# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
机器人拉个拉链,到底需不需要“脑子”?
过去几年,从OpenVLA到π0、π0.5,具身大模型已经能让机器人把指令和动作连得有模有样。
但一旦包的位置挪了几厘米,或者光照暗了一点,它们往往就会“大脑宕机”。
究其原因,是因为这些机器人大多在玩“连连看”:看到观察结果,直接输出动作。
它们只是记住了轨迹,却并不理解背后的物理逻辑。
现在,一种让机器人“先想明白,再稳定行动”的新范式来了。
由至简动力、北大、港中文联合提出的LaST-R1,首次将隐空间物理推理塞进了强化学习的闭环。
同时,LaST-R1作为LaST₀基座模型的物理世界后训练范式,LaST₀首创面向机器人的隐空间物理思维链推理,并已中稿ICML2026 Spotlight(top 2.2%)。

它的表现有多夸张?
这个让机器人长出“物理脑”的LaST-R1,到底是怎么炼成的?
那个让环境反馈同时优化“怎么想”和“怎么动”的LAPO算法又藏着什么玄机?
我们顺着这篇论文,深挖了一下这套能让机器人“深思熟虑”的后训练黑科技。
尽管从OpenVLA到π0.5,具身大模型已经完成了图像、语言与动作的初步对齐。
但在实际落地中,工业界发现了一个致命的“幻觉”:
能模仿,不等于能在物理世界泛化。
这就导致了极差的泛化性。
打个比方,机器人可能记住了100种拉拉链的轨迹,但只要拉链的角度偏转15度,或者光照发生变化,单纯靠“观察→动作”的端到端映射就会失效。
核心问题在于,现有的VLA模型缺少一个“思考”的中间层——即让机器人在行动之前,对物理世界进行推理。
过去,学术界也曾尝试引入思维链(CoT)来解决推理问题。
但对于机器人操作而言,语言推理往往太慢且颗粒度太粗,你很难用文字精准描述“拉链咬合时的细微阻力反馈”。
LaST-R1的核心突破,就是放弃了低效的语言CoT,转而在隐空间(Latent Space)中构建物理推理链。
它不再让机器人看到图像就“闭眼”出动作,而是先在隐性空间里建模场景的结构、物体的物理关系以及未来的动态变化。
然而,要让机器人学会这种“思考”,仅靠静态的模仿学习(SFT)是不够的。
目前的强化学习(RL)方法大多像是一个只看结果的严厉教练:它只告诉机器人动作成没成功(优化Action Space),却无法指导机器人“刚才那下你是怎么想的”。
针对这一痛点,该团队提出的LAPO(Latent-to-Action Policy Optimization)算法,正式将“思考过程”拉进了强化学习的优化闭环。
它让环境反馈不仅优化动作,也优化机器人行动前的“物理思考”。
近日,至简动力、香港中文大学、北京大学计算机学院多媒体信息处理国家重点实验室,提出了一种面向机器人操作的自适应物理隐空间推理强化学习框架——
LaST-R1(Reinforcing Robotic Manipulation via Adaptive Physical Latent Reasoning)。
它希望通过强化学习后训练,让具身大模型不仅学会生成动作,也学会在行动前,进行面向物理世界的隐空间推理。
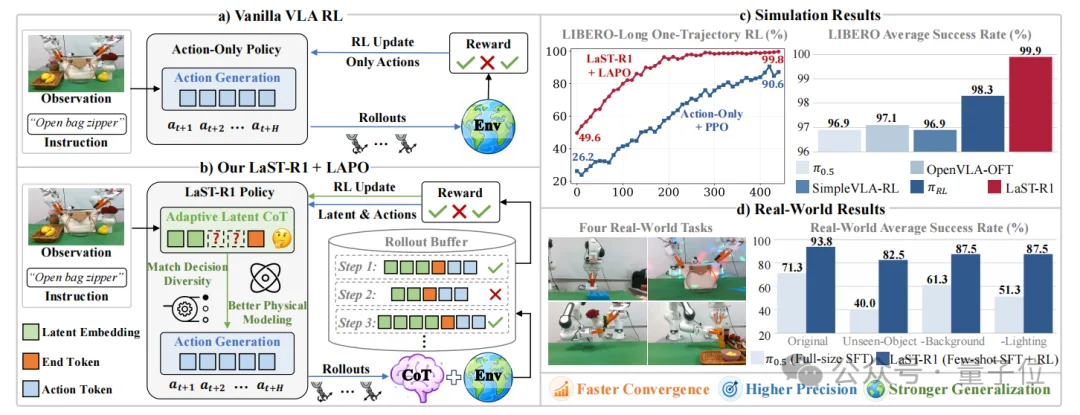
△LaST-R1 概览。
(a) 不同于仅严格优化动作的 vanilla RL 基线方法,
(b) 我们的方法利用 LAPO 联合优化自适应 latent CoT 与物理执行过程。通过连接认知推理与控制,LaST-R1 实现了
(c) 更快的收敛速度、更高的仿真成功率,
以及 (d) 更强的真实世界泛化能力。
与以往主要优化action space(动作空间,即机器人所有可执行指令的集合)的具身大模型RL不同,LaST-R1的核心思想是:
机器人不应只从图像和指令直接预测下一步动作,而应先在latent space(隐空间,可以理解为机器人大脑里的“隐性认知层”)中理解场景结构、物体关系和物理动态,再生成更稳定、精准的动作。
换句话说:
LaST-R1不只优化机器人的“手”,也优化它的“脑”。
具体来看,LaST-R1构建了一个面向latent reasoning-before-acting策略的强化学习后训练框架,核心由三步组成:
LaST-R1改变的是具身大模型后训练的优化对象:从只优化动作,转向同时优化动作背后的物理推理。
研究团队在仿真和真机环境中都进行了系统验证。
在仿真LIBERO benchmark上,LaST-R1仅依赖1条轨迹完成warm-up,随后通过在线RL优化,最终取得99.9%平均成功率,并相比Action-Only+PPO展现出更快收敛和更高最终性能。
在真机部署中,LaST-R1仅使用30条轨迹warm-up,再通过RL后训练将平均成功率从52.5%提升到93.75%,显著超过使用100条专家轨迹的π0.5(71.25%)。
更重要的是,在真实扰动条件下,LaST-R1仍保持较小性能下降,说明其学习到的不是单一场景中的动作轨迹,而是更可迁移的空间语义和物理动态理解。
上述结果意味着,具身大模型强化学习的重点正在发生变化——
机器人不再只是通过RL学会更熟练地执行动作,而是开始通过RL学会更合理地进行物理推理。
LaST-R1的意义,在于它提出了一种新的具身大模型后训练范式,能够让环境反馈同时塑造机器人的“思考方式”和“行动方式”。
一旦隐空间推理从模仿学习的“静态脚本”进化为强化学习的“演进核心”,机器人便能摆脱对演示数据的刻板复现。
在不断的交互试错中,它们开始强化模型的物理推理。
这或许也是具身大模型从“会模仿”走向“会适应”的关键一步。
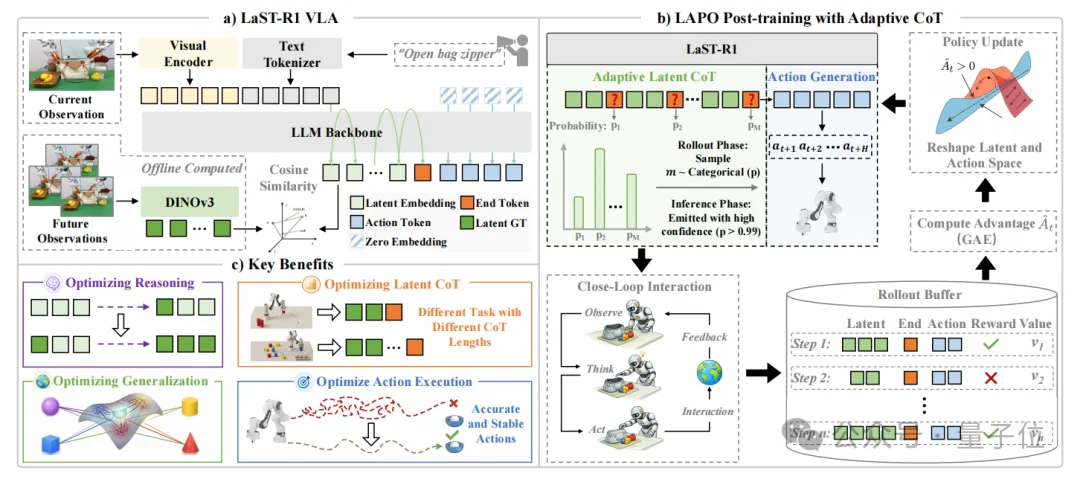
△LaST-R1 框架。
(a) LaST-R1 是一个统一模型,以视觉观测和语言指令作为输入,其中视觉基础模型提供具有物理语义约束的 latent targets,用于在动作生成前引导 latent CoT 推理。
(b) 在 LAPO 强化学习后训练过程中,LaST-R1 以闭环方式与环境交互,并将 latents、actions 和 rewards 存储到 rollout buffer 中,以联合重塑 latent space 与 action space。进一步地,模型通过基于预测概率学习生成 token,实现自适应推理,从而在不同任务中动态调整推理长度。
(c) 通过 LAPO,LaST-R1 能够在多样化任务中形成自适应推理长度,从而提升泛化能力与执行稳定性。
整个LaST-R1框架可以概括为三个关键阶段:先推理、再优化、动态决定想多久。
给定当前视觉观测和语言指令,LaST-R1不会直接生成动作,而是先生成一段隐空间推理嵌入(latent reasoning embeddings),作为行动前的“隐空间物理思考”,用于建模物体关系、未来状态和操作动态。
随后,模型再基于这些隐空间推理 (latent reasoning) 并行生成action tokens。
这一步解决的是:如何让动作生成建立在物理推理之上。
LaST-R1的核心算法是LAPO(隐空间到动作策略优化,Latent-to-Action Policy Optimization)。
传统具身大模型RL主要优化action,而LAPO将latent reasoning也纳入强化学习目标,让环境奖励同时塑造“怎么想”和“怎么动”。
论文中最关键的是latent-level ratio surrogate:
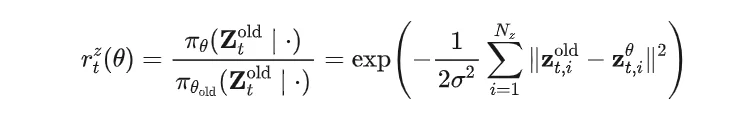

直观来说,如果某条轨迹成功,LaST-R1不仅会强化对应动作,也会强化动作之前产生的“好推理”。
随后,LAPO将latent和action放进统一的clipped objective中:
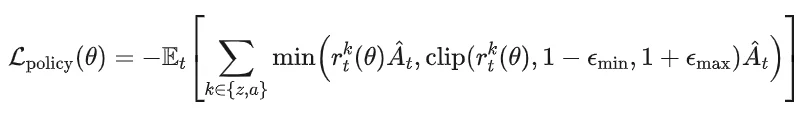

最终,总训练目标为:
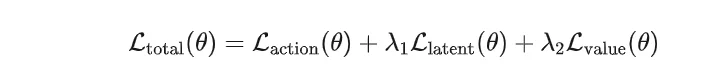
这意味着:LaST-R1的RL后训练不只是优化机器人的动作结果,也在优化行动前的物理推理过程。
不同任务需要不同的思考长度。
因此,LaST-R1引入Adaptive Latent CoT,通过token让模型动态决定何时结束latent reasoning并进入action generation。
这是为了让机器人根据任务难度自适应分配推理预算。
也就是说,LaST-R1不是让机器人每一步都固定想同样久,而是让它学会:简单状态快速执行,复杂状态多想一步。
为了优化这个结束标识符token的自适应生成,训练目标需要进一步加上L_end。
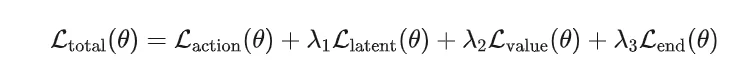
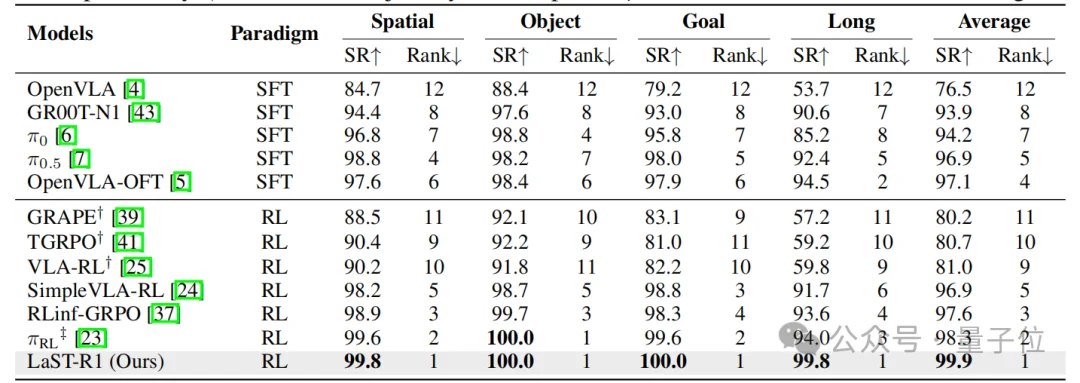
LaST-R1在LIBERO benchmark上进行系统评估,覆盖Spatial、Object、Goal 和Long四个任务套件。实验在one-shot SFT warm-up设置下进行,随后进入在线RL后训练。
结果显示,LaST-R1在四个suite上分别达到99.8%/100.0%/100.0%/99.8%,平均成功率达到99.9%,超过OpenVLA-OFT、π0.5、SimpleVLA-RL和πRL等强基线。
相比只优化动作空间的Action-Only + PPO,LaST-R1 + LAPO收敛更快、最终成功率更高,说明latent reasoning与action generation的联合优化能够为RL提供更稳定的“认知缓冲区”,从而提升复杂长程操作能力。

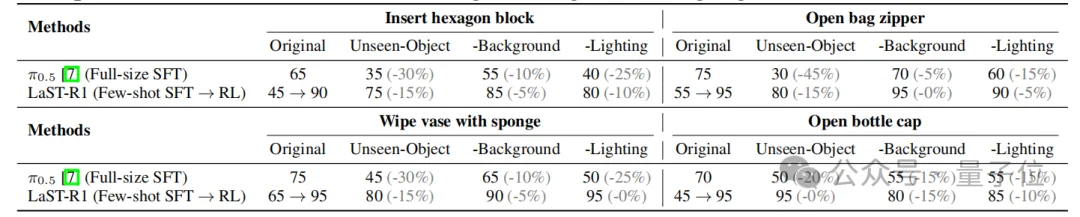
LaST-R1在四个真实操作任务上进行测试,覆盖单臂高精度插入、双臂协同、接触式擦拭和连续旋转等复杂物理交互。
为了突出RL后训练效果,论文将其与SOTA模型π0.5对比:π0.5使用100条专家轨迹进行SFT,而LaST-R1仅使用30条轨迹warm-up,并通过RL后训练继续优化。
结果显示,LaST-R1将真机平均成功率从warmup后的52.5%提升到93.75%,显著超过π0.5的71.25%,说明其优势不仅存在于仿真环境,也能迁移到真实物理交互中,并形成更稳定的执行策略。


在LIBERO OOD设置中,研究团队采用9个seen tasks进行在线RL,并保留1个held-out task做泛化测试。
结果显示,Action-Only + PPO容易出现性能停滞甚至退化,而LaST-R1 + LAPO能在OOD tasks上持续提升,说明latent reasoning能帮助模型学到更可迁移的空间语义和物理动态。

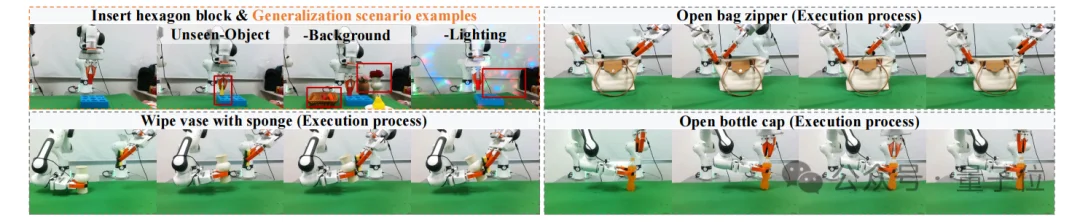
在真实世界中,论文进一步测试了unseen object、background variation和lighting condition三类扰动。
相比SFT π0.5,LaST-R1在这些变化下保持更小的性能下降,说明它并不是简单记住训练场景中的动作轨迹,而是形成了更鲁棒的物理推理与动作生成能力。

LaST-R1的意义,不只是把LIBERO平均成功率推到99.9%,也不只是让真机任务成功率提升到93.75%。
更重要的是,它提出了一种新的具身大模型后训练范式:强化学习不应该只优化机器人的动作,也应该优化动作背后的物理推理过程。
过去,我们更关心机器人能不能生成正确动作。
现在,LaST-R1在此基础上进一步追问:机器人能不能在行动前进行正确的物理推理?
通过LAPO,环境reward可以直接塑造latent reasoning space;
通过adaptive latent CoT,机器人可以根据任务难度动态调整思考长度。
这意味着,机器人不再只是复现演示数据中的动作轨迹,而是在交互中逐步强化模型的物理推理。
从这个角度看,LaST-R1让具身大模型强化学习从“看见就动”走向“先想明白,再稳定行动”。
当具身大模型开始学会在latent space中思考,机器人距离真正的自主操作,也许又近了一步。
论文链接: https://arxiv.org/abs/2604.28192
项目主页: https://siriyep.github.io/last-r1/
代码链接:https://github.com/CHEN-H01/LaST-R1
文章来自于"量子位",作者 "允中"。



