# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。
视觉-语言-动作 (VLA) 模型结合了视觉理解、自然语言处理和动作生成,使机器人能够遵循人类指令。这些模型利用预训练的视觉-语言模型 (VLM) 来理解它们所看到的内容以及被要求做的事情,然后将这种理解转化为物理动作。
然而,当前的VLA模型面临一个根本问题:它们经常会形成一种「视觉捷径」,使得其忽略语言指令,而仅仅依赖视觉线索。
之所以会发生,是因为典型的机器人训练数据集在机器人看到的内容和它应该执行的动作之间创建了可预测的映射,使得语言指令变得多余。例如,看到一个柜子几乎总是意味着「打开柜子」,而不管实际给出的指令是什么。
换句话说,对VLA模型的训练来说,语言往往无法为模型提供额外的信息

换句话说,模型有效地忽略了语言指令,学习了一种「视觉捷径」,而当任务存在歧义或环境发生变化时,这种方法就会失效

论文链接:https://arxiv.org/abs/2601.15197

研究人员首先在PhysicalAI-Robotics-GR00T-X-Embodiment-Sim (HuggingFace数据集名称) 的Humanoid机器人桌面操作数据上训练一个标准的VLA模型,并在RoboCasa基准的24个任务上进行评估。由于训练和测试场景非常相似,在全部24个任务上,仅使用视觉的模型取得了44.6%的成功率,与语言条件下的基准(47.8%)非常接近。
这一微小差距表明,该模型在无需依赖语言指令的情况下也能取得成功,因为训练和评估场景及任务高度相似,使模型能够学习到从视觉到动作的近似确定性映射。下图提供了一个相关示例。

为了进一步研究这种行为,研究人员在经典的LIBERO基准上训练了一VLA模型,该基准包含四个子集:Spatial、Object、Long 和 Goal,使用同一个模型在所有四个训练集上联合训练,并在所有四个测试集上进行评估。
结果显示,在三个子集(Spatial: 95.7%,Object: 92.7%,Long: 95.3%)上,仅视觉模型的表现与完整VLA模型相当,这些子集中每个视觉场景对应单一任务。然而,在 LIBERO Goal子集上,仅视觉模型的成功率骤降至12.4%。

关键区别在于,LIBERO Goal本身存在分歧:在训练过程中,相同的物体配置可能对应多个有效任务。例如,一个包含多个碗、炉灶和抽屉的场景,可能对应「将碗放入抽屉」或「将碗放在炉灶上」。
最后,研究人员通过在高质量的BridgeDataV2数据集(diverse, in-the-wild scenes)上进行训练,并在SimplerEnv(simulation, OOD)上进行评估,来测试模型的泛化能力。
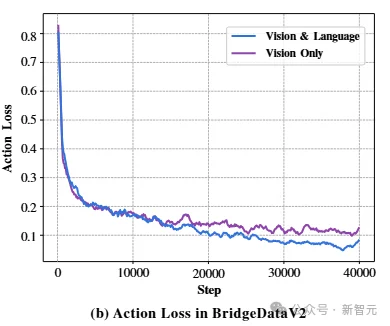
在Bridge数据集上训练时,仅视觉模型的动作损失为0.13,与完整语言条件模型的损失0.08(如图 2(b) 所示)相当。这表明,即使在多样化的、真实世界场景中,模型仍能识别出视觉捷径(例如特定光照或背景特征对应特定动作),从而在无需真正理解语言指令的情况下最小化训练目标。
然而,这种对视觉捷径的依赖对泛化能力造成了灾难性的影响。
在呈现视觉上截然不同的仿真环境的SimplerEnv上进行评估时,仅使用视觉的基准方法取得了接近0%的成功率,证实了在Bridge任务中实现的低训练损失是由于过度拟合特定领域的视觉模式,而非学习到可泛化的操作技能。
因此,当这些特定的视觉线索在分布外(OOD)环境中缺失时,策略会完全失效。


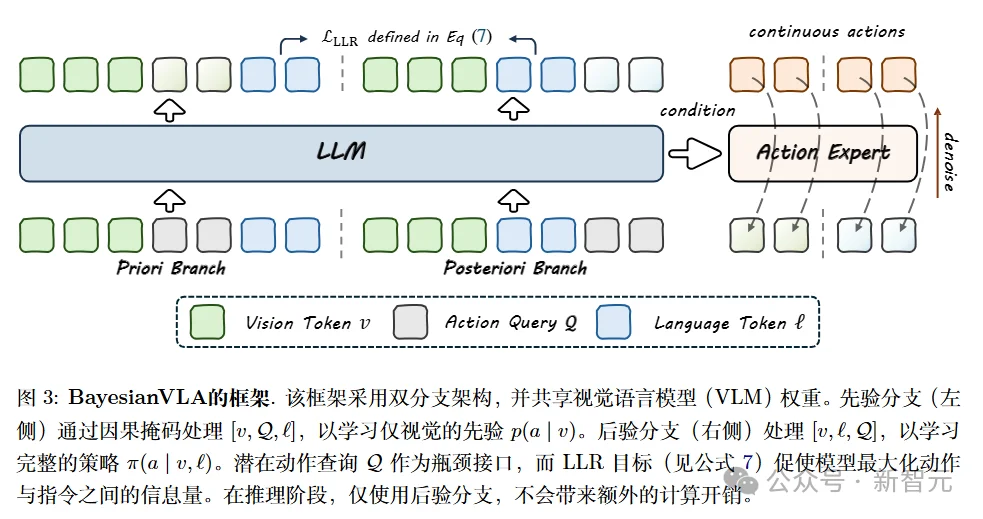


这确保了该方法在测试时相比标准 VLA 基准不会引入额外的计算开销。
LangForce在多项基准测试中展现出显著改进:
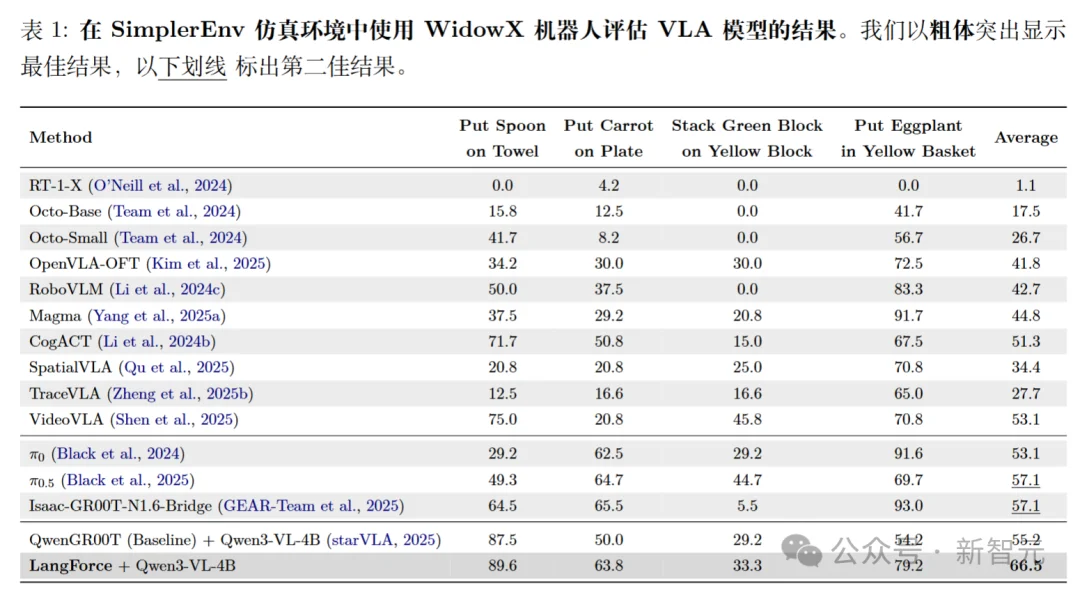
对分布外泛化能力 (SimplerEnv), LangForce平均成功率达到66.5%,超越所有对比算法, 且相较于基线QwenGR00T,实现了11.3%的绝对提升。

对分布内性能 (RoboCasa), LangForce同样达到最先进水平的平均成功率52.6%,优于包括QwenOFT (48.8%) 和Isaac-GR00T (47.6%) 在内的强大基线。
最后,在经典的LIBERO上,LangForce在Goal套件上达到了99.4%的成功率,相较于Qwen3-VL-GR00T基线(97.4%)提升了+2.0%,Goal 套件存在显著的视觉分歧,多个任务共享同一场景。
该结果实证验证了方法能有效缓解视觉捷径问题,使模型通过稳健的指令。
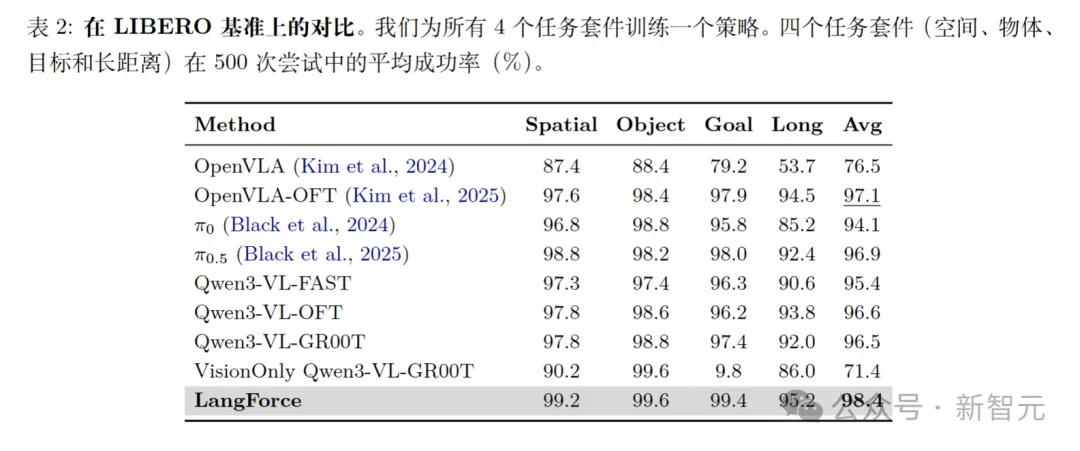
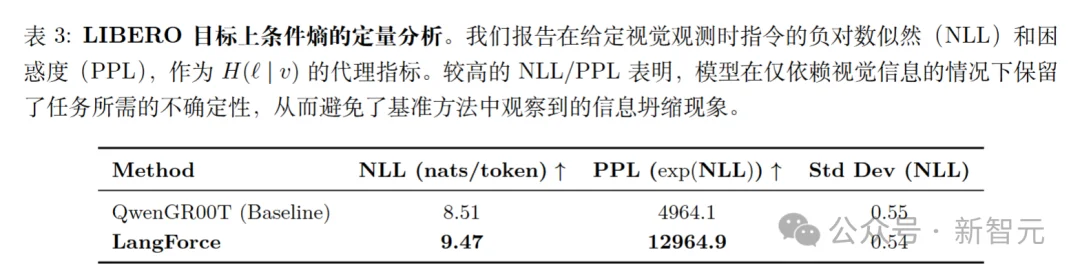
为了进一步证实这一观点,研究人员对LIBERO Goal数据集上的条件熵进行了定量分析,LangForce在NLL上显著高于QwenGR00T。
值得注意的是,LIBERO Goal中的语言结构具有高度重复性(例如 「把 [物体] 放在/放进 [容器]」),自然促使模型拟合这些句法模式。
尽管如此,该方法仍表现出更高的NLL与PPL,表明LangForce保持了与视觉场景固有模糊性相符的不确定性水平。
通过维持这一必要不确定性,该方法迫使策略主动利用提供的语言指令以解决歧义,直接促进了在Goal套件上的优异表现。
语言能力的保留
同时, LangForce的一个关键优势在于它能够保留底层视觉-语言模型的原始推理和对话能力。标准的VLA微调往往伴随着其中LLM模型语言能力的丧失和通用能力的退化,但LangForce却保持了VLM的语言核心。

在基线方法中,「视觉捷径」会使指令在控制任务中变得实际上冗余,从而削弱鼓励有意义语言处理的训练信号,并加剧共享参数的偏移,最终表现为即使在纯文本查询上也会失败。
相比之下,该方法通过LLR损失强制模型对语言产生强依赖。 该机制起到正则化作用,有效维持了指令的功能性,从而在视觉模态被专门用于控制任务的同时,依然保留了主干模型的纯文本对话能力。
这种能力的保留具有重要的实际价值:它确保了VLA的LLM部分的不会退化为降低的浅层特征映射器。通过保留其语言核心,VLA得以维持对高层推理和对新指理和对新指令泛化的潜力。
参考资料:
https://arxiv.org/abs/2601.15197
文章来自于"新智元",作者 "LRST"。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
