# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你可能觉得今年人形机器人的 demo 已经看麻了。但 Ted Xiao 说,哪怕是最粗糙的那一条,放在两年前都能让全场研究者惊掉下巴,因为那时候没人相信这事真能成。
Ted Xiao 曾任 Google DeepMind Staff Research Scientist 及技术负责人,一待就是 8 年,参与了 RT-1、RT-2、SayCan 以及 Open X-Embodiment 等具有行业定义意义的机器人基础模型项目。如今,他已加入由亚马逊创始人杰夫・贝佐斯亲自掌舵的新型 AI 初创公司 —— Project Prometheus,致力于突破具身智能在大规模环境下的推理与控制难题。
在最近的一次访谈中(来自 RoboPapers),Ted Xiao 以亲历者视角,系统回顾了过去近十年来具身智能领域的变革,复盘了每个关键决策背后的思考过程 —— 那些在论文里看不到的犹豫、转折与顿悟时刻。
视频链接:http://youtube.com/watch?v=etPqBphTgmE&t=1101s
这篇文章整理了 Ted 讲的机器人学习三个时代:存在性证明时代、基础模型时代、Scaling 时代。
Ted 会告诉你,为什么他们团队曾经陷入「Code Yellowish」状态,一年半不发论文,只闷头收集数据;在强化学习被寄予厚望的时期,为什么他们会大胆推进当时不被看好的模仿学习;以及为什么把视觉语言模型直接当机器人策略骨架的 VLA 路线,他们本可以早至少一年动手,却硬是晚了一步?

如果你关心 AI,关心机器人,或者只是好奇「这波浪潮是怎么起来并持续演进的」,这个故事值得细读。
2015、2016 年,DQN(Deep Q-Networks)和 AlphaGo 相继问世,证明了端到端数据驱动方法的惊人普适性。与此同时,机器人硬件其实早已成熟 —— 斯坦福几十年前的双臂移动操作系统已能完成各种家务,瓶颈始终是背后那个必须介入的人类智能。
于是一个听起来很疯狂的问题出现了:将强化学习等数据驱动方法直接应用于真实机器人系统,会发生什么?
Ted 就是被这个问题吸引进来的。他加入了当时不到 20 人的 Google Brain 机器人团队,做一件听起来很枯燥的事:把一批 KUKA 机械臂摆进房间,让它们 24 小时不间断抓取物体,跑在线强化学习。
这件事的难点,比想象中要大得多。
Atari 和 Go 的成功,依赖于清晰离散的动作空间 —— 游戏手柄上那几个按键,棋盘上有限的落子位置。而真实机械臂面对的,是一个高维、连续的动作空间:六七个关节的角度、末端执行器的位姿、夹爪的力度…… 加上从摄像头以较高频率传入的图像观测,无论是状态空间还是动作空间的维度,都远超游戏场景。直接套用为 Atari 设计的 value-based RL 方法,是行不通的。
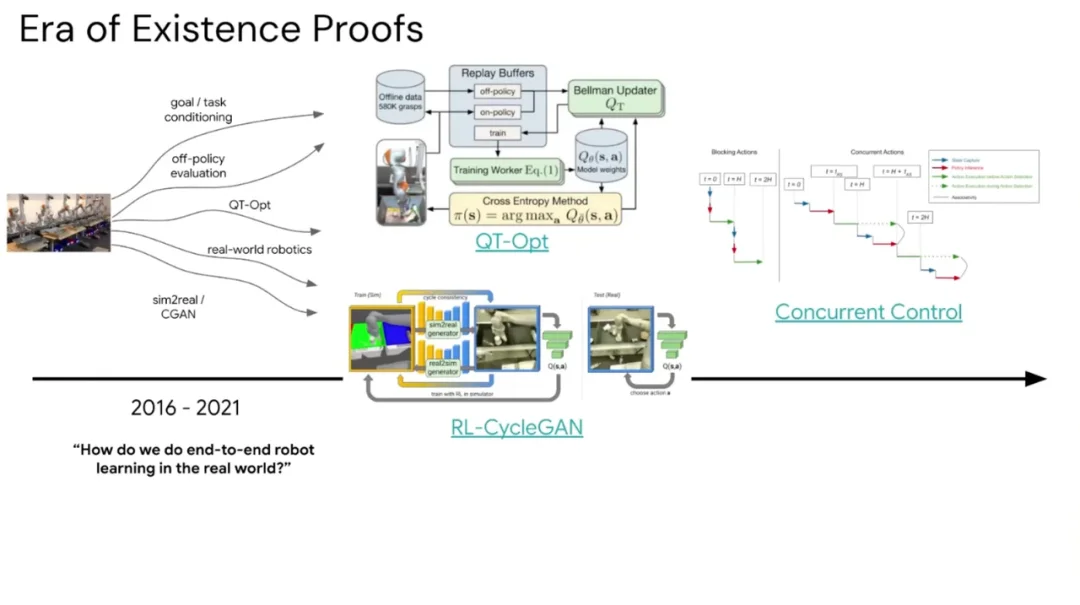
团队提出的解法是 QT-Opt—— 用交叉熵方法(CEM)来近似求解 Bellman 更新中的 Q 值最大化问题,从而处理机器人连续动作空间。QT-Opt 不仅仅是算法创新,还需要构建一整套系统:24 小时运行的机械臂农场(arm farm)、评估系统、控制栈等。例如,他们实现了「并发 RL」(concurrent RL),让机器人在执行动作的同时进行推理,而不是「停顿 - 观察 - 推理 - 执行」的串行模式。为了缩小仿真与真实环境的域差异,他们训练了 CycleGAN 将仿真图像转换为逼真的真实风格图像,使策略能在仿真中训练后较好地迁移到真实世界。
这套「机械臂农场」系统最终证明了一件事:端到端机器人学习在真实世界里不是玩具,它能 work。
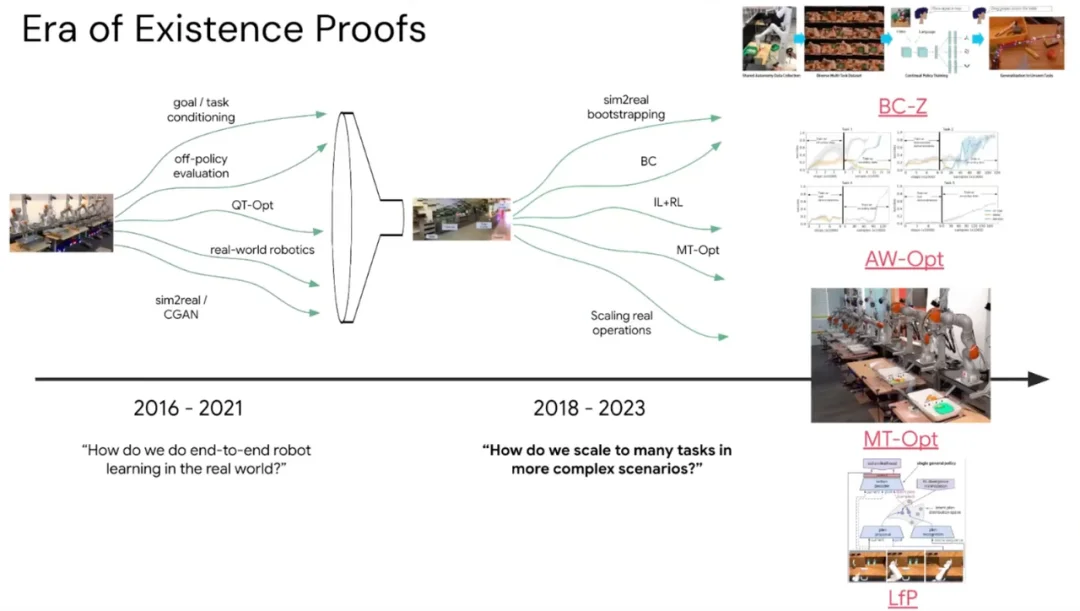
抓取跑通之后,下一个问题自然来了:能不能同时学会多个任务?
这一时期团队展开了一批方向各异的探索:
BC-Z 是其中一项代表工作 —— 第一个大规模、多任务、语言条件化的模仿学习策略。
MT-OPT 则是 QT-Opt 的多任务扩展,尝试把大量技能压缩进同一套神经网络权重里,探索一个网络能否同时「记住」多种行为。
另一条更有野心的路线是 Learning from Play。它的出发点是:能不能让人类随心所欲地操作机器人,不设定明确目标,只是「玩」—— 然后用 Hindsight Experience Relabeling 从这些无结构的轨迹中提取有意义的经验?Ted 形容这个方向在当时非常好玩。
探索越多,一个问题变得越来越清晰:强化学习这条路正在遭遇收益递减。
Ted 展示了一张学习曲线图:RL 线确实在往右上爬,但背后是整个分布式系统的运维噩梦 —— 一部分数据来自仿真,一部分来自真实机器人,策略 checkpoint 会过期,控制器代码一旦改了某个 bug,之前采的数据就可能报废。「RL is Painful」。与此同时,模仿学习虽然开箱即用,但准确率始终卡在 60%、70%、80%,死活上不去。
两条路都不对劲。团队进入了一种被称为「Code Yellowish」的状态 —— 不是危及存亡的 Code Red,而是「研究方向出问题了,得停下来还研究债」。
于是,团队做了一个在当时看来极其反主流的决定:停掉所有论文发表,花一年半时间,什么都不做,只攒数据。 他们雇了近 10 名专业操作员,用远程操控(teleop)方式,在微型厨房环境里收集了几百种不同任务的高质量专家演示,最终攒下约 87,000 条轨迹。这在今天看来或许规模不大,但在当时是一个孤注一掷的赌注 —— 赌的是「离线高质量数据 + 监督学习」这条被整个领域视为「第一章玩具」的路,能不能在真实机器人上 scale。
之所以说反主流,是因为当时的学术信仰很明确。Ted 回忆,2016 年伯克利的第一门机器人学习课上,老师首先讲 BC,然后就是「为什么 BC 不行」——compounding errors、分布偏移,结论是:BC 只能解决玩具问题, 其余都得靠 RL。这种「BC 到 70%,RL 才能带你到 90%」的信念,几乎就是当时的铁律。
但就在那段「Code Yellowish」的沉寂期里,团队的一位基础设施大神 Yao Lu 把整个训练器从底层重写了一遍。重写之后,BC 突然不再撞墙了 —— 它从 80% 的天花板一路冲到 90%、95%,而且随着真实世界数据的增加,还在继续提升。
那一刻,数据说话了。大规模模仿学习不仅能 work,而且就是他们要的那张「配方」(recipe)。 团队由此退出 Code Yellowish,带着信心把 teleop 数据规模再推一个数量级,目标是在微型厨房里解决数千种任务。
这个阶段可以被总结为「slowing down to speed up」:放慢发 paper 的速度,还清技术债,反而为后面的爆发攒下了最稀缺的资产 —— 不是某个算法,而是高质量、可 scale 的真实机器人数据。
至此,第一个时代「存在性证明」完成了它的使命。它证明了端到端学习在真实机械臂上能跑通,也证明了数据才是当时的真正瓶颈。这个认知,直接把机器人学习推进了下一个时代:基础模型时代。
2022 年前后,机器人学习领域遭遇了一场来自外部的「完美风暴」—— 大语言模型和视觉语言模型开始展现出真正的通用性与涌现能力。对机器人研究者而言,这是一类「外星技术」—— 前所未有,但显然可以利用。
与此同时,机器人学习本身也正在完成一次范式迁移:从在线强化学习(机器人边运行边积累经验)转向离线大规模模仿学习(人类示范 → 监督学习)。这两个趋势的叠加,创造了将基础模型引入机器人领域的历史性窗口。
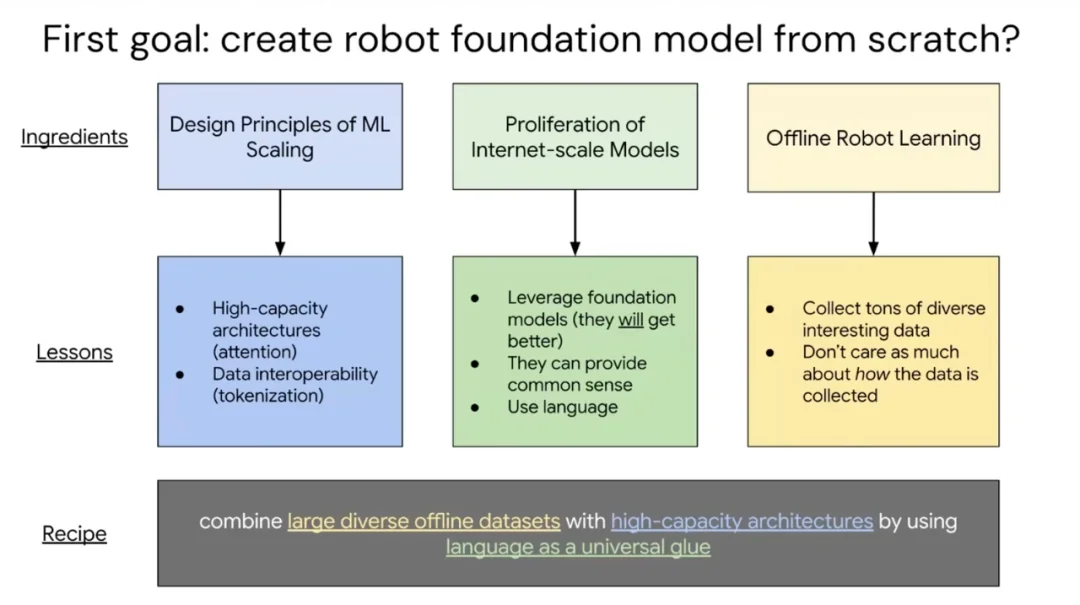
率先发布的工作是 SayCan—— 语言模型与机器人的第一次正式「握手」。
核心思路是将语言模型用作规划器:给定一个指令(比如「把苹果放到桌上」),语言模型负责生成合理的高层计划,而机器人则通过一个习得的价值函数来评估哪些子步骤在当前环境下实际可行。两者的输出相互加权:语言模型提供常识推理,价值函数提供落地约束,最终产出「既合理又可执行」的行动计划。
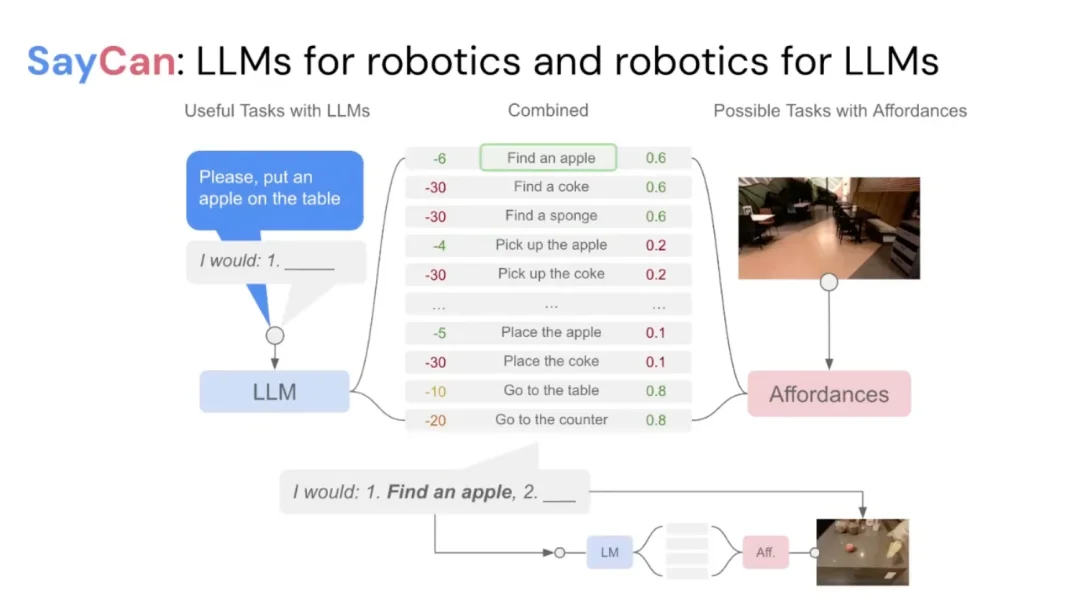
这篇论文在时机上堪称绝佳 —— 它在 ChatGPT 发布前几个月内落地,正逢 LLM 热潮席卷公众视野。SayCan 演示视频(由团队成员 Fei Xia 亲自拍摄)精良,整个办公室把它打印出来贴在墙上。这是第一个信号:基础模型或许真的能为机器人带来质变。
如果说 SayCan 是「用语言模型辅助机器人」,RT-1 则是迈出了更大的一步:让机器人策略本身也变成一个 Transformer。
设计逻辑简洁而激进 —— 将语言指令和图像观测全部 tokne 化,输出同样是离散化的机器人动作词元,整个系统以 3Hz 频率运行,参数量约为 5000 万。在这 8.7 万条轨迹(覆盖约 500 种任务)的数据集上训练后,RT-1 轻松超越了此前所有基于 ResNet-18 的行为克隆基线。
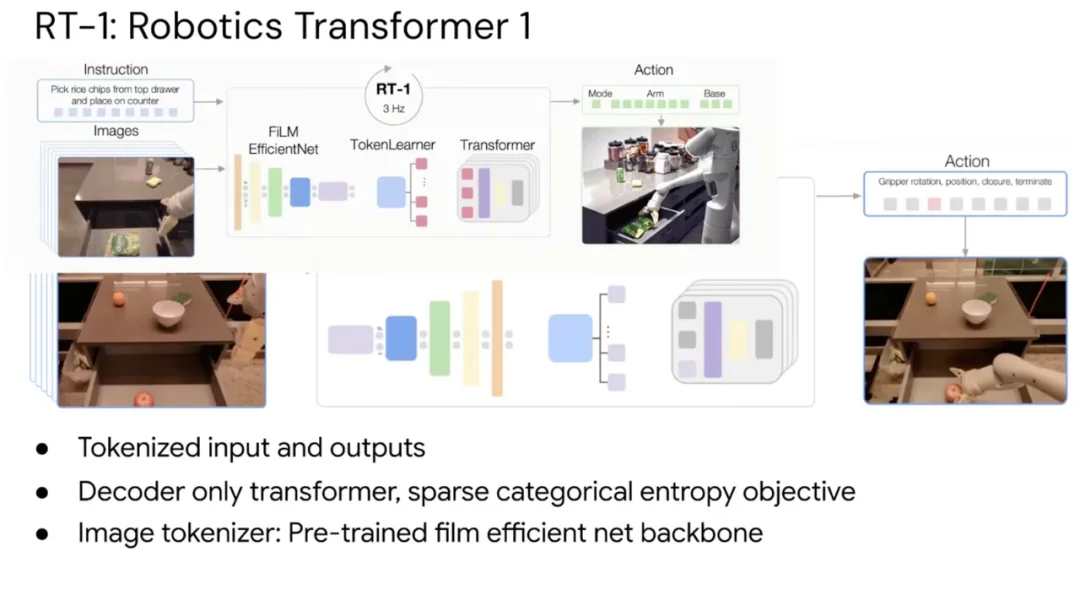
RT-1 的意义不仅是性能,更是一套可复用的研究基础设施:有了这个稳定的起点,后续的新想法可以快速接入、快速验证。
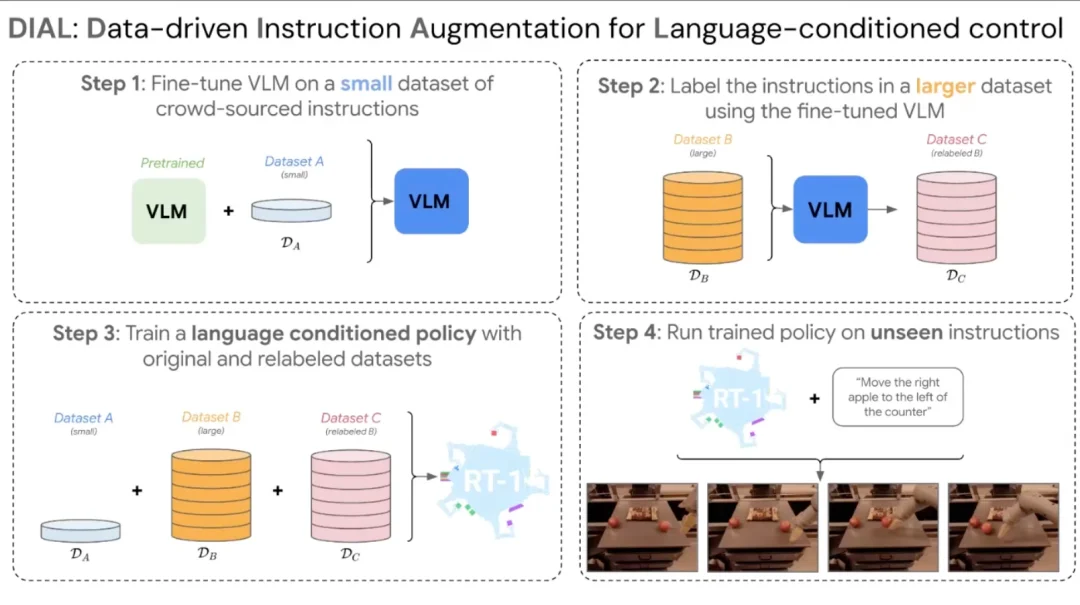
既然 VLM 可以用来规划,那能不能用来造数据?团队接下来做了 DIAL:用视觉语言模型给那八万七千条轨迹重新打标签,把几百个任务的语言描述扩展到数百万条,让模型在语言泛化上更进一步。这有点像当年 hindsight relabeling 的思路,只不过这次是在语言空间里做。
将语言模型用作规划器,或用作数据标注工具,这只是外围的整合。更激进的问题是:能否直接把视觉语言模型当作策略骨干本身?
这正是 RT-2(视觉 - 语言 - 动作模型,VLA) 所做的事。研究团队将机器人动作预测重构为视觉问答(VQA)任务,将 VLM 从外部工具变成核心引擎,训练了从 5B 到 55B 参数规模的一系列模型。结果是惊人的:相比 RT-1,涌现出大量此前从未见过的推理能力和泛化行为。

回头来看,这一跳跃本可以更早发生。Ted Xiao 坦承,在 RT-1 阶段,大量精力花在了从零搭建各种模块(视觉编码器、token 压缩、条件注意力……)上,而 RT-2 的逻辑其实是相反的 —— 直接信任 VLM,做最小化的适配。这种「全部拿来,最小改动」的思路,可能本可提前一年付诸实施。
尝到规模化的甜头之后,团队开始思考更激进的扩展方向:数据不仅可以跨任务,能不能跨机器人形态?
Open X-Embodiment 项目联合了全球 34 家研究机构,将各自收集的机器人数据整合进统一格式并开源。训练结果表明,在一种机器人上习得的技能,确实可以迁移到另一种机器人上 —— 尤其是那些与语言描述相关的行为(「推到旁边」、「放入容器」……)。这是跨本体泛化的早期存在性证明。

有了 RT1 和 RT2 这样的基座,后续研究像搭积木一样快。团队很快尝试了各种动作表征:边界框、分割掩码、思维链、affordance、第一人称姿态追踪…… 以前需要从零造轮子的算法探索,现在可以基于一个扎实基线快速迭代。Ted 说,这就是「临界质量」的魔力 —— 一旦起点足够好,新想法的验证速度会指数级加快。基础模型的时代,本质上是用外部的智能放大器,解了机器人学里「从零造一切」的困局。
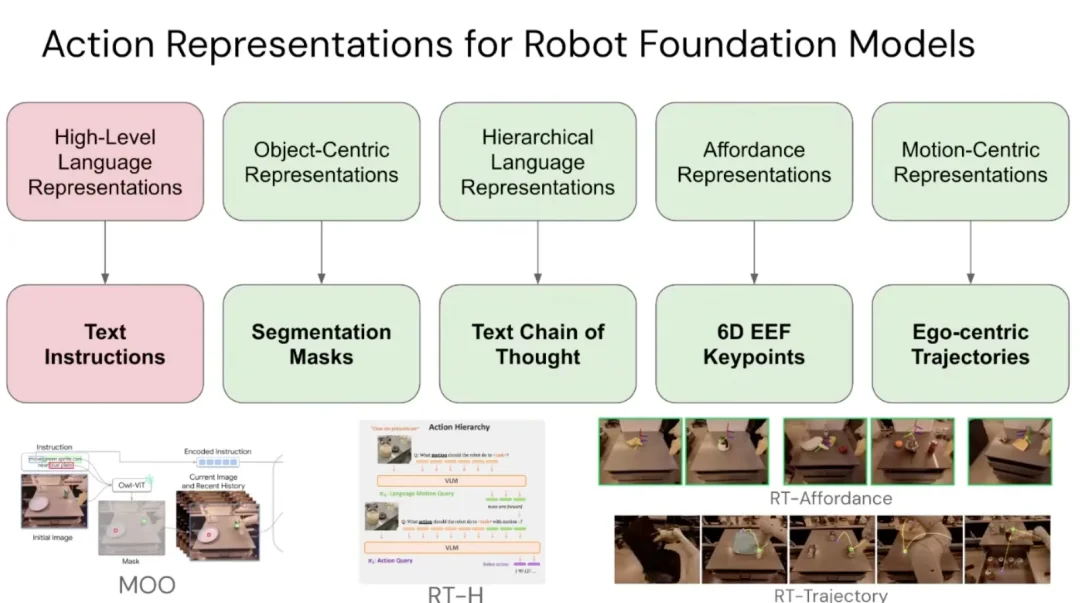
从 8.7 万条人工示范轨迹,到 VLA 的涌现推理,再到跨形态的知识迁移 —— 基础模型时代的核心洞见,是停止把机器人当作一个孤立系统来精心调教,而是开始借用语言与视觉领域一切可用的智识积累,以最小的代价将其对接到物理世界。
这个时代留下的问题,正是下一个时代 —— 规模化时代 —— 试图回答的:当数据和模型都足够大,机器人能学到什么?
进入第三个时代,导火索是 VLA 证明了这条路能走通,但天花板还远。于是世界开始超大规模 Scaling—— 参数、数据、本体复杂度,同时爆发。
Ted 把这一阶段称为 Scaling。如果说上一个时代是借别人的智能放大器,这个时代就是往各个维度疯狂加码,直到涌现出新东西。
这一时代,DeepMind 的第一个标志性工作是 2025 年 3 月发布的 Gemini Robotics。从 RT-2 到 Gemini Robotics,中间隔了一年半,但外部生态已经天翻地覆。Physical Intelligence、Generalist AI 等创业公司成立,资本涌入,所有人都意识到:VLA 是范式,现在该拼的是谁能把它 scale 到物理极限。
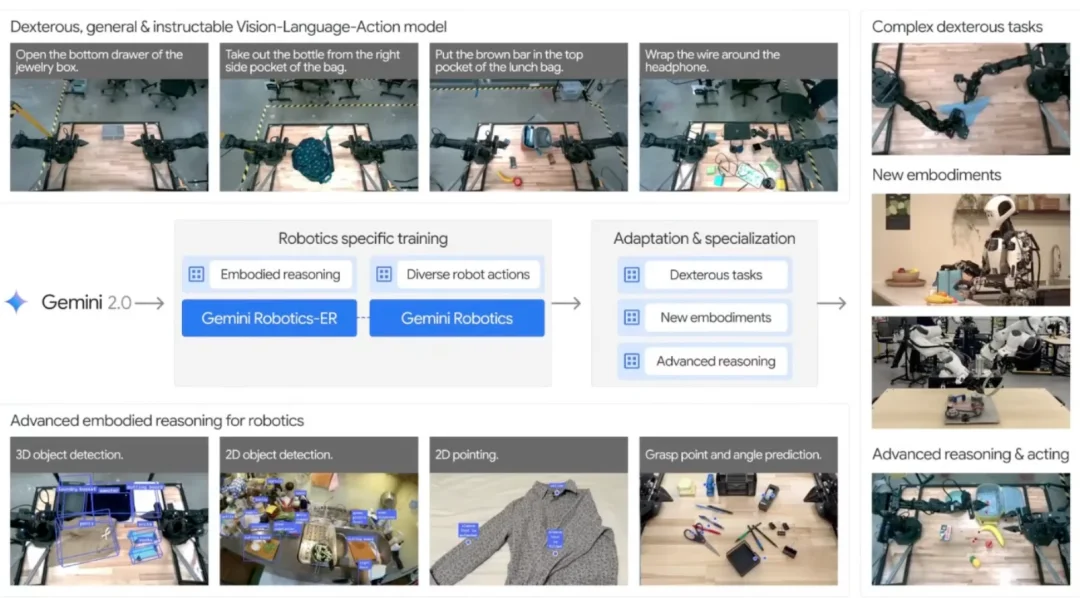
硬件端首先变了。斯坦福的 ALOHA 平台带来了关键洞察:真正高频、高质量的数据,才能解锁灵巧操作的极限。 双臂系统、高频率控制、直觉式遥操作,能做到以前单臂移动平台根本想象不到的动作。Google DeepMind 团队很快拥抱了更复杂的本体 —— 从 ALOHA 到人形机器人,动作空间的复杂度远超当年的 Kuka。
Gemini Robotics 的主干直接 fork 自 Gemini 2.0。Ted 评价,Gemini 在多模态理解上一直很强,而机器人团队这次拿到的数据量,已经远超当年一年半攒下的八万七千条轨迹。规模一上来,第一件事就是突破 RT-2 的「黑箱」思路。
RT-2 时代,团队把 VLM 当黑箱搬进来,没有细看内部。但 Gemini Robotics 团队有机会直接看「香肠厂里面是怎么做的」—— 他们发现,外界抱怨 VLM 缺乏物理常识、空间推理、时间推理,这些问题在 Gemini 内部是可以被定向解决的。
于是有了 Gemini Robotics ER(Embodied Reasoning)。这不是一个机器人策略,而是一个被专门增强过具身推理能力的 VLM:它能做 3D 物体检测、2D 指向、预测抓取角度。先把视觉语言模型的具身推理能力补齐,再把它喂给下游的 VLA 策略,机器人的泛化性和灵巧度自然上了一个台阶。
随后发布的 Gemini Robotics 1.5 则将推理时代的红利引入具身智能。彼时,DeepSeek R1、OpenAI o1等模型已让业界意识到:在推理阶段引入「思考」过程,能够显著提升语言模型的表现。Gemini Robotics 1.5 将这一范式移植到机器人领域:策略在执行前先用自然语言「想一想」,将长时域任务分解为短时域指令,再逐步执行。
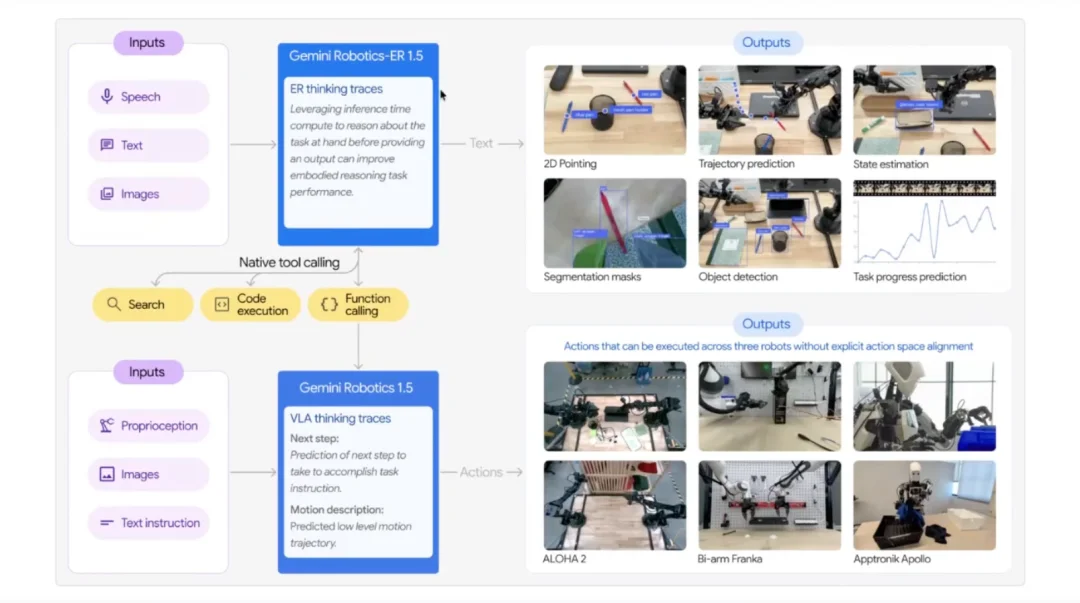
更值得关注的是动作迁移(Motion Transfer) 能力:同一个神经网络,可以将在某种机器人上采集的运动经验,零样本迁移到运动学截然不同的其他平台 —— 包括仿人机器人、Franka 机械臂和 Aloha 双臂系统。这与早期「跨具身训练」时代将多个形态相近的单臂机器人数据合并训练,已是本质上的不同。
Scaling 时代并非单一方向的线性推进,而是多个维度并行爆发。

模型性能维度,以 Pi 0.6 为代表的后训练(Post-training)范式逐渐成形:先训练一个泛化能力强的通用策略,再针对长时域、高精度任务进行专项微调。
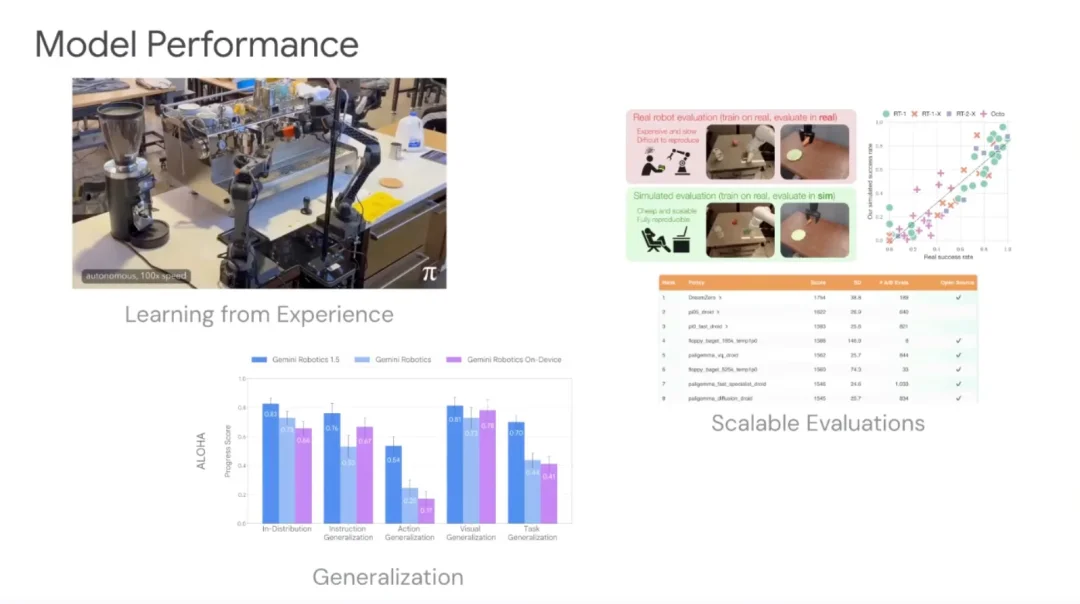
评估体系维度,随着模型声称的能力日益宽泛,评估本身成为一大挑战。当前涌现出多种解法:基于仿真的 Sim-to-Real 评估、以 RoboArena 为代表的分布式跨机构评估,以及利用世界模型进行策略验证的方法。
数据维度,Generalist AI 放出五十万小时交互数据做预训练,第一人称人类数据(egocentric)成了「当红炸子鸡」,NVIDIA、Pi 、Georgia Tech 都在卷。这些工作表明:大规模采集人类第一视角操作数据,并设计能够消化此类数据的训练方法,是突破机器人数据瓶颈的重要路径。

商业化与数据飞轮维度,特斯拉式的闭环逻辑开始在机器人领域隐现:当机器人真正部署到真实场景,数据采集的成本由服务价值本身来摊薄,长尾罕见场景的数据也随之自然积累。
Ted 认为,这个时代最迷人的不是某个单一突破,而是研究熵的暴涨。社区不再挤在一条漏斗里,而是多路并进:
尽管今天大多数讨论集中在操控(Manipulation),运动控制(Locomotion)领域同样经历了一场静悄悄的革命。会跳舞、能后空翻的机器人已近乎「商品化」,背后是一套与操控截然不同的方法论:零样本 Sim-to-Real 迁移 + 在线强化学习 + 小型网络。
这一对比催生了一个深刻的隐喻:操控更像是大脑皮层的工作 —— 需要示例学习、专家数据、监督信号;而运动控制更像是小脑或脊髓的工作 —— 反射性的、本能的。如何将两者融合,进而与长时域推理能力三者合一,是当前机器人学习领域最核心的开放问题之一。
访谈最后,主持人问:机器人的 ChatGPT 时刻什么时候来?
Ted 把它拆成两半。产品层面,它不会是一个 demo,而是一个真正通用、消费级的操作系统,像当年的 ChatGPT 一样,让普通人觉得「好用、惊喜、离不开」。他认为这可能在一两年内发生,也可能需要更久 —— 更像自动驾驶从爆发到落地的那十年。
技术层面,没有单一突破,而是多个拼图同时到位:架构、视频动作模型、高级全身反应系统、后训练、数据飞轮。Ted 的个人赌注押在视频动作模型和第一人称人类数据上。
更多内容请参见原视频。
文章来自于"机器之心",作者 "机器之心编辑部"。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
