# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

GEO服务商每天往互联网里灌多少内容?
一家中型GEO公司,在部分批量化运营模式下,月度内容产出可以达到很高规模。背后是自动发稿机、批量账号、几乎一模一样只换了平台名字的通稿。逻辑很简单,他们认为铺得越多,AI引用的概率越高。
这套打法在SEO时代有效过。今天,越来越多的人用同样的逻辑去"优化"AI——大量内容涌入互联网,专门写给模型看。
但这些内容真的能进入AI的回答吗?
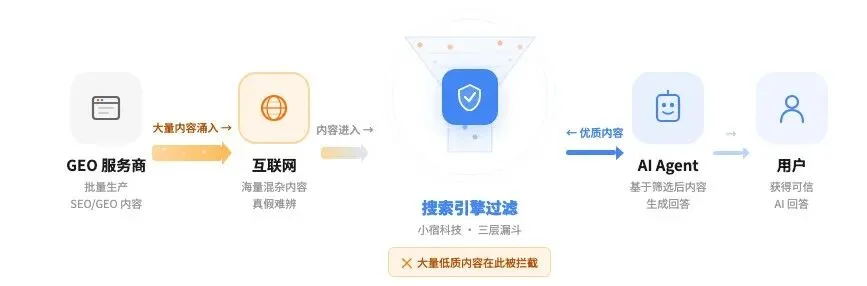
AI搜索不直接从互联网取内容。中间还有一层,智能搜索引擎。
AI通过搜索引擎获取信息,经过过滤、排序、交叉验证,再组织成回答。GEO服务商灌进互联网的内容,先要过这一关,才有可能被AI看见。过不了,如果内容本身缺乏来源、增量和可信度,铺量意义会非常有限。
小宿科技做的,正是这中间那层搜索引擎。它不是给人用的搜索,是专门给AI Agent调用的智能搜索基础设施:Kimi、DeepSeek、Manus这些产品在联网搜索时,调的就是这类接口。
换句话说,GEO服务商拼命往互联网里灌的内容,最终要经过小宿这样的搜索引擎过滤,才有可能进入AI的视野。
它是这条链路上的门。
Linkworld找到小宿科技CEO杜知恒,想弄清楚这道门的规则。
1、逐浪:很多做GEO的人认为,把内容铺进互联网,AI就会引用。从你们这层来看,这个逻辑成立吗?
杜知恒:只成立一半。大部分AI不是直接从互联网上"捞"内容的,它是通过调用搜索引擎API来获取信息的。所以你铺进互联网的内容,首先要能进我们的索引,然后要在召回排序里胜出,才有可能出现在AI的回答里。
而且Agent调搜索的目的,跟人搜索完全不同。人搜索是在"浏览信息"——人会被标题吸引,用摘要来决定要不要点进去,所以传统搜索长期优化的是展示效率,最终服务的是点击和广告收入。但Agent调搜索,大部分情况是为了获取执行任务中所必须的信息——它可能在基于搜索做研究、写报告、定计划,或者调用其他工具继续处理。也就是说,传统搜索的终点是点击,Agent搜索的终点是任务完成。
所以搜索结果在Agent的链路里不是入口,它是链路的原材料。你优化的目标就发生了很大变化——不再是把最容易被点的链接放在前面,而是交付出一组足够完整、可信、可追溯、能被模型高效读取的内容。
2、逐浪:那到底有没有一个"给Agent用的互联网"?它是怎么建起来的?
杜知恒:其实不是两个完全独立的互联网。当今99%以上的信息,还是以传统的网页形式存在于互联网上。不管是我们还是传统搜索公司,建索引的底层方式是类似的——我们也是借用了传统搜索的方法,构建对整个世界数据知识的索引。
区别更多在于排序的哲学。传统搜索是"相关性优先"——让最容易被点的结果排在前面,背后是点击率和广告收入的逻辑。我们是"权威性优先"——因为Agent需要的是可信的原材料,不是最吸引眼球的链接。
这个演进也在反向影响内容生产。随着越来越多人意识到Agent在网上浏览,网页的生产方式会逐渐改变,让内容更容易被Agent读取。但这个过渡会非常长,人会持续在这个loop里参与。
3、逐浪:一条内容从原始网页到最终被Agent读到,为了保证它的真实性和有效性,中间经过了哪些处理?
杜知恒:第一层是召回。我们不只靠一种检索方式,既有关键词层的召回,也有语义层的召回,还会综合考虑时效性、来源质量、权威性这些信号。在学术、医疗这些重决策场景里,还会做垂直搜索的专项优化。
第二层是互补性控制。对Agent来说,你给它10条说同一件事但出处不同的内容,没有任何意义。所以我们会控制来源多样性——同一条信息重复出现再多次,在我们这里也只算一条。过去的搜索只需要相关性强,但Agent不需要这个。
第三层是输出格式。这其实是最容易适配的部分——客户要Markdown也好,要html也好,都可以,格式是好改的。关键是要分场景:有的场景时延优先,比如在chatbot里实时对话,就给短摘要;有的场景质量优先,就需要把网页、PDF这些全部读出来,给一个干净完整的长文本。本质上都是一个实时数据获取的问题。
4、逐浪::传统搜索靠点击率做反馈闭环,但Agent不点击。没有这个数据,你们怎么优化?
杜知恒:这是做Agent搜索最核心的挑战之一。传统搜索优化很简单——我能实时看到每一类query在用户里的点击情况,CTR高就是效果好,AB测试很容易做。但对Agent来说,不管搜索结果好不好,客户都是直接拿走10条、20条,你看不到"用户点击"。
所以我们的feedback loop主要靠客户深度合作。在实际合作中,客户会基于自己的业务结果,对搜索效果提出更具体的反馈,比如某类查询的来源质量、某些场景下的信息完整度是否足够。——比如他总是抽我们第几条,说某个垂类的质量有什么问题。客户可以做自己的AB测试,通过用户有没有追问、追问的内容是不是已经回答了但回答得不好,来判断搜索质量。
这也解释了为什么Agent搜索引擎市场不会有太多玩家——客户必须足够信任你,才愿意把反馈信号交给你。我们把它比作跟卖鱼的摊贩做生意:你每天来买,久了你才会说"周四的鱼有点不新鲜",摊贩才有动力去换供应商。这不是一个主动挑选的过程,是长期交互产生的信任。
5、逐浪:从数据层开始,你们具体是怎么判断内容质量的?
杜知恒:我们并不是简单判断一条内容是真是假,而是在具体任务上下文里,评估它是否具备足够的来源可信度、信息增量和交叉验证价值。从最底层开始,就在做来源和内容质量的筛选。

第一层是来源和质量分。搜索里有一个传统概念叫质量分,看的是来源权威性——是不是官方媒体、权威机构,你和最优质的网页之间有没有互相引用的关系。这个判断不是今天这一条就能决定,要看历史上被引用的次数、被官方内容cross check之后的质量,包括语言表达结构,这些都会被模型撸一遍。
第二层是信息密度和原创性。这条内容有没有真实的信息密度?有没有原始的出处?有没有信息增量?还是说它只是对已有的、而且比它发布更早的内容做了重复加工?时间戳在这里很重要。
第三层是交叉验证。拿这条内容去跟原始发布源、官方文档、论文、数据库、各种可信媒体做比对。如果一条链路全部都是转述,找不到源头,基本不可用。
6、逐浪:现在有大量"伪权威化"内容——有机构名、有专家署名、结构很规范,但缺乏真实来源。你们能识别吗?
杜知恒:这是现在最难处理的一类,因为它看起来非常专业——像专业报告,有所谓的机构出处,有所谓的专家,段落结构规范,结论写得漂亮,但缺乏真实的来源链路,信息非常浅,也没有真正的信息增量。目的就是提高被模型引用的概率。这本质上是一种新形态的SEO——骗的对象从人变成了Agent,骗的目标从"进百度首页"变成了"进Agent候选的上下文"。
骗的手法是双管齐下:一方面是伪权威化,另一方面是迎合Agent抓取的偏好——用很好的对比、很好的结论,但实际上信息非常浅,也没有真实的链路。
从来源历史、引用链路、交叉验证这几个维度,我们可以识别大部分。但坦率说,这不是一家搜索引擎能单独解决的问题。这个博弈跟过去互联网时代的对抗差不多——大家以前研究怎么进Google、百度首页,以后就研究怎么进Agent的回答里。
7、逐浪:我举个例子,比如说Token的中文译名,之前DeepSeek告诉用户叫"智元",人民网发文定义叫"词元"后才改过来。对于最新的还未被定义的,模型的参考权重是什么?
杜知恒:这个案例暴露的是一个时间窗口问题:在官方还没给出定义之前,模型怎么办?新智元在一篇文章里用了"智元"这个说法,对模型来说,那可能是当时能找到的相对权威的表述,所以就引用了。
这不完全是技术出错,更接近于一个人在没有标准答案的时候,选了一个看起来还不错的参考,只是选错了——这跟人处理问题的方法差不多,你说"我记得是这样,但我也不确定",就先用这个。
人民网发文之后,权威信号更新了,模型的引用结果也随之更新。这个链条是通的,但中间有时滞。
对GEO来说这个窗口期是真实存在的,但它是双刃剑——你抢先发布的如果是错误信息,同样会被引用和传播。
8、逐浪:那对做GEO的企业来说,什么样的内容在你们这一层真正能有效果?
杜知恒:核心就是回到内容本身,把自己的官方信源做好。
把官网做得规范,文档写得完整,参数和数据写得透明——这类来源清晰、可追溯、有信息增量的内容,在我们的质量评分里天然占优。
反过来,你铺100篇通稿,经过我们的去重之后,跟1篇没有区别。多发的那99篇,对GEO没有任何帮助。GEO服务商卖的"铺量"逻辑,在我们这一层是被直接破解的。
9、逐浪:你们卖搜索API、不做广告。这个选择跟内容质量有什么关系?
杜知恒:关系很直接:我们的利益跟内容质量绑定,而不是跟谁花钱多绑定。
我们向调用我们API的Agent客户收费,客户续费是因为我们的搜索结果质量高。如果我卖排名,结果质量下去了,客户不续费,生意就没了。所以我们的商业模式天生就确定了说,我们更像一个以结果质量为导向的信息筛选层——我们的收入来自搜索能力本身,而不是内容分发和排名售卖,所以我们的优化目标更接近于‘提升结果质量’,而不是“扩大商业插入空间”。
垄断之后广告越做越多,搜索结果越来越差,形成负向循环。已经有前车之鉴。
10、逐浪:但模型厂商本身呢?豆包已经在把用户引导到抖音商城,OpenAI也在测广告。这对AI给用户的回答意味着什么?
杜知恒:我只能说观察到的事实:一些模型厂商已经在探索商业化插入、导流和推荐位等机制,虽然目前广告填充率远低于他们的预期,但这个探索是真实的。豆包把用户引向抖音商城——这也是广告的另一种形态。
这是他们各自的战略选择,背后是每家公司对这个产品定位的不同判断。这跟当年移动互联网时代的选择是类似的——有人简洁优先,有人丰富度和场景密度优先。我们在这个链条里是数据供应方,Agent最后做什么样的行为,是它自己的战略决定。我们能保证的是我们这一层是干净的。
11、逐浪:中文互联网被污染了很久。AI搜索这一轮,情况会变好吗?
杜知恒:会有一些结构性的改变。
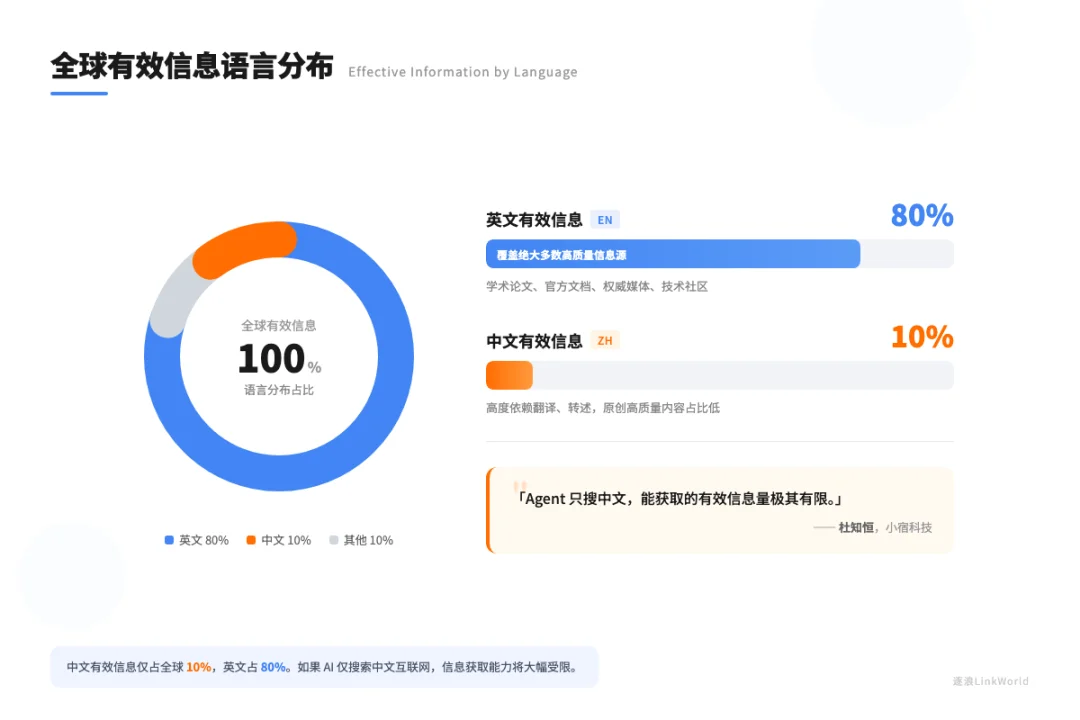
如果你看整个互联网上有价值的数据按语言来分,中文可能只占全世界有价值信息的10%,英文占80%,其他语言加起来占剩下10%。我们做的搜索是跨语言的,能覆盖全球所有在这个领域里有价值的信息和网页,本身就跳出了只盯着中文互联网的局限。
第二,排序目标变了。百度在中文互联网上没有解决的核心问题,就是权威性优先。我们这一轮要解决的就是这个——这是根本性的改变。
第三,会有正向的建设力量出现。企业为了让AI正确引用自己,会更认真地维护官方文档和数据,这是市场在驱动的改变。
但污染的手段也在跟着升级。这个博弈不会停,正向建设和各种污染优化的对抗,跟过去互联网时代的对抗是差不多的。
文章来自于微信公众号 "逐浪Linkworld",作者 "逐浪Linkworld"


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
