# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一位中国开发者,在横跨大西洋的 11 小时航程中,拒绝了 25 美元的机上网络,却在万米高空完成了一整套复杂的客户项目交付?
没有 Cloud API,没有 Anthropic,没有 OpenAI,甚至没有一格信号。
只有一台 MacBook Pro M4、一段自己写的编排脚本,以及Llama 70B这个本地AI模型,然后就把项目跑通了?
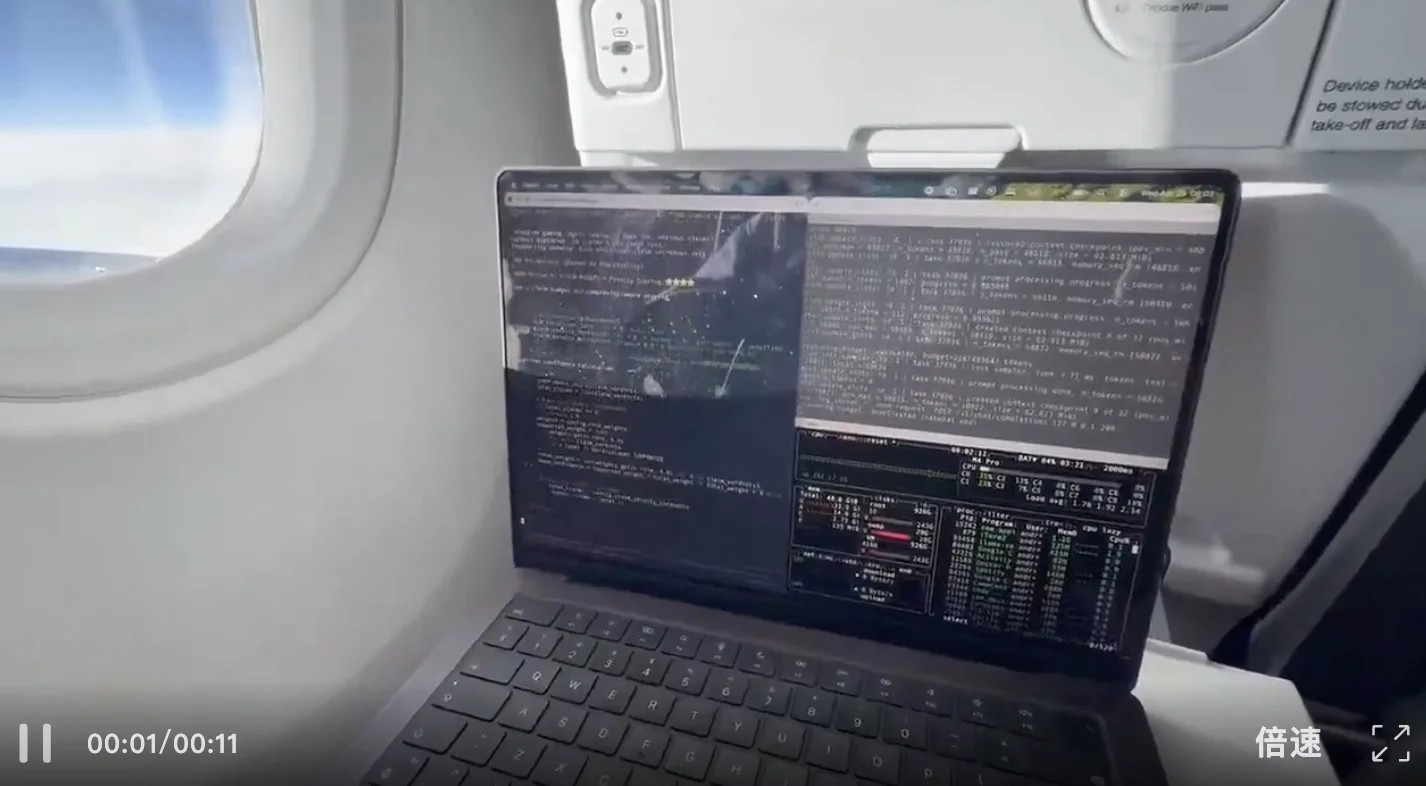
舷窗外是白云与蓝天,没有 WiFi;小桌板上是一台 MacBook,终端开着两个窗口,本地运行着一个推理服务器
因为太过炸裂,这个帖子一经发出,就在技术社区传开了。
本地推理的时代,真的来了?
在万米高空,
用MacBook跑Llama 70B
据说,故事的主角是一位中国开发者。
在飞往大洋彼岸的靠窗座位上,他打开64GB内存的MacBook Pro,面对的是堆积如山的客户任务队列。
接下来整整11个小时,都没有网络。
换做普通人,此刻已经乖乖掏出信用卡,支付那昂贵且延迟极高的 25 美元机上 Wi-Fi。
但他选择了另一条路:本地推理。
他启动了通过 llama.cpp 运行的 Llama 3.3 70B。
生成速度 71 tokens/秒,上下文约 60,000 tokens,内存占用 48.6 GiB / 64 GiB,起飞时电池剩余 3 小时 21 分钟。

为了让这个庞然大物在64GB内存的机器上跑起来,他甚至为自己编写了一个「离线编排器」脚本。
最令人拍案叫绝的,是他给AI下达的系统提示词。
你是一个运行在单台 MacBook 上的离线编排器。没有网络。你唯一的资源是 /Users/dev/work 下的本地文件、localhost:8080 的 Llama 70B 推理服务,以及 3 小时 21 分钟的电池预算。
处理 /Users/dev/work/queue.jsonl 中的任务队列(每行一个客户任务)。对每个任务:起草 → 运行本地评估 → 保存产物到 /Users/dev/work/done/。每 12 个任务保存一次上下文检查点,以便更换电池后恢复。仅在队列为空或电池低于 5% 时停止。
因此,这个系统完全清楚自己所处的困境。
它知道自己未来 11 小时与世隔绝,知道内存和电池是有限的奢侈品,甚至知道在飞机降落前,它必须独自处理所有的逻辑。
系统在一个循环中运行:从任务队列中取出一个任务,进行推理处理,保存生成结果,写入检查点。一个接一个,就这样持续执行。

只有当电量低于 5% 时,调度器才会自动暂停,等待笔记本切换到备用移动电源,然后从上一次的检查点继续运行。
飞行过程中,系统日志里写下了这样的内容:
「已保存上下文检查点 8 / 12(pos_min = 488,pos_max = 50118,大小 = 62.813 MiB)」
「已恢复上下文检查点(pos_min = 488,pos_max = 50118)」
「提示处理进度:n_tokens = 50 / 60,818」
「任务 37016 完成 | 处理速度 = 71 tokens/s → 输出至 /Users/dev/work/done/proposal_westside.md」
有人惊呼:这是我过去一年里见过的最干净利落的离线 AI 工作流程!
11 小时航程,WiFi 花费为 0,当飞机轮子触碰跑道的那一刻,他合上电脑,所有的客户提案已经整整齐齐地躺在 done/ 文件夹里。
系统不再是一个只会复读的复读机,而是一个具备资源意识的管理者。
这正是「Self-aware Computing」最迷人的地方。
网友打假:
技术神话,还是「赛博爽文」?
不过,文章在社区疯传后,很快引来了技术极客们的质疑。
资深开发者们纷纷掏出计算器,开始疯狂「对线」。
第一刀:内存与权重的「不可能三角」
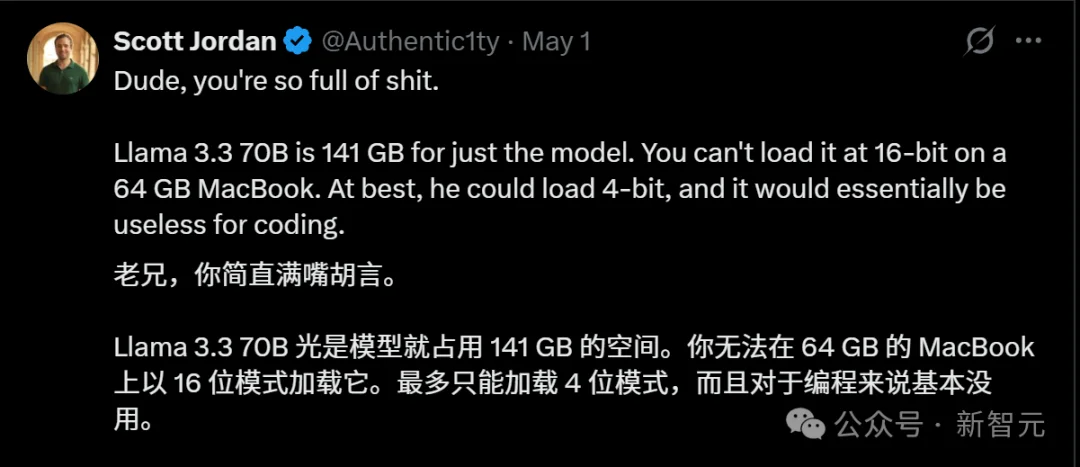
Llama 3.3 70B 如果以 BF16(半精度)运行,光模型权重就需要约 140GB 内存。要在 64GB 的 MacBook 上跑起来,简直就像把大象塞进冰箱。
64GB 内存大概率只能跑 4-bit 量化版本,算上 60k 的上下文 KV Cache,内存占用至少也要 40GB+,BF16 绝无可能。
非要说的话,要在64GB上跑70B,只有一条路——量化。4-bit量化后模型约35GB,加上KV缓存和系统开销,勉强能塞进去。

但量化版本和BF16是两回事,精度、推理质量都会打折扣。
帖子里写的是「bf16」。看起来,这个细节要么是不懂,要么是故意的。
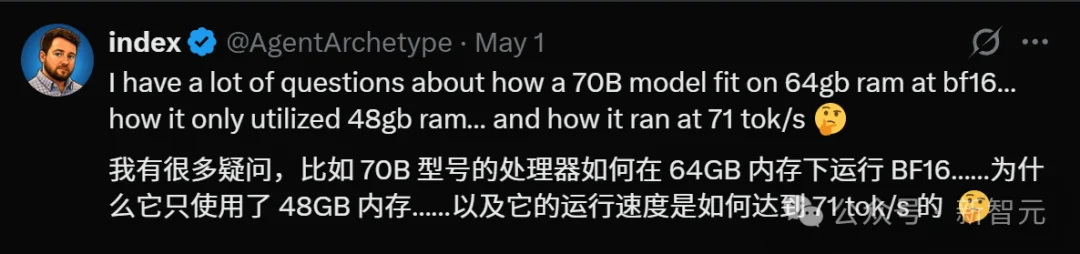
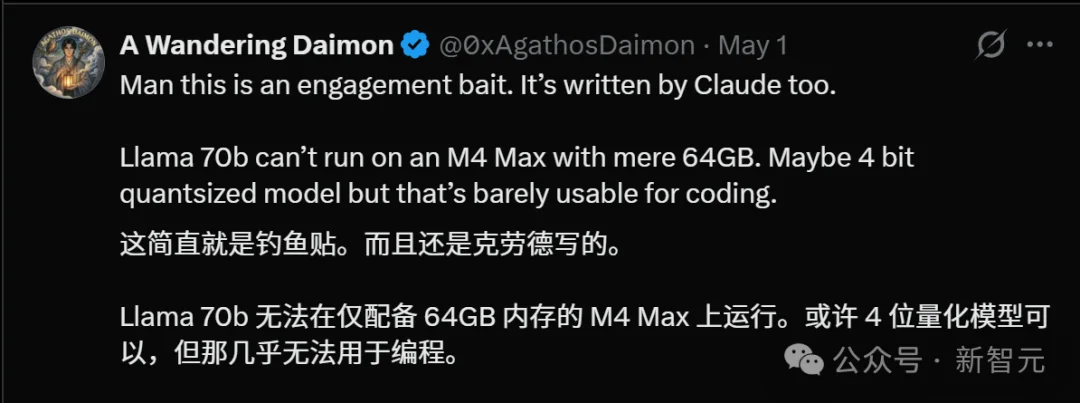

第二刀:71 tokens/s 的「神仙速度」
帖子声称生成速度71 tokens/s。
根据 M4 芯片的实际表现,本地运行 70B 规模的模型,生成速度通常在 5-12 tokens/s 之间。
71 tokens/s 是什么概念?这几乎是顶级 H100 集群的响应速度。
「这个速度可能是 8B 模型或者是某种极致的投机采样,70B 跑出这个速度,MacBook 怕是要起火。」
评论区一位用户直接亮出自己的实测数据:M5 Max 128GB(注意,128GB,是帖子里设备内存的两倍),跑同款模型量化版llama.cpp,实测12.8 tokens/s。
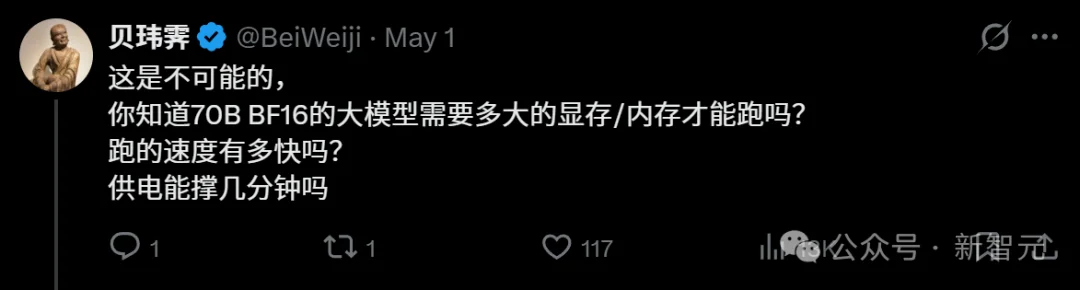
更高端的硬件,跑更轻的量化版本,速度反而只有帖子声称的五分之一,因此,原帖中说的速度几乎不可能实现。
第三刀:11小时续航
帖子中提到的「更换电池」引发了老用户的集体怀旧:现代 MacBook Pro 都是一体化设计,所谓的「换电池」,大概率是切换到了大功率的备用充电宝(如百瓦快充移动电源)。
MacBook Pro M4 Max官方标称续航约18小时,那是轻度使用。持续满载跑70B推理,GPU和内存全程拉满,实际续航会大幅缩水。
虽然帖子里提到「切换到备用充电宝后恢复」——但跨大西洋航班经济舱的USB口功率通常只有7.5W到18W,而M4 Max满载功耗超过40W。
因此,续航11小时这个说法几乎站不住脚。

故事是假的,但范式转向是真的
面对质疑,我们需要剥开数据的水份,看清这件事背后真正令科技圈高潮的原因。
长期以来,我们已经习惯了「云端成瘾」。
没有 GPT-4 的 API,很多开发者甚至不知道该如何写代码;没有网络,AI 就变成了一个哑巴。
现在,本地推理,确实在发生一场静悄悄的革命。
2024年,在笔记本上跑7B模型还需要各种技巧。
2026年,M4 Mac上跑70B量化版已经是日常操作。虽然速度不快,大概10来个tokens/s,但已经能用。
真实的使用场景不是「飞机上交付完整项目」这种听起来很爽的叙事,而是一些更朴素的东西,比如离线环境下的文档问答,隐私敏感场景下不想把数据传上云等等。
这些场景不性感,但实用。
现在,llama.cpp的mlx后端已经针对Apple Silicon做了深度优化,Ollama也把部署门槛压到了一条命令。
即便 71 tokens/s 的速度存疑,BF16 的精度可能有夸张,但这种「在孤岛上建立文明」的技术浪漫主义,才是最牛的。
未来,最顶尖的开发者或许不再是那个最会调优云端 Prompt 的人,而是那个能在资源枯竭、完全离线的极端环境下,手搓出一个「自感知、自循环」AI 系统的人。
下一次坐飞机,你准备好带上你的「数字大脑」了吗?
参考资料:https://x.com/servasyy_ai/status/2050098091789828376
文章来自于微信公众号 "新智元",作者 "新智元"


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
