# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,苹果又整了个活儿,很工程、也挺关键:
把又贵又强的 Transformer,改造成又便宜又差不多强的 Mamba。而且,性能基本没怎么掉。
听起来炸不炸?有点像水电煤级别的升级。
为啥要折腾这个?很简单,Transformer 确实猛,这十年基本就是靠它打天下。但问题也很现实:它越长越贵,而且是平方级变贵。
短文本还好,一旦上到长上下文(比如代码、agent、多轮推理),那成本就不是有点高,而是直接肉疼。

于是,大家就开始找替代方案。比如线性 attention、RWKV,还有这两年很火的 Mamba。这些模型的思路都很统一:别再平方爆炸了,改成线性。好处也很直接:更快、更省显存、推理更丝滑。
但问题来了, 它们不够强。尤其一旦规模上去,和 Transformer 还是有差距。于是就卡住了一个经典局面:
要性能?用 Transformer(但贵) ;
要便宜?用 Mamba(但弱一点);
那有没有可能「既要又要」?能不能不重训,把 Transformer 的能力,直接搬到 Mamba 上?

直接蒸馏,性能肯定得崩。Transformer 像那种随时翻资料的学霸, Mamba 更像全靠记忆的选手。你突然让一个翻书型选手闭卷考试,还不给过渡—— 那基本就是灾难现场。

苹果没有硬刚,而是搞了一个「两步走」:
先造一个「中间形态」,让 Transformer 先变成一个更简单、更接近 Mamba 的版本。再从这个中间版本,转成 Mamba。
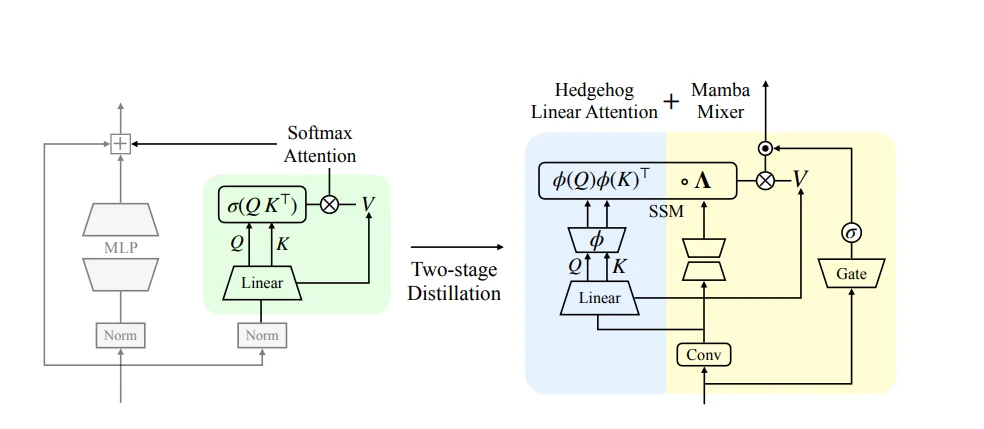
用来把 Transformer 里原本计算很贵的 Softmax Attention,换成一个更省算力的 Mamba 模块。中间加了一个过渡形态:先把 Attention 变成一种学出来的线性 Attention(Hedgehog),再结合 Mamba,最终得到一个混合模块,叫 HedgeMamba。
第一步,把原始的 softmax attention 换成一种线性 attention,同时尽量不丢性能。
问题在于,传统线性注意力一直有明显短板,和 softmax attention 的表现差距很大。为了解决这个差距,他们依据Mercer 定理,用了 Hedgehog 方法,用一个小型神经网络(MLP)去学习一种特征映射,让线性 attention 尽量模仿原来的行为。
再通过余弦相似度(cosine similarity)蒸馏,让这个新结构在输出上对齐 Transformer。这一步做完,相当于得到一个「更便宜但还挺像 Transformer」的中间模型。

第二步,是把这个已经对齐好的线性 attention,进一步嵌入到 Mamba 结构里。
他们做了一件很关键的事情:把 attention 里的核心计算方式,对应映射到 Mamba 的内部参数上,让 Mamba 在初始化的时候,行为就已经接近前一步的模型,而不是从零开始学。这一步本质是在做结构对齐。
不过,还有一个问题需要处理。原始 attention 自带一种归一化机制,而线性版本没有,所以他们额外加了一步归一化,让输出形式更接近原来的 attention,同时又不破坏计算效率。
完成这些之后,才进入真正的训练阶段。
他们对整个模型做微调,用标准的交叉熵训练,并重新启用 Mamba 原本的能力,比如卷积和门控( Gate )机制。这一步的作用,是让模型不只是模仿,而是用自己的方式把能力重新学出来。
整套方法的关键不在某一个技巧,而在这条路径本身:先让两种模型在「表达方式」上对齐,再做结构转换,最后通过训练把能力恢复出来。
也正是因为这样分步处理,才避免了直接蒸馏时常见的性能崩塌问题。

效果到底咋样?性能几乎没掉,但成本逻辑已经变了。
论文里最关键的一张表,把三类1B模型摆在一起对比:Transformer教师模型(Pythia)、传统蒸馏基线( Hedgehog ),以及他们的方法( HedgeMamba )。在只用10B token(大约是教师训练数据的 2.7% )的情况下,结果非常直接——
教师模型的困惑度是 13.86,基线方法掉到 14.89,而HedgeMamba把这个指标拉回到 14.11,已经贴得很近了。

他们用一个大约10B token训练出来的1B模型做实验,最后得到的 Mamba 模型能够保留原始 Pythia-1B Transformer 在下游任务中的性能,其困惑度(perplexity)保持在 14.11,接近老师模型的 13.86。
这件事的含义其实挺重的。
过去大家默认一个前提:只要你把 Transformer 换成另一种架构,性能就会明显掉一截。
但这篇论文给出的答案是,这个损失可以被大幅追回来。而且,不只是语言建模指标好看,在Arc、PIQA、BoolQ、RACE、LogiQA 这些下游任务上,HedgeMamba基本全面超过基线,同时整体表现已经逼近教师模型。这说明它保留下来的不只是表面的概率分布,而是相当一部分推理能力和语义结构。
更关键的是,这种效果不是调出来的,而是有方法论支撑的。他们尝试过最直接的做法——从 Transformer 一步蒸馏到 Mamba,结果是 PPL 直接炸到 100 以上,几乎不可用。
换句话说,两阶段蒸馏在这里不是优化,而是绕不过去的结构性条件。

后面的消融和分析,其实是在解释这条路径为什么成立。
比如,架构上,真正起作用的不是简单叠模块,而是门控机制——也就是让模型学会该记什么、不该记什么;
训练策略上,两阶段的数据分配也不是平均最优,而是明显偏向第二阶段,说明中间表示只是过渡,真正的能力是在后半段完成迁移;
再看数据规模,从1B 到 10B token,性能是稳定往上走的,没有出现不收敛或反复震荡的情况,这一点很重要,因为它说明这条路线是可以规模化放大的。
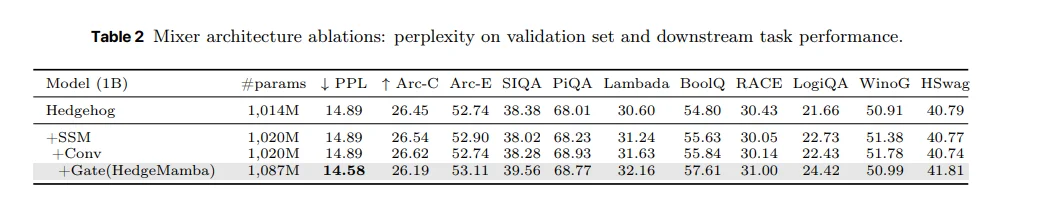
架构消融实验表明,让 Mamba 好用的关键,不是简单堆结构,而是门控机制。
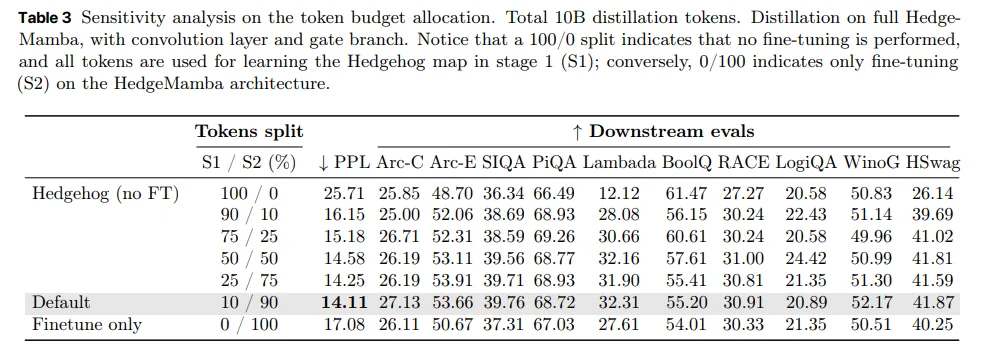
蒸馏的两步(S1 和 S2),数据到底该怎么分配才最有效?两阶段蒸馏是必要的,而且最优策略是轻S1 + 重S2。
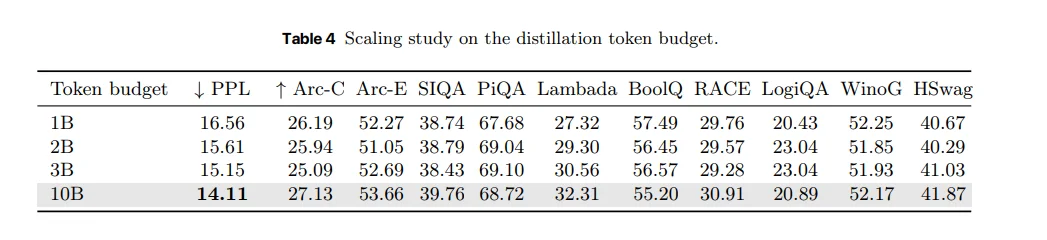
蒸馏过程中 token 数量(训练数据量)对效果的影响。似乎只要给足够多的蒸馏数据,Mamba 可以逼近 Transformer 的性能。
把这些信息合在一起,这篇工作的价值就不在「又做了一个更好的模型」,而在于它提供了一种新的工程可能性。
过去几年积累的大量 Transformer 模型,并不需要全部推倒重来,而是有机会通过一套流程,被「转制」为更高效的形态。
如果这件事能稳定复现,那整个开源模型生态、甚至很多公司的自研模型,都有机会被整体降本重构。
参考链接
https://arxiv.org/abs/2604.14191
文章来自于"机器之心",作者 "Sia"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
