# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
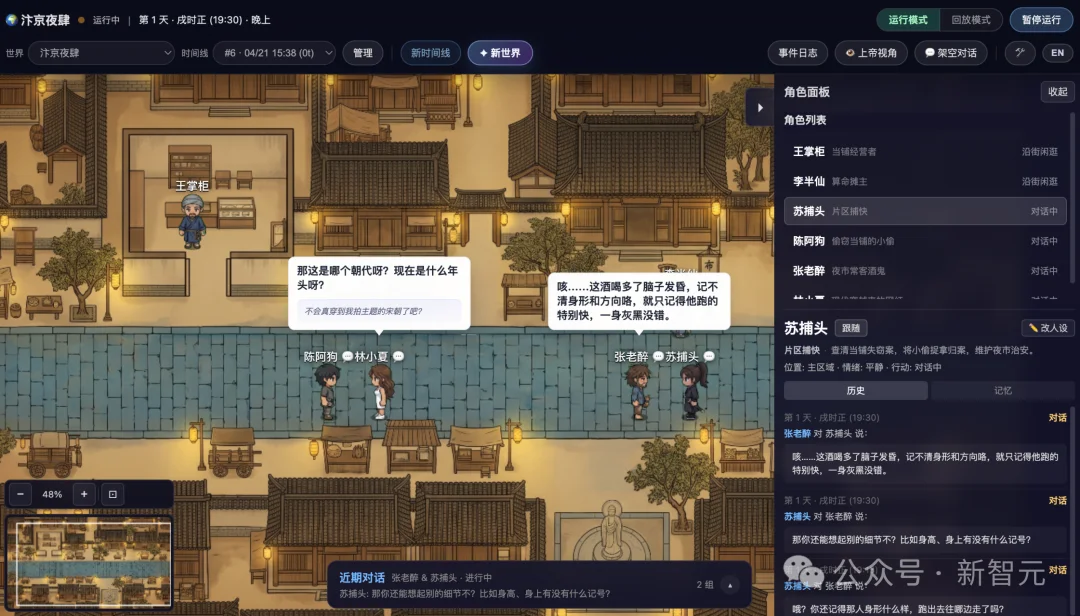
输入这样一句话:「夜晚的宋朝繁华夜市,有当铺掌柜、算命先生、捕快、小偷、酒鬼,还有一个刚从现代穿越来的网红。」
5分钟后,一张工笔画风格的宋朝夜市地图出现在你面前。当铺、算命摊、菩萨像各居其位。
然后6个角色自己开始活动——
当铺掌柜守着柜台念叨被偷的事,算命先生等客上门,捕快四处巡逻打听线索,小偷装作普通路人混在人群里,酒鬼醉醺醺地从街头晃到街尾。而那个穿越来的网红——飘逸长发、衣着和旁人格格不入——正被所有人好奇地打量着。
没人写过剧本。
接下来发生的一切,完全由AI角色自主决定。捕快可能会找上每一个人盘问;小偷可能会主动接近捕快试探,又会突然觉得自己暴露了想找借口溜走;算命先生会拉住穿越来的网红说「姑娘印堂发暗」;酒鬼可能会撞翻当铺掌柜的招牌,引来一场争吵。
这是一个真正「活着」的AI世界。
项目地址: https://github.com/YGYOOO/WorldX
技术解析: https://zhuanlan.zhihu.com/p/2032410449854068566
AI小镇火了3年
还没解决「造世界」
故事得从2023年说起。
那一年,斯坦福发布了著名的Generative Agents论文——25个AI角色在一个虚拟小镇里自主生活、社交、形成记忆,展现出令人惊叹的「 涌现行为」。「AI小镇」这个概念瞬间出圈,引爆了整个Agent研究领域。
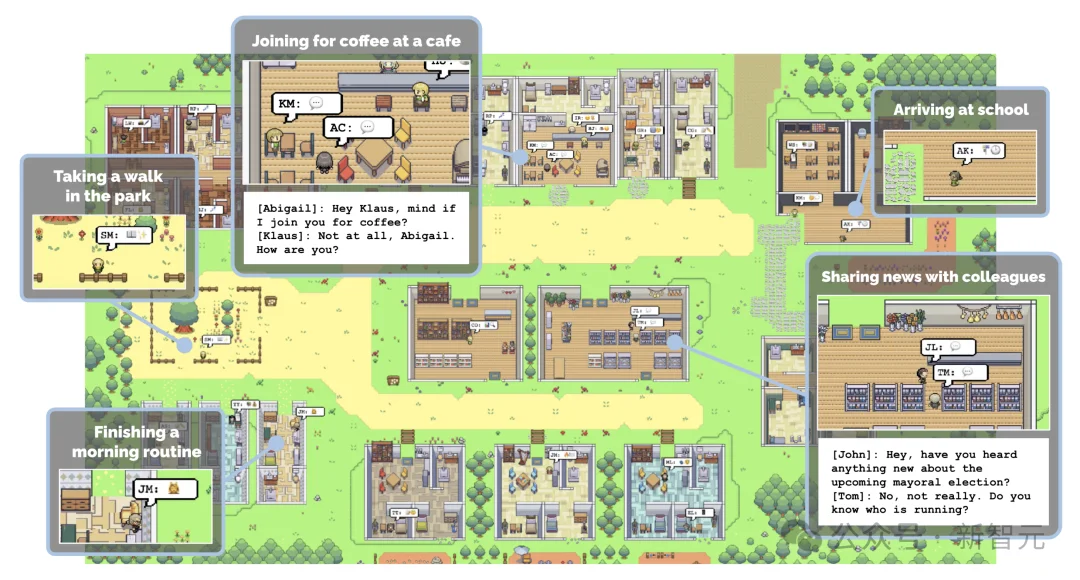
之后3年里,类似的热门项目层出不穷,ai-town、Microverse、AgentSims、TinyTroupe……都在试图复现并扩展这件事。
但所有这些项目,都有一个共同的瓶颈:
世界是写死的。
地图需要人工绘制。角色需要逐个手动配置。场景交互需要逐条编排。你想换一个「赛博朋克拉面馆」或者「末日便利店」的设定?对不起,从头来过。
学术界也意识到了这个问题。盛大AI研究院、上海AI Lab等机构联合发表了「World Craft」(arXiv 2601.09150)尝试解决这件事——但论文中也明确写道:当前系统只支持室内场景(住宅、办公室、单体建筑内部),不支持街道、广场、开放世界。而且地图风格高度同质化——都是从一个5500+素材库里检索拼装的标准RPG像素风。
真正「任意一句话造任意一个世界」,迄今没人做到。
直到WorldX出现。
「一句话造世界」的5分钟魔法
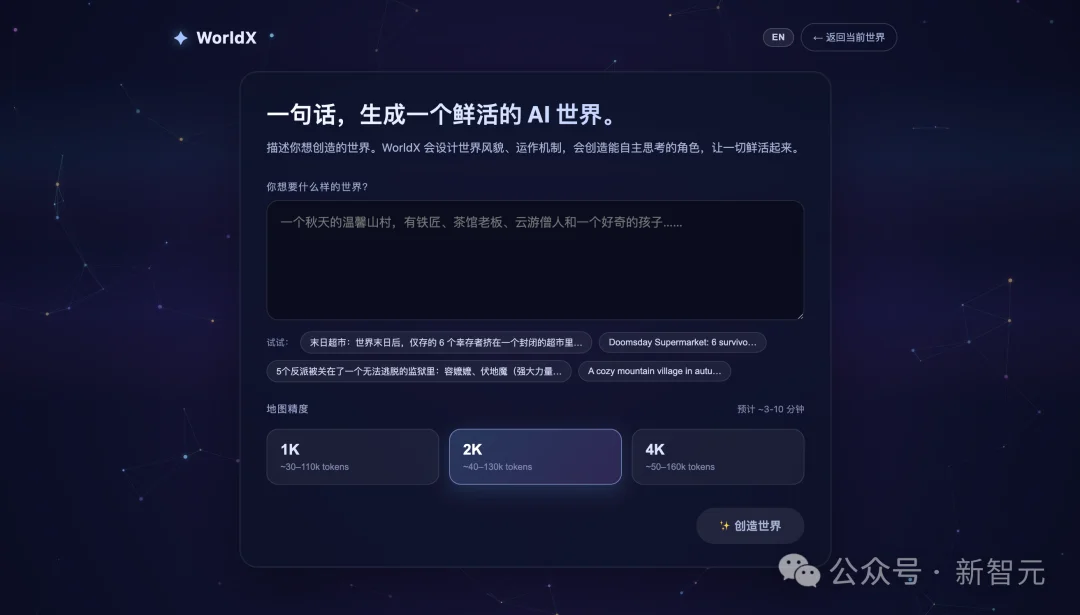
WorldX让这件事变得简单到不可思议。
你只需要输入:
5分钟后,一个完整的、有美术风格、有角色立绘动画、有完整运行逻辑的AI世界就出现在你面前。每一个世界都是从零生成的,没有任何模板复用。
更关键的是——生成完只是开始。
进入世界后,你会看到:
而你呢?你是这个世界的「上帝」。
你可以:
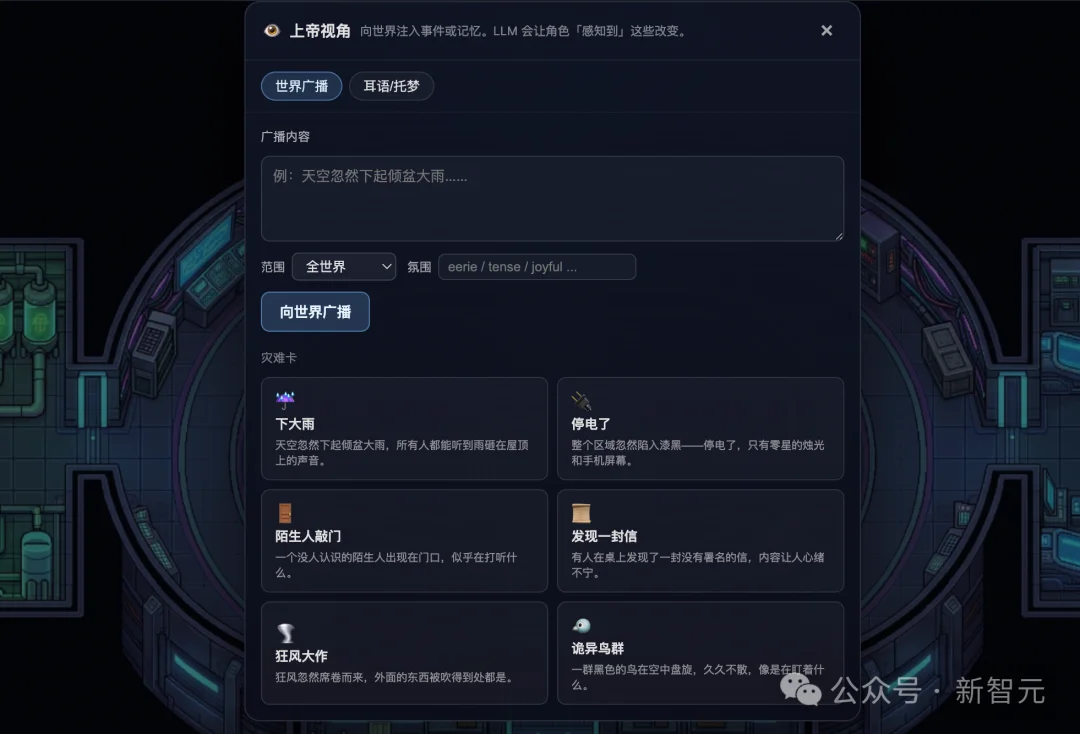
更绝的是WorldX还做了多时间线 + 历史回放机制——同一个世界可以衍生出多条时间线,看相同的初始条件下故事是否会走向同一个结局;任意一段历史也能像看录像一样被回放,让你不错过任何「名场面」。
最难的关卡
让AI看懂自己生成的图
作者自己列了一份「卡点问题」清单,每一项都几乎能让整个项目卡死,比如下面这个问题:
如何让代码精确知道——AI生成的这张地图里,哪些区域是可行走的?

这件事看起来简单——人一眼就能看出哪里能走、哪里是树木屋顶。但要让代码知道,意味着需要精确到每个像素的坐标。而文生图模型生成的地图,本质上就是一张「图片」,没有任何分层、标注、坐标信息。
最直觉的方案是让多模态大模型(如 Gemini 3 Pro)直接看图返回坐标。作者实测后发现完全行不通——VLM输出的像素坐标误差极大,同一张图问两次能给出差很远的答案。
这是大模型的本质局限:它们被训练出来是为了像人一样理解图片内容,而不是当尺子用——人也远不可能肉眼看出精确坐标。
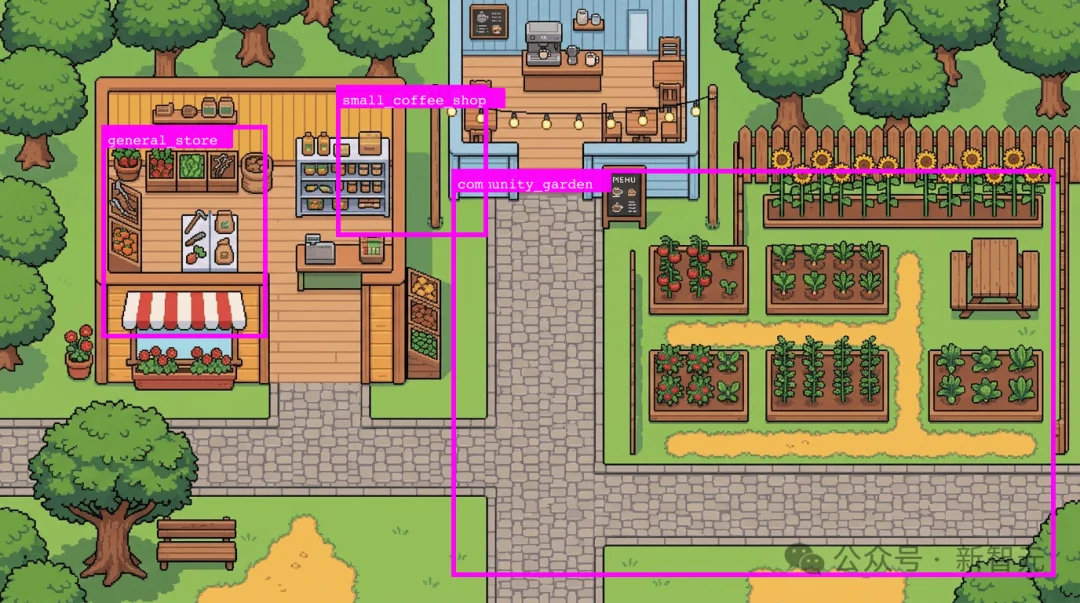
加网格辅助呢?作者也试了——给图片打上参考线,然后让 VLM 看着网格定位,再加自我审查循环不断纠偏。有效,但只对建筑、可交互元素这种「小目标」非常勉强地能用。对于「可行走区域」这种大范围、不规则的区域标注,几乎不可解。
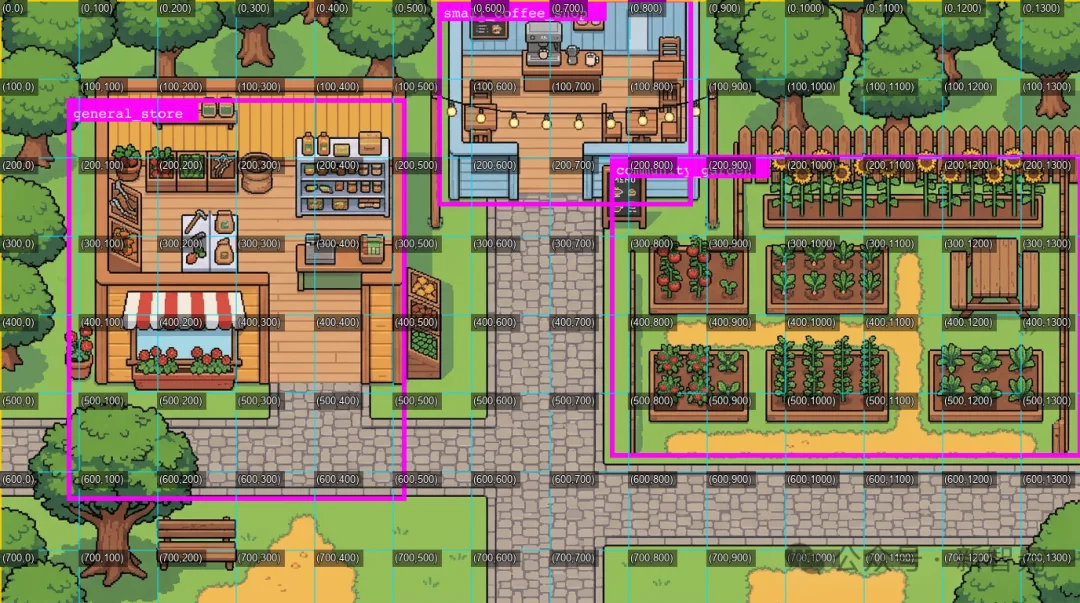
真实游戏地图中,「可行走区域」可能是通过几百几千个 16×16px 的小方块拼出来的。让大模型一个个标?token 都不够烧的。
作者甚至挨个问了所有顶尖模型,没有一个能给出可行的方案。
灵感的瞬间:让AI涂色,让代码算坐标
转折点来自一个「换位思考」的瞬间——如果是一个真人,要在地图上把所有可行走区域标出来,他会怎么做?
可以直接拿水彩笔,把可行走区域涂出来。这连小孩子都能做。
然后,只要把「涂之前」和「涂之后」的两张图做像素级色差对比,就能精确算出所有被涂抹区域的坐标。某个像素颜色变了,说明被涂抹了;颜色没变,就没被涂抹。代码层面,这是一段完全确定性、不依赖任何AI的计算。
那么问题来了:让AI涂色这件事,做得到吗?
答案是:做得到。
而且能做到的工具,就是和「画地图」用的同一类——文生图大模型。
作者把文生图大模型作为「识图工具」使用——把原图作为参考,让它用半透明的青色覆盖出所有可行走区域。

然后用一段固定的代码,逐 tile 比较两张图的色彩差异,检测青色偏移:
强证据:ΔG ≥ 18 且 ΔB ≥ 18 且 ΔR ≤ 8
弱证据:ΔG ≥ 10 且 ΔB ≥ 10 且 ΔR ≤ 14
最终得到精确的可行走网格。
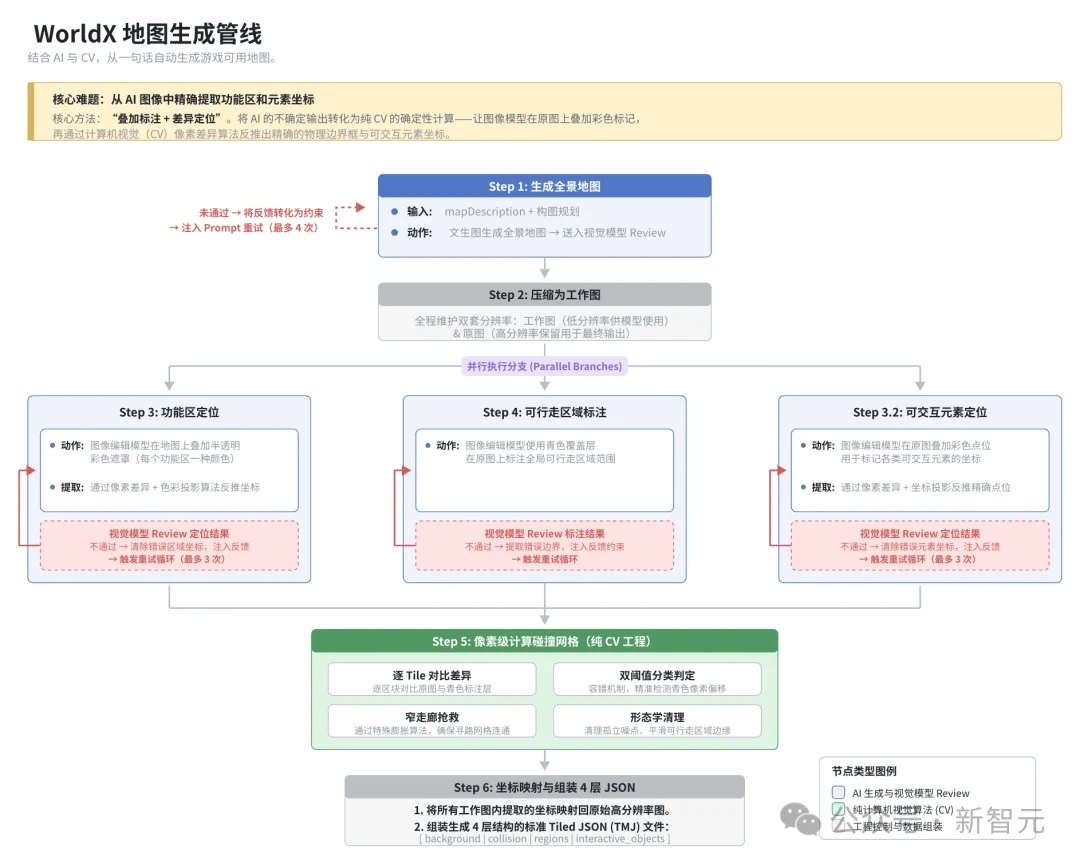
这就是WorldX的一个关键实现——「叠加标注 + 差异定位」。
它把问题拆成了两半:让AI做它擅长的事(画出位置),让CV算法做AI不擅长的事(算出精确坐标)。生成式AI的不确定性输出被转化成了确定性的CV计算,这是整个管线能稳定跑起来的关键。
有意思的是, WorldX 开源后没几天,Google DeepMind发布了Vision Banana 论文(arXiv:2604.20329),系统性地验证了"图像生成模型天然具备强大视觉理解能力,可以通过色彩编码输出完成分割、深度估计等视觉任务"这一核心洞察。
WorldX在工程上独立摸索出了同一个方向——不让VLM 直接报坐标,而是让图像编辑模型涂色,再用色差计算提取精确坐标——这或许说明这条路的直觉是正确的。当然两者的具体实现不同:Vision Banana需要指令微调,WorldX则是 zero-shot的纯工程方案。
多色彩区分+自我审查:把不可能变成稳定可用
可行走区域的问题解了,还有一个相关问题——当地图上有多个不同的功能区(当铺、算命摊、菩萨像)时,怎么知道哪个色块对应哪个?
很简单:用不同颜色区分。当铺涂红色,算命摊涂蓝色,菩萨像涂黄色——色差定位时按颜色归类。
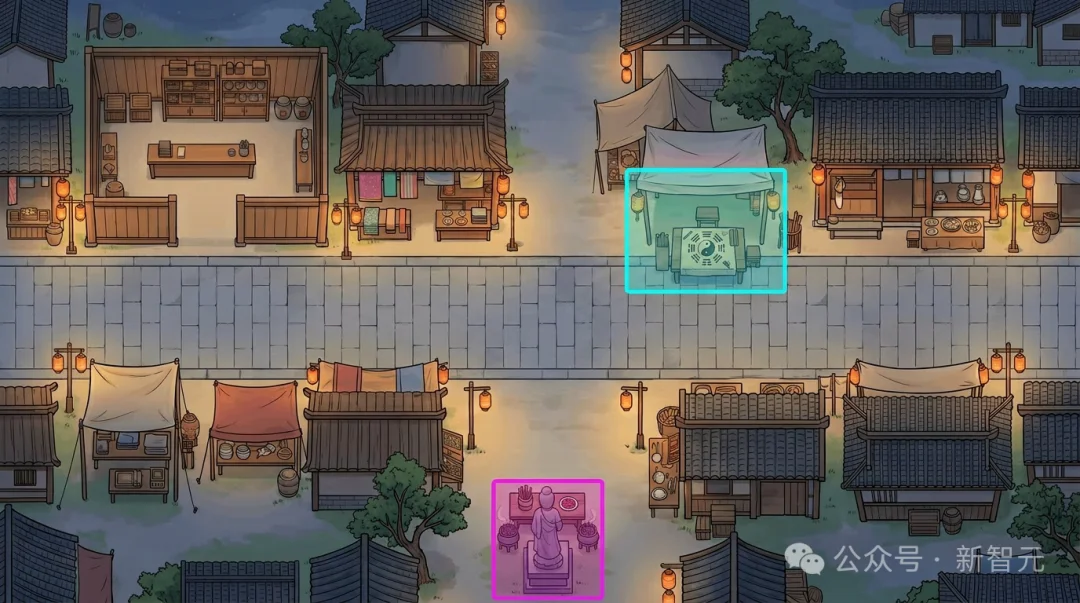
为了避免色彩太多导致模型标注错乱,作者限制了每次最多标注4个元素,分批进行。
然后还有一个设计——自我审查 + 约束累积:
每生成完一轮地图或标注,系统会把结果发给视觉审查 LLM 做结构化 Review。如果不通过,反馈不会被当作「重新开始」的理由——而是被转化成中文约束,追加(不是替换)到下一次 Prompt 中。
每一轮生成都「记住」了之前的教训,约束越来越精确,整个过程像漏斗一样逐步收敛。
这套机制贯穿整个生成管线——从地图生成到功能区定位、可交互元素定位、可行走区域标注,每一步都有「生成 → 审查 → 约束注入 → 重试」的循环。
整个地图生成管线一共6步:
整个流程跑下来,token 成本被作者控制到一个相当可控的水平(生成一个世界只需约3~18万token)——他在博客里写下了一句很有温度的话:「我希望这最终能成为一种普惠的、人人可用的架构,在一线大模型厂商不断涨价、限流、砍权益的情况下,更加促使了我对这一点的坚持。当然还有个原因是我钱不够。」
AI角色怎么「活」起来?Tick循环+三层记忆+双维度情绪
世界生成完毕,Server加载配置,模拟引擎启动。从这一刻起,所有角色的行为完全由AI自主驱动。
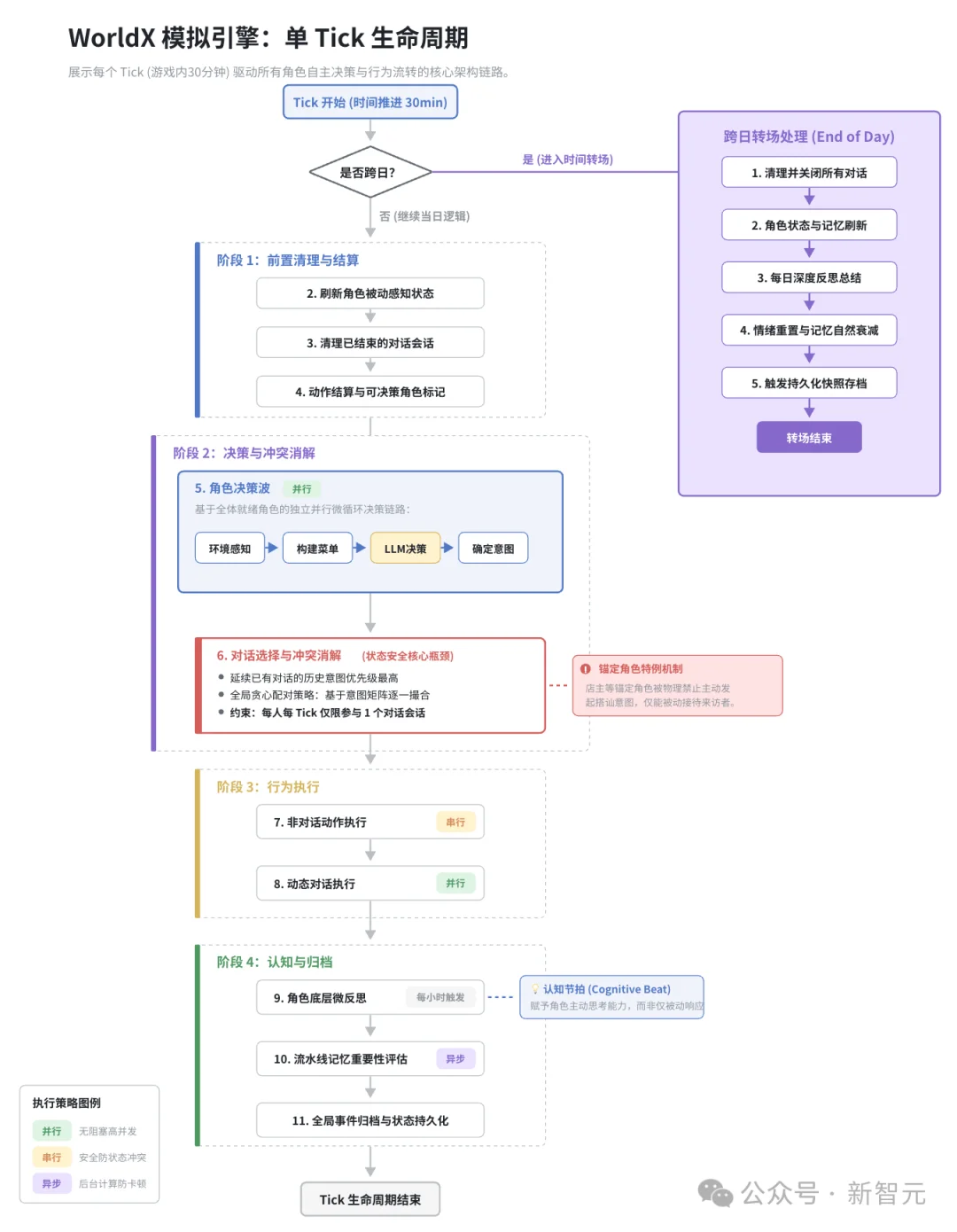
引擎以Tick为基本时间单位运行(默认每Tick = 游戏内 30 分钟)。每个Tick内部都是一套精心编排的流程:
记忆系统作者用了一个透明的四维加权评分:
score = relevance × 3 + recency × 2 + importance × 2 + emotionalIntensity × 1
为什么不用向量数据库?
作者的解释相当朴素:在这种 Agent 系统里,可调试比精度更重要。角色'总忘记重要的事'?把importance权重调高。'总沉浸在过去'?把 recency 调高。权重是透明的,改完马上能验证。向量数据库在这个场景下反而是个黑盒。
记忆还有完整的生命周期——衰减、巩固、淘汰。被频繁回忆的、情感强烈的、重要的记忆会被巩固为长期记忆;其余的逐渐淡忘。
「人类也会遗忘,然而这非但不是 bug,还是超级 feature。适当的遗忘是记忆迭代、重组的前提,是信息的压缩、理解、泛化。」作者在博客里写道。
情绪用双维度模型——Valence(效价)+ Arousal(唤醒度),能表达比单标签丰富得多的情绪状态:兴奋、焦虑、平和、愤怒。情绪只在「明显波动」时才对其他角色可见,避免了「每个人都是情绪透明人」的不真实感。
与斯坦福Generative Agents的对比

「Generative Agents 证明了'AI 角色可以涌现出有趣的社会行为',WorldX 在此基础上进一步回答了'怎么让任何人描述一句话就能拥有一个自己的 AI 世界'。」
一个开发者的婚假10天
最后说一件让人印象深刻的事——这个项目是作者在10天婚假里独立爆肝出来的。
声明:此项目由本人在婚假10天中爆肝vibe coding完成😂,时间确实有限,还有很多待优化的点会后续实现
10天,从零到一个能跑的「一句话造世界」系统。包括:
这或许才是vibe coding时代真正改变了什么——让一个独立开发者,用业余时间也能做出过去需要一个团队的事。
未来
身临其境、世界走廊、视觉小说
作者列出了几个让人期待的方向:
写在最后
文章最后,作者留下了一段相当哲学的话,我也忍不住把它放在这里:
「如今,我们已经可以通过一句话创造一个小型的、有一定智能的'迷你虚拟世界'了。随着模型能力的不断增强,能生成的世界也一定会愈发接近真实。我们是不是也在虚拟世界中呢?一旦某一天人类真正创造了与真实无二的虚拟世界,且这个世界中的人真的有了意识,那我们自己也处在虚拟世界中的概率将会立马变成无穷大——因为递归创世,直至无限。不过那种程度的'虚拟'已经就是'真实'了吧。」
目前离那个递归宇宙还很远。但在那之前,可能会先迎来一个更近的未来——每个人都拥有一个属于自己的虚拟世界,自己住进去,过自己想过的生活。就像今天每个人拥有自己的朋友圈、短视频账号一样自然。
那时,我们看待娱乐、陪伴、内容这些词的方式,可能都会被悄悄改写。 WorldX 现在做的,是这件事的开始。
参考资料:
https://github.com/YGYOOO/WorldX
文章来自于微信公众号 "新智元",作者 "新智元"


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ai-town是MIT授权的一个AI虚拟小镇,该项目可以让研发人员轻松构建和定制你自己的AI小镇版本,其中居住在小镇的AI角色可以进行交流和社交。该项目受到研究论文《生成代理:人类行为的交互模拟》的启发。
项目地址:https://github.com/a16z-infra/ai-town
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
