# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多Agent 系统里,经常会出现一个单 Agent 里从来不会出现的问题:一个子 Agent 刚写完数据,另一个子 Agent 立刻去读,结果是空的。
根本问题出在 Agent 的写-读模式撞上了很多数据库为单 Agent 场景设计的默认一致性配置。
接下来,这篇文章将说清楚这个矛盾从哪来,以及怎么用一行参数解决它。
单 Agent RAG 的工作方式是这样的:用户提出一个问题,Agent 把问题向量化,去 Milvus 检索 Top-K 文档片段,拼成 prompt 喂给模型,模型输出答案。整条链路里,向量数据库是默认只读的——数据在应用启动时、文档更新时已经写好了,推理过程中没有人再继续往里写东西。
但多 Agent 系统里有两类角色:Writer Agent负责执行任务、调用外部工具、发现新信息,把结果 embedding 后写入 Milvus 作为共享记忆;Reader Agent收到协调信号后,从 Milvus 检索最新记忆,基于这些上下文生成下一步行动。
两者是独立的进程或线程,通过消息、回调或事件协调。Writer 写完,立刻通知 Reader,这个间隔是毫秒级的。
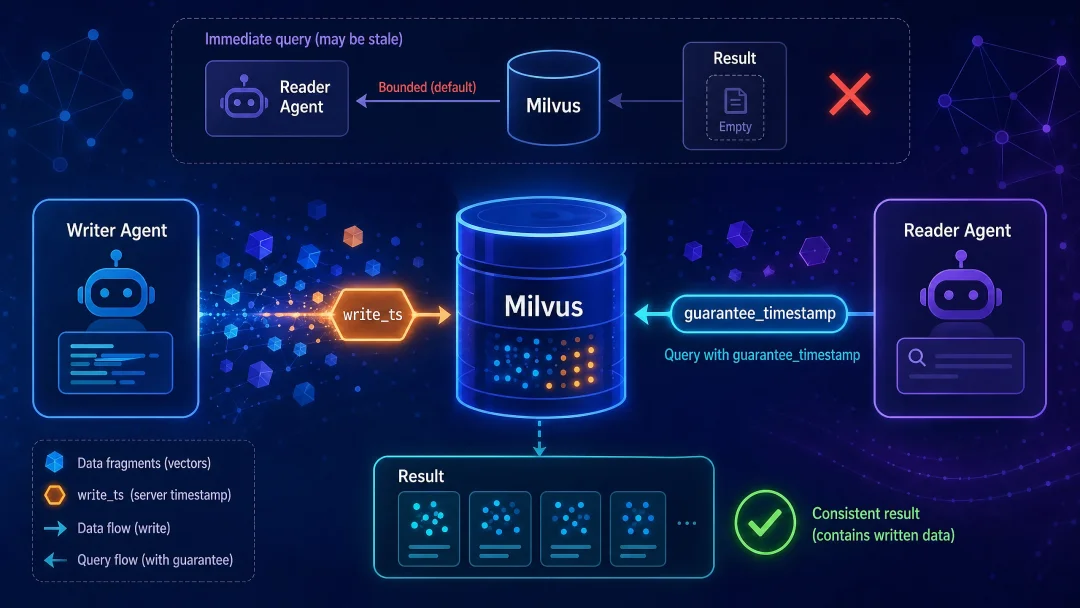
在这种情况下,Writer 写完、信号发出、Reader 立刻查,这种模式会导致Reader的查询动作,恰好落在“数据已写入但未对Query Node可见”的时间窗口内,最终返回空结果。
那么,这个时间窗口是怎么产生的,又要如何解决?
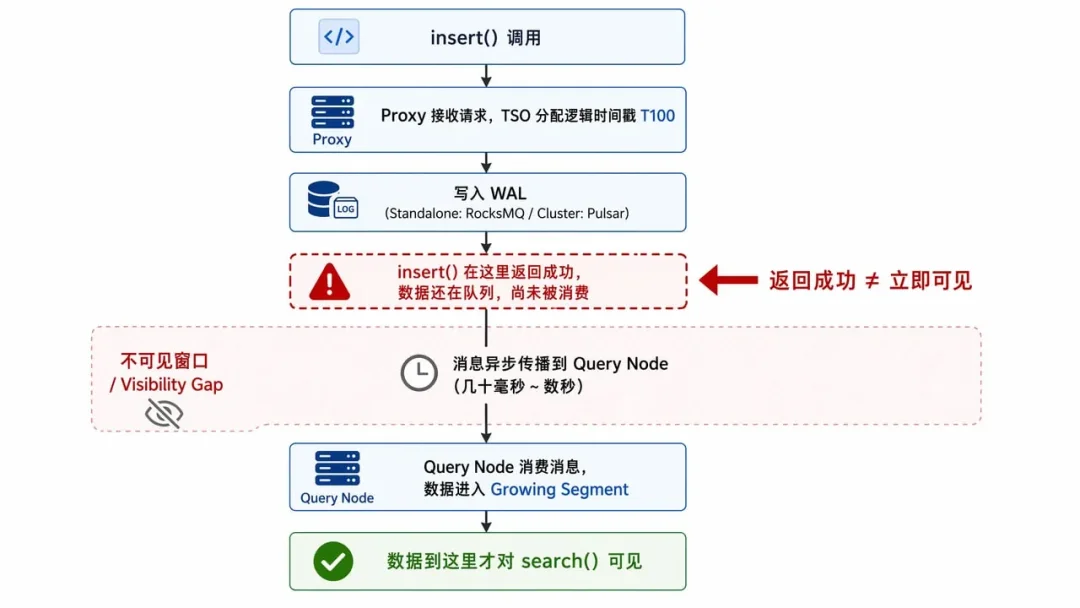
出现“写后读空”的关键,在于我们对Milvus的insert()操作存在一个认知误区——insert()返回成功,不代表数据已经可以被查询。
具体来说,Milvus 的写入流程分两段,insert()操作在第一阶段完成后就会返回“成功”,但数据此时只是被写入了消息队列(类似Kafka producer ack的语义)安全落盘,但消费者(Query Node)尚未处理,此时读取自然无法看到新数据。
如图所示,这个“写入成功到数据进入Growing Segment、查询可见”的几十毫秒到几秒的时间差,就是多Agent场景下读空问题的核心诱因。
要想解决这个问题,在Milvus中,我们可以通过guarantee_timestamp来控制数据的可见性:每次search()调用都携带上这个时间戳,Query Node执行查询前会先检查自己使用的数据版本是否追上了这个时间戳?没追上就等待,追上了再执行查询。
而我们在代码中设置的consistency_level(一致性级别),本质上就是在控制guarantee_timestamp的设定逻辑。
Milvus提供四档一致性选项,可在创建Collection时设置默认值,也可在每次search()调用时单独覆盖,不同级别对应不同的可见性、性能代价,具体如下:
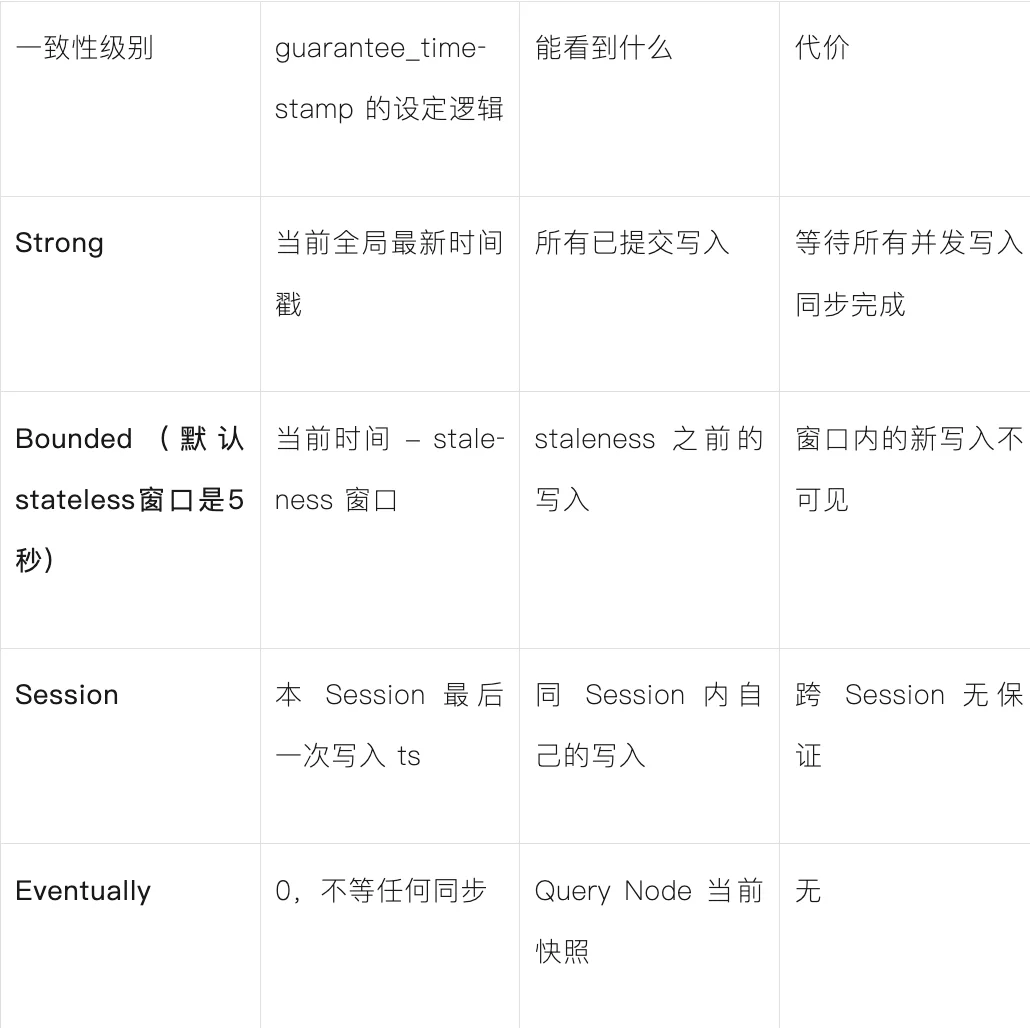
这里需要重点说明:Milvus创建Collection的默认一致性级别是Bounded,这对单Agent RAG场景是完全合理的——因为单Agent场景没有推理过程中的写入操作,Bounded的5秒窗口不会被触发,既能保证检索性能,又能满足需求,是性能与体验的双赢选择。
但对于Writer写完数据后Reader立即查询的多Agent事件驱动场景,此时查询的guarantee_timestamp如果仍落在Bounded的5秒窗口内,新写入的数据就会不可见,返回空结果。
而解决这个问题的关键,就是将consistency_level从默认的Bounded,切换到适配多Agent场景的strong级别。
为了直观验证上述结论,我们设计了一组实验:通过模拟生产环境的高写压,让Query Node始终处于数据追赶状态,再执行“写入一条数据后立即查询”的操作,对比Bounded和Strong两种一致性级别的查询结果。
实验设计思路
通过两个机制模拟生产环境的写压,确保Query Node始终处于忙碌的追赶状态:
每轮实验中,先写入一条带唯一标记(marker)的记录,然后立即分别用Bounded和Strong级别查询该记录——一旦出现Bounded=0、Strong=1,即判定问题复现成功。
运行前提:pymilvus >= 2.6.0 已安装,Milvus 服务可访问。
#!/usr/bin/env python3
import argparse
import itertools
import random
import threading
import time
import uuid
from contextlib import suppress
from pymilvus import DataType, MilvusClient
defmake_vector(seed, dim):
rng = random.Random(seed)
vec = [rng.uniform(-1.0, 1.0) for _ inrange(dim)]
norm = sum(x * x for x in vec) ** 0.5or1.0
return [x / norm for x in vec]
defmake_records(start_id, count, dim, marker, round_no):
return [
{
"id": start_id + i,
"vector": make_vector(start_id + i, dim),
"marker": marker,
"round": round_no,
}
for i inrange(count)
]
defcreate_collection(client, name, dim):
if client.has_collection(name):
client.drop_collection(name)
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=dim)
schema.add_field("marker", DataType.VARCHAR, max_length=128)
schema.add_field("round", DataType.INT64)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="AUTOINDEX",
metric_type="COSINE",
)
client.create_collection(
collection_name=name,
schema=schema,
index_params=index_params,
consistency_level="Bounded",
)
client.load_collection(name)
defsearch_marker(client, name, vector, marker, consistency, timeout):
result = client.search(
collection_name=name,
data=[vector],
anns_field="vector",
search_params={"metric_type": "COSINE"},
filter=f'marker == "{marker}"',
limit=1,
output_fields=["id", "marker", "round"],
consistency_level=consistency,
timeout=timeout,
)
hits = result[0] if result else []
returnlen(hits), hits
defwriter_storm(uri, name, dim, stop_event, id_counter, batch_size, sleep_seconds):
client = MilvusClient(uri=uri)
whilenot stop_event.is_set():
start_id = next(id_counter)
records = make_records(start_id, batch_size, dim, "storm", -1)
with suppress(Exception):
client.insert(collection_name=name, data=records)
if sleep_seconds > 0:
time.sleep(sleep_seconds)
defmain():
parser = argparse.ArgumentParser()
parser.add_argument("--uri", default="http://localhost:19530")
parser.add_argument("--collection", default="")
parser.add_argument("--dim", type=int, default=16)
parser.add_argument("--attempts", type=int, default=200)
parser.add_argument("--bounded-timeout", type=float, default=2.0)
parser.add_argument("--strong-timeout", type=float, default=30.0)
parser.add_argument("--storm-writers", type=int, default=2)
parser.add_argument("--storm-batch-size", type=int, default=2000)
parser.add_argument("--storm-sleep", type=float, default=0.0)
parser.add_argument("--preload", type=int, default=5000)
parser.add_argument("--keep", action="store_true")
args = parser.parse_args()
collection = args.collection orf"consistency_probe_{int(time.time())}_{uuid.uuid4().hex[:8]}"
writer = MilvusClient(uri=args.uri)
bounded_reader = MilvusClient(uri=args.uri)
strong_reader = MilvusClient(uri=args.uri)
stop_event = threading.Event()
storm_threads = []
storm_id_counter = itertools.count(10_000_000, args.storm_batch_size)
print(f"uri={args.uri}")
print(f"collection={collection}")
try:
create_collection(writer, collection, args.dim)
if args.preload > 0:
print(f"preload {args.preload} rows")
writer.insert(
collection_name=collection,
data=make_records(1_000_000, args.preload, args.dim, "preload", -2),
)
_, _ = search_marker(
strong_reader,
collection,
make_vector(1_000_000, args.dim),
"preload",
"Strong",
args.strong_timeout,
)
for _ inrange(args.storm_writers):
thread = threading.Thread(
target=writer_storm,
args=(
args.uri,
collection,
args.dim,
stop_event,
storm_id_counter,
args.storm_batch_size,
args.storm_sleep,
),
daemon=True,
)
thread.start()
storm_threads.append(thread)
for attempt inrange(args.attempts):
marker = f"probe_{attempt}_{uuid.uuid4().hex[:12]}"
record_id = attempt + 1
vector = make_vector(record_id, args.dim)
record = {
"id": record_id,
"vector": vector,
"marker": marker,
"round": attempt,
}
insert_start = time.perf_counter()
writer.insert(collection_name=collection, data=[record])
insert_ms = (time.perf_counter() - insert_start) * 1000
bounded_start = time.perf_counter()
bounded_count, bounded_hits = search_marker(
bounded_reader, collection, vector, marker,
"Bounded", args.bounded_timeout,
)
bounded_ms = (time.perf_counter() - bounded_start) * 1000
strong_start = time.perf_counter()
strong_count, strong_hits = search_marker(
strong_reader, collection, vector, marker,
"Strong", args.strong_timeout,
)
strong_ms = (time.perf_counter() - strong_start) * 1000
print(
f"attempt={attempt:03d} insert={insert_ms:.1f}ms "
f"bounded={bounded_count}({bounded_ms:.1f}ms) "
f"strong={strong_count}({strong_ms:.1f}ms)"
)
if bounded_count == 0and strong_count > 0:
print("\nREPRODUCED: Bounded missed the just-inserted row, Strong found it.")
print(f"marker={marker}")
print(f"strong_hit={strong_hits[0] if strong_hits elseNone}")
return
if bounded_hits andnot strong_hits:
print("Unexpected: Bounded found the row but Strong did not; check service config.")
print("\nNot reproduced. QueryNode likely consumed the insert before each Bounded search.")
print("Try increasing --storm-writers/--storm-batch-size/--attempts, or run against a cluster under write load.")
finally:
stop_event.set()
for thread in storm_threads:
thread.join(timeout=1)
if args.keep:
print(f"kept collection={collection}")
else:
with suppress(Exception):
writer.drop_collection(collection)
print(f"dropped collection={collection}")
if __name__ == "__main__":
main()
运行命令(替换uri为自身Milvus服务地址):
python probe.py --uri http://localhost:19530 \--storm-writers 2\
--storm-batch-size 2000\
--preload 5000
运行结果:(与文档中报错URL对应的服务地址一致):
uri=http://localhost:19530
collection=consistency_probe_1777278755_71fb2959
preload5000 rows
attempt=000 insert=47.7ms bounded=0(100.7ms) strong=1(171.7ms)
REPRODUCED: Bounded missed the just-inserted row, Strong found it.
marker=probe_0_96fadc07d29e
strong_hit={'id': 1, 'distance': 1.0, 'entity': {'marker': 'probe_0_96fadc07d29e', 'round': 0, 'id': 1}}
dropped collection=consistency_probe_1777278755_71fb2959
实验结论
第一次尝试(attempt=000)即复现:bounded=0 说明 Query Node 正忙于消费 storm writers 制造的写入积压,Bounded 的 guarantee_timestamp 落在本次写入之前,新记录对此次查询不可见;strong=1 说明 Strong 强制 Query Node 追赶到全局最新时间戳后再返回,新记录被稳定查到。
其中distance=1.0确认了查询向量与写入向量完全一致,排除了向量不匹配的干扰。这进一步证明:问题的核心不是数据未写入,而是一致性级别导致的数据可见性时序冲突,与原文开头提出的多Agent写后读空问题完全吻合。
虽然consistency_level="Strong" 能解决多 Agent 写后立刻读的问题,但它需要等待所有并发写入同步完成,会牺牲一定的性能。
因此,我们无需盲目将所有场景都设置为Strong级别,核心判断标准是:写入和查询之间是否有明确的因果关系,以及查询对数据新鲜度的要求。
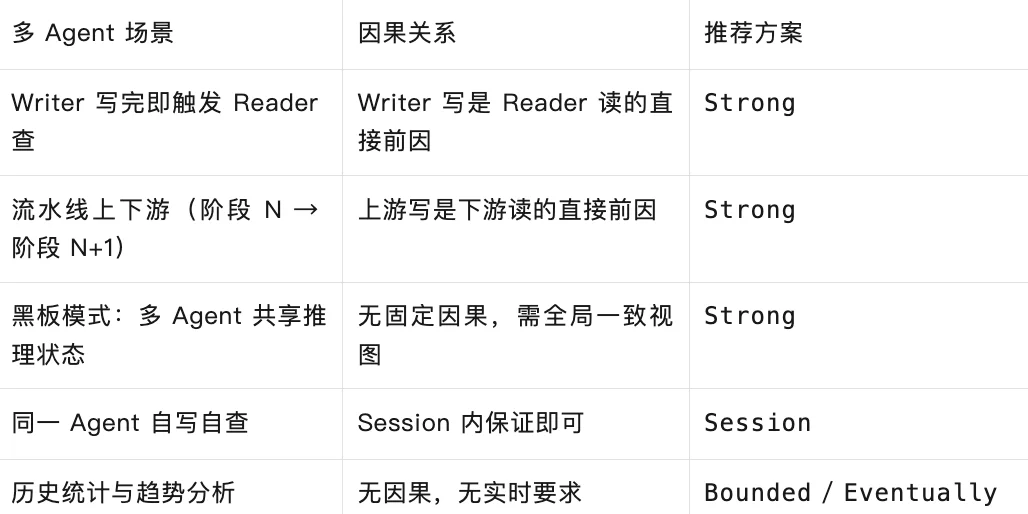
结合多Agent常见场景,我们整理了针对性的一致性级别推荐方案,兼顾性能与一致性需求:
有明确因果——Writer 写完触发 Reader 查,流水线上一阶段写完触发下一阶段读,用 Strong。
无固定因果、但必须看到最新——多个 Agent 并发读写共享状态,没有固定上下游,任何人的写入都可能影响其他人的决策。用 Strong,等全局最新。
在实际开发中,很多人会用time.sleep(N)或无视一致性配置的方式“规避”读空问题,但这两种方式都不可靠:time.sleep靠猜测时间窗口,无法适配不同负载场景;无视一致性则完全靠运气,会导致系统偶发异常,难以排查。
其实,consistency_level参数的作用非常简单:告诉Milvus这次查询需要看到多新的数据。将默认的Bounded改为Strong,就为多Agent的“写后立即读”提供了确定性的可见性保证——这一行参数的差距,就是多Agent系统稳定运行与偶发空结果之间的全部距离。
总结来说:单Agent RAG场景,Milvus的默认配置完全够用;但在多Agent事件驱动场景中,你需要明确告诉Milvus“这次查询要看到最新数据”,通过一行参数调整一致性级别,就能彻底解决写后读空的核心难题。

Zilliz黄金写手:尹珉
文章来自于"Zilliz",作者 "尹珉"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
