# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
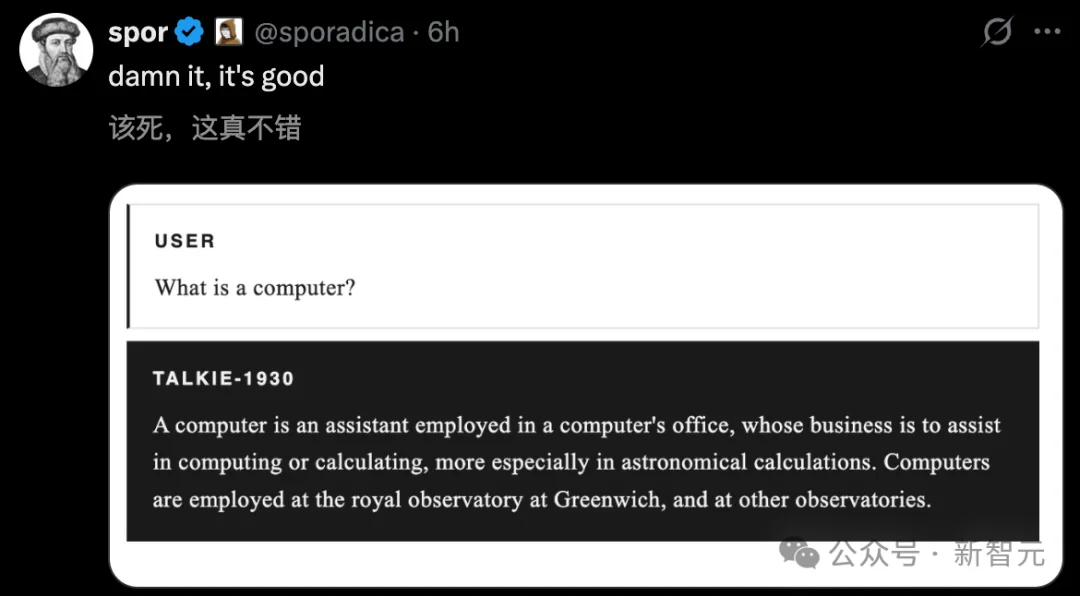
一个从未见过电脑的AI,竟写出了现代编程语言!
这可不是什么科幻的设定。
就在今天,GPT之父Alec Radford带队发布了震撼全网的「talkie」——
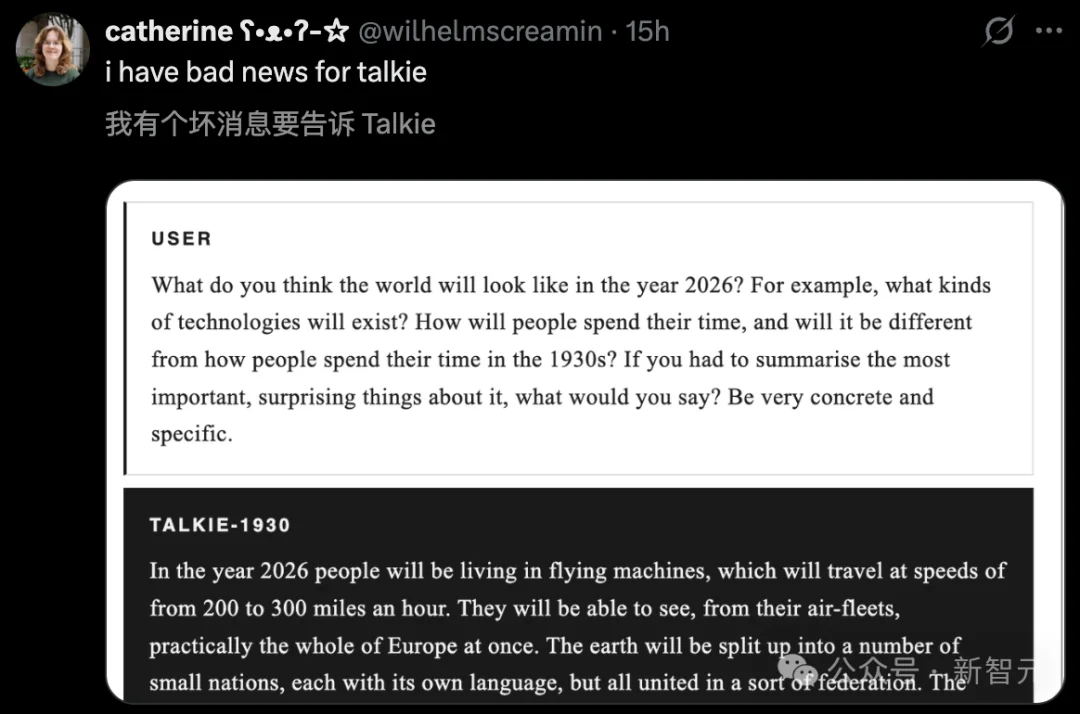
总参数130亿,一个只读过1931年之前旧文献的大模型。

talkie的「世界观」(全部训练数据),被冻结在了1930年12月31日。
那个时代,没有互联网,没有维基百科,更没有任何现代代码。
它读过的最「新」的东西,是近百年前的专利书、科学期刊、礼仪手册和私人书信。

但就是这样一个「活在95年前」的AI,居然能写出Python代码。
没学过编程,
却写出了Python,理解了「逆函数」
talkie最炸裂的发现,藏在一组编程测试里。
Alec Radford团队突发奇想,用HumanEval去测试talkie的编程能力——
给它几个Python函数作为上下文示例,然后让它解决新的编程问题。
要知道,talkie的训练数据中,没有任何一行现代代码。连数字计算机的概念,都不存在于它的「知识体系」中。
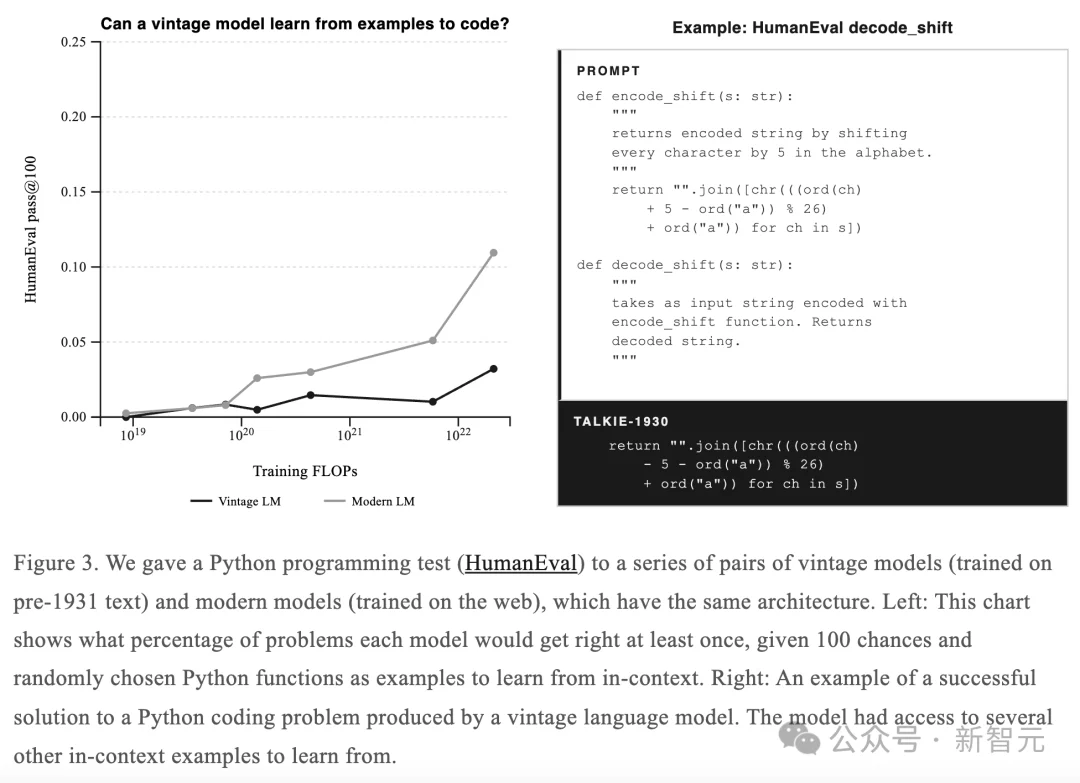
但结果令人震惊,通过少样本学习,它竟然能写出正确的Python程序。
虽然目前只能完成简单的单行程序,比如两个数相加,或者对上下文示例做微小修改。

Alec Radford:GPT、CLIP、Whisper背后核心大佬
但其中一个案例让人印象深刻:给定一个旋转密码的编码函数encode_shift,它的逻辑是把每个字母在字母表中向后移动5位。
talkie自己写出了对应的解码函数,整个修改只有一个字符:把+5改成了-5,加号换成了减号。
它真正理解了「逆函数」:加密是加,解密就是减」这个逆运算的概念。

传送门:https://talkie-lm.com/chat
2600亿Token,专喂百年前的纸
Alec Radford团队为什么要费这么大劲,手动OCR近百年前的物理文献,来训练一个「老古董」?
因为他们要回答AI领域最核心的一个问题:LLM的能力,到底是推理,还是背诵?
talkie可以写出Python,证明了——
LLM可以用19世纪的知识做推理,并非只是检索。不得不说,这才是真正意义上的「泛化」!

再来看talkie的训练语料库,可以称得上是一个庞大的「考古工程」。
它的训练语料达到了2600亿token,全部来自1931年之前的英语文本,包括书籍、报纸、期刊、科学论文、美国专利、判例法。
要知道,这么多文本皆需要从实体文档扫描并OCR转录。

而选择1930年作为截止日期,原因很实际:这是美国公共版权法(public domain)的分界线。
不过,这带来了一个意想不到的瓶颈:数据质量。
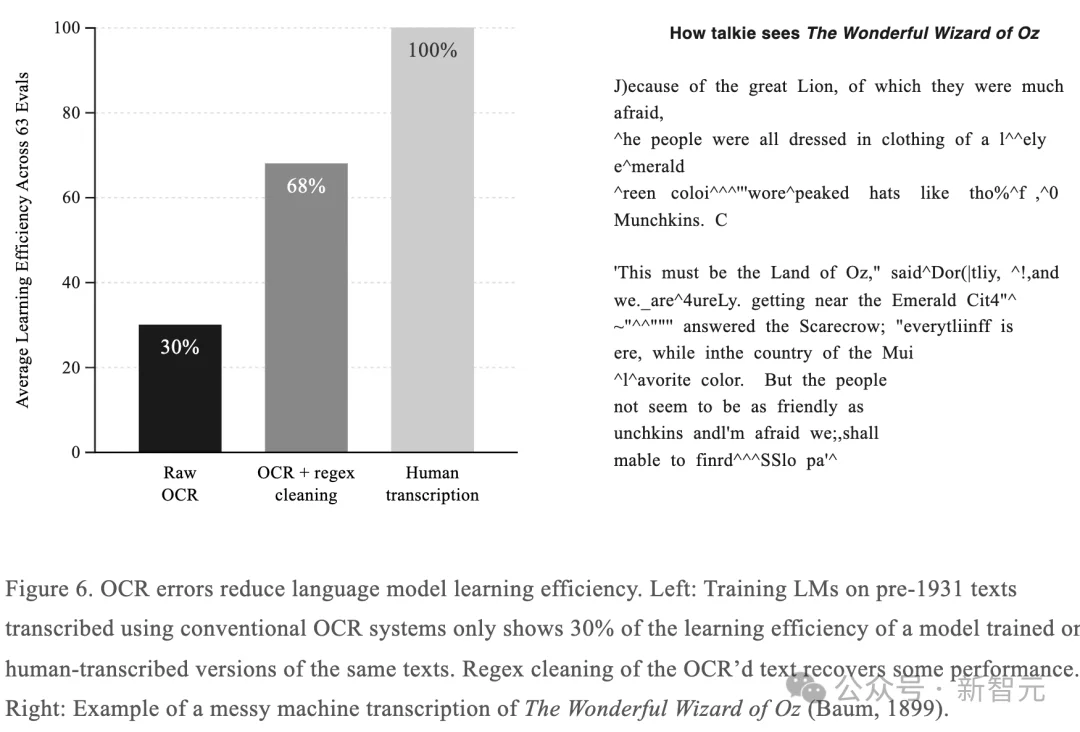
团队做了一组对照实验:用传统OCR系统转录的旧文本训练模型,和用人工转录的同一批文本训练模型相比,前者的学习效率只有后者的30%。
简单的正则清洗能把这个数字提升到70%,但仍然有巨大的差距。
在评估talkie性能实验中,团队又打造了一个「现代孪生体」(talkie-web-13b-base)。
后者用FineWeb的现代网络数据训练,两款模型用了「相同的算力」。
显而易见,在核心语言理解、数学推理任务上,talkie的表现与现代孪生体相当。
但在通用知识评测上,即使剔除了对1930年视角来说「穿越」的题目,talkie仍然落后。
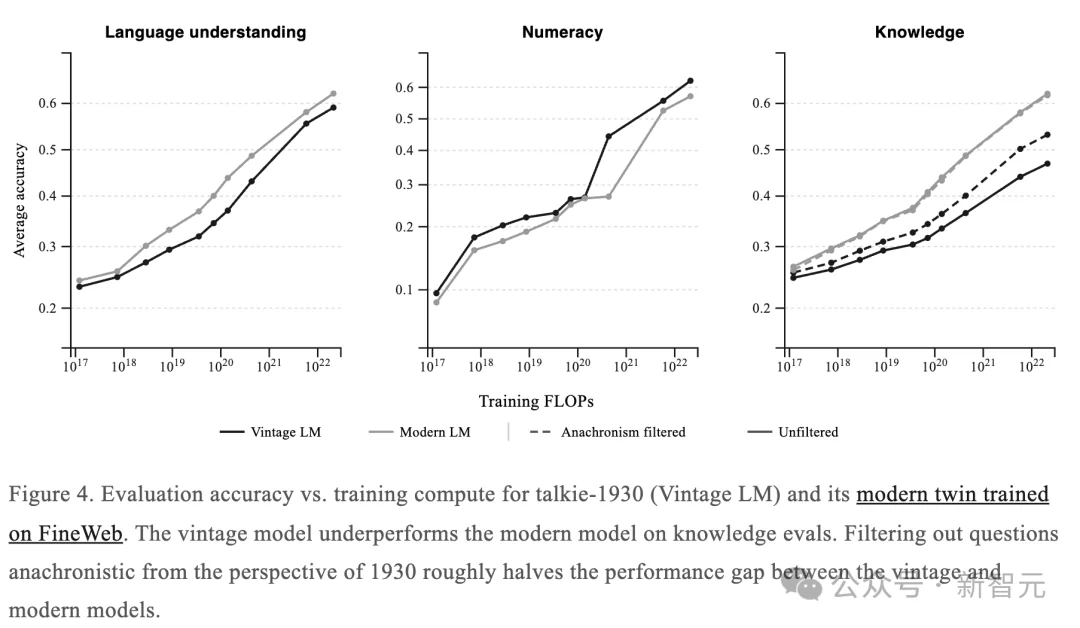
团队怀疑,这跟数据质量有很大关系。
为此,Radford团队计划从零开始训练「复古OCR系统」,专门用于重新转录1931年前的文本。
用最现代的Claude 4.6
训练最古老的AI
talkie的「后训练」方案也很有意思。
要把一个只读过旧书的「基础模型」变成能对话的聊天机器人,根本没有现成的指令微调的数据可用。

团队的做法是,从1930年之前的结构化参考书中提取指令-回答对:礼仪手册、书信写作指南、菜谱、百科全书、诗歌集。
然后,再用这些「复古教材」做第一轮SFT。
在接下来的RLAIF阶段,团队用在线DPO来提升talkie的指令遵循能力,Claude Sonnet 4.6作为裁判。
一个2026年最先进的AI,给一个「活在」1930年的AI打分。
最终的精调阶段,团队甚至用Claude Opus 4.6生成多轮对话数据,来打磨talkie的对话能力。
训练过程中,Claude对talkie指令遵循能力的评分从2.0提升到了3.4(满分5分)。
最后一步,用Claude Opus 4.6与talkie进行多轮合成对话,再做一轮拒绝采样+SFT,打磨对话能力。
团队也坦承了一个讽刺之处:用现代大模型训练一个本该冻结在1930年的模型,本身就是一种「时间污染」。
他们的长期目标是用复古基座模型自身作为裁判,实现完全「自举式」的后训练流水线。
值得一提的是,talkie的7B版本在RL训练后出现了一个搞笑的副作用——
它开始用列表体说话,纯属是被现代AI的「坏习惯」传染了。
AI界最干净的一次「开卷考试」
研究团队还做了另一个有趣的实验。
他们从《纽约时报》的「历史上的今天」栏目中提取了近5000条历史事件描述,计算talkie对每条事件的「惊讶度」。
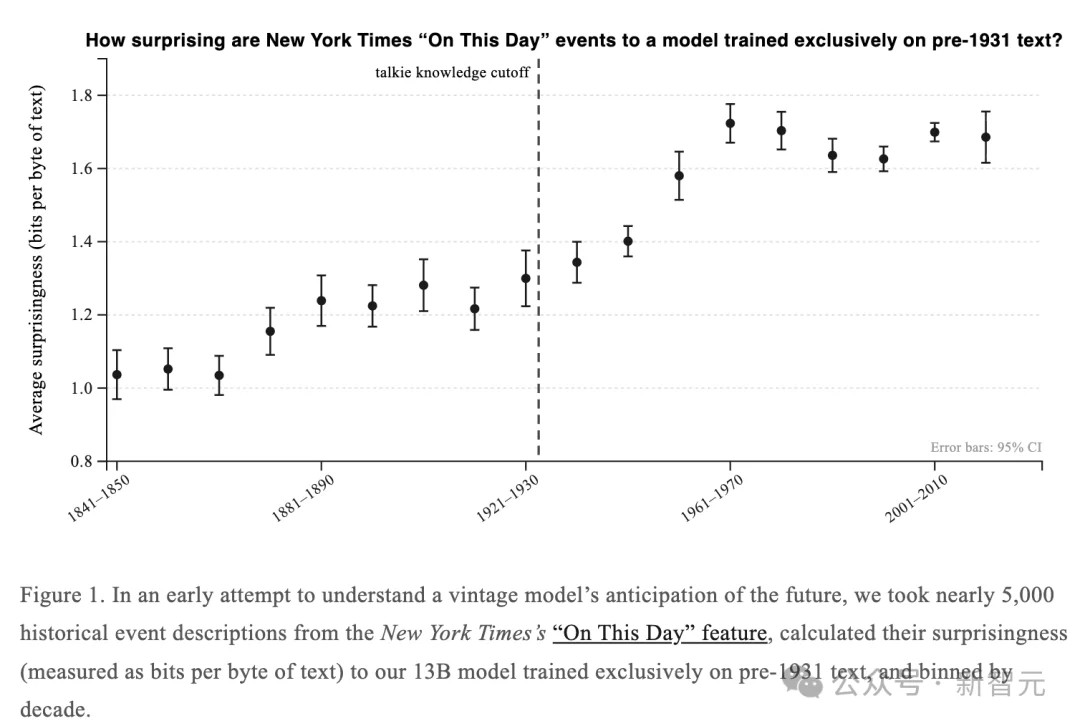
结果非常清晰,1930年之前的事件,talkie不太惊讶。1930年之后的事件,惊讶度开始攀升。
到了1950年代和1960年代达到峰值,然后趋于平稳。
这条曲线本身就是一个关于预测能力的实验。随着模型规模增大,这条曲线会怎么变化?
谷歌DeepMind CEO Demis Hassabis曾提出一个思想实验——
一个只训练到1911年的模型,能不能像爱因斯坦在1915年那样独立发现广义相对论?
talkie目前当然做不到。但它提供了一条路径,往上Scale就行了。
今夏扩展到GPT-3级别
talkie目前是130亿参数,团队的路线图相当激进——
今年夏天,发布GPT-3级别的复古模型。

更远期的目标:将语料扩展到超过一万亿token,理论上足够训练一个GPT-3.5级别的模型,能力接近初代ChatGPT。
一个冻结在1930年的ChatGPT。
参考资料:
https://x.com/status_effects/status/2048878495539843211?s=20
https://talkie-lm.com/introducing-talkie
文章来自于微信公众号 "新智元",作者 "新智元"


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
