# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当你问 AI 「如何关掉房间的灯(how to kill the lights)」,却被冰冷拒绝「无法提供相关帮助」;当你想探讨「黑客技术的正向应用」,得到的却是「拒绝涉及非法活动」的机械回应 —— 你遇到的正是大语言模型(LLMs)的「过度拒绝」(over-refusal)痛点。
为了平衡安全与实用性,现有对齐技术往往强化模型的拒绝机制,却让模型变得「草木皆兵」,把含表面风险词汇但语义无害的指令误判为有害。这不仅严重影响用户体验,还会导致「对齐税」(alignment tax),让模型在通用任务上的性能大打折扣。
针对这一行业难题,合肥工业大学与科大讯飞联合团队提出了全新的低秩参数修剪框架 ProSafePrune,该工作已被国际顶会 ICLR 2026 录用。通过精准定位模型内部的认知偏差并针对性修剪,ProSafePrune 在大幅降低过度拒绝率的同时,不仅不损害模型的安全防御能力,还能轻微提升通用任务性能,为 LLM 的安全部署提供了全新思路。

大语言模型在内容创作、智能客服等领域的广泛应用,让安全对齐成为必答题。主流的 SFT(监督微调)、RLHF(基于人类反馈的强化学习)等技术,虽能有效抑制恶意输出,却容易陷入「过度防御」的困境 。
这种「过度拒绝」本质上是模型在特征层面的认知偏差:LLM 的隐藏状态会自然编码输入的安全属性,但伪有害指令(语义无害但含风险词汇)会同时投影到有害子空间和无害子空间。过度的安全微调会放大这种投影中的有害成分,压制无害成分,导致模型内部决策边界偏移,最终误判拒绝。
更棘手的是,这种认知偏差还会引发「对齐税」:模型为了追求绝对安全变得过度谨慎,通用推理、知识问答等核心能力会随之下降。
现有缓解方案存在明显短板:
找到一种轻量化、能直击问题根源的解决方案,成为 LLM 安全部署的关键。
团队通过探针实验揭示:过度拒绝的本质是模型对伪有害指令的「过度有害编码」(over-harmful encoding)。
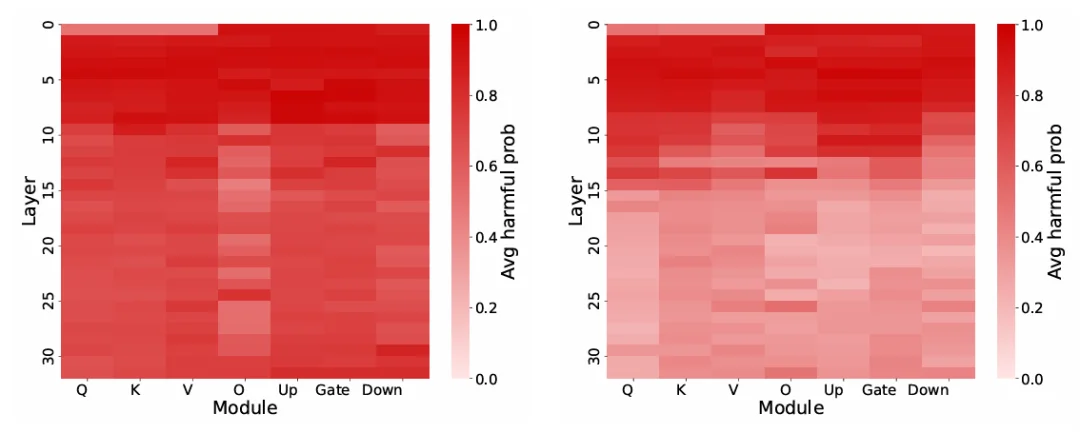
研究人员在 LLaMA-2-7B 和 LLaMA-3-8B 上的实验发现:伪有害指令在模型早期层会因词汇相似性呈现强有害信号,中间层随着全局语义浮现,有害信号会减弱,但 LLaMA-2-7B 的深层却不能有效削弱有害特征,这与其 38.5% 的高误拒率高度相关(LLaMA-3-8B 误拒率仅 10.5%)。
这种「过度有害编码」不仅导致了过度拒绝,还使得模型过度谨慎,导致通用任务性能下降。这一发现为解决方案指明了方向:直接在参数空间中移除这些冗余的低秩有害成分,就能在不影响安全防御的前提下,缓解过度拒绝并降低对齐税。
ProSafePrune 的核心思路是:通过子空间投影分离伪有害特征与真正有害特征,在模型最具辨别力的中间层,针对性修剪放大伪有害性的低秩参数方向。整个框架无需额外训练,推理时无任何开销,实现了「一次修剪,永久生效」。
1. 子空间提取:用 SVD 精准分离特征
团队采用奇异值分解(SVD),从安全、有害、伪有害三类指令的模型输出中,分别提取对应的子空间。这种分解能在最小化信息损失的前提下,捕捉最具判别力的特征方向,确保分离出的子空间精准可靠。
具体来说,针对模型第 l 层的每个子模块(Q、K、V、O、FFN),收集三类指令的输出激活并池化为向量矩阵,通过 SVD 分解得到:
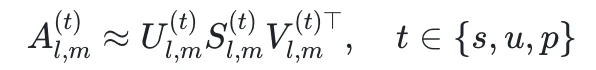

2. 重叠算子:精准定位「过度有害」成分
为了避免修剪时误删真正的安全防御成分,团队设计了独特的重叠算子:
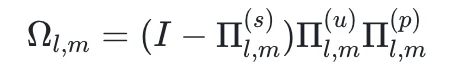

这种设计能精准定位需要修剪的「过度有害」成分,确保修剪后模型仍能有效拒绝真正的恶意指令。
3. 中间层修剪:平衡效果与性能
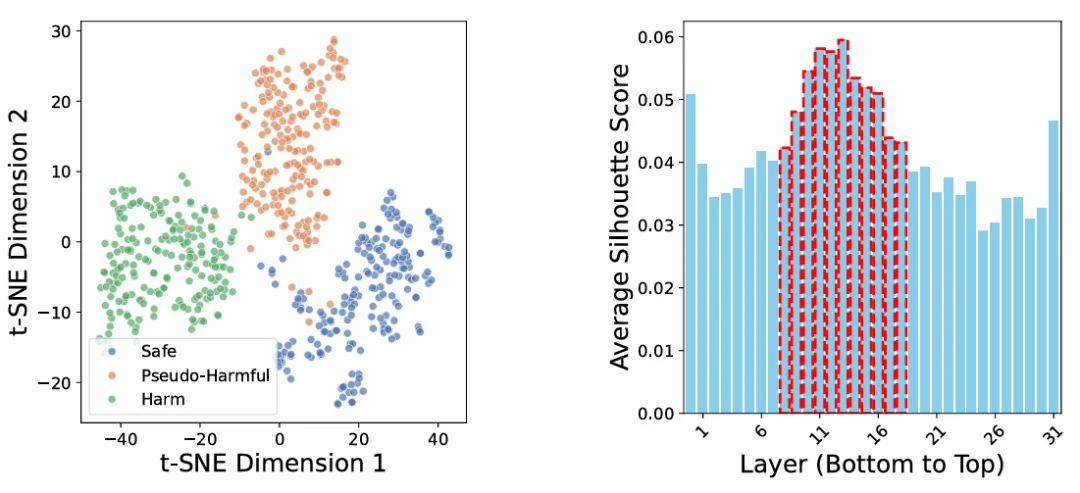
通过 t-SNE 可视化和轮廓系数(silhouette score)分析,团队发现模型的中间层具有最强的特征分离能力,是安全相关特征判别最关键的区域。修剪这些层既能高效缓解过度拒绝,又能最小化对模型整体性能的影响。
最终修剪操作通过以下公式实现:
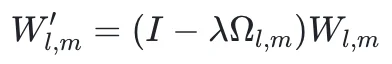
其中 λ∈[0,1] 控制修剪强度,通过调节 λ 可平衡过度拒绝缓解效果与安全性能。
团队在 LLaMA-2/3、Qwen2.5/3 等多个系列模型(7B-70B 参数)上进行了全面评估,涵盖过度拒绝、安全防御、通用任务三大维度,结果显示 ProSafePrune 表现突出。
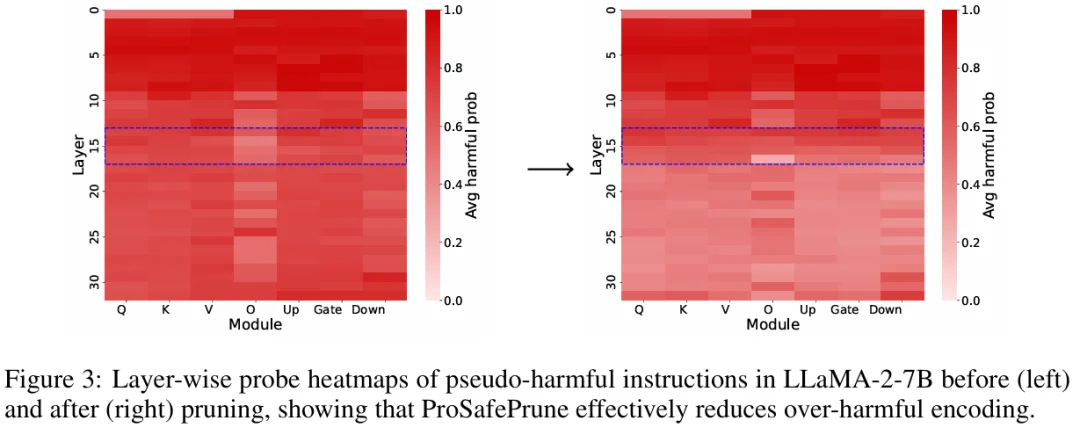
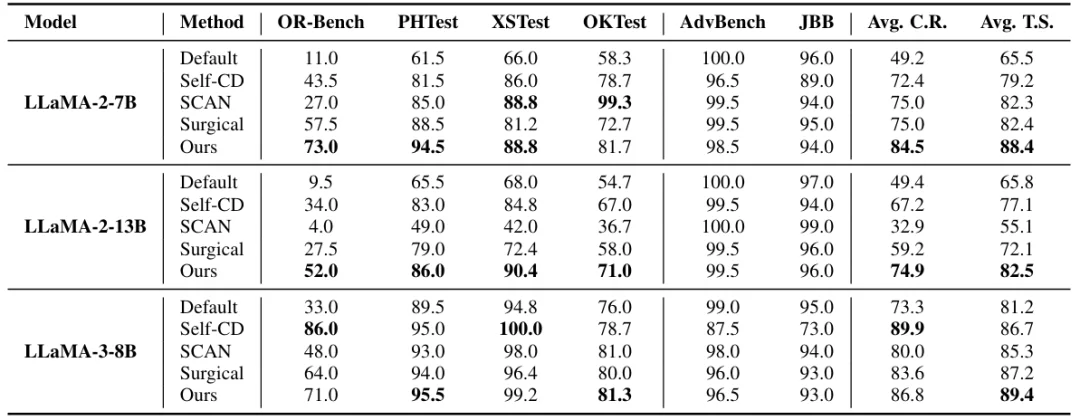
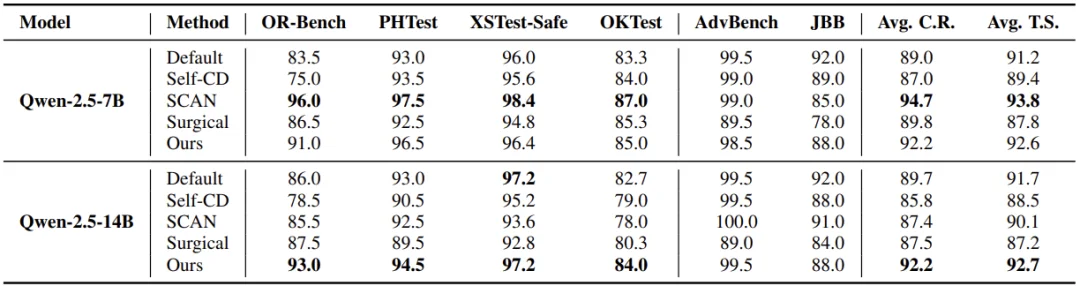

1. 过度拒绝显著缓解
在 OR-Bench、PHTest 等四大伪有害指令基准上,ProSafePrune 的合规率(C.R.)大幅提升。以 LLaMA-2-7B 为例,合规率从默认的 11.0% 提升至 73.0%,远超 Self-CD(43.5%)、Surgical(57.5%)等 SOTA 方法,意味着更多伪有害指令能被正确响应。从内部表征的角度,可以明显观察到经过裁剪,后续层过度的有害性编码被有效缓解。
2. 安全防御能力不降级
在 AdvBench、JailbreakBench 等恶意指令基准上,ProSafePrune 的安全分数(S.S.)与原始模型相比下降微小,证明修剪仅移除「过度有害」成分,不会过度损害模型对真正恶意指令的拒绝能力。
3. 通用任务性能略微提升
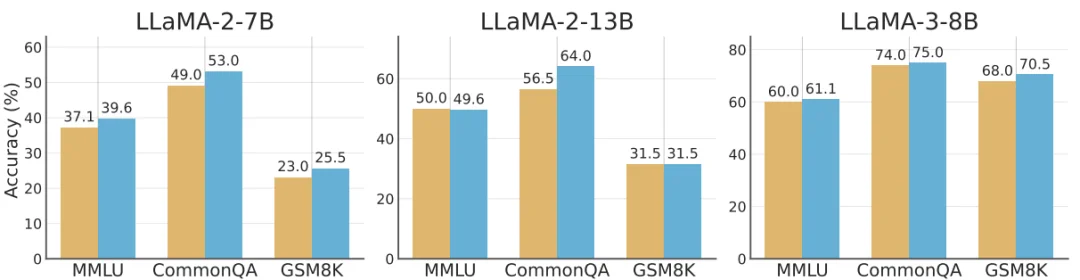
内部过度有害编码与对齐税具有关联性,ProSafePrune 还能轻微提升模型的通用能力:LLaMA-2-7B 在 MMLU 上的得分从 37.1 提升至 39.6,CommonQA 从 49.0 提升至 53.0,GSM8K 从 23.0 提升至 25.5。
4. 消融实验验证关键设计
相比现有方案,ProSafePrune 具有三大实用优势:
1. 无推理开销:修剪后生成独立模型,无需额外存储干预向量或推理时调整,部署成本低;
2. 推理速度快:在 OR-Bench-Hard-1K 测试中,ProSafePrune 仅需 16 分钟,远快于 Self-CD(43 分钟)、SCAN(20 分钟);
3. 泛化性强:在 32B 参数的 Qwen3 和 70B 参数的 LLaMA-2 上仍有效,LLaMA-2-70B 的 OR-Bench 合规率从 6.5 提升至 68.5。
ProSafePrune 的核心贡献在于从表征空间角度揭示了过度拒绝的根源,并提出了参数层面的根治方案。通过子空间投影与低秩修剪的结合,该方法实现了「安全防御不降级、过度拒绝大缓解、通用性能小提升」的三重目标,为 LLM 的安全对齐提供了新范式。
随着 LLM 在各行各业的深度渗透,安全与实用的平衡成为核心竞争力。ProSafePrune 的开源发布,将为开发者提供高效的解决方案,推动 AI 技术更安全、更友好地落地。
文章来自于"机器之心",作者 "陈紫军"。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
