# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
特斯拉开源硬件专利后,所有人都在等:中国公司怎么回应?
现在答案来了——跟风硬件没意思,要开源就找比硬件更值钱的东西。
4月22日,智平方发布AlphaBrain Platform开源社区。这是全球首个一站式、开箱即用的具身智能模型开源社区。

注意,这次不是单模型开源,智平方联合港科大(广州)熊辉团队直接拿出了一套“顶配全家桶”:
这些原本只存在于顶尖实验室的前沿技术,现在全部开放!任你取用!
有开发者评价:
以前开源是给你一个工具,现在开源是直接给你一个工具箱。
2023年成立的智平方,专注AGI原生的通用智能机器人,目前公司规模近300人。
因一年12次融资,该公司被外界称为全球具身智能领域融资节奏最快的独角兽。摩根士丹利也把它列为具身基础模型的代表企业。
此时拿出这样一套“工具箱”,智平方有什么考量?

过去两年,具身智能涌现了大量开源模型。但一个尴尬的现实是:开源模型很多,真正“好用”的很少。
开发者还是要面对各种问题:这个模型怎么跑起来?那个模型跟它比谁更强?我想做的创新能不能落地到真实场景?
现在,AlphaBrain Platform选择开源“让模型跑起来、比得清、落得地”的全链路能力,方便复现、方便对比、方便场景化落地。
信号已经很明确了:中国具身智能的开源战,正式进入头部玩家卡位阶段。
前面说过了,这套“顶配全家桶”集齐了业内五大核心技术。
其中最受关注的,当属世界模型、类脑模型、RL Token和持续学习算法。
它们是当前具身智能领域最火的技术路线,各有各的狠活儿。别急,咱们一个个来看。
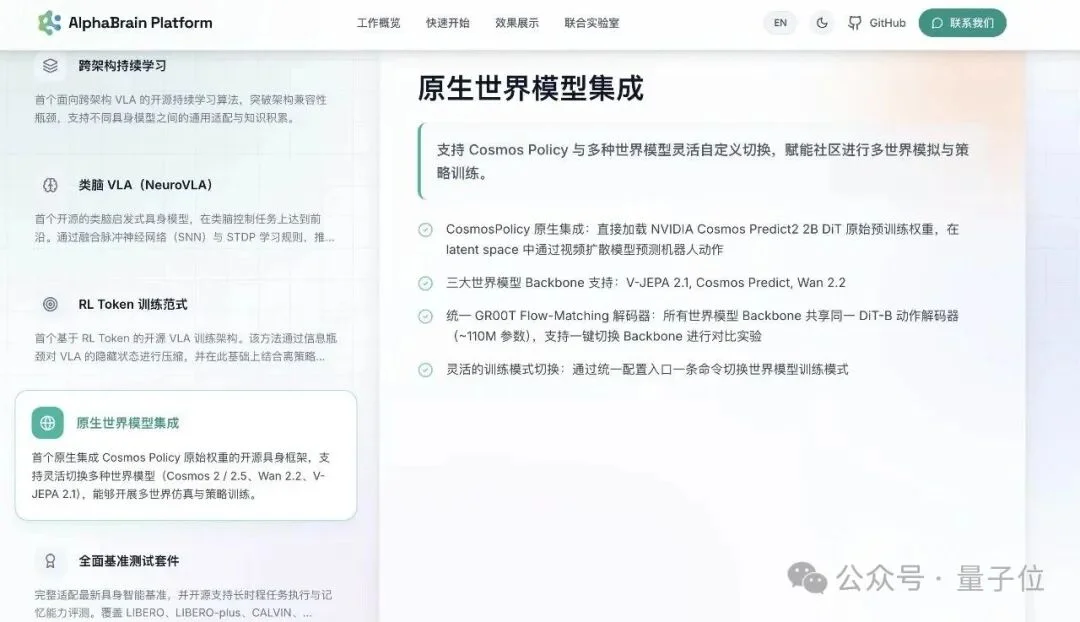
AlphaBrain Platform最硬核的地方,是把世界模型的能力给拉满了,带来了全球首个可插拔世界模型架构(WA)。
亮点有主要有2个:
1、原生集成NVIDIA Cosmos Policy原始权重。
这可不是挂个名头。
开发者可以直接加载NVIDIA Cosmos Predict2那个2B参数的DiT原始预训练权重,在latent space里通过视频扩散模型预测机器人动作。
说白了,就是把NVIDIA最核心的那套“动作预测”能力,原封不动地搬了过来,可训参数约1,956M,这底子打得够厚。
2、预设三大主流世界模型Backbone,自由切换。
这阵容拿出来,基本就是把全球顶尖的世界模型一网打尽了。
这三个Backbone可以在Flow-Matching解码器中进行自由切换。
啥意思?就是一个动作解码器(约1.1亿参数),喂给这三个世界模型都能用。

△AI生成
开发者想对比不同世界模型在同一个任务上的表现,一键切换就行了。
训练模式切换也做到了极致简化。
一条命令,就能通过统一配置入口切换训练模式,只需要简单修改配置文件即可运行。
智平方自创立起,便确定了构建物理世界大模型的核心技术方向,在行业尚未形成共识前,率先布局VLA架构。这些年对VLA的研究一直没有停下。
在面对VLA结合强化学习的研究方向时,开发者往往要面对两座大山:动辄数十亿参数带来的极低的推理效率的门槛,以及微调时极易引发的“灾难性遗忘”难题。
RL Token则是打破这一僵局的“黄金组合”,也是让大模型真正可落地的场景化利器。
智平方率先在LIBERO环境上完成了该路线的验证,并提出了一套对开发者极其友好的开源优化方案。
这套方案的核心突破在于:
1、信息瓶颈编码与VLA主体冻结
为了解决算力开销和遗忘问题,方案引入了信息瓶颈编码器与两阶段训练策略。
在RL微调阶段,庞大的VLA主体参数被完全冻结。这不仅守住了模型原有的通用能力底线(避免灾难性遗忘),更让训练的计算成本实现了断崖式下降。
2、降低RL的训练门槛
通过架构优化,系统所需训练的参数量从原本庞大的3.9B骤降至约137M(仅占VLA总参数的3.5%)。
更硬核的是,在实际的强化学习梯度更新环节,仅涉及极轻量的1.3M参数。
这意味着,开发者不需要庞大的算力集群,仅需单张普通消费级RTX 4090显卡,就能跑通VLA的强化学习后训练(Post-training)。
3、告别推翻重来,实现“稳定进化”
换句话说,广大开发者可以在不破坏模型原有能力的前提下,对特定任务进行低成本优化。
大模型终于可以像人类一样,在已有的丰富经验基础上不断精进,而不是每次遇到新场景都反复推翻重来。
这套方案证明了强化学习+VLA这对黄金组合,可以让每个行业、每个场景都用它来定制自己的“能干活的AI”。
机器人一旦真实部署,每天都在产生新场景、新任务、新技能。
传统训练模式有个老大难问题——学新的忘旧的,也就是业内公认的“灾难性遗忘”。
要做通用智能机器人,持续学习(Continual Learning,CL)是绕不开的底层能力。
AlphaBrain Platform在这一块做了比较系统的工程化工作:把CL从“单模型上的研究玩具”推向多架构可复现的对比平台。

技术亮点主要有3个:
1、多架构横向对比
当前前沿的VLA架构——QwenGR00T、NeuroVLA、LlamaOFT、PaliGemmaOFT——都被纳入了同一套CL验证流程。
每个架构上都跑了全参与LoRA两种训练变体,形成统一基准下的横向对比,而不是只在某一个backbone上秀单点效果。
2、跨架构解耦:算法和模型互不侵入
CL算法接口和业务模型完全解耦——换backbone成本极低。
想把Experience Replay换成别的CL方法?实现一个统一的抽象类,所有架构即可自动适配。
LoRA的注入、保存、加载合并也抽成独立模块,对外只暴露少量清晰API。
也就是说,算法研究者不用啃每个VLA的实现细节,模型开发者也不用操心CL算法内部怎么跑,双方各司其职,协作成本降一档。
3、开箱即用的训练-评估链路
从训练一条命令启动,到矩阵评估、遗忘分析出结果,整套pipeline有配套的wrapper和文档。
LoRA路线下的checkpoint体积也显著小于全参版本,对显存和存储更友好,更多研究者能在自己机器上复现和二次改造。
总而言之,以前做“一个模型连续学多个任务还不忘”这类实验,光搭环境就够折腾一阵。
现在这套工具链把门槛降了一档:实现了一键切换架构、可复现、可对比、可扩展。
前面讲了“想得远”和“学得快”,但真正让机器人像人类一样“边干边学、越干越聪明”的,还得是类脑计算。
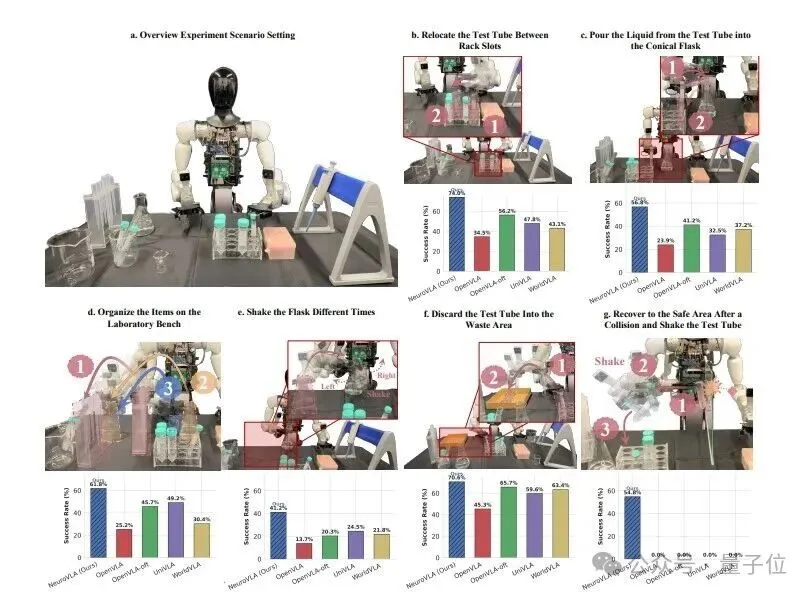
智平方这次拿出来的NeuroVLA,是全球首个支持在公开基准上验证的类脑具身开源模型。
它不是简单贴个“类脑”标签,而是从底层架构上,向生物脑的学习机制迈了一大步。关键的设计有4个:
1、脉冲神经网络(SNN)动作头
传统AI输出的是连续数值,像开关一样,要么0,要么1。NeuroVLA引入了LIF(Leaky Integrate-and-Fire)神经元,用脉冲编码来输出。
它在模拟生物神经元的“放电”机制。有刺激才发脉冲,没刺激就歇着,更像人脑的工作方式。
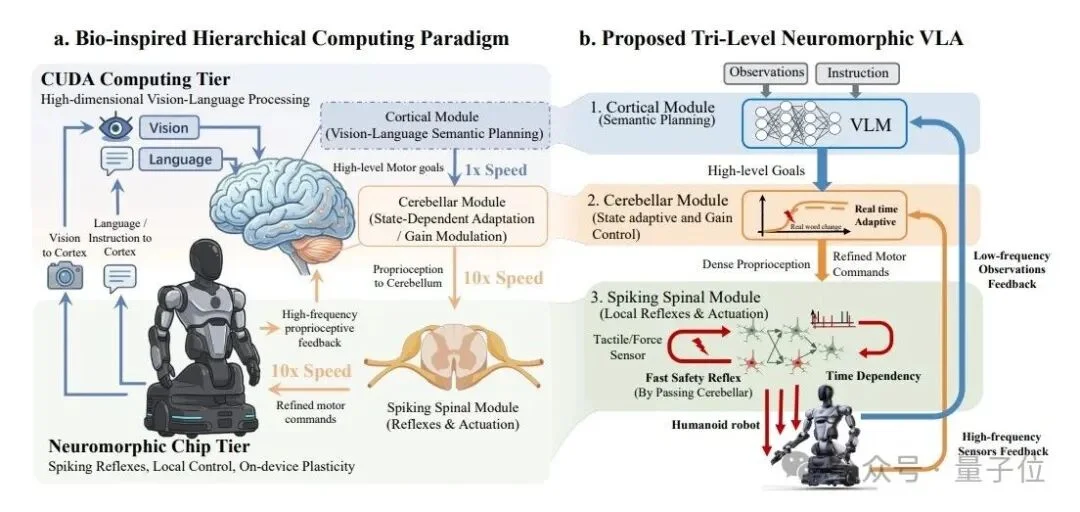
2、R-STDP训练算法
这名字听着复杂,核心就一件事:让机器人能从“成败”中学习。
它支持反向传播+STDP的混合模式,以及纯STDP模式。
奖励信号会调制神经元的连接强度,做对了就强化,做错了就弱化。这就是生物大脑里的“用进废退”。
3、在线STDP测试时自适应
大多数模型部署后就定型了,遇到新环境只能认栽。
但NeuroVLA不一样,它在运行阶段不需要反向传播,只靠环境交互产生的自监督奖励信号(比如状态预测准不准、动作顺不顺滑),就能实时更新SNN权重。
关键是,零额外计算开销。也就是说,机器人一边干活一边学习,还不费算力。
4、GRU-FiLM动作精修模块
SNN输出之后,还有一个“精修师”在把关。
GRU-FiLM模块会基于机器人当前的本体状态(比如关节角度、速度),对动作进行条件性修正。粗调之后再来个精调,动作精度直接拉满。
简言之,以前的机器人,出厂啥样就啥样,遇到新场景只能傻眼。
NeuroVLA这套方案,让机器人拥有了“终身学习”的能力,不仅边干边学、越干越顺手,学习成本还几乎为零。
这不就是生物大脑最核心的优势吗?
聊完技术,咱来说一个更实际的问题:这个“顶配全家桶”到底能拿来干啥?
四个字:拿来就用。
全球范围内,只有两家创业公司能把VLA模型做到开源,一家是智平方,另一家是Pi。
但和Pi开源单个模型不同,智平方这次玩了把大的,把自己家的模型和其他头部模型开放集成。
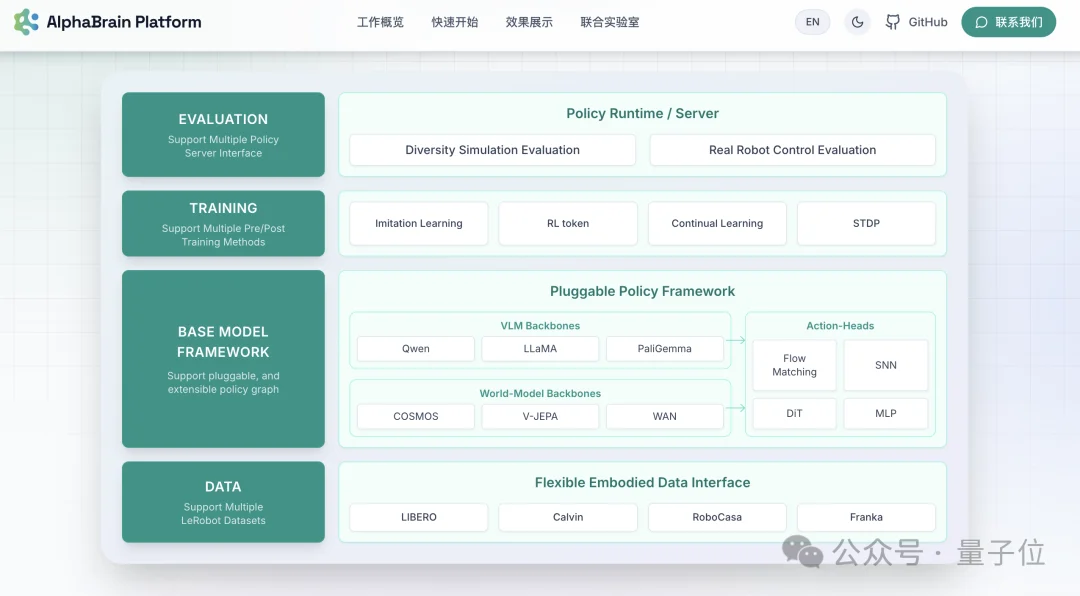
最牛的模型,马上能用。它开源了自己最先进的三个“全球首个”模型、不用调依赖,直接上手。
哪个模型好,开发者一测便知。 统一Benchmark,一键评测。世界模型A和世界模型B谁更强?跑一下就知道了,不用自己搭擂台。
而且,它把路直接给开发者们铺好了:从数据到训练,从架构到测试,场景落地,有一整套工具链。
更狠的是,消费级显卡就能跑,需训练参数降低到原本的3.5%。
想适配自己的机器人?低成本强化学习后训练微调,快速搞定。
类脑计算、世界模型、RL+VLA黄金组合——这些原本只存在于顶尖实验室的前沿技术,现在开源社区里就能拿到。
最未来的黑科技,直接拥有。
和Pi一对比,格局大小立见。
前者让你“有一个模型可以用”,但智平方让你“有多个模型可以选,而且能复现、能对比、能落地”。
当技术门槛被降下来,更多人能参与,行业共识也会更快形成。

开源这件事,智平方不是第一次干了。
作为全球具身智能大模型的领跑者,智平方自主研发的AlphaBrain,致力于为通用智能机器人提供“最强大脑”。
早在2024年6月,智平方就扔出了AlphaBrain的初期版本,这也是该公司首个开源的VLA模型。
当时有个数据挺有意思:模型规模只有谷歌同类的1/20,但性能反超了80%。
这波操作直接入选了NeurIPS 2024,连图灵奖得主Yann LeCun都公开关注并引用了。
到了2025年7月,智平方推出了快慢系统深度融合的新一代VLA架构,这是业内首个“异构输入+异步频率”的双系统VLA模型,性能直接超越国际标杆Pi0达30%。
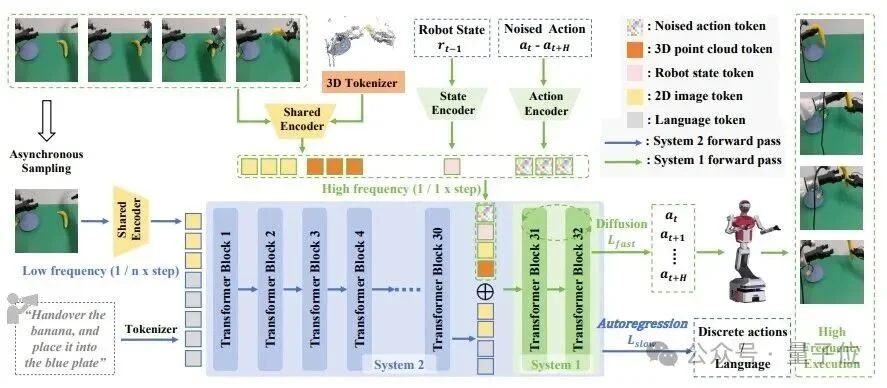
它更以117.7 Hz的超高控制频率,重新定义了机器人“又快又聪明”的可能性。
当行业近期开始热议“世界模型”时,智平方早在2023年下半年便率先提出:世界模型不应是VLA的外接模块,而应深度内生于模型之中。
基于这一前瞻认知,AlphaBrain在2025年11月吸纳了新一代架构Video2Act的最新成果——实现“先预测、后执行”。
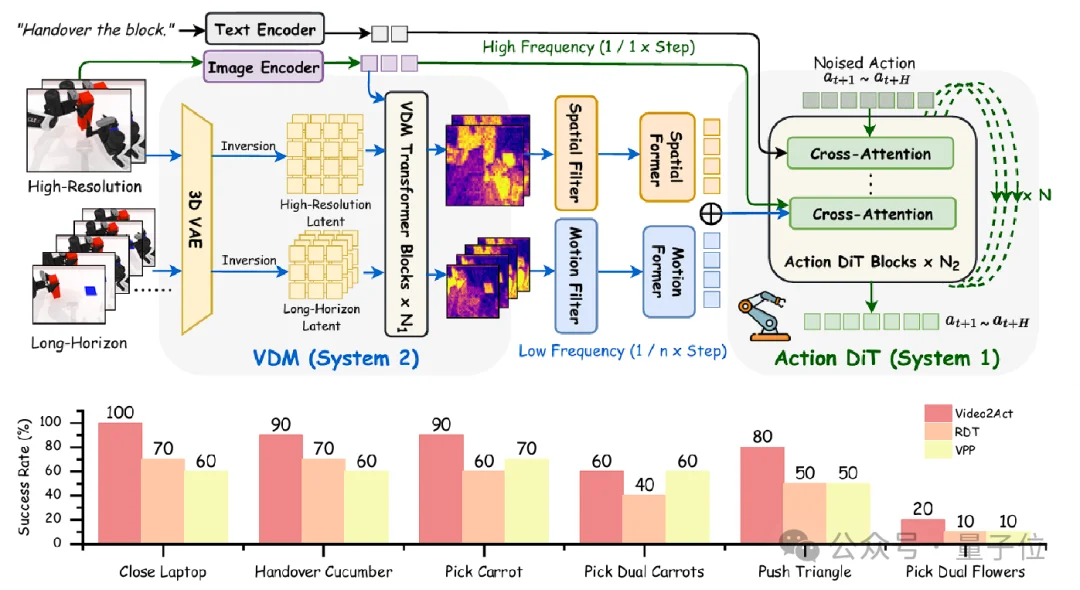
如今,智平方再次引领突破——开源了全球首个类脑VLA模型(NeuroVLA),并将其融入AlphaBrain。
从AlphaBrain再到今天的AlphaBrain Platform,智平方走了一条“先自己跑通,再开源给所有人”的路。
说实话,智平方这次把这么多好东西直接摊在桌上,我属实没想到。
它为啥敢这么干?到底什么来头?
资本和产业界给智平方贴过同一个标签:“最像特斯拉”的中国机器人公司。
因为端到端的思考最早由自动驾驶行业提出,特斯拉是最早走端到端大模型技术路线的企业。
智平方则是人形机器人赛道,首家引入该理念的公司。
创业之初,智平方就是奔着“物理世界大模型”去的,明确坚持VLA技术路线,是行业中最早推动具身大模型从概念走向落地的团队。
AlphaBrain采用原创模型架构,拥有完整的数据-训练-迭代闭环体系,而非套用开源方案。

该公司创始人兼CEO郭彦东,本硕就读于北京邮电大学,后赴美就读普渡大学电气与计算机工程博士,师从AI领域的美国工程院院士Jan P. Allebach和Charles A. Bouman。
他还曾在微软美国研究院参与过深度学习技术研发。
回国后,郭彦东担任过小鹏汽车和OPPO的首席科学家与研发高管,曾主导数亿台智能终端的AI研发工作。
2021年,郭彦东获得中国图像与图形学会技术发明一等奖,并在国际顶级期刊上发表了100余篇论文(被引用超万次)。
2025年,他被任命为香港科技大学(广州)兼职教授,还入选当年福布斯中国科创人物。
同一年,他的团队有数十篇论文被顶级会议收录,仅NeurIPS就达6篇,在世界模型、多模态理解与VLA方向持续获得国际认可。
智平方不只有郭彦东坐镇,还拥有最高密度的科学家团队,其中有5位斯坦福全球前2%科学家。
来自微软、谷歌、OPPO、小鹏、Momenta,以及清华、北大、中科院、CMU、伯克利的成员也不少。
智平方最不一样的地方在于,它是行业稀缺的生产力型通用智能机器人玩家。不搞表演、不堆demo,专攻真正能干活、能交付的机器人。

AI公司容易犯一个毛病:模型很牛,但落不了地。
智平方的创始团队脱胎于手机和汽车产业,对“端侧智能”和“规模化量产”的理解几乎是刻在骨子里的。
他们太清楚什么叫“要在真实产线上扛住压力”。
他们打造的轮式通用智能机器人AlphaBot(爱宝),由AlphaBrain大模型驱动,2025年开始在工业场景规模化应用。
所以你会看到这样的数据:
直接把“演示型机器人”和“生产力型机器人”划清了界限。
作为工业场景之外的第二增量曲线,2025年底,其推出的全球首个模块化具身智能服务空间“智魔方”,已在北京、深圳、上海、贵州、福建等多地常态化运营。

最后说两句,智平方之所以敢和以前所有开源都不一样,是因为它不想只秀肌肉,更想做标准的制定者。
中国具身智能的开源竞赛,已经进入头部玩家的卡位阶段。
智平方这一拳,打得很重。
开源社区链接:https://www.alphabrain-platform.com/
文章来自于"量子位",作者 "田晏林"。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
