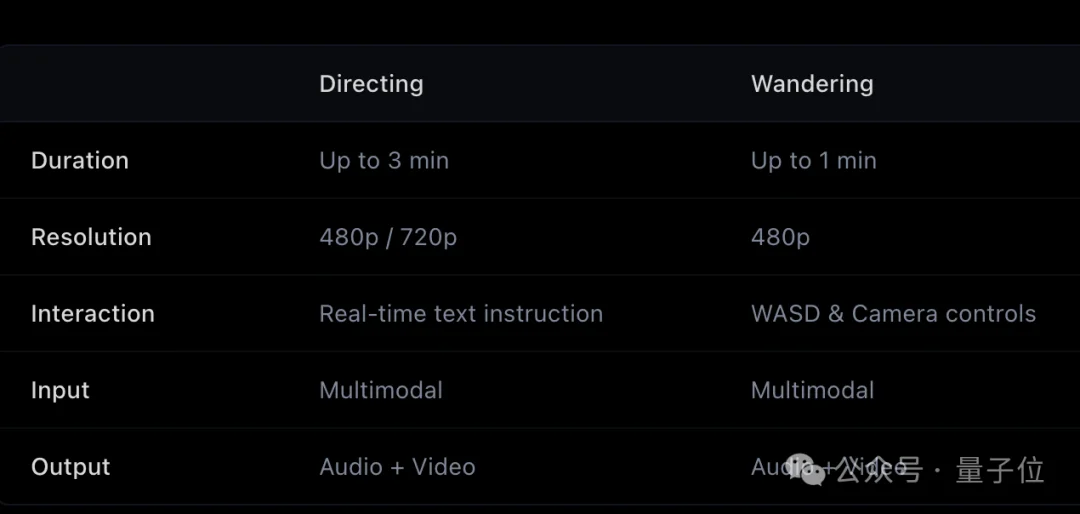
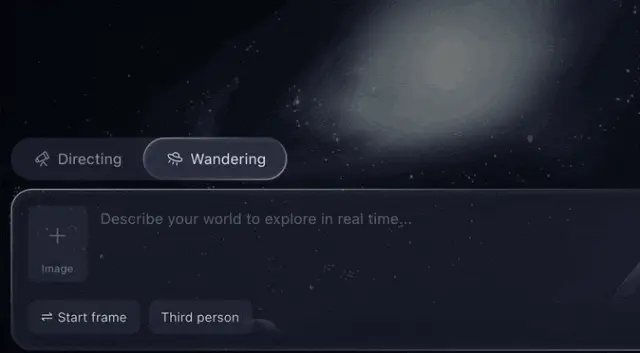
先具体来看Wandering漫游模式,支持文本、图片输入。
你可以直接输一句Prompt造世界,也能精细化控制,分别设定“角色(Character)”和“场景(Scene)”,还能自由切换第一人称或第三人称。
我们先浅试了一个海边小镇,一起来看效果:

让人眼前一亮的是,HappyOyster生成的世界自带BGM;而且不只是能生成场景——小镇里竟然还有NPC在走动,代入感拉满。
P.S. HappyOyster可在你探索世界的时候自动帮你录制视频,在个人主页的My videos可查看。录制好的视频支持下载。
目前,Wandering模式分辨率480p,而且探索时长目前有1分钟限制(时间到了需要重新进入)。
我们还试了一下像素风格:
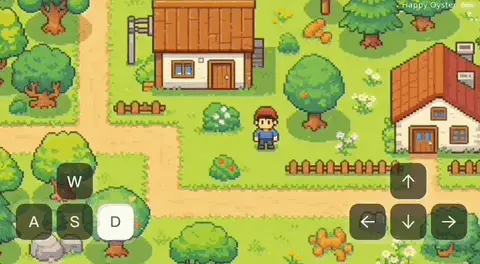
HappyOyster也能轻松驾驭,让你直接化身像素小人。
不得不提一嘴,HappyOyster生成速度是真的快,be like:

此外,Gallery(画廊)中还有别人分享出来的很多世界,也都可以点开探索:

比如梵高的油画世界,超梦幻:

下面再来看一下Directing导演玩法。
Directing同样支持文本、图片多模态输入。
用户可调整分辨率(720p、480p),设定视频画面的叙事风格与情感基调(Regular、Peaceful、Dramatic),控制视频的运镜方式与画面稳定度(Steady、Fast)。
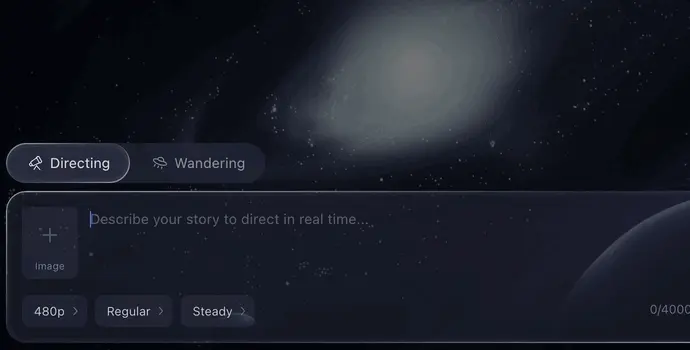
一句话总结玩法,你可在任意节点用prompt改变你眼前的内容,改变剧情走向。
举个例子,男孩正在熟睡,在输入框中输入“一只猫跳到了床上,男孩被吵醒”:

下一幕直接呈现你所描述的画面:

咱又找着别人造的奇幻世界了,一起来探索一下吧:

这里还有来自官方的更多展示:

当然,HappyOyster应用并不止屏幕里的沉浸式生成和交互。
在阿里ATH团队看来,HappyOyster的核心能力是对开放世界状态进行持续建模、预测与响应,天生就适合延伸到需要“实时感知—实时生成—实时反馈”闭环的现实场景中。
比如在文旅展陈、线下娱乐、机器人训练、数字人陪伴、教育演练、智能空间交互等方向,模型都可以作为一个实时演化的世界引擎,与摄像头、麦克风、空间传感器、显示终端、机械装置或可穿戴设备连接,根据人的位置、动作、语言和环境变化,动态生成对应的视觉内容、事件反馈或交互结果。
要是再和硬件系统结合,HappyOyster承载的就不只是“内容生成”,而是一个能被现实输入持续驱动的生成式环境系统。只能说,未来的应用场景打开了。
新产品发布的同时,阿里ATH事业群也向我们揭秘了其背后核心技术。
阿里ATH事业群,是阿里今年3月16日正式成立的创新事业群。团队打出的核心目标是“创造Token、输送Token、应用Token”。
ATH旗下涵盖通义实验室、MaaS业务线、千问事业部、悟空事业部及AI创新事业部,从基础模型研发、模型服务平台,到个人与企业端AI应用,布局得明明白白。
团队表示,HappyOyster的核心能力,源于其背后的原生多模态架构与流式生成世界模型,重点突破了三大核心技术难点,才实现了“实时交互、长时连贯、音画同步”的体验。
第一,长时世界建模,解决“生成久了就错乱”的问题。
HappyOyster采用长时间跨度的世界演化建模方式,靠海量长视频训练数据,深度学习真实世界的运行规律,捕捉世界持续运行中的状态转移逻辑,能稳定输出高保真、高一致性的动态场景。
针对长时间生成容易出现的内容漂移、结构退化问题,团队还加入了持续状态复用机制,强化时序连贯性。
流式生成时,模型不用每一步都重建完整上下文,而是通过历史注意力状态的连续传递,高效继承已生成信息、渐进更新,使生成始终沿既有时序语境扩展。
这种方式使其减少了上下文重建带来的不稳定性,在更长时间尺度上可维持稳定的场景结构与动态连贯性。

第二,实时交互控制响应。
HappyOyster在建模初期就设计了多样的控制信号(文本、Action、图像等),让世界生成和实时交互深度绑定。外部指令不再只作用于初始条件,而是持续影响后续的世界演化。
由此,模型能够在统一的时序框架下同时实现生成质量、长时一致性与实时可控性的协同优化。
团队表示,这一能力让模型从“被动生成内容”,升级到“主动模拟世界、让用户参与演化”,也为构建可交互的通用世界模拟器,提供了关键技术路径。

为了解决实时性训练难题,HappyOyster用流式生成框架实现实时世界演化:
模型通过对世界状态进行高度压缩的隐式建模,将高维视频与多模态信息映射为紧凑的动态latent state,大幅降低单步生成的计算开销,让推理能低延迟持续推进;
同时,文本、图像与wandering指令等控制信号被设计为可在线注入的条件变量,确保模型在无需重置生成过程的情况下即可实时响应外部交互。
第三,音视频联合生成,让世界更有“沉浸感”。
针对音画协同这一训练难点,团队并未采用将音视频分阶段建模的思路,而是采用统一的音视频生成框架,在同一世界状态下同步生成视觉与听觉信号。
在该机制下,音频作为世界动态的一部分参与联合生成,自然建立跨模态时间对齐关系;同时,通过共享条件约束与协同解码机制,保障音画同步与语义一致。
这些技术突破,让HappyOyster真正区别于传统文生视频模型。
正如团队所强调的,过去几年生成式AI完成了“文本→图像→视频”的跃迁,但始终停留在“生成像素”的阶段,用户只能观看,无法真正参与其中,这便是横亘在用户与数字世界之间的“第四面墙”。
而HappyOyster的核心目标,就是打破这道墙:
真正的下一代生成式AI,不再仅仅是把画面生成得更清晰,在那之上会进化到可以生成一个完整的、可进入的世界。这个世界有空间、有物理、有因果、有角色、有故事。你可以推门而入,可以亲手改写,可以离开又回来,也可以带朋友进去。
为啥取快乐生蚝这么个名?这背后还有小巧思呢。
官方解释:
四百年前,莎士比亚在The Merry Wives of Windsor里写下一句传世之言:
“The world is your oyster.Open it.(世界是你的生蚝,等你亲手打开).”
四百年后,Happy Oyster让这句话第一次成为字面意义上的现实:说一句话,就能拥有一个完整的、可漫游、可导演、可分享的数字世界。
官网链接:
https://www.happyoyster.cn/
OverView:https://www.happyoyster.cn/docs
文章来自于微信公众号 "量子位",作者 "量子位"


【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
