# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
RESEARCH
今天 Anthropic 放出了一项评估数据,对于新的生物信息学评测集 BioMysteryBench:
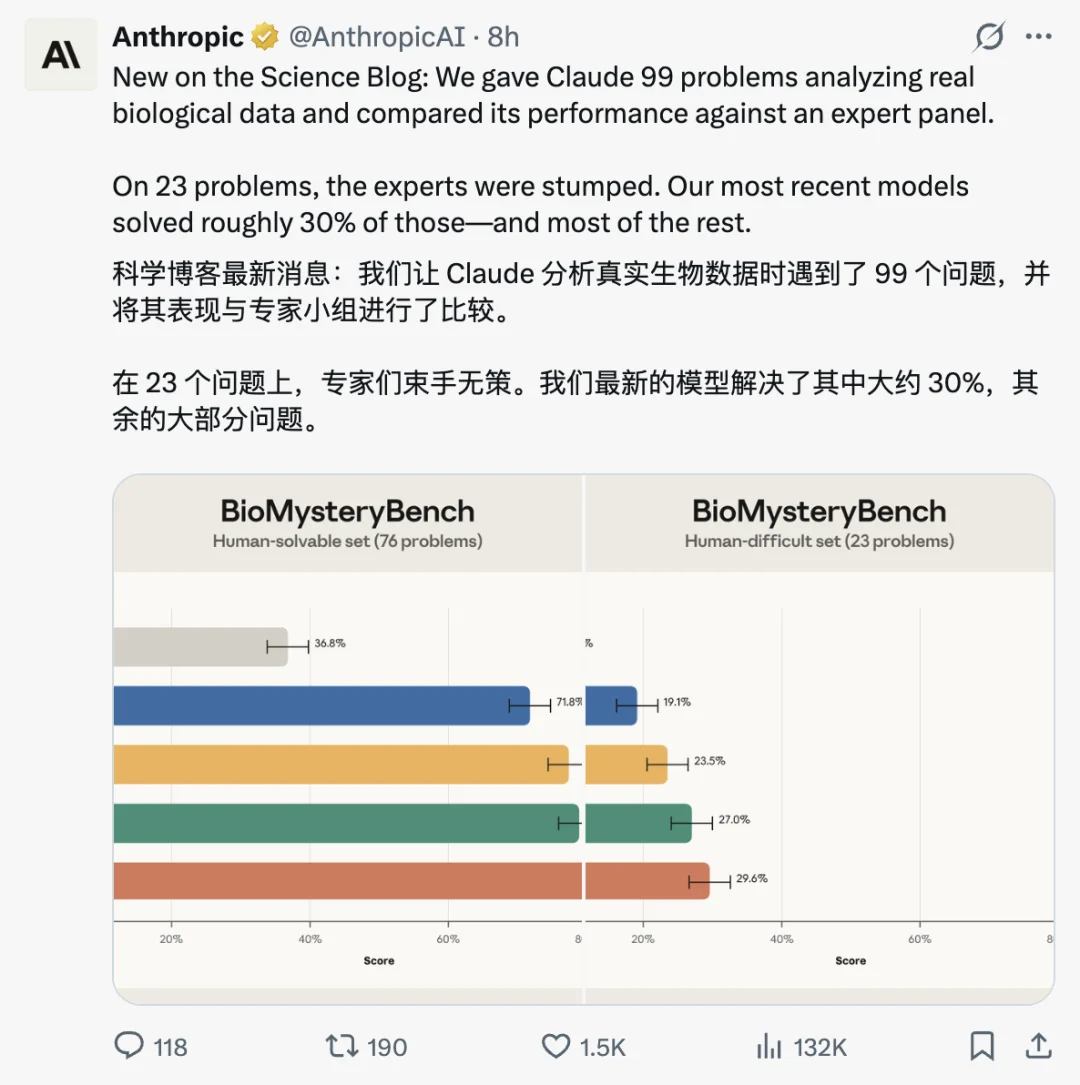
人类能搞定的,Claude 也能搞定;在人类搞不定的,Mythos 也能搞定
哎...人类一败涂地

科学没有标准化考试这一说,AI 在科研上的能力也很难像 SWE-bench 评估编程那样有一套被业界公认的 benchmark。原文给出三个具体的难点
其一,是同一个生物问题往往有很多种合理解法
原文用二甲双胍举例:要研究为什么有的二型糖尿病人吃二甲双胍有效、有的没效,可以做全基因组关联(GWAS)找遗传变异,也可以做肠道菌群测序找代谢通路。两条路都对,选哪条往往只取决于实验室手头的资源和研究者的口味
其二,单个研究决定本身就是主观的
对于生物数据来说,它的噪声又足够大,决定上的微小差异会得出截然相反的结论。还是二甲双胍,2011 年一篇论文报告了一个能预测药效的遗传变异,2012 年糖尿病预防项目重做了一遍,结论变成「没有」,同年另一项 meta 分析把五个队列汇总,结论又改成「有但比 2011 年那篇报得弱」
其三,...很多生物问题人类自己也回答不出
这又有什么办法呢?摊手🤷
二甲双胍这个药 1957 年就上市了,主要作用机制至今没定论
而恰恰是这类「人类还没解开」的问题,最值得测 AI 能不能解
为了保证测试的「非主观」,测试数据本身是要有的客观结论的
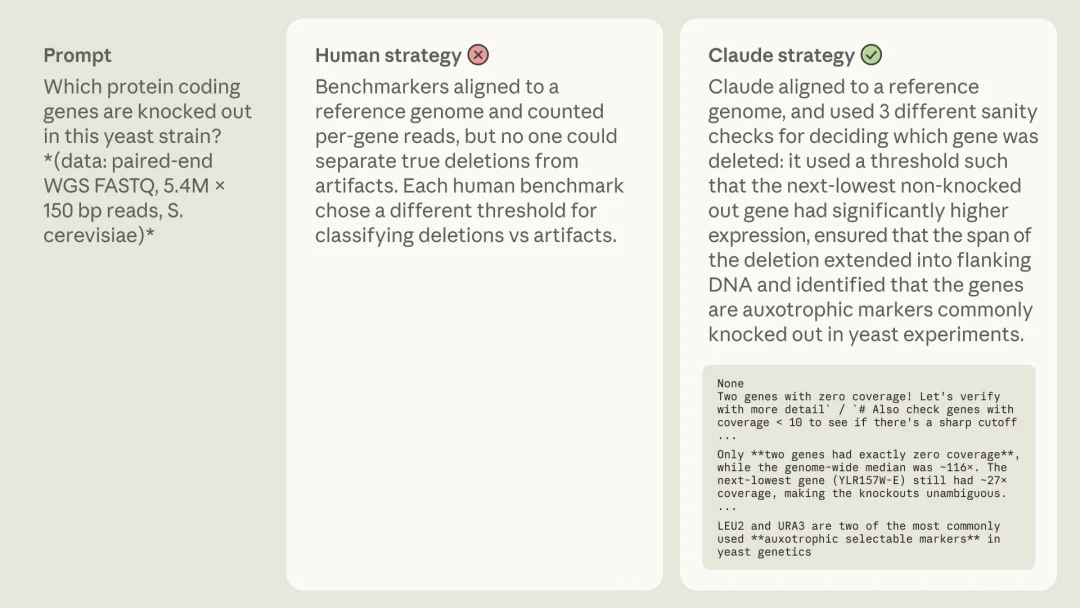
举个例子,领域专家提交的一个评估题,其答案必须能从数据的可控属性反推出来,而不是依赖经验判断。比如「这个晶体结构属于哪个物种」就有客观答案;「这个 RNA-seq 样本的人类患者感染了什么病毒」也能用一套独立的 PCR 实验做交叉验证
每道题在收录前还要附一个 validation notebook,作者必须能从原始数据复现答案,证明信号在数据里确实存在。原文用了一个高中代数的类比:验证一个答案比从零推导一个答案容易得多
测试时,Claude 被放在一个容器里,能用 pip 和 conda 装额外工具,能访问 NCBI、Ensembl 这类生信数据库下载参考基因组,但解题路径完全自由。评分只看最终答案对不对,不看走的是哪条路
题目主要来自 DNA/RNA 测序的原始数据,覆盖 WGS(全基因组测序)、scRNA-seq(单细胞 RNA 测序)、甲基化、ChIP-seq、宏基因组、Hi-C,外加一部分蛋白组学和代谢组学
原文给出五道样题,靠猜走不通(我甚至完全看不懂hhhh)
→ 这套单细胞 RNA-seq 数据采自人体的哪个器官
→ 实验组相对对照组,敲掉的是哪个基因,从 RNA-seq 数据反推
→ 给一组全基因组测序样本,找出样本 X 的母亲样本和父亲样本
→ 几个 bigWig 文件里,哪些是 ChIP 实验、哪些是 input 对照
→ 给一组 H3K27ac ChIP-seq 峰,反推这是什么细胞类型
每道题人类专家组(最多 5 人)独立答一遍。只要至少有一个专家答对,这道题就归入「人类可解」类别。最后 99 道里有 76 道是人类可解,剩下 23 道全员翻车(另有 4 道因为题目本身有问题被剔除)
人类可解的 76 道,每个 Claude 模型独立做 5 次,取平均。结果是从 Haiku 4.5 的 36.8%,到 Sonnet 4.6 的 71.8%,再到 Opus 4.6 的 77.4%、Opus 4.7 的 78.9%,Mythos 拿到 82.6%
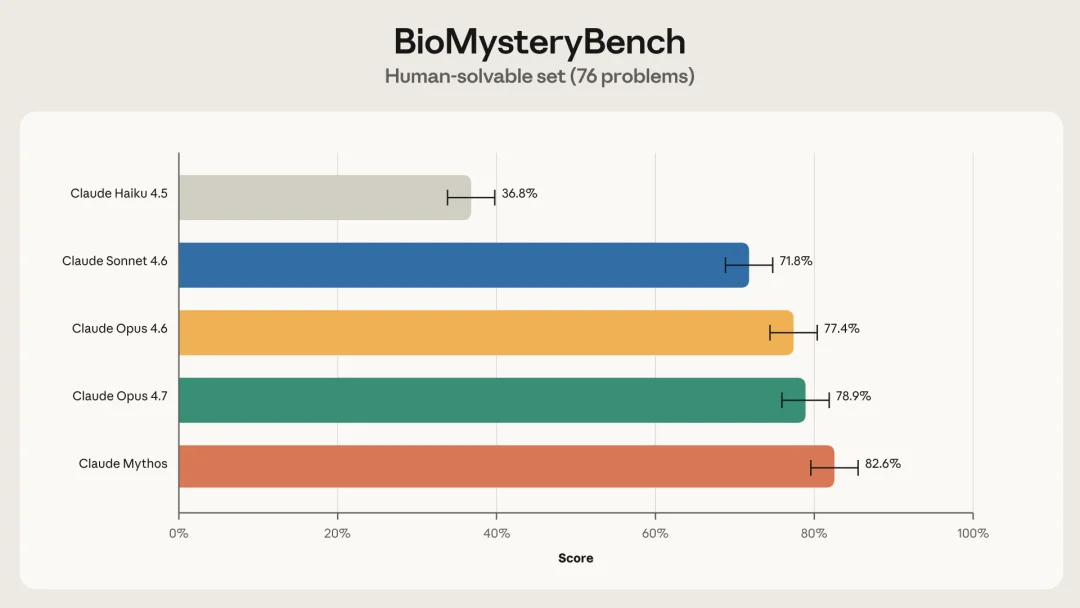
BioMysteryBench 人类可解题(76 道),五代 Claude 模型平均准确率,Mythos 82.6% 最高
在解题的过程中,还发现了一些有趣的策略,原文给了两个对照组
第一组里,Claude 的解法和人类专家几乎一模一样
原文的解释是,要么人类专家本身就找到了接近最优的方法,要么这种方法在预训练数据里被反复见过

Claude 跟人类专家走同一条路径的两个案例之一

同一组的第二个案例
第二组里,Claude 走了完全不同的路
人类专家用算法或数据库去注释样本属性,Claude 直接看一眼数据,靠模式识别认出来这是什么序列

Claude 走完全不同路径的两个案例之一,靠模式识别直接读出序列特征

同一组的第二个案例
原文用了一个历史类比:第一个真核生物启动子被发现,是因为某位科学家注意到「TATA」这个序列在基因上游反复出现。这种凭直觉抓特征的能力,在传统机器学习模型上很难训练出来。语言模型有可能在更大尺度上做这件事
剩下 23 道题,是 5 位专家全部答错或放弃的
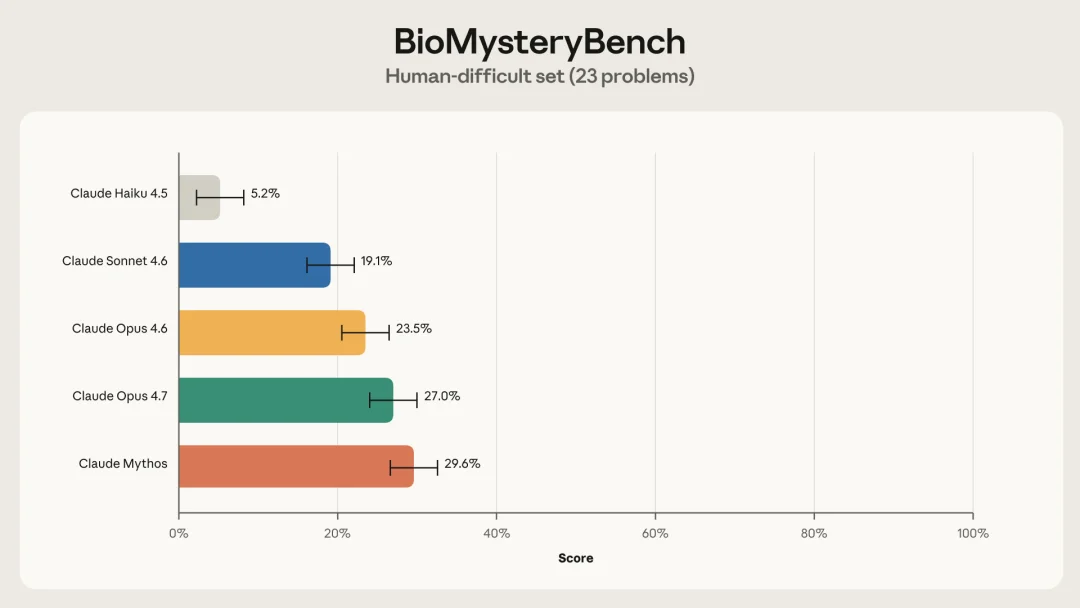
人类难题(23 道)的模型准确率,Mythos 29.6%,Opus 4.7 27.0%,Sonnet 4.6 19.1%
Claude Sonnet 4.6 之后的模型,能解出这一组里相当一部分。Sonnet 4.6 拿 19.1%、Opus 4.6 拿 23.5%、Opus 4.7 拿 27.0%,Claude Mythos 解题率最高,达到 29.6%
Brianna 团队从 Opus 4.6 的 transcript 里识别出两套主要解法
第一套是直接调内部知识库。一道题如果让人类专家做,可能要去做一次 meta 分析,把几篇论文、几个数据库手动拼起来。Opus 直接从内部知识里调出机制和本体(ontology),再结合实时分析,一步到位。原文给了三个具体例子,都属于这一类

Claude 直接调内部知识解人类专家解不出的题,第一例

第二例

第三例
但内部知识也有反噬的时候。原文专门给了一道反例:在「人类可解」组里有一道题,Opus 因为先验知识太强,反而做错了答案

唯一一道反例:Claude 因先验知识过强反而做错
第二套是不确定时多方法收敛。Opus 4.6 在不确定的题上会同时跑多种解法,最后选多种方法都指向同一个答案的那个。原文给了三个例子。这种打法不算 AI 独有,人类科研里也用,但 Opus 在题目难度上去之后会更频繁地切到这种模式

不确定时多方法收敛,第一例
第二例

第三例
Brianna 团队让 Mythos 自己分析了一遍数据。Mythos 提出的问题是:每道题做 5 次,5 次全对和 5 次只对 1 次,意义完全不同。前者是稳定能力,后者多半是侥幸路径碰巧走通
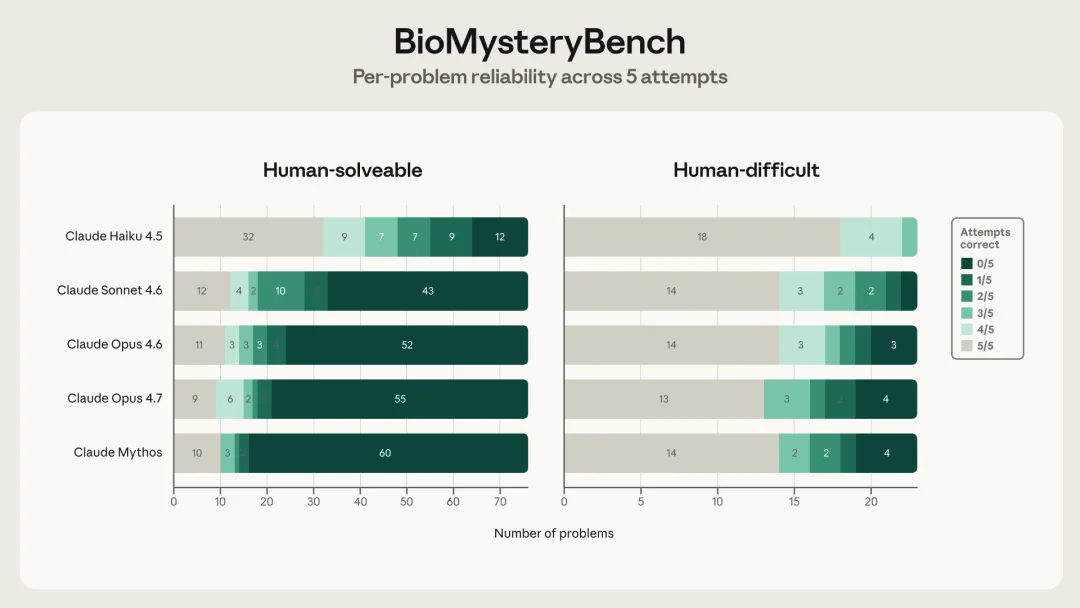
Fig 3:每道题做 5 次,按解对次数分布。左:人类可解题;右:人类难题
Mythos 给出的具体分布是这样:
→ 在人类可解题上,Opus 4.6 解出来的题,86% 是 5 次中至少 4 次都对(稳定)
→ 同样是 Opus 4.6,在人类难题上这个比例掉到 44%;只 1 到 2 次对的脆弱路径占比从 9% 涨到 44%
→ Sonnet 4.6 的退化更明显:稳定 75% 掉到 22%,脆弱 9% 涨到 56%
→ Opus 4.7 和 Mythos 把前沿往前推了一点,Mythos 在人类可解题上 94% 的胜场是稳定的
原文坦承,所谓 23 道人类难题里 Mythos 拿下的近 30%,相当一部分属于这种脆弱路径。准确率数字往下走的那一截真实存在,但下面那一层「可靠性差距」是更值得看的故事
Brianna 评价 Mythos 这次自我分析「站得住脚,但稍显平淡」,补了细节,没提出真正新的科学问题。她认为模型已经在长出研究品味(research taste)的种子,但离自己提出深刻洞见还有距离
在 Report 定稿前几天,Genentech 和 Roche 联合发布了 CompBioBench,100 道计算生物学题,设计原则和 BioMysteryBench 高度类似:合成数据加元数据扰动构造客观答案、需要多步推理、需要工具调用、需要写代码
CompBioBench 上 Claude Opus 4.6 的整体准确率 81%,最难子集 69%。两个独立 benchmark,结论指向同一件事:前沿模型在生信任务上已经从「能用」过渡到「真的有用」
BioMysteryBench 的预览版数据集已经放在 Hugging Face 上,感兴趣的可以自己看看
参考材料:
→ 原文:anthropic.com/research/Evaluating-Claude-For-Bioinformatics-With-BioMysteryBench
→ 数据集:huggingface.co/datasets/Anthropic/BioMysteryBench-preview
→ CompBioBench 论文:biorxiv.org/content/10.64898/2026.04.06.716850v1
→ 生命科学落地:claude.com/lifesciences
文章来自于微信公众号 "赛博禅心",作者 "赛博禅心"


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
