李飞飞的世界模型,终于开始训练机器人了
李飞飞的世界模型,终于开始训练机器人了李飞飞老师的World Labs,补了块关键拼图。
来自主题: AI技术研报
7428 点击 2026-07-29 14:22
 搜索
搜索
李飞飞老师的World Labs,补了块关键拼图。

Z Potentials 独家获悉,新加坡国立大学博士,牛津大学博士后研究员林庆泓(Kevin)近期以首席研究员(Principal Researcher)身份加入世界模型公司 Video Rebirth,负责多模态智能体与世界模型相关研究。

刚刚,BeingBeyond智在无界发布首个基于人类视频数据的隐式触觉世界动作模型—— Being-H0.8。
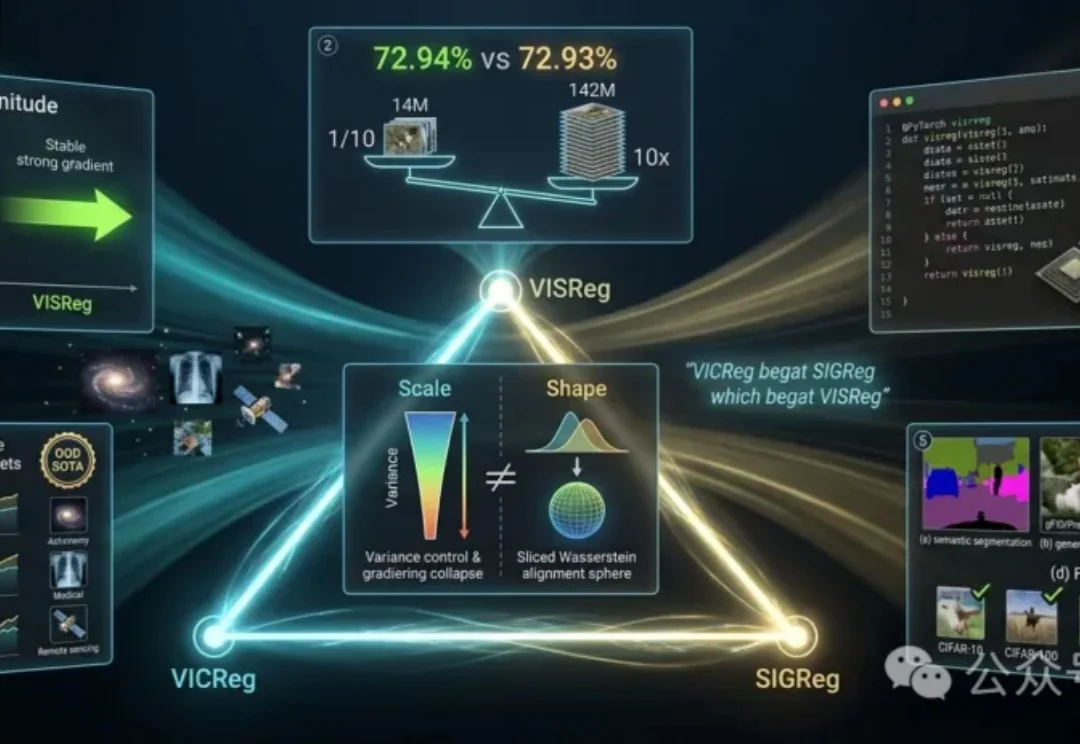
JEPA世界模型的底层是Yann LeCun自2017年起持续倡导的自监督学习(Self-Supervised Learning, SSL)。
当机器人拥有多个摄像头,它看到的世界是否仍然保持一致?
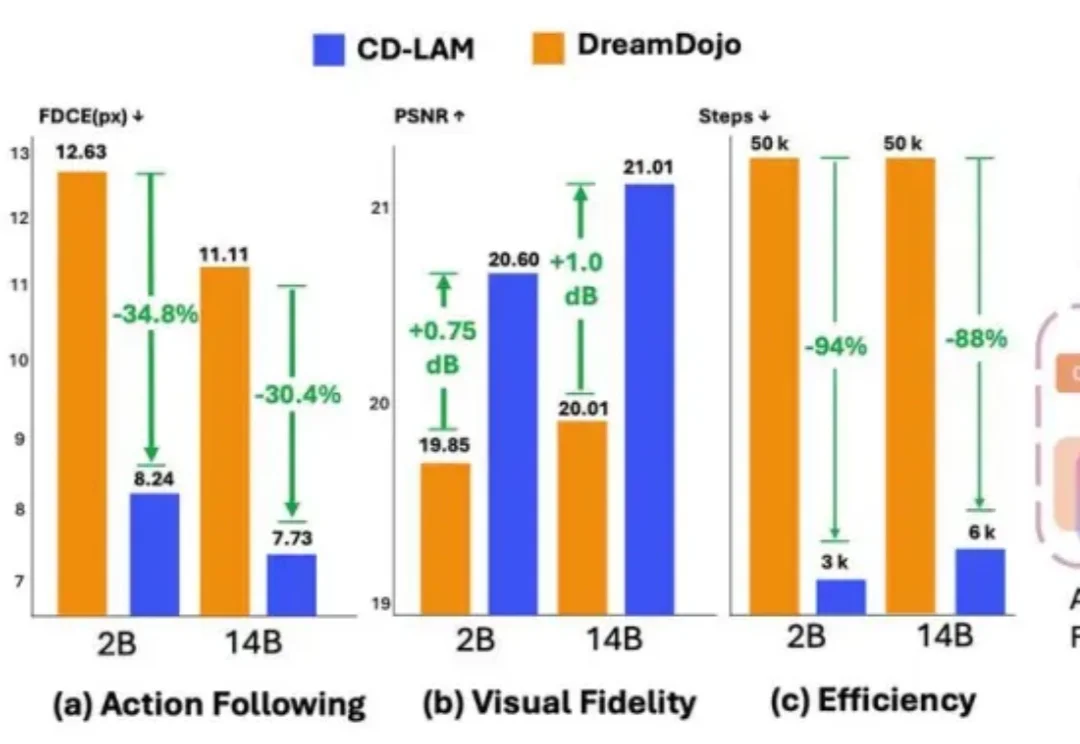
人类可以轻松想象一个还没做出的动作会带来什么:手一松,杯子会掉;往前一推,抽屉会合上。动作尚未发生,大脑已经预演了可能的结果。对机器人来说,具身世界模型(Embodied World Model)会根据当前观察和未来的动作,预测动作执行后的未来画面。
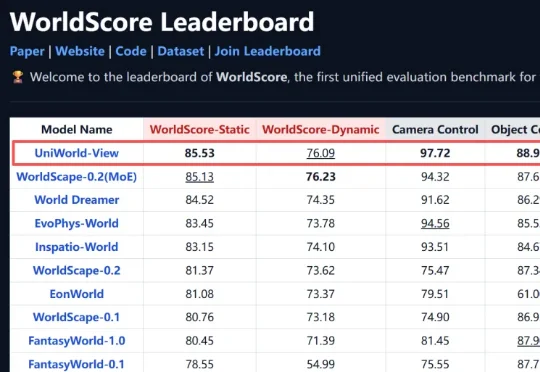
最近,兔展智能联合北京大学、鹏城实验室研发的 UniWorld-View 登顶李飞飞团队 WorldScore 世界模型榜单(训练数据来自北大系初创企业元空智能),并完成国产昇腾算力适配与代码、权重开源。
社会智能公司境瞳科技近日完成数千万元人民币天使轮融资,投资方包括英诺天使基金、水木清华校友种子基金、零以创投和驰星创投。这笔钱将主要用来扩大社会模拟器的规模,为社会世界模型的预训练做准备。

联想之星、银杏谷资本、啟赋资本等投了。
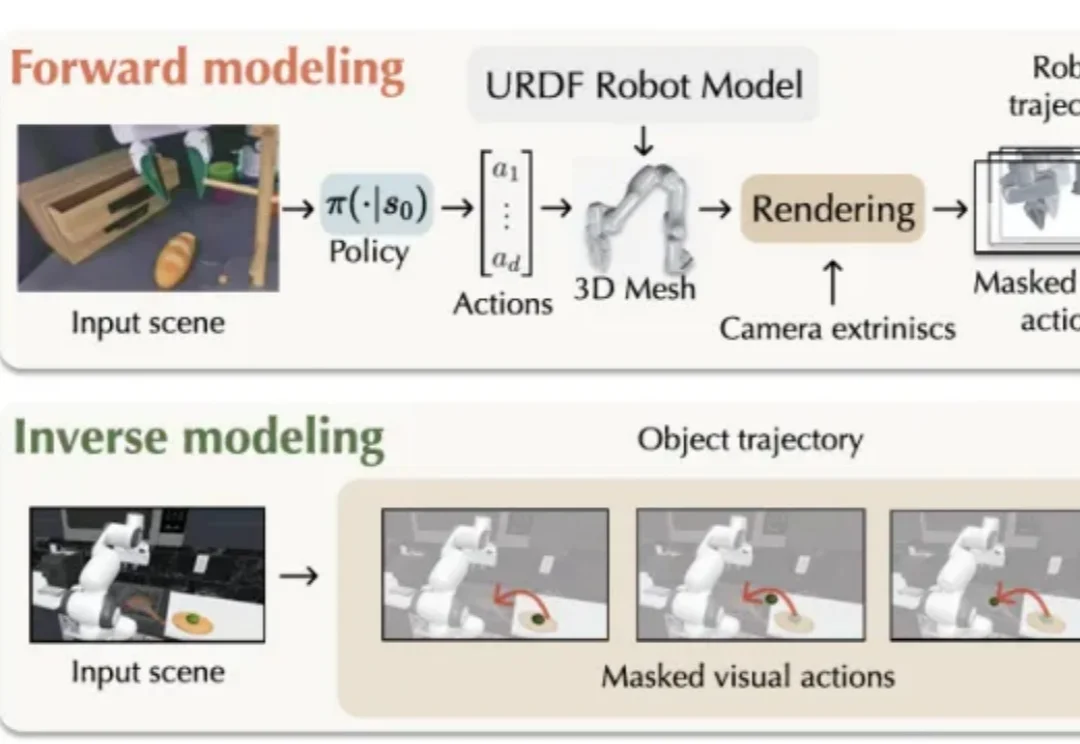
如果要让机械臂把咖啡机旁的杯子移到桌上,需要经历哪几个步骤?