# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。
但如果你亲手跑过 OPD,你可能会遇到一个反直觉现象:为什么我换了一个更强的 Teacher,Student 的性能反而毫无提升,甚至出现了倒退?
大模型时代的蒸馏,早就不是简单的「大力出奇迹」了。
清华大学团队最新的一项研究,系统性地解剖了 On-Policy 蒸馏的黑箱。这篇论文不仅揭示了决定蒸馏成败的两大先决条件,还深挖了 Token 级别的对齐机制,并给出了拯救失败蒸馏的实用配方。
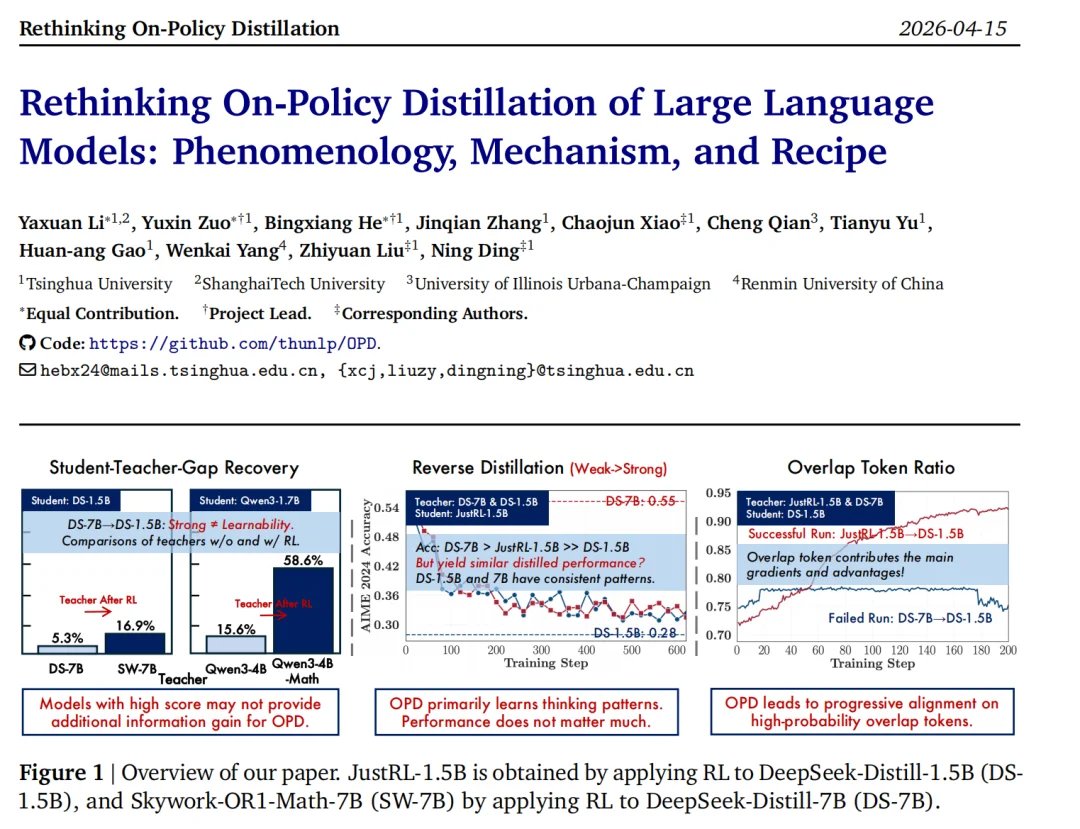
在常规认知中,Teacher 模型的分数越高,蒸馏效果应该越好。但研究团队通过严谨的对比实验,发现了控制 OPD 命运的两个核心法则:
法则一:思维模式一致性(Thinking-Pattern Consistency)
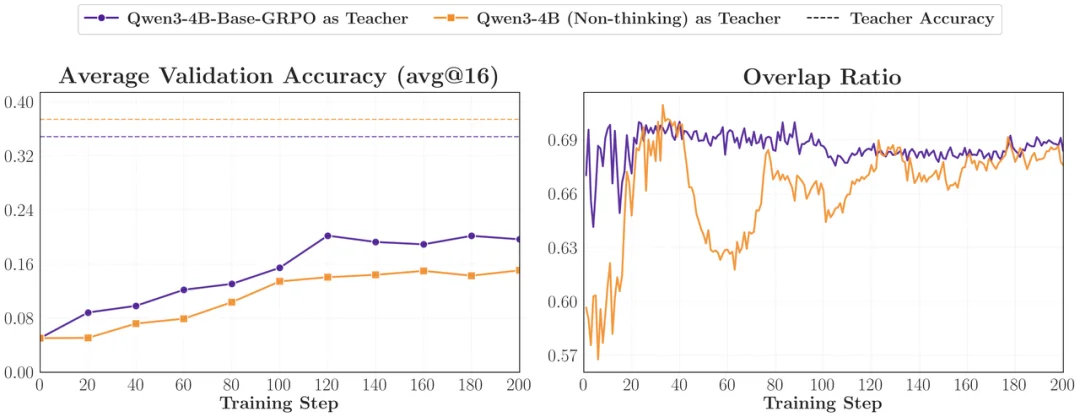
研究者让弱 Base 模型 Qwen3-1.7B-Base 向两个能力相近的 Teacher 学习:一个是 Qwen3-4B (Non-thinking) ,另一个是只经过 GRPO 训练的 Qwen3-4B-Base-GRPO。结果发现,由于学生也是 Base 模型,它与经过 GRPO 强化的 Base Teacher 的 thinking pattern 更近(初始 Overlap Ratio 更高),最终的蒸馏效果取得了显著提升。如果早期思维模式错配,后续很难完全弥补。
法则二:高分 ≠ 新知识(Higher scores ≠ new knowledge)
如果老师和学生思维模式一致,且老师分数更高,蒸馏就一定管用吗?
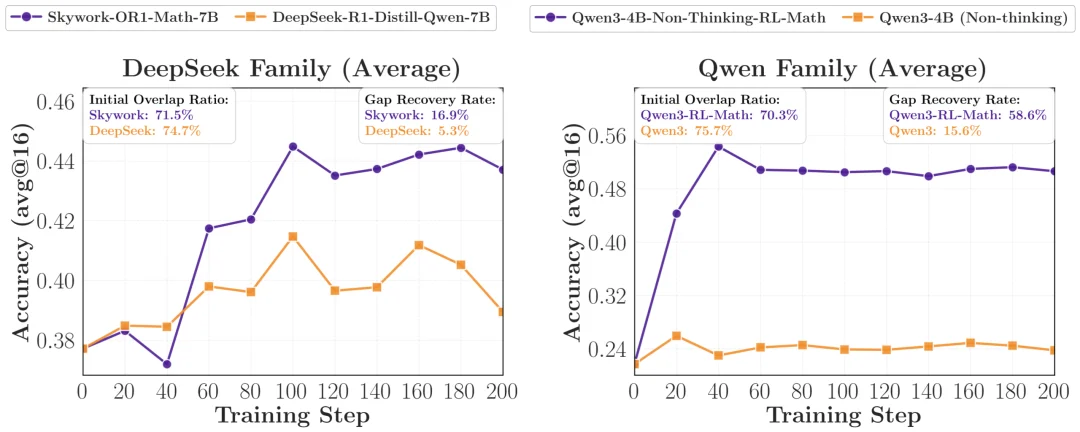
研究者在 DeepSeek 和 Qwen 两个 family 里都看到同样的现象:同 pipeline、同 recipe、只是更大一点的 teacher,提升非常有限;反而是经过额外 RL post-training 的 teacher,能恢复更多 teacher-student gap。比如在 DeepSeek family 里,经过 RL 的 Skywork-OR1-Math-7B gap recovery 是16.9%,而同 pipeline 的 DeepSeek-R1-Distill-7B 只有 5.3%;在 Qwen family 里,这个差距甚至达到 58.6% 对 15.6%。
这说明如果老师只是同一条 pipeline、同一种数据和 recipe 下做得更大,它在学生眼里可能只是「同一类分布的不同尺度版本」,并不会提供多少新的可迁移信号。
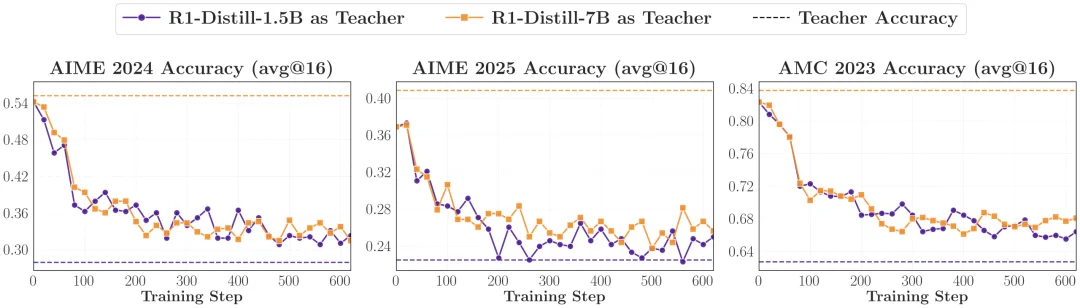
最狠的实验,是把学生「蒸馏回去」
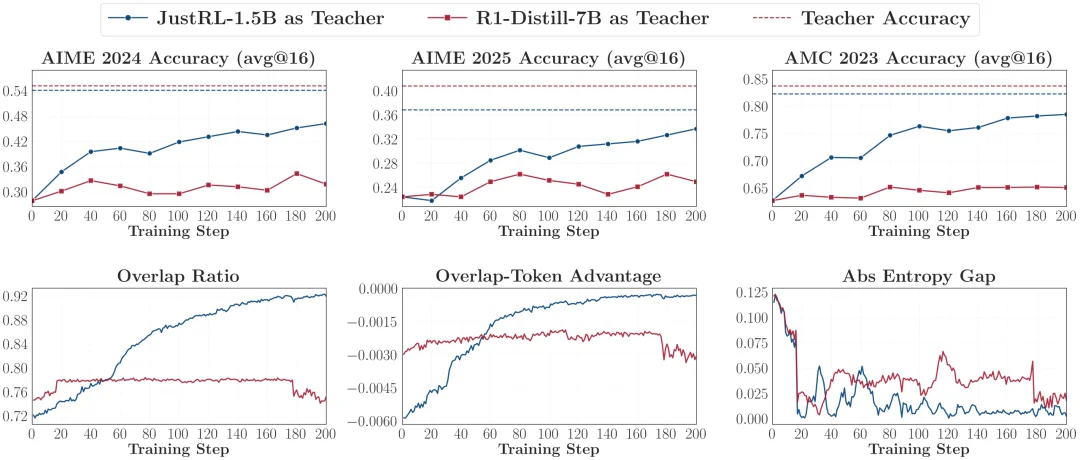
研究者做了一个堪称极端的「反向蒸馏」实验:用 RL 后的 JustRL-1.5B 做学生,让它反过来向自己 RL 之前的 checkpoint R1-Distill-1.5B 学习;同时再拿一个更大、分数也更高的同家族 R1-Distill-7B 来做对照。
结果很意外:向 7B 学习和向 1.5B 学习,效果几乎一样 —— 都让学生的能力倒退回了前 RL 的水平,并且下降曲线非常相近!这说明,7B 虽然分数高,但它相较于 1.5B 只是参数规模带来的红利,并没有提供 Student 更多可学习的信息。 OPD 并不是在简单地「学习高分」,而是在主动提取并复刻老师的思维模式。
当 OPD 成功或失败时,在 Token level 到底发生了什么?
研究者监控了训练全过程的动态指标,发现了一个极为清晰的规律:成功的蒸馏,是一场高概率 Token 的「双向奔赴」。
在成功的 OPD 中,Student 和 Teacher 的前 k 个预测 Token 的重叠率(Overlap Ratio)会从 72% 稳步攀升到 91% 以上,同时两者的熵差距(Entropy Gap)迅速缩小。而在失败的 OPD 中,这些指标从头到尾基本无变化。
更重要的是的发现是:「重叠区域」即是全部。
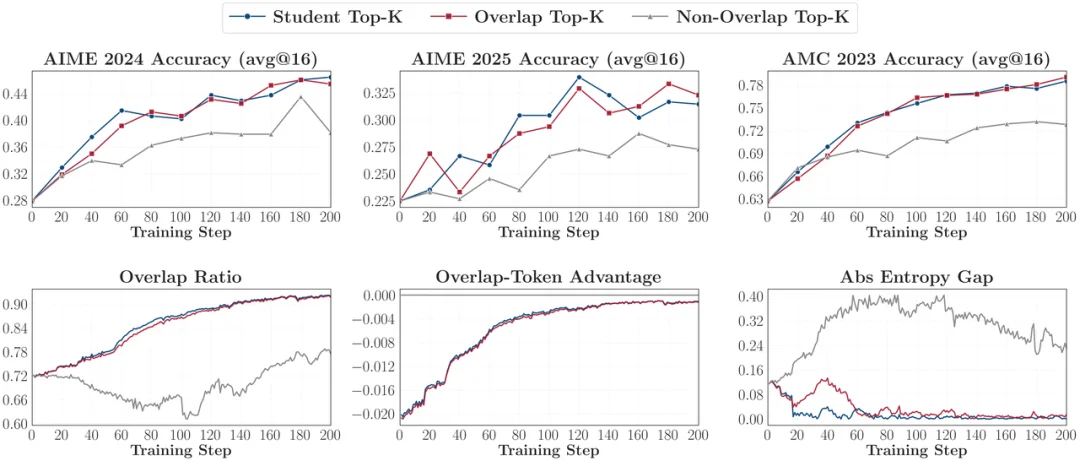
研究者把蒸馏目标拆开,做了一组剥离实验。他们发现,那些被师生共同看好的高概率 Token 是整个优化的核心引擎,贡献了主要梯度和优势。如果只对这些 Overlap Token 计算损失,蒸馏性能几乎不打折扣!而那些非重叠的 Token 对优化几乎毫无贡献。
如果手头只有思维模式不契合的 teacher,是不是就束手无策了?基于上述现象和机制,研究者给出了两剂「对症下药」的药方:
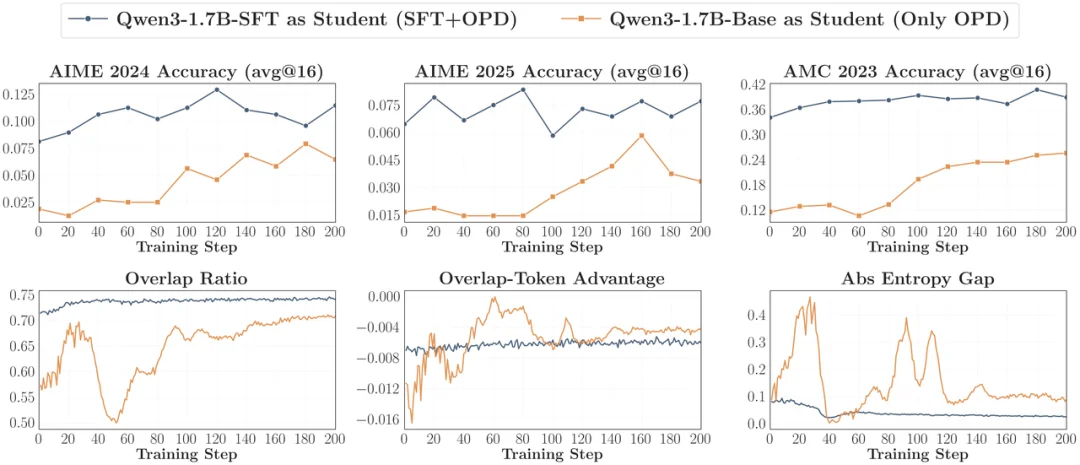
1. 教师 Rollout 上进行 Off-Policy 冷启动(Cold Start)
既然一上来就直接 On-Policy Distillation 容易发生思维方式的不匹配,那就先用 Off-Policy 强行对齐。在开始 OPD 之前,先让 Student 在 Teacher 生成的 rollout 上进行一轮轻量级的 SFT。这能直接拉高初始的 Overlap Ratio ,在随后的 OPD 训练就能丝滑启动,最终收敛的性能上限超越纯 OPD baseline。
2. 与教师对齐的提示词(Teacher-aligned Prompts)
既然 teacher 的策略是在某类 post-training prompt 上被塑造出来的,那就尽量让 OPD 看到更接近 teacher 训练分布的 prompt,包括模板层面的对齐和内容层面的对齐。论文发现,这确实能进一步提升 accuracy 和 overlap growth;但代价是 student entropy 会降得更快,所以最好和一部分 OOD 的 prompt 混用,避免过早发生熵坍塌。
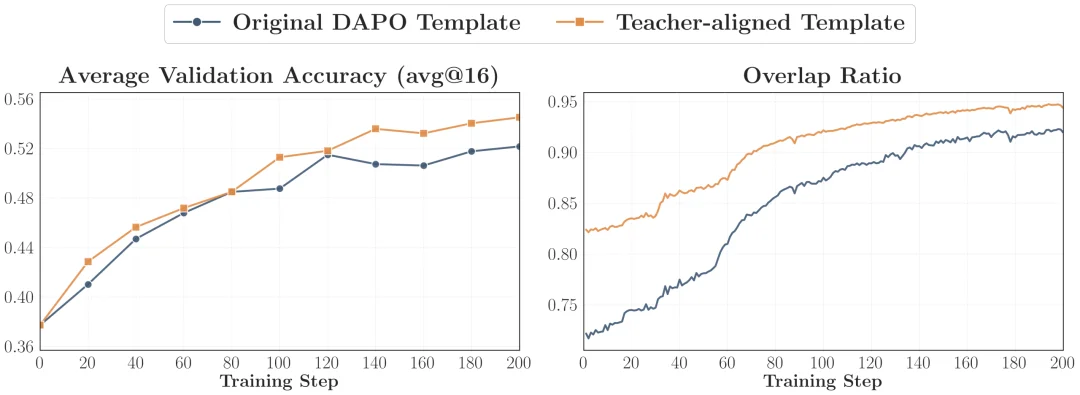
Template 对齐
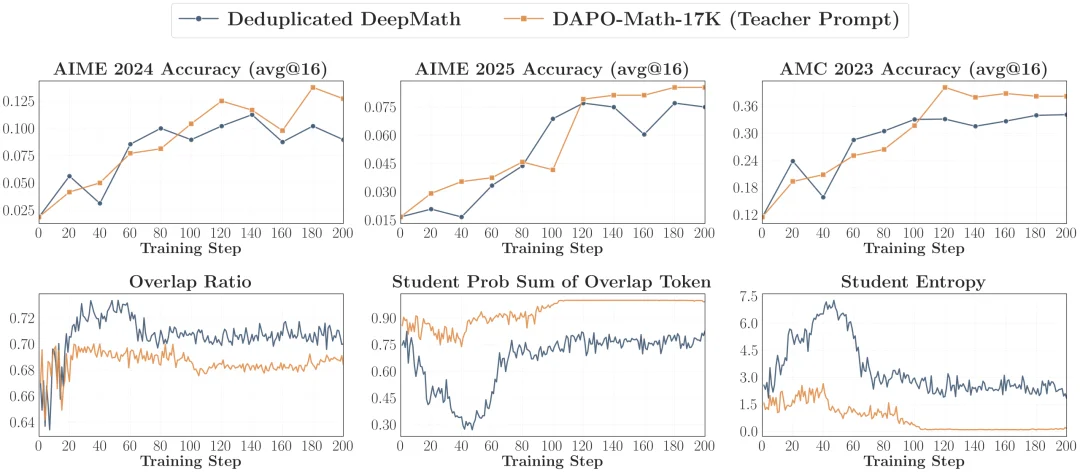
Content 对齐
免费的密集奖励信号确实很诱人,但研究者发现奖励信号的质量会随着轨迹深度急剧衰减。
在长达 15K token 的响应中,研究者观察到了清晰的「从后向前的熵崩塌」:随着生成的深入,Student 的前缀越来越偏离 Teacher 熟悉的分布,导致 Teacher 在后半段给出的奖励变成了纯粹的噪音,进而引发整个训练的坍塌。这说明 OPD 目前很难直接扩展到长思维链或 agentic 多轮场景。密集监督与监督可靠性之间存在根本性张力。
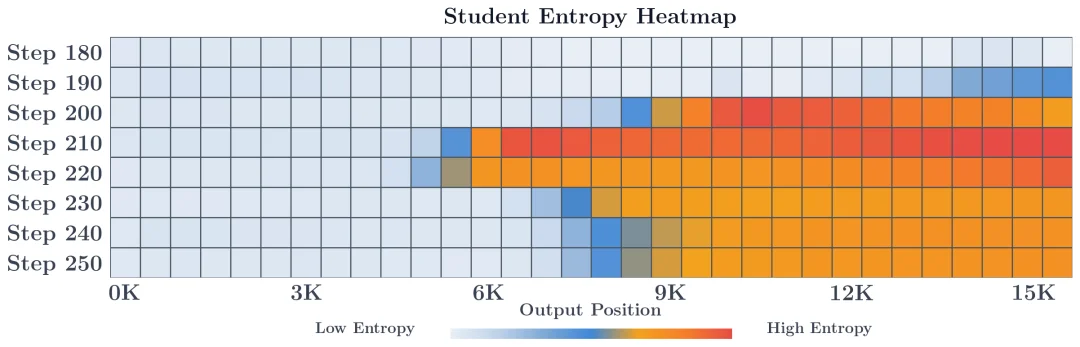
此外,全局有用的奖励,不代表局部能被有效优化。失败 teacher 给出的全局 reward 其实并不弱,区分正确 / 错误 rollout 的 AUROC 甚至和成功 teacher 相近,这说明失败不是因为 reward 信号本身没有信息量,而是因为 reward 的局部优化几何结构出了问题 —— 全局有信息,局部却平坦。
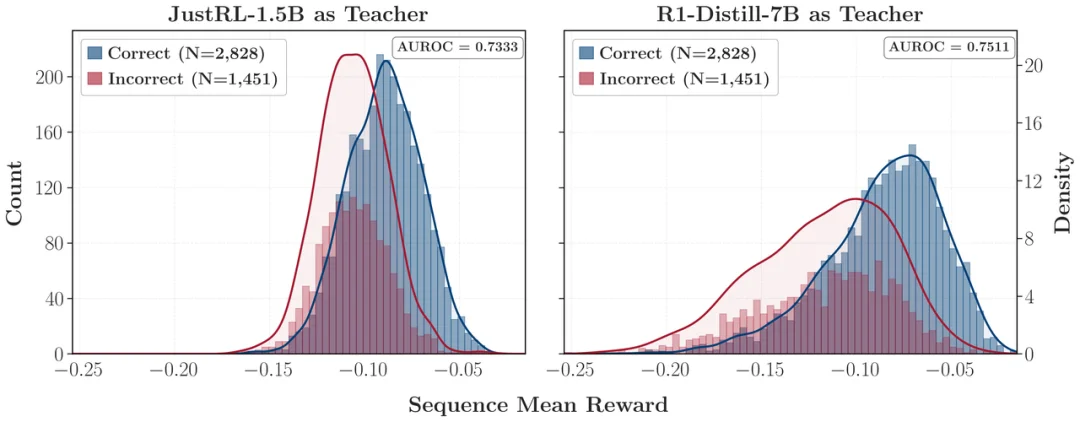
我们习惯了去寻找一个更大的模型来提取知识,想当然认为越强的教师教的越好。但这篇论文给出的答案是:未必。在 OPD 里,更强不自动等于更会教。高分不自动等于新知识。大模型也不只是把能力「灌」给小模型,它更像是在传递一种思维路径、一种局部偏好的组织方式。
所以真正的问题,不是「teacher 有多强」,而是:
而这,也许正是这篇论文最有价值的地方:它没有再给 OPD 增加一个新 trick,而是第一次比较系统地告诉我们 —— 为什么有些 teacher 能教会学生,为什么有些 teacher 只是在「看起来更强」。
文章来自于"机器之心",作者 "机器之心"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
