# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Anthropic 的工程师们写了篇技术博客,标题是:构建 Claude Code 的经验教训:Prompt Caching 就是一切。

Claude Code
Claude Code 是目前最受欢迎的 AI 编程工具之一,而支撑它流畅运行的底层秘密,其实就藏在「缓存」这两个字里。这篇博客一共讲了 7 条经验,条条都是踩坑踩出来的。
Anthropic 内部把 Prompt Cache 的命中率当作基础设施级别的指标来监控,地位跟服务器 uptime 差不多。一旦命中率下降,就会触发 oncall 告警,工程师得像处理线上事故一样去排查。
换句话说,缓存在 Claude Code 里,并非锦上添花的优化,而是整个系统能跑起来的前提。
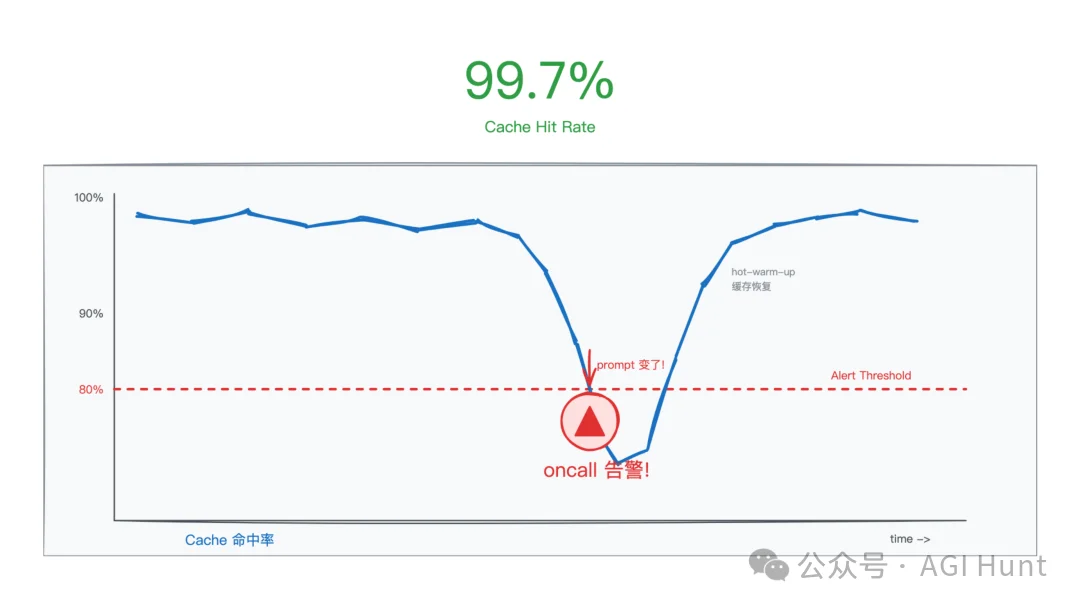
缓存命中率监控
没有缓存,就没有 Claude Code。
为什么呢?
因为 Claude Code 这类 Agent 产品有一个特殊性:它是长对话的。用户可能在一个 session 里聊几十轮,每一轮都要把之前的上下文带上重新发给模型。如果每次都从头算,延迟和成本都会爆炸。
而 Prompt Caching 的原理说白了就一句话:前缀匹配。
API 会缓存从请求开头到每个 cache_control 断点之间的所有内容。只要下次请求的前缀跟上次一样,就能复用之前的计算结果,不用重新跑。
而所有经验中最重要的一条,也就从这个原理生长出来。
既然缓存靠前缀匹配,那 prompt 里内容的排列顺序就至关重要了。
Anthropic 给出的最佳实践是这样排的:
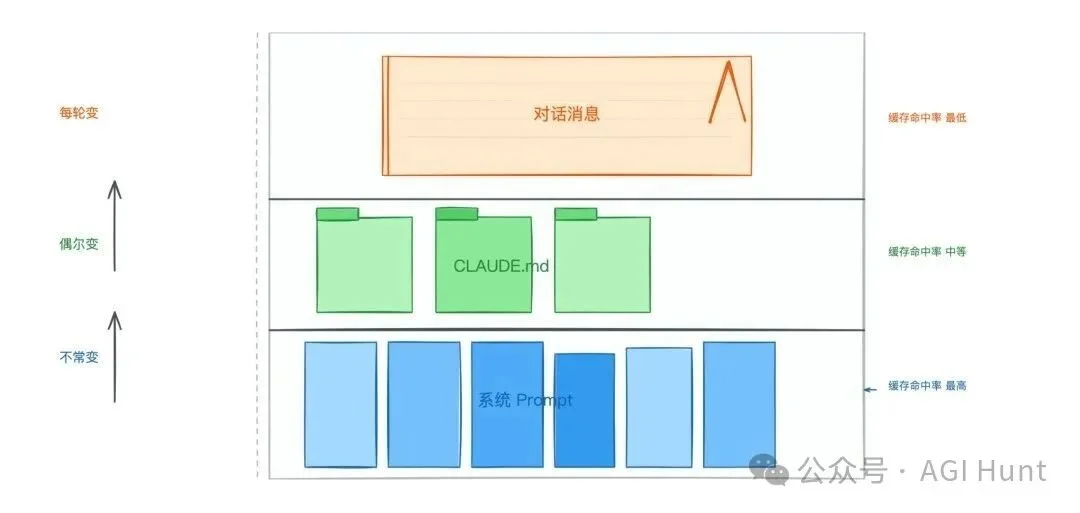
1. 静态系统 prompt 和工具定义(全局缓存,所有 session 共享)
2. CLAUDE.md 文档(项目级缓存,同一个项目内共享)
3. Session 上下文(会话级缓存,单次会话内共享)
4. 对话消息(逐轮增长,每轮只新增最后一条)

Prompt 排列结构
一句话概括:越不容易变的东西,越往前放。
这就好比你收拾书桌,常年不动的参考书放最底层,这周要看的资料放中间,今天正在写的草稿放最上面。只有这样,你每天坐下来才不用把整张桌子翻一遍。
书桌比喻
而这里面有几个特别容易踩的坑:
在静态 prompt 里嵌了时间戳,每秒都在变,缓存直接废掉。
工具定义的排列顺序不确定(比如用了 dict 或 set),每次请求顺序都不一样,前缀就对不上了。
工具参数更新了(哪怕只改一个字段),整个前缀的缓存也会失效。
一个小细节没注意,整条缓存链就断了。
那如果信息确实过时了怎么办呢?比如时间戳、文件变更状态这些。
Anthropic 的做法是:别去改 prompt,把更新塞进下一轮的消息里。
具体来说,Claude Code 会用 <system-reminder> 这样的标签,把需要更新的信息放进 user message 或者 tool result 里。这样系统 prompt 纹丝不动,缓存完好无损。
这个设计背后的思路值得琢磨:prompt 是「不可变的基础设施」,消息才是「流动的信息层」。
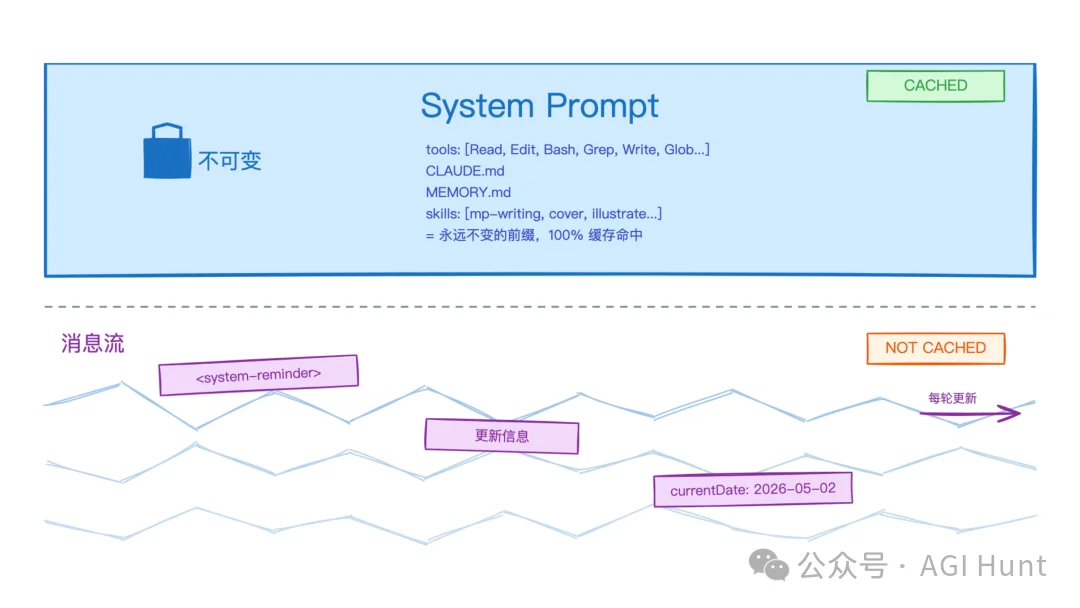
Prompt 与消息流
把它们分开,缓存自然就稳了。
第三条经验,对许多人来说,可能会有些反直觉。
你可能会想:对话中遇到简单问题,切到 Haiku 省点钱,遇到难题再切回 Opus,多合理啊?
但实际情况是,缓存是跟模型绑定的。
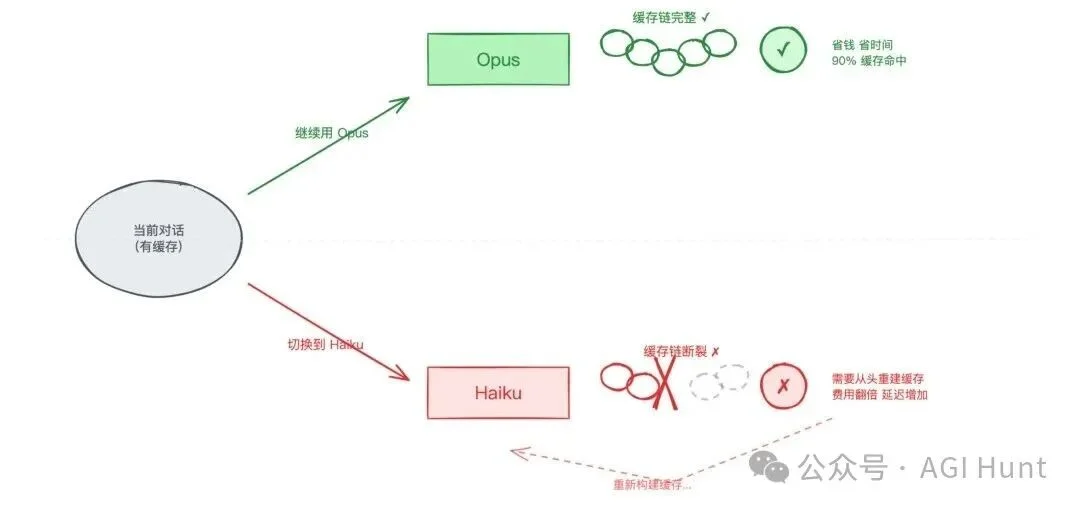
换模型就意味着……之前积攒的所有缓存全部作废,得从头重建。重建缓存的成本,往往比让 Opus 直接回答那个简单问题还要高。
换模型的代价
所以 Claude Code 的策略是:主对话自始至终用同一个模型。
需要用小模型干活的时候怎么办呢?用子 Agent。
子 Agent 有自己独立的上下文和缓存,不会污染主对话的缓存链。做完之后,只把结果传回来就行。
这就像办公室里,你不会为了省事让实习生坐到你工位上用你的电脑,而是给他分配一台独立的机器,做完把结果发过来。
且给搞中转的朋友提个醒,这里需要注意的是:缓存是按账号隔离的。
我就看到有个想通过账号池搞中转的,把账号池混一起后缓存命中率过低从而钱没赚钱反而暴露后号没了……
还有教你用 cc switch 咔咔切账号的,也要留意,别聊两句就来回切了啊……
第四条和第五条可以放在一起说,核心意思是一样的:session 期间,工具集不要动。
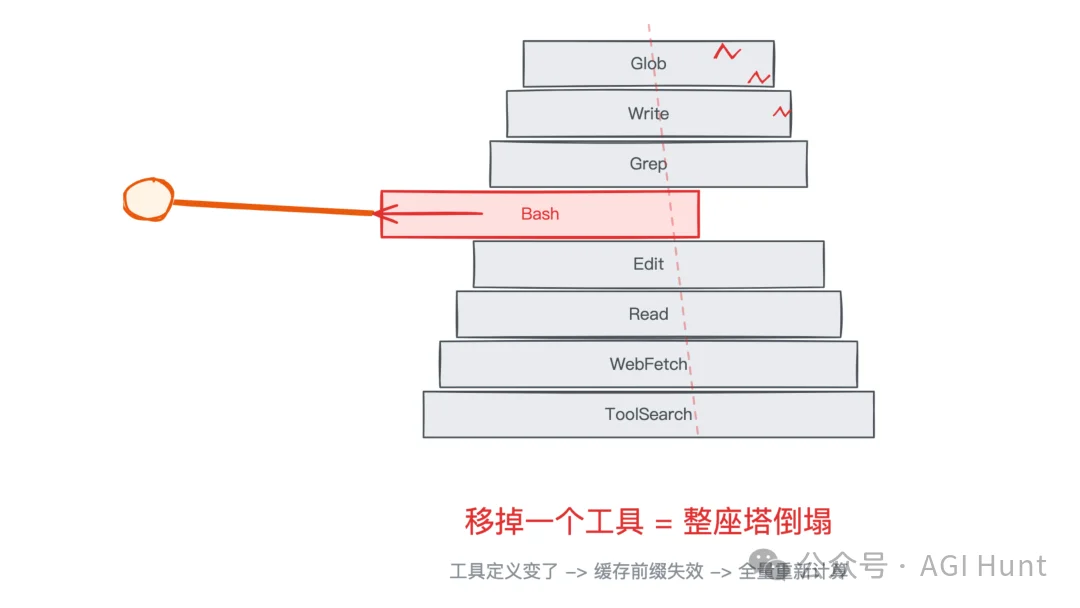
直觉上,你可能觉得:当前任务只需要 3 个工具,为什么要把 30 个工具的定义都留在 context 里呢?把用不着的移掉不是更干净?
但工具定义是缓存前缀的一部分。
加一个、减一个……缓存就断了。一断就是整个对话的缓存全部重建,代价远远超过多放几个工具定义的 token 开销。
看似在优化,实则在添乱。
Claude Code 有个 Plan Mode,进入后模型只做思考和规划,不执行操作。
按照直觉的做法,进 Plan Mode 就把执行类工具移走,退出来再加回来。
但 Anthropic 没这么干。
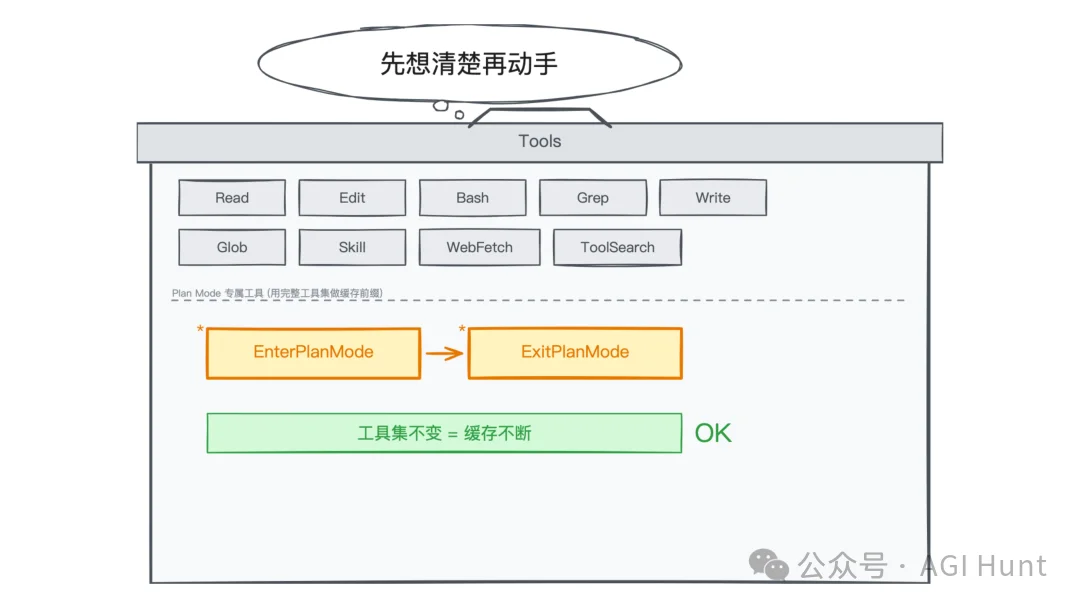
Plan Mode 设计
他们的做法是保留所有工具不动,然后加了两个特殊工具:EnterPlanMode 和 ExitPlanMode。模型调用 EnterPlanMode 就进入规划模式,调用 ExitPlanMode 就退出。
至于「规划模式下不能执行操作」这个约束,用 system message 来传达就好,工具集不用碰。
这样一来,工具集始终不变,缓存始终有效。
而且还带来了一个额外的好处:模型可以自主判断什么时候该进 Plan Mode。遇到复杂任务,它自己调用 EnterPlanMode 先想清楚再动手,不需要用户手动切换。
Claude Code 可能会接入几十个 MCP 工具。把所有工具的完整 schema 都塞进 prompt,token 开销太大;但如果按需加减工具,又会破坏缓存。
Anthropic 找到的折中方案是延迟加载。
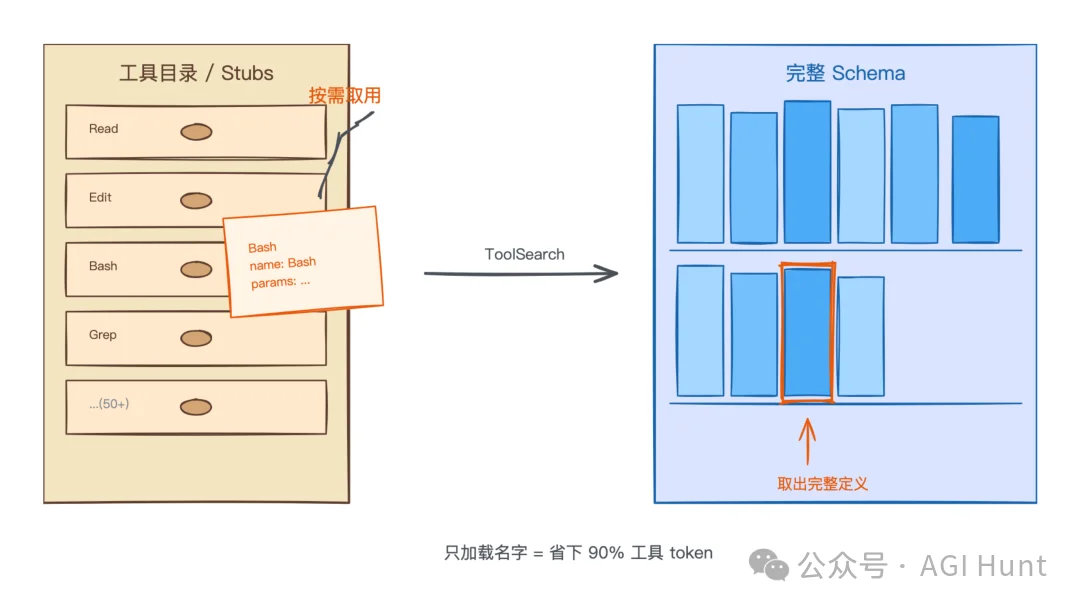
图书馆目录
一开始只放一个轻量的 stub(存根),标记 defer_loading: true。模型看到的只是工具名和一句话描述,不含完整的参数定义。
等模型真的需要用某个工具了,通过 Tool Search 去拉取完整 schema。
这样做的好处是:prompt 前缀始终只包含那些轻量 stub,不会因为加载了某个工具的完整 schema 而变化。缓存稳稳的。
相当于图书馆的书目索引:你先翻目录,找到想看的书再去书架取,不用把所有书都搬到桌上。
最后一条是关于 context 压缩的,也是技术上最巧妙的一条。
长对话跑久了,context window 会被填满。这时候需要把之前的对话压缩成一个摘要,腾出空间继续聊。
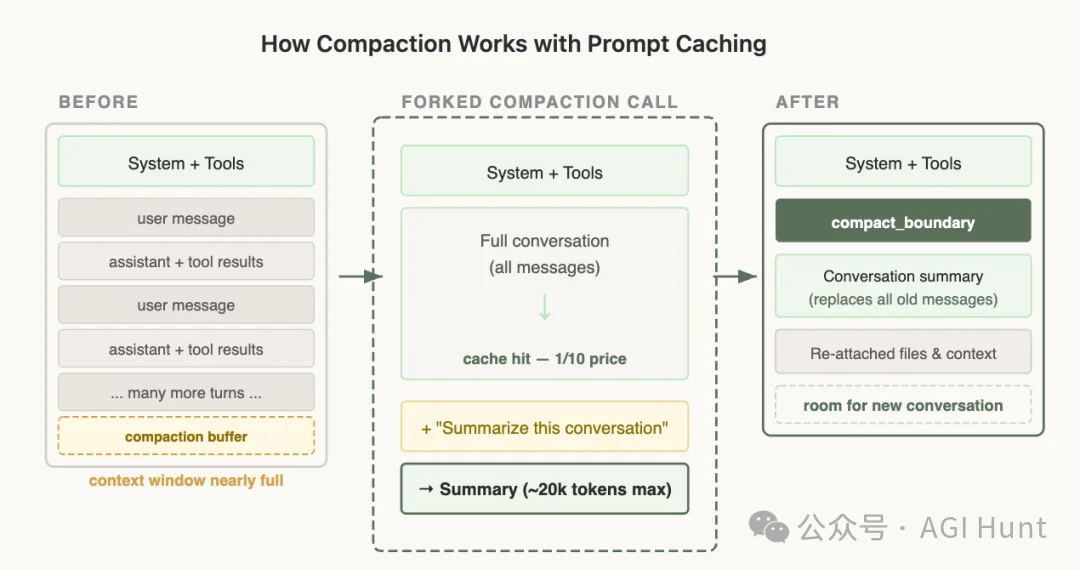
Compaction 压缩流程
但问题来了:如果你另起一个 API 调用来做压缩,用了不同的 system prompt、没带工具定义……那从第一个 token 开始就跟主对话的缓存完全对不上了。
两条缓存链,互相不复用,白白多花一份钱。
Anthropic 的解决方案叫「Cache-Safe Forking」:
压缩请求必须用跟主对话完全一样的 system prompt、user context、工具定义,把主对话的消息作为历史带上。
然后在末尾追加一条压缩指令,作为新的 user message。
这样一来,压缩请求跟主对话共享同一条缓存链,新增的成本只有最后那条压缩指令本身。
同时,还要预留一个「压缩缓冲区」,给摘要输出留够空间。
一个压缩操作,能复用主对话积攒下来的全部缓存,几乎不会多花什么钱。
回头看这 7 条经验,其实都在说同一件事:Prompt Caching 是前缀匹配。
所有的设计,都要围绕这一个约束来展开。
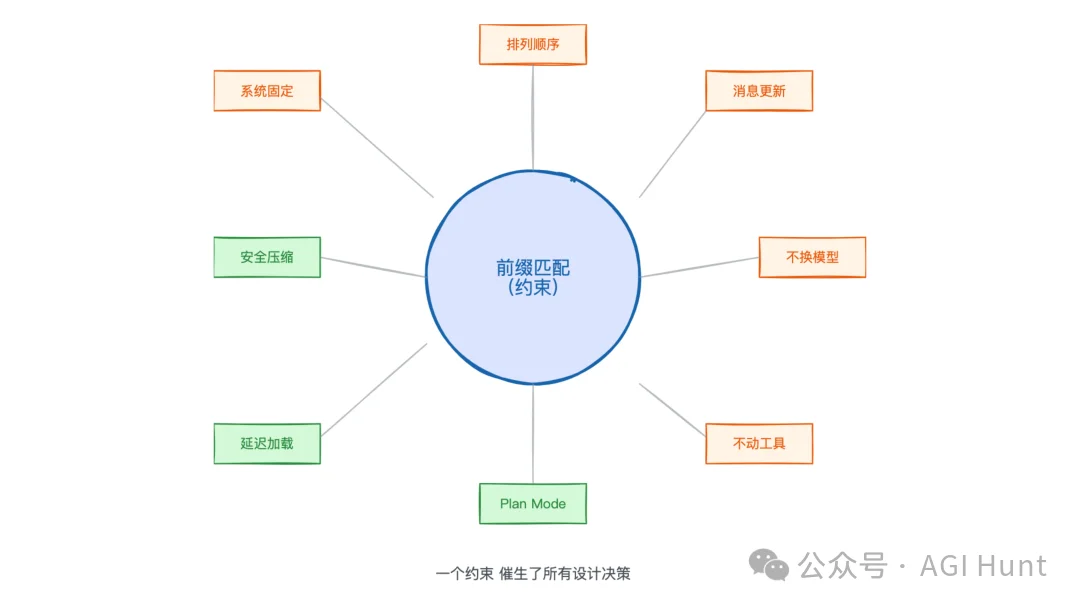
别改 prompt,别换模型,别动工具,别另起炉灶,别瞎切账号……
这看起来是在讲缓存优化,但也是在讲一种系统设计哲学:先确定约束,再围绕约束做设计。
Anthropic 还提到,Compaction 功能已经直接内置到了 API 中,开发者可以直接用,不需要自己从头实现。
对于正在构建 Agent 产品的开发者来说,这篇博客的价值在于:它把缓存从一个优化手段,提升到了架构约束的层面。
并非「做完了顺便加个缓存」,而是得从第一天起,就围绕缓存来设计。
原文链接:https://claude.com/blog/lessons-from-building-claude-code-prompt-caching-is-everything
Claude Code 文档:https://code.claude.com/docs/en/overview
文章来自于微信公众号 "AGI Hunt",作者 "AGI Hunt"


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
