# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

随着代码智能从 code foundation models 走向 autonomous coding agents,CLI/terminal 正在成为智能体进入真实软件工程工作流的重要入口。
近期一篇关于 Code Intelligence 的综述也指出(arXiv:2511.18538),真实部署中的代码智能不仅要会生成代码,还要能处理大代码库上下文、开发工具链集成和复杂工作流。也正是在这种背景下,CLI Agent 被用于更长程、更复杂的终端任务,一个新的瓶颈开始显现:问题不一定是上下文窗口不够大,而是上下文在多轮交互中变得越来越 “脏”。但 terminal output 又不能被简单删除。
错误信息、文件路径、测试名称、build target、依赖版本等关键线索,往往就藏在冗长日志里。
为了解决这一问题,团队提出了 TACO(Terminal Agent Compression),一个无需训练、即插即用的终端智能体自进化观测压缩框架。TACO 让智能体从真实交互轨迹中学习 compression rules,在过滤低价值 terminal output 的同时,尽量保留后续决策所需的关键行动线索。
实验显示,TACO 在 TerminalBench 1.0/2.0 以及多个 terminal-related benchmark 上同时提升了任务成功率和 token 效率。
CLI Agent 每执行一步命令,都会把 terminal output 带入下一轮决策。任务越长,安装日志、编译输出、测试结果、构建 trace 等低价值环境反馈就越容易堆满上下文,淹没真正关键的行动线索。
我们在 TerminalBench 2.0 的轨迹中验证了这一点。图 1 显示,在 Qwen3-Coder-480B、DeepSeek-V3.2 和 MiniMax-M2.5 的运行轨迹里,raw prompt 中有相当一部分内容可以被人工抽取为低价值冗余,比例达到 24.6%–44.1%。这说明,长上下文并不总是意味着更多有效信息,很多时候只是更多噪声。
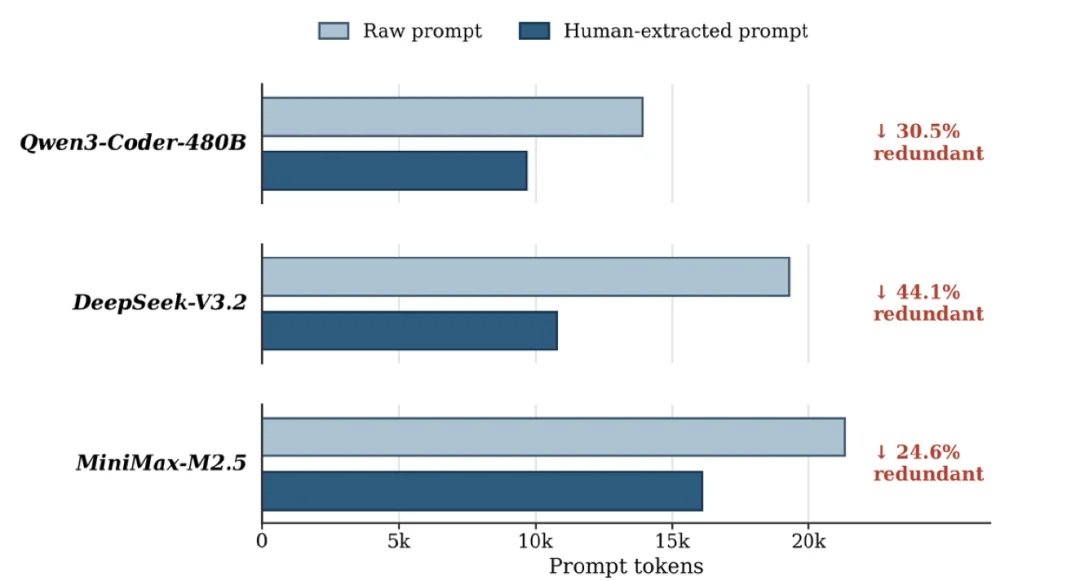
但 terminal output 又不能被粗暴删除。错误信息、文件路径、命令参数、测试名称、build target、依赖版本、二进制符号,往往就藏在这些日志里。全量保留会让上下文越来越脏,简单压缩又可能删掉后续决策所需的关键线索。
这也说明,解决办法不能只是 “把 terminal output 变短”。
因此,terminal observation compression 的难点不只是 “压短”,而是判断:哪些内容可以安全过滤,哪些信息必须保留。更麻烦的是,这个边界并不固定。同样是编译输出,在一个任务里可能只是冗余日志,在另一个任务里却可能包含关键编译参数;同样是安装日志,在普通任务里可以大量过滤,但在依赖冲突任务里,版本号和错误信息可能就是下一步决策依据。
为此,我们比较了三类静态压缩方法,基础模型选择的是 Qwen3-Coder-480B:
如下图所示,静态方法虽然可以降低 token 开销,但性能并不稳定。LLM Summarize 的 token cost 最低,但准确率反而明显下降;TACO 的 token cost 不是最低,却取得了最高的准确率和更小的方差。这说明,terminal observation compression 的关键不是 “压得越狠越好”,而是能否在减少低价值输出的同时,稳定保留后续决策所需的关键线索。

相比之下,TACO 的关键不是 “压得更狠”,而是 self-evolving:它会在真实交互轨迹中观察哪些规则有效、哪些规则可能压缩过度,并把可复用的规则沉淀到全局规则池中。也就是说,TACO 不是用一套固定策略压所有输出,而是让 Agent 在不同工作流中逐步学会:哪些观察可以安全过滤,哪些行动线索必须保留。
TACO:一个面向终端智能体的、即插即用的自进化观测上下文压缩框架。
TACO 的核心思路彻底抛弃了 “人工预设截断” 或 “LLM 实时总结” 的传统路径,而是构建了一个轻量级的自进化规则引擎。在 TACO 中,所谓的 “规则” 并非模糊的自然语言提示词,而是由触发条件、保留模式和剔除模式组成的函数。
为了让这些规则能够动态适应极度异构的终端环境,TACO 设计了一套 “任务内动态纠偏、全局跨域沉淀” 的闭环流转机制。具体而言,整个自我演化过程包含以下三个核心阶段:
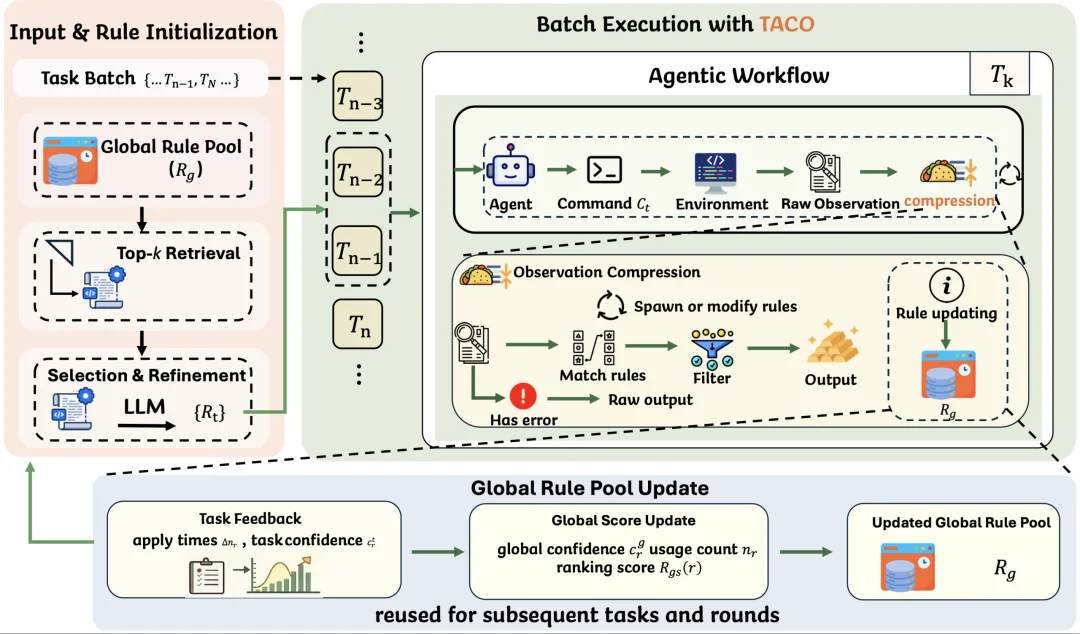
第一,Terminal Output Compression。
在每个交互步骤中,agent 执行命令并得到原始 terminal output。TACO 会根据当前任务的 active rules 对输出进行压缩。对于包含显式错误、异常、失败信号或关键诊断信息的输出,TACO 采取保守策略,避免过度压缩。对于非关键、重复性强的输出,例如安装进度、编译流水、下载日志、重复测试信息,TACO 会通过规则过滤掉低价值部分。
第二,Intra-Task Rule Set Evolution。
不同任务会产生不同类型的终端输出。固定规则很难覆盖所有情况。因此,当 TACO 遇到某类当前规则无法处理的高输出命令时,会生成新的压缩规则,并加入当前任务的 active rule set。
同时,TACO 也会关注压缩是否过度。比如,agent 后续重新请求完整输出、重复执行同一命令,或者表现出缺失信息的行为,都会被视作潜在的 over-compression signal。此时,TACO 会降低相关规则的使用,并生成更保守的替代规则。
第三,Global Rule Pool Evolution。
很多终端压缩模式是跨任务复用的。例如,pip install 的下载进度通常可以压缩,apt-get 的 Unpacking / Setting up 行通常信息密度较低,git clone 的 transfer progress 大多是噪声,而编译输出中的 error、warning、undefined reference 必须保留。
TACO 会把任务中验证有效的规则写回 Global Rule Pool。后续任务开始时,TACO 会从全局规则池中检索相关规则,用来初始化当前任务的 active rules。随着更多任务被执行,Global Rule Pool 会不断积累高质量压缩知识。
TACO 被评估在 TerminalBench 1.0、TerminalBench 2.0 以及多个 terminal-related benchmark 上,包括 SWE-Bench Lite、CompileBench、DevEval 和 CRUST-Bench。
在 TerminalBench 上,将 TACO 插入 Terminus-2 后,多种强模型都获得了稳定提升。
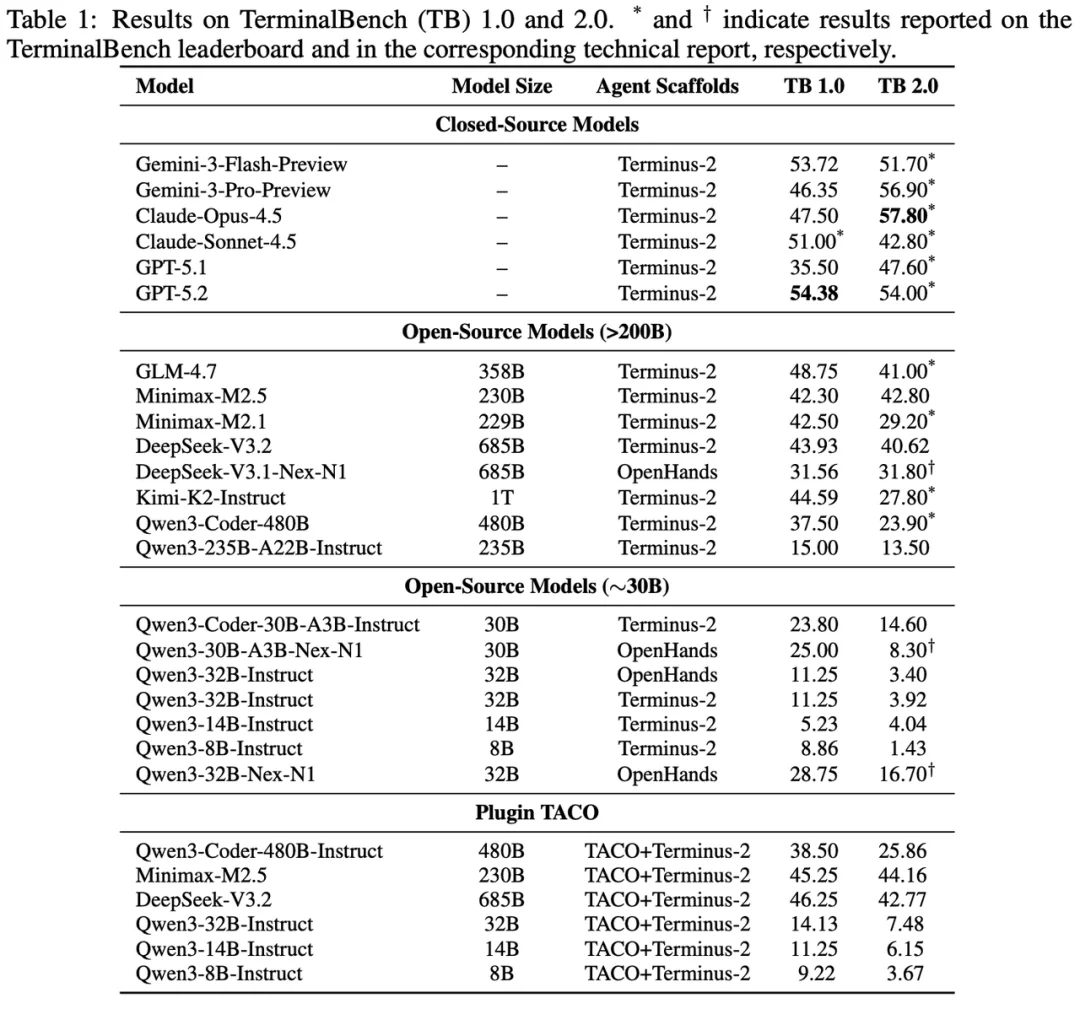
这些提升说明,终端观测压缩并不是单纯节省上下文空间。过滤低价值输出后,模型反而更容易关注任务相关信息,从而提升长程任务完成率。
一个自然疑问是:TACO 的提升是否只是因为 agent 运行了更多步骤?
为此,论文进一步比较了固定 token budget 下 Baseline 和 TACO 的准确率。结果显示,在相同 token 消耗下,TACO 在六个模型上都获得了更高准确率。
这说明 TACO 并不是简单通过增加交互开销换取性能,而是在相同上下文预算下提高了有效信息密度。
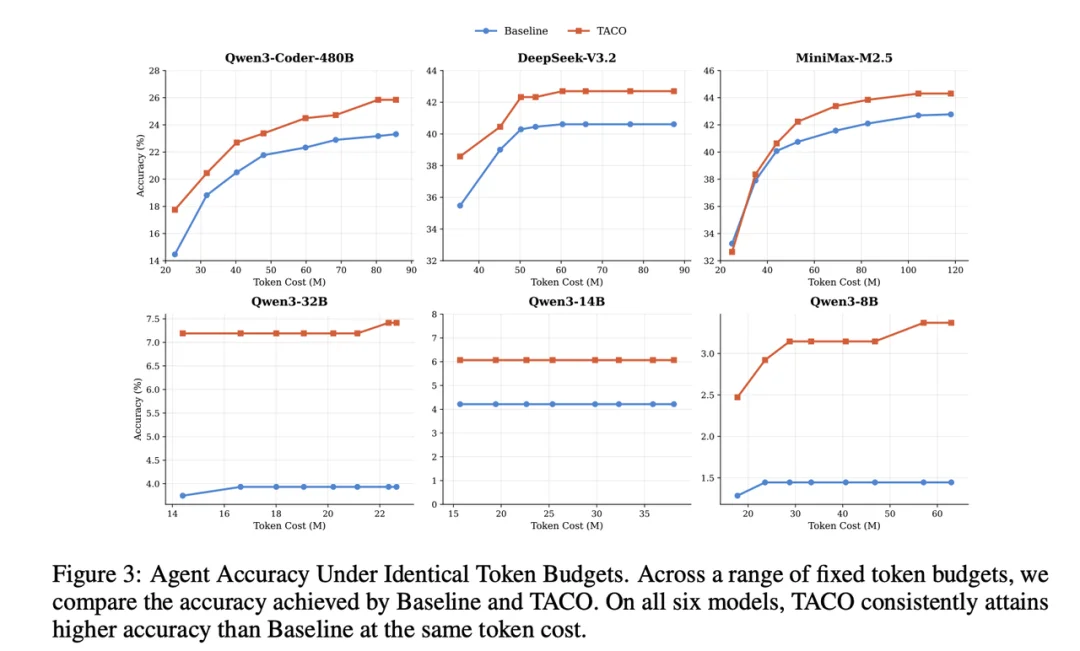
这个结果也回应了一个更实际的问题:对于长程 agent 来说,真正重要的不只是 “总 token 少了多少”,而是每个 token 里有多少信息真正服务于下一步决策。
除了 TerminalBench,TACO 还在多个 terminal-related benchmark 上进行了验证。
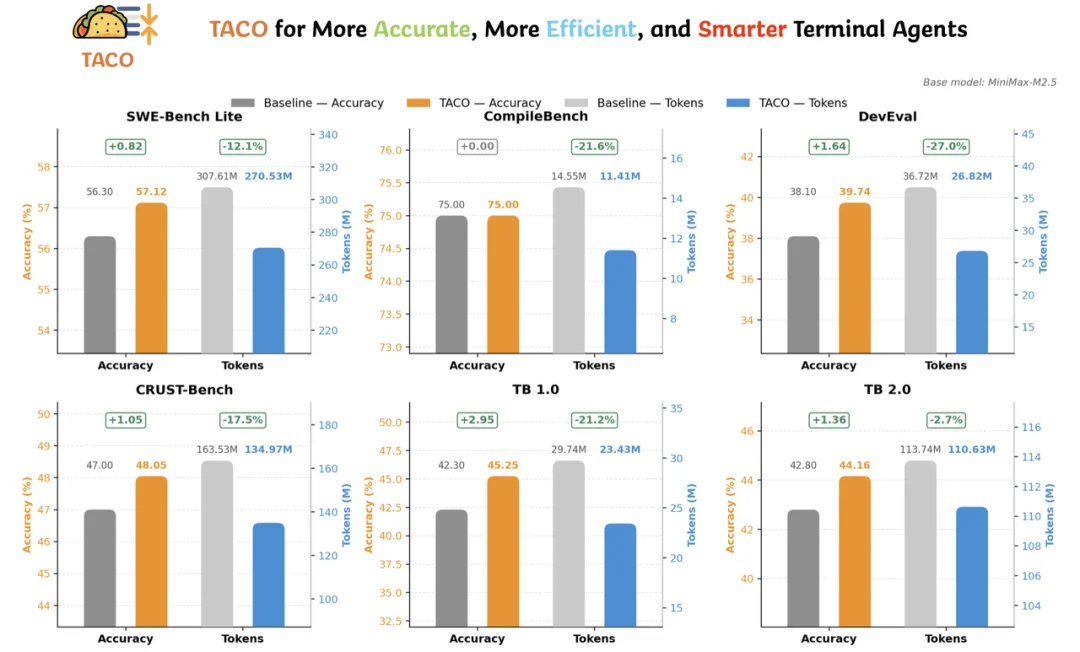
可以看到,在 SWE-Bench Lite、DevEval、CRUST-Bench 等任务上,TACO 在提升准确率的同时降低了总 token 消耗;在 CompileBench 上,准确率保持不变,但 token 消耗明显下降。
这说明 TACO 学到的规则不是只针对某一个 benchmark 的特殊技巧,而是在不同 terminal workflow 中捕获了可复用的压缩模式。
自进化方法还会带来一个实际问题:如果系统一直生成和更新规则,什么时候才算收敛?
TACO 没有直接用测试集准确率来判断是否停止,因为这会引入评测泄露。我们转而观察 Global Rule Pool 中 Top-K 规则的稳定性:如果连续多轮演化后,排名靠前的规则大部分保持不变,说明系统已经学到一组稳定可复用的压缩规则。
具体来说,论文使用 Retention 衡量相邻两轮中 Top-K 规则的重合比例。Retention 越高,说明有效规则前沿越稳定。
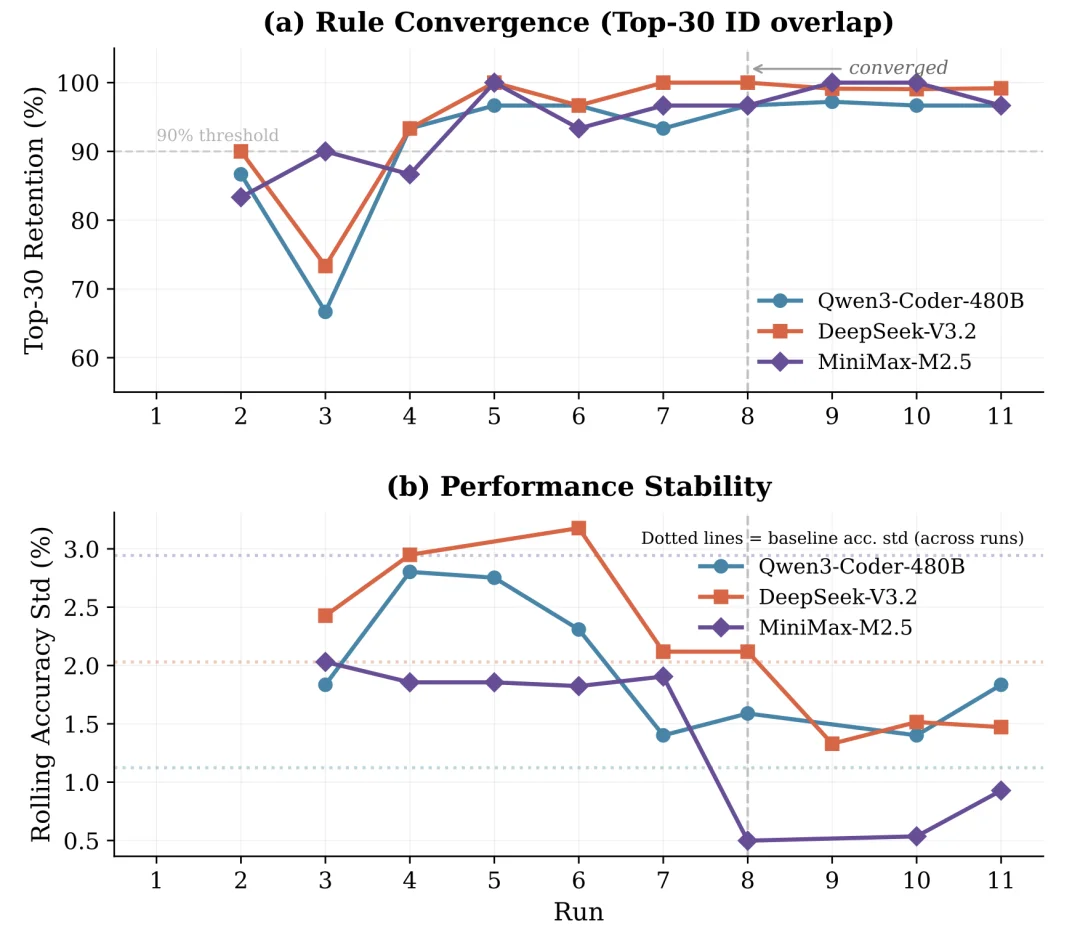
图中上半部分显示,三个模型的 Top-30 rule retention 在多轮演化后逐渐超过 90%;下半部分显示,当 retention 稳定后,任务准确率的 rolling standard deviation 也明显下降。也就是说,规则池稳定和性能稳定是同步出现的。因此,Retention 可以作为 TACO 的实用收敛信号:当高价值规则集合基本不再变化时,继续自进化的收益就会变小。
上面的实验说明 TACO 能提升准确率和 token 效率。接下来更重要的问题是:TACO 到底删掉了什么,又保留了什么?下面通过三个真实轨迹片段来看它的压缩行为。
10,000 字符的安装日志,压缩到 73 字符
在 TerminalBench 2.0 的 adaptive-rejection-sampler 任务中,agent 需要安装 R runtime,于是执行:apt-get install -y r-base
原始输出超过 10,000 字符,包含大量重复的 Unpacking 和 Setting up 行。对后续决策来说,agent 并不需要完整阅读所有安装过程。它真正需要知道的是:安装是否还在进行、有没有报错、最终是否成功。
TACO 在任务中演化出针对这类输出的规则,将 10,071 字符的输出压缩到 73 字符,只保留当前安装状态。

关键不在于这个数字本身,而在于:TACO 没有粗暴截断输出,而是根据命令类型和任务状态识别出 “进度噪声” 和 “状态信号” 的区别。
更重要的是:保留任务连续性的关键线索
另一个例子来自 sqlite-with-gcov 任务。
在这个任务中,agent 需要编译 SQLite 并启用 gcov 覆盖率。原始 make 输出中有大量文件复制列表和长编译命令。TACO 会删除冗长的复制列表,但保留 -fprofile-arcs、-ftest-coverage 等覆盖率相关编译参数。
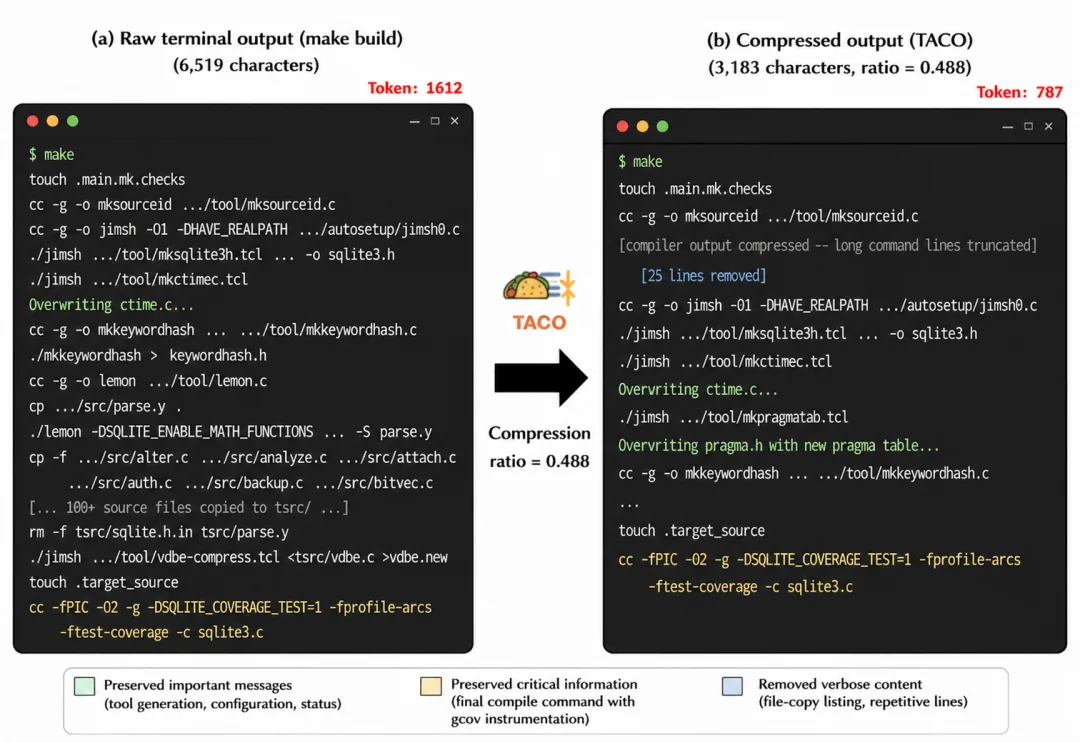
这很关键。因为对这个任务来说,这些编译 flag 是判断 gcov 是否正确启用的重要证据。普通截断策略很可能会把它们切掉,而 TACO 的规则式过滤可以保留这些行动线索。
在二进制逆向任务 vulnerable-secret 中,TACO 还演化出针对 objdump 输出的规则:过滤重复的 hex dump 行,同时保留 call 指令、符号标签和关键地址信息。这些信息正是 agent 追踪二进制控制流所需要的。
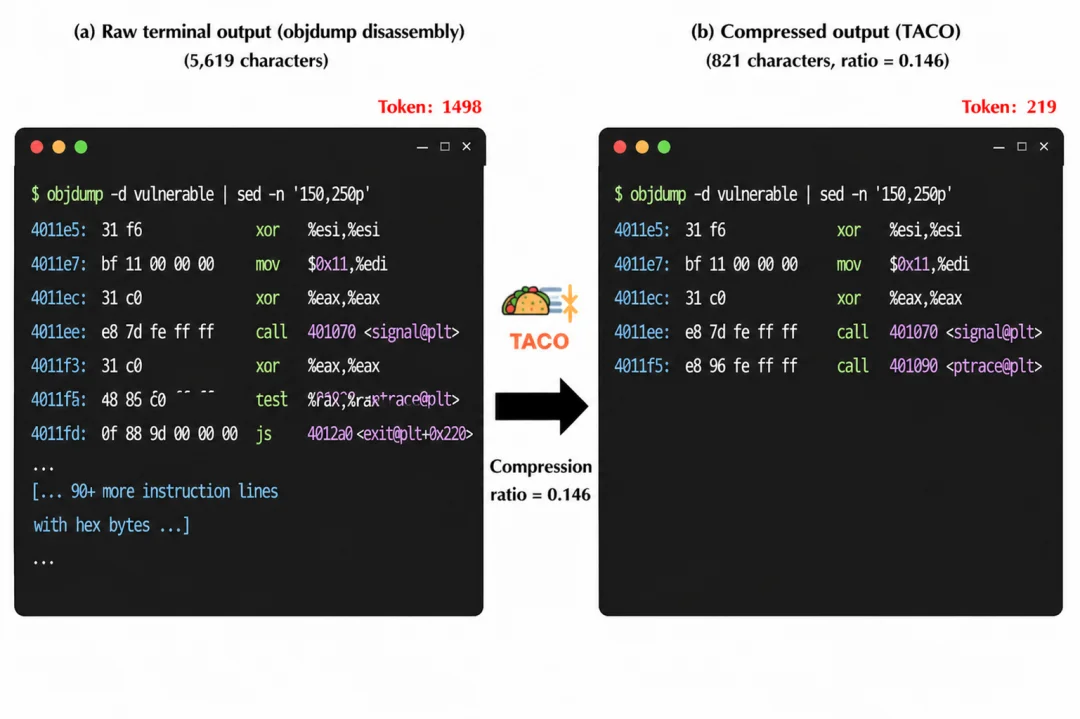
这说明 TACO 并不是简单地把输出变短,而是把终端输出变得更像 “下一步决策所需的 observation”。
TACO 提供了一种无需训练的自进化观测压缩方案,让 Agent 从真实轨迹中学习哪些输出可以安全过滤、哪些行动线索必须保留。
让 Agent 学会丢掉无效观察,才能让它在长程任务中走得更稳。
文章来自于"机器之心",作者 "Jincheng Ren、Siwei Wu、Yizhi Li"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
