# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
GENE-26.5 值得看的,是它背后的「具身智能版 Harness + 模型」。

5 月 7 日,Genesis AI 正式发布了:
GENE-26.5。

26.5,代表 2026 年 5 月。按照官方博客里的说法,这也是 GENE 系列第一次公开发布。
几天前它刚发布出来,就在海内外具身智能圈引发了不少讨论。原因也比较简单,这次视频 Demo 里的机器人,开始做一些过去很少被机器人 demo 真正做到的事情,能力有了比较直观的提升。
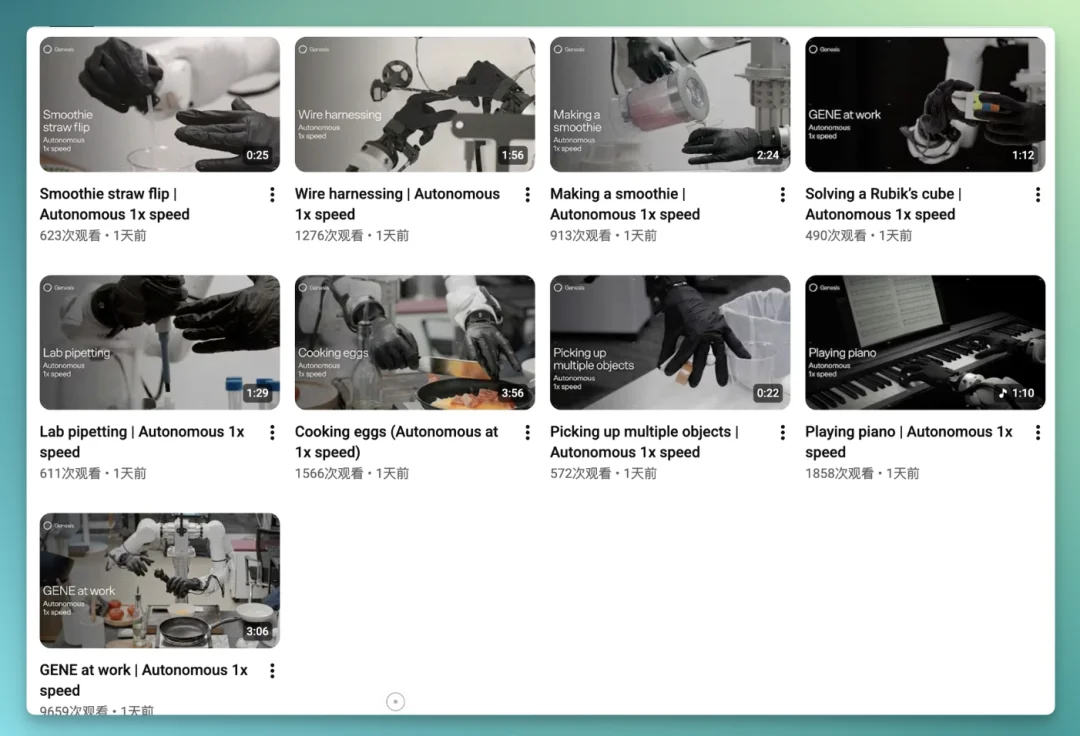
比如,单手打鸡蛋、双手切番茄、用刀背把切好的番茄从案板上转移出去:

抓移液器、插枪头、拧小管盖、整理线束、解魔方,一只手同时夹住好几个不同尺寸的物体等等,一次性全部放了出来:

过去几年,人形机器人视频 Demo 已经足够多了。走路、跳舞、搬箱子、叠衣服、煮咖啡。
很多时候,视觉观感上给人一种比较成熟的「错觉」,但普通人对机器人的期待,最后经常是很真实的:
它到底、什么时候、能真的帮我干活?
干活这件事,对人类来说很普通,但落到机器人身上就会变得异常麻烦。
因为真实世界里的劳动,大部分都不是「走到那里」就结束了。机器人当然要会走路、会保持平衡、会绕开障碍物,这部分在 robotics 里更接近 Locomotion。
但真正把活干完,往往发生在下一步。它要把东西拿起来、转过去、切开、拧紧、插进去、折起来,最后放到一个刚刚好的位置。这就是 Manipulation,也就是操作。
GENE-26.5 的官方博客里,其实也是这样区分的。Locomotion 里的接触,更多是为了支撑身体;Manipulation 里的接触,本身就是任务。
类似这样的概念区分,官方博客里还提到了很多,所以如果只把它当成一组宣传 demo,可能会错过更重要的东西。
🚥
我们阅读整理了原博客内容,这次 GENE-26.5 的发布,展现出来的最大亮点,可能是机器人基础模型的竞争的重点已经发生了转向:从基础模型到「具身智能版 Harness + 模型」。
所以这篇文章,我们想从这一套「全栈底层系统」开始,分享我们的观察。
Genesis AI 这家公司本身值得先说一下。
AI 这家公司本身值得先说一下。
它确实是一家非常早期的公司,从公开信息看,Genesis AI 今年才正式进入外界视野,但团队组合比较典型:周衔的背景更偏机器人和物理仿真,Théophile Gervet 则有大模型公司研究经历。

这不是一家已经在聚光灯下反复出现很多年的机器人公司。
但它第一次公开发布,就把模型、灵巧手、训练手套、控制系统、仿真评估等一整套「具身智能版 Harness + 模型」全部放出来了。
这与其在融资方面的「异常信息」比较相符合。
融资方面,Genesis 的唯一官方披露轮次就是 1.05 亿美元 seed。公司官方写明此轮由 Eclipse 与 Khosla Ventures 共领投,参投者包括 Bpifrance、HSG、Eric Schmidt 和 Xavier Niel 等等。
TechCrunch 与 Reuters 都把这轮融资描述为「异常大的 seed(giant $105M seed round)」。
Reuters 甚至指出它与 Mistral AI 在法国创下的超大种子轮规模相当。这种资本配置对一家成立约一年、尚未公开客户名单的机器人公司而言,其实是非常罕见的,资方押注的显然是其底层平台价值。
这可能就是 full-stack robotics 的价值。
官方博客里有一句话很值得注意:
如果目标是 human-level manipulation,解决方案就不能只停在模型训练上。
这句话看起来普通,但放到今天的具身智能行业里,其实有点分水岭的味道。
过去两年,大家很容易把注意力放在 VLA 上。视觉、语言、动作,听起来像是把大模型接进机器人之后,问题就会自然往前推进,接下来就只需要数据、Scaling。
但现实中,大模型与机器人的真实表现中间还隔着非常多「道不清、说不明」的东西。
比如:数据怎么收集,硬件能不能精准的表达有「手感」的动作,控制系统有没有延迟,模型输出的轨迹能不能完整地反馈到电机,评估能不能规模化跑起来。这些东西每一层都可能出现问题。
面对这样复杂的一系列问题,GENE-26.5 在其博客中给出了回答:

GENE-26.5 这次给出的答案,大致可以归结成「具身智能版 Harness」,具体则可以拆成几层。
机器人行业一直缺高质量数据,是公认的事实。
Google 做 RT-1 的时候,用 13 台机器人采了 17 个月,最后拿到 13 万条左右的真实机器人 episode。后来 DROID 这种多机构合作的数据集,动用了 50 个采集者,覆盖 564 个场景和 86 个任务,也只是攒出了 350 小时左右的真机交互数据。
这些数据很有价值,但也反过来印证了:真实机器人数据很难像文本、图片、视频那样自然放大。
遥操作可以提供高质量轨迹,但它慢、贵、依赖硬件,也很容易变成「为了采数据而采数据」。相比之下,人类第一视角视频的规模上限要高很多。
Meta 的 Ego4D 已经做到 3000 多小时第一视角视频,来自 9 个国家、855 个佩戴者。
所以到了 GENE-26.5 这里,Genesis AI 强调 human-centric data,并不只是换一个数据来源。它是在尝试绕开机器人数据最难 scale 的地方:让人类真实工作里的动作,变成机器人可以学习的物理经验。
据披露,它的数据引擎里有三类来源:手套数据、第一视角视频、第三人称视频。官方披露的数据规模已经超过 20 万小时。
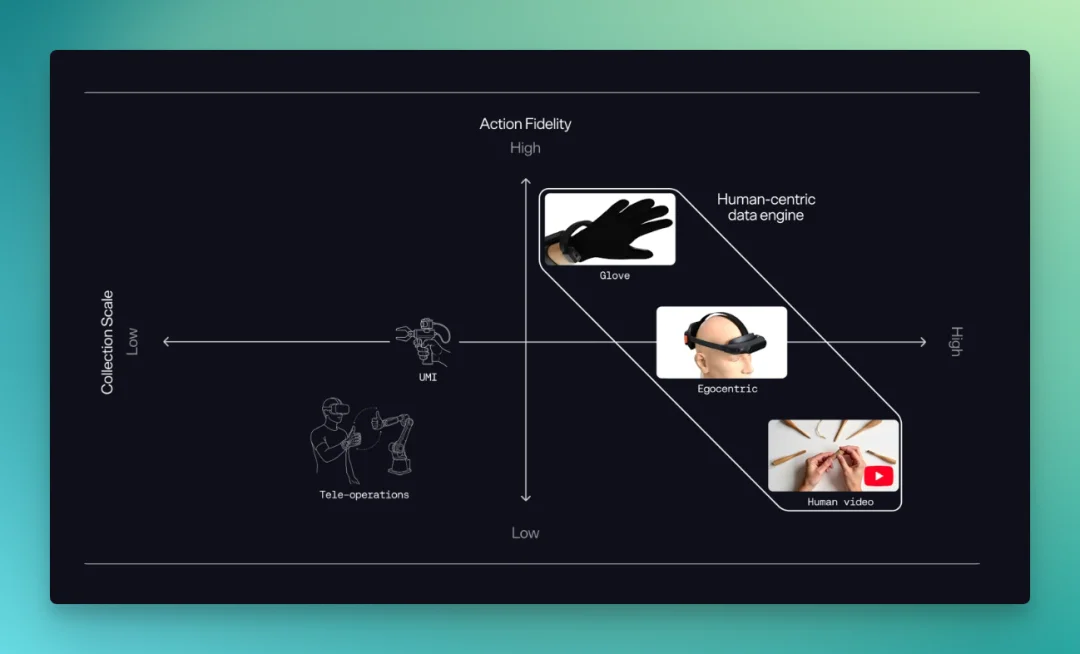
这条路径比较有意思。
因为,第一视角视频可以看到人在真实任务里的自然行为,第三人称视频可以扩大覆盖面,手套数据负责把手部动作和触觉信息记录得更细。
说白了,机器人真正应该学习的,可能不止是实验室里一条条标准轨迹。更有价值的,是人类长期和物理世界打交道时积累下来的「手感」。
这个手感很难写成规则,所以需要数据。
在预训练的 open-loop evaluation 里,他们验证了基础模型的 Scaling Law,也就是模型越大、数据越多、算力越足,效果还在持续变好。
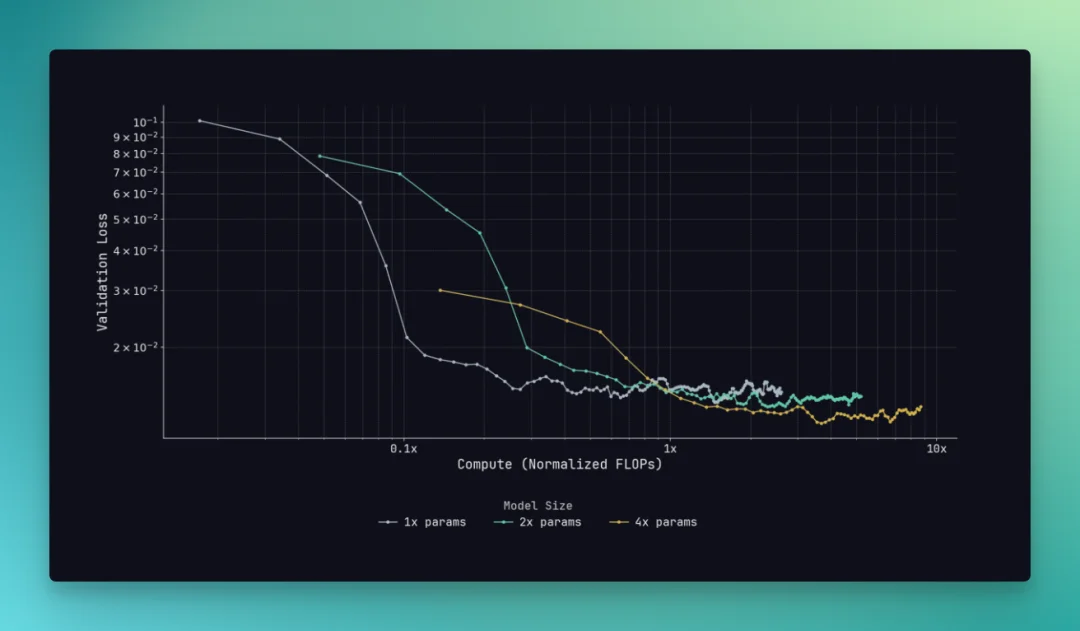
而对于真实数据、合成数据来说,还有一个细节也挺有意思。
GENE-26.5 的官方博客里,几乎没有把 synthetic data 当成核心训练路线来讲。它讲得最多的,是手套数据、第一视角视频、第三人称视频和少量机器人数据。
仿真当然很重要,但在这篇博客里,它更多被放在 closed-loop evaluation 的位置上,用来更快、更稳定地评估模型,而不是作为主要训练数据来源。
这和 Physical Intelligence 的 π 系列公开材料有点接近。
π0 到 π0.7 讲得更多的是真实机器人数据、Web-scale 视觉语言预训练、人类数据和自主执行数据。至少从公开材料看,synthetic data 还没有被写成一条已经充分验证的核心 scaling path。
背后的逻辑其实一样:在 contact-rich manipulation 这种任务上,大家现在最想要的,可能仍然是真实世界里的人类动作和机器人交互数据。
这某种程度上再次说明,至少在接触丰富的机器人操作任务里,合成数据还没有到可以当「主粮」的时候。
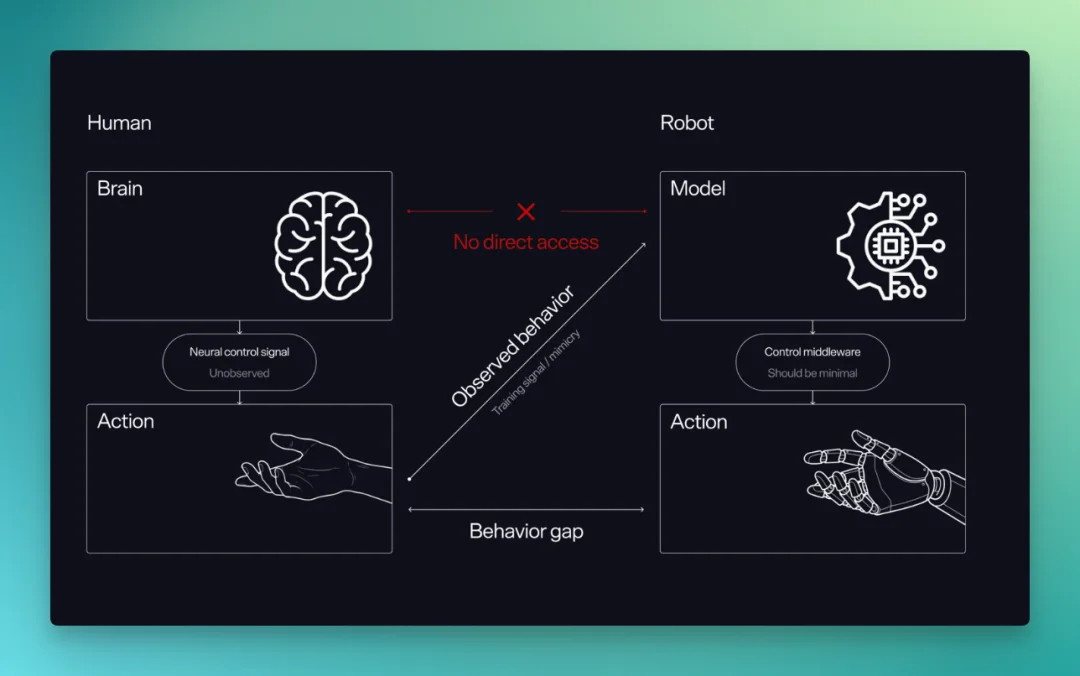
可是,人类数据怎么迁移到机器人?
人手实在是太复杂了。手指长度、关节结构、软接触、皮肤摩擦、手掌形状,这些都会影响动作。人类手部数据再丰富,如果机器人手的形态差太远,迁移时就会损失很多信息。
这就是所谓的 embodiment gap。所以 Genesis AI 会强调 Genesis Hand 1.0。按照官方介绍,这只手的目标是接近人手 1:1 尺寸,有 20 个主动、可反驱自由度,手掌和手指覆盖软材料,用来接近人类皮肤的软接触物理。

其在官方博客里被称为 proprietary(自主专有) 硬件:

但在 Reddit 等社区里,有一些声音认为 Genesis Hand 1.0 的硬件,看起来采用的是深圳舞肌科技的 WUJI HAND,这是由 WUJI TECH 研发的高自由度仿生灵巧手:
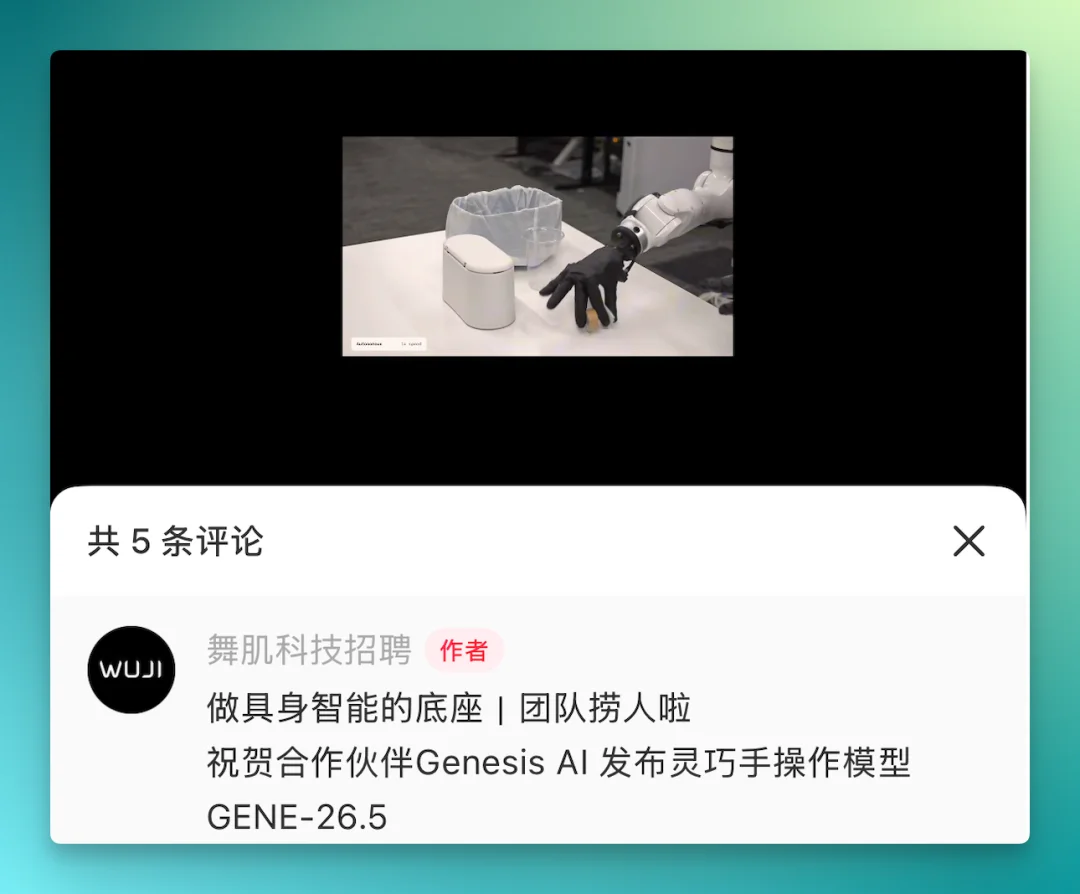
舞肌科技官方也在社区中,转发了 Genesis AI 的 GENE-26.5 发布视频,并称为「合作伙伴」:
除开这个灵巧手「迷思」,GENE-26.5 大致的思路是,如果机器人要从人类手部动作里学习,那么硬件越接近人类,数据迁移的损耗就越小。
传统做法经常需要复杂的动作重映射,把人手动作重新映射到机器人关节空间里。这个过程会丢掉细节,也会把机器人硬件自己的限制混进训练信号里。
所以灵巧手在这里不是传统思路里模型的外设,反而成为了数据系统的一部分。
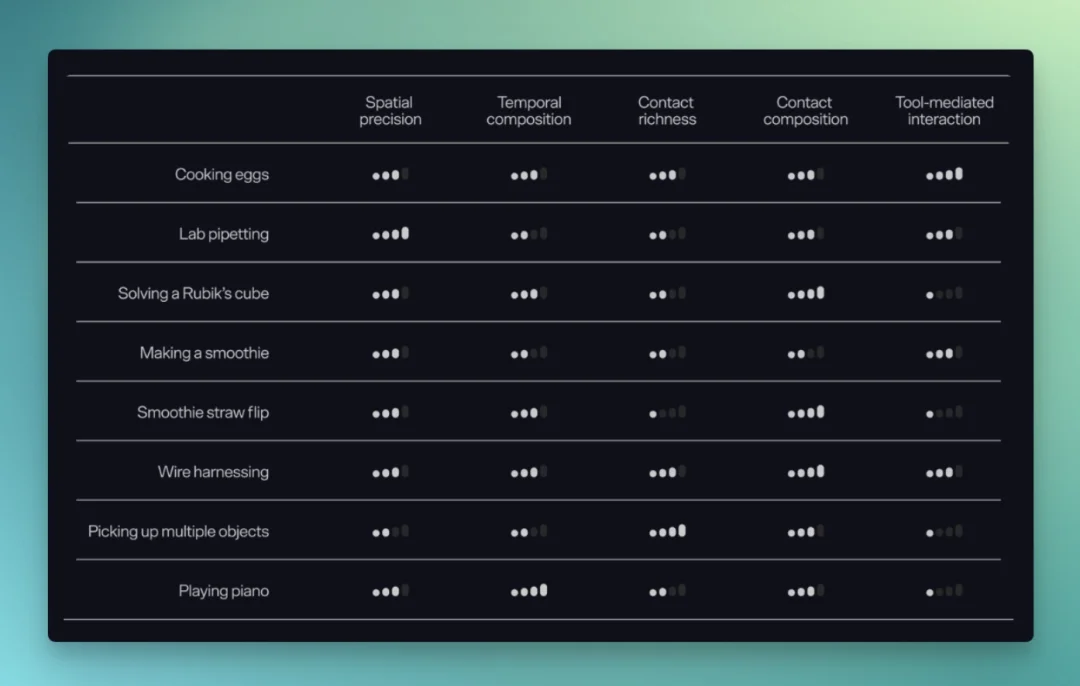
在此基础上,GENE-26.5 做了非常多的任务测试:
这一层可能更容易被忽略,但在机器人里非常关键。
模型输出的动作意图,不能直接变成真实机器人的动作。中间要经过控制器、通信层、低层执行、电机驱动。任何一点延迟和误差,都会把模型想做的事扭曲掉。
官方博客里给了一些很具体的 DEMO,其最典型的案例是 GENE-26.5 放出了一段钢琴演奏的视频:

所以在灵巧操作里,底层控制远不只是工程细节。
如果控制层不够干净,模型训练会被执行误差污染。模型以为自己输出了一个动作,机器人实际做出来的是另一个动作。久了之后,模型学到的可能是硬件系统里的各种补丁,而不是人类动作背后的物理规律。
这也是为什么我觉得,未来具身智能里很重要的一层,可能会是 harness layer。
这里的 harness,可以理解成模型和真实机器人之间的一整套承接系统。它包括低延迟控制、动作平滑、实时通信、执行反馈、状态估计,也包括让模型输出真正落地的那些中间层。
语言模型时代,很多能力可以停留在 token 上。但机器人必须把意图变成力、位置、速度和接触,停在 token 层面没有意义。
当然,这里也要留一点技术归因的空间。GENE-26.5 的 Demo 不能简单理解成「模型赢了」或者「控制赢了」。
所以有业内人士提醒道,如果底层平台本身就是成熟的谐波减速器机械臂,那最终效果就不能全部归因到自研 control。
另外,X 上也有不少人质疑,这次放出来的 demo 里存在较多 cut 部分,有些任务到底是不是连续完成,外部其实很难判断。
这类质疑并不奇怪。
机器人 Demo 一直很难做技术归因:模型、手、机械臂、控制栈、任务数据、拍摄选择,都会影响最后呈现出来的效果。
所以这也提醒我们,机器人 Demo 不能被当成严格 benchmark 来看,与现实落地之间仍然有相当大的距离。
GENE-26.5 的输入不是单一模态。它要接收语言、视觉、本体感知、触觉,还要输出动作轨迹。官方提到,它用 Flow Matching 建模轨迹的联合分布。
直观理解就是,机器人模型处理的东西比文本模型麻烦很多。文字输出错了,可以撤回。图像生成幻觉大了,可以重来。机器人手伸出去之后,物体可能已经掉了,液体可能已经洒了,刀也可能已经碰到不该碰的位置。
所以机器人原生模型要面对一个更难的闭环。
它不能一次性回答完问题就结束。动作会改变环境,模型还要根据新的环境状态继续调整。
这次被注意到的,还有 Genesis World 这个仿真平台。
这个平台面向 Robotics、Embodied AI 和 Physical AI,可以处理刚体、液体、气体、可变形物体、薄壳、颗粒材料等不同物理现象。
官方博客里提到,它们做 closed-loop evaluation 时,一个数据点就对应 200 个评估设置和超过 150 小时机器人执行时间。如果放到真实世界里,整张图需要大量人机时间。
把以上这些内容连起来看,GENE-26.5 的重点就清楚很多了。
它展示了一条可能的具身智能 scaling path:
先利用人类操作数据进行预训练,再通过接近人类的硬件尝试减少迁移损耗,底层控制旨在让模型意图更稳定地落地,模型输入多模态监督,仿真和真实反馈被用来辅助迭代。
整体上,这套系统可被视作「具身智能版 Harness + 模型」的全栈组合。
如果这条链路能够顺利运作,机器人基础模型的竞争逻辑可能会发生一定变化。
未来同场竞赛的重点将主要集中在数据的自然性、硬件对人类动作的表达能力、控制层延迟以及仿真评估的可信度上。
任何一层出现领先,后续迭代的节奏也可能因此加快。
🚥
整体来看,Gene-26.5 此次发布,可以被视作对行业现状的一种观察:
模型可以越做越大,但手的自由度表达不了动作,很多能力就出不来。控制层延迟太高,模型落到真机上就会抖。评估不能规模化,下一版模型到底进步了多少也说不清。
之后的具身智能可能会越来越像一个飞轮,人类数据、类人硬件、控制系统、仿真评估、真实世界反馈。
这些「具身智能版 Harness + 模型」是下一个赛点,也是整个系统的底层要素。

文章来自于"十字路口Crossing",作者 "GaKi"。



