# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Anthropic自己戳破了百万上下文神话?

https://claude.com/blog/using-claude-code-session-management-and-1m-context
近日,Anthropic一篇关于「如何管理百万上下文」的博客中再次提到了「上下文腐烂」(context rot)的问题,简单说就是:
上下文越长,模型越蠢。
Anthropic解释道,上下文窗口是指模型在生成下一条回复时能够「看到」的全部内容,它包括你的系统提示、迄今为止的对话内容、每一次工具调用及其输出,以及所有已读取的文件。
目前,Claude Code的上下文窗口为一百万个token。
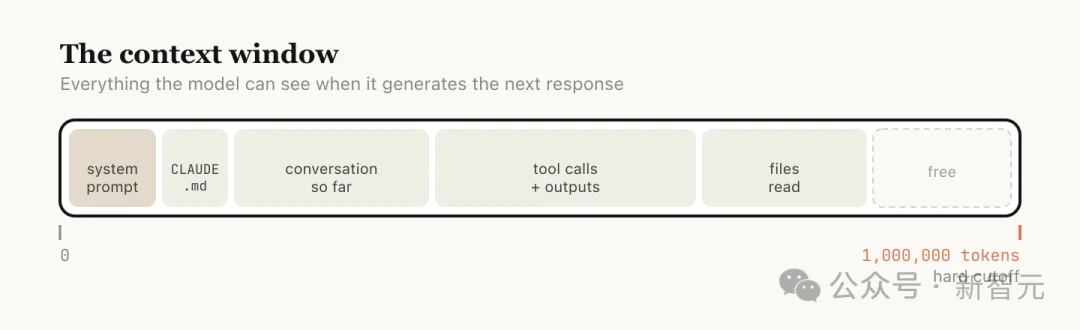
但上下文并非越长越好。模型的注意力被分散到更多token上,更早的、已经不相关的内容会开始干扰当前任务,导致表现下降,这就是「上下文腐烂」。

这并非社区自造的概念,而是出自Anthropic官方博客。
早在今年2月Sonnet 4.6发布时,公告里就写明了:Sonnet 4.6提供了测试版百万token上下文窗口。
但百万Token≠百万有效Token。
你往对话里塞的每一条消息、每一次文件读取、每一轮工具调用,都在稀释模型的注意力。
早期那些已经不相关的内容不会自动消失,它们会像噪音一样持续干扰当前任务。
提出问题后,Anthropic通过这篇博客给出了一套完整的管理方法。
先告诉你「你的对话在腐烂」,然后再手把手教你怎么治。
上下文越长
AI越蠢
先把「上下文腐烂」的机制拆开看。
100万Token听起来很多。
一个中型代码库,连文档带源码,可能也就几十万Token。理论上你可以把整个项目塞进去,然后随便问。
但模型的注意力是有限资源。
你两小时前读的那个配置文件、一小时前调试失败的那段日志、半小时前探索的一条死胡同,全都还在窗口里,全都在抢模型的注意力。
这就是context rot的机制:模型被迫同时「记住」太多不相关的东西,没法集中精力处理眼前的任务。
也许你会觉得,这不就和人类开会开久了走神是一个道理嘛。
的确如此。
信息过载导致注意力稀释,这与能力无关,是带宽问题。
更要命的是,当上下文快要撑到100万Token上限时,系统会自动触发「压缩」(compaction):
即把整段对话总结成一个更短的摘要,然后在新窗口里继续工作。
这听起来很智能,但自动压缩发生的那一刻,恰恰是上下文最长、模型表现最差的时候。
用最蠢的状态去做最关键的总结,这事儿本身就很难靠谱。
每一轮对话都是岔路口
Anthropic在博客里把每一次对话交互定义为一个决策节点。
每一轮交互结束后,你其实站在一个岔路口,不是只有「继续聊」这一条路。
第一条:Continue。在同一会话中发送另一条消息,直接继续聊。上下文还相关,没必要折腾。这是最自然的选择,大多数时候也确实够用。
第二条:/rewind。 连按两下Esc,跳回之前某条消息,从那里重新来。
官方博客里有一个很精准的判断:与其纠正,不如回退。
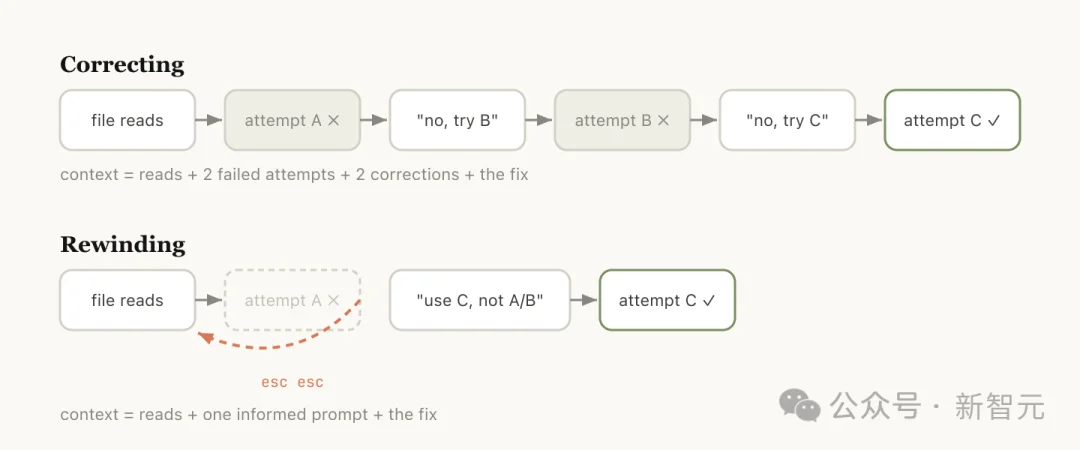
回退(Rewind)通常是更佳的修正方式。
比如Claude读了五个文件,试了一种方法没成功,你的本能反应是说「这个不行,换个方法」。
但这样做的问题是,那次失败尝试的全部中间过程还留在上下文里,继续污染后续判断。
更聪明的做法是rewind到读完文件那个节点,带着新信息重新发一条更精确的指令:别用方案A,foo模块没暴露那个接口,直接走B。
有用的文件读取保留了,失败的尝试丢掉了。上下文干干净净。
你也可以让Claude总结它学到的内容并创建一条交接信息。这有点像未来的Claude给过去的自己留了一封信:这条路我试过了,走不通。
第三条:/clear。开启一个新会话,附带一段简要说明:之前做了什么、现在要干什么、哪些文件相关。
好处是零腐烂,上下文完全由你控制。坏处是费事,所有背景都得你自己写。
第四条:/compact。让模型总结当前对话,用摘要替换掉原来的历史记录。
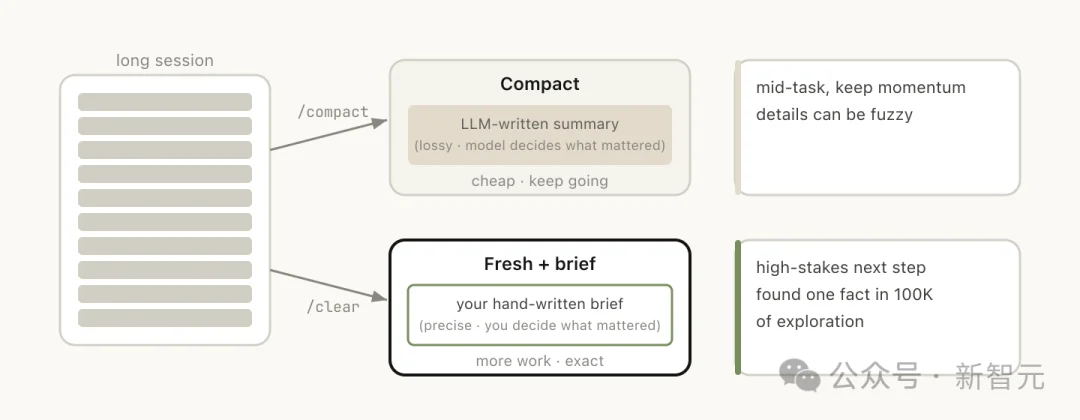
省事,但有损。
你可以附上引导指令:/compact focus on the auth refactor, drop the test debugging(聚焦认证重构,删掉测试调试。)
让它知道什么该留什么该扔,而不是去猜。
/clear和/compact看起来相似,但行为截然不同:
/compact由模型决定什么重要,你省心但可能丢关键信息,而/clear由你自己写下关键内容,费事但精确。

第五条,Subagents。
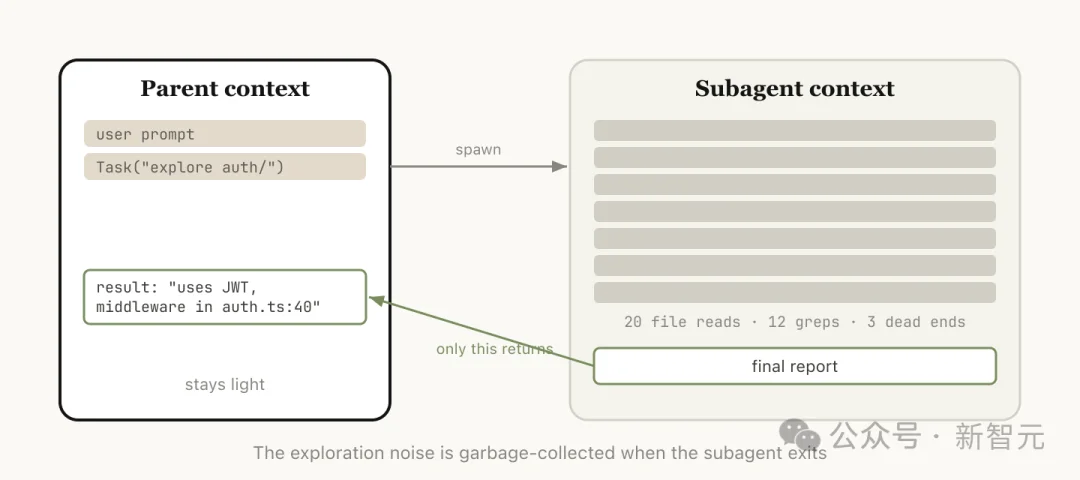
把一块工作交给一个拥有独立上下文的子智能体,干完活只把结论带回来。
当你知道接下来的任务会产生大量中间输出,但你只需要最终结论时,subagent是最干净的方案。
它拿到一个全新的独立上下文窗口,在里面完成所有脏活,中间过程全部留在子窗口里,最后只有一份结论带回主会话。
Subagents:你的一次性调查员
这五个动作里,最容易被误解的就是subagents。
很多人一听「子智能体」就往「多智能体协作」上联想:团队分工、并行处理、AI员工开会讨论。
但Anthropic这篇博客里讲的subagents,核心价值只有一个:上下文隔离。
官方文档明确写道:每个subagent都运行在自己的上下文窗口中。
它可以读大量文件、做大量搜索、跑完整个调查流程。但最终,只有摘要和一小段元数据会回传给主会话。
那些海量的中间过程,全部留在子智能体的一次性上下文里。你的主会话不会被这些噪声污染。
Anthropic内部用的判断标准也很简单:
我之后还需要这些工具输出本身吗,还是只需要最终结论?
如果答案是后者,就交给subagent。
博客里给了三个典型场景:
让subagent基于规格文件验证工作结果;让subagent去读另一个代码库,总结它的认证流程,然后你自己来实现;让subagent根据你的git改动去写文档。
这三个场景有一个共同点:过程很重,结论很轻。
所以subagent的本质不是你的同事,和你在一块干活,更像是你的「一次性调查员」。
它的工作簿在任务结束后就可以扔掉,你只需要拿走最后那页报告。
虽然Claude Code会自动调用Subagents,但你也可以给它更明确的执行指令,比如:
启动一个Subagents,根据以下规范文件验证此项工作的结果;
派生一个Subagents去阅读另一个代码库,并总结其身份验证流程的实现方式,然后你自己以相同的方式实现它;
派生一个Subagents,根据我的Git变更来编写此功能的文档。
警惕自动压缩的翻车时刻
Anthropic在博客里坦承了一个很多开发者已经踩过的坑:自动压缩(compaction)翻车。
什么时候翻车?当模型无法预测你接下来要干什么的时候。
博客举了一个例子:
你做了一次很长的调试会话,自动压缩触发了,模型把整个排查过程总结了一遍。然后你突然说:「现在修一下bar.ts里那个warning。」
但因为整个会话主要围绕调试展开,那个warning只是中途顺带看到的一眼,压缩的时候已经被丢掉了。
这事棘手在哪?触发自动压缩的那一刻,恰恰是上下文最长、模型表现最打折的时候。
你让一个已经「走神」的模型来决定什么信息重要、什么可以丢掉。
好在百万Token窗口给了一个缓冲区。
你不用等到自动触发,可以提前主动/compact,并附上说明:接下来要做什么、哪些信息必须保留。

用最清醒的时候做压缩,而不是等到最糊涂的时候被动挨打。
说到底,自动压缩不是不能用,是不能盲信。
五条路
一个急救包
虽然最自然的做法就是继续下去,但另外四个选项可用于帮助你管理上下文。
这五条路拼在一起,本质上就是一套防治「上下文腐烂」的急救包。

Anthropic官方示意图:五种上下文管理动作,从左到右保留的旧上下文越来越多
官方博客在文末放了一张决策表,按场景匹配工具:

每一次回车,都是一次上下文决策。
五种场景,五个工具,选对了上下文干净,选错了模型变蠢。
因此,每一轮交互之后,都该花一秒钟想想:我的上下文还干净吗?接下来该走哪条路?
百万上下文的另一面
是百万token的账单
除了管上下文质量,Anthropic这次还做了另一件事:
让开发者看见自己的消耗。
博客开头就说了,/usage这个新命令的推出,「来自我们和客户进行的多次交流」。
/usage是干什么的?
根据Claude Code官方命令文档,它的作用是「显示套餐使用上限和速率限制状态」。
注意,这不是一个上下文管理工具。
它不压缩、不回退、不清理,只做一件事:让你看见自己用了多少,还剩多少,有没有撞上限流。
但这恰恰是开发者最焦虑的事。
100万上下文听起来很美,但token不是免费的。
一个长会话跑下来,你到底消耗了多少配额?自动压缩会不会在你不知情的情况下触发,丢掉关键信息?你离速率限制还有多远?
以前这些问题没有答案,现在Anthropic给了一个透明窗口。
这个功能很小,但表明Anthropic已经意识到,百万上下文时代,「用得起」和「用得好」是两个必须同时解决的问题。
光给能力不给可见性,开发者迟早会踩坑然后流失。

提示词工程之后
是上下文工程
退一步看全局。
今年2月,Anthropic发布Sonnet 4.6,公告里确认了100万token上下文窗口(beta)。

那篇公告解决的是「能不能」的问题:模型能不能撑住这么长的上下文。
用户反馈也很正面:它在改代码前更能有效读取上下文了。
4月15日这篇博客,解决的是「怎么用」的问题。它直接承认了现实局限,然后给出一套系统化的管理方法。
两步合在一起,构成了一个完整的闭环:先给你武器,再教你怎么用不伤到自己的钱包。
Prompt engineering这几年被讲烂了。但真正决定AI编程天花板的,可能是下一个词:context engineering(上下文工程)。
怎么喂上下文、什么时候清理、哪些信息该隔离、哪些该保留,这些问题以前靠直觉,现在Anthropic开始给方法论了。
上下文工程,正在成为AI编程时代的必修课。
参考资料:
https://claude.com/blog/using-claude-code-session-management-and-1m-context
文章来自于微信公众号 "新智元",作者 "新智元"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
