# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
我被AI杀了?
有视频为证,我被一个不知道是人还是AI的东西,一枪崩了。
还是在一个世界模型创造的世界里。
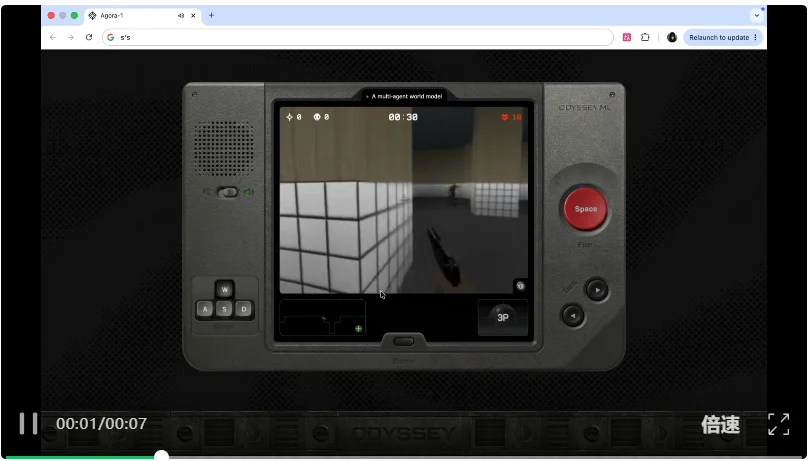
嗯,就是这个画质糊成马赛克的网页版FPS。
背后没有游戏引擎,没有物理规则,没有一行渲染代码。
你看到的一切,都是靠一个叫Agora-1的世界模型,实时生成的。
人类和AI,同时在其中搏击。

先一起看看这条官方产品发布视频。
我看了好多遍,很奇怪的感觉。
和之前看到的demo都不一样。审美很独特的一家公司,拍个发布视频跟拍《黑镜》一样。

关键伪人感真的很重,我时刻怀疑视频里的人是不是也是AI生成的。
实在集中不了注意力,交给codex转成逐字稿看了一下,大概意思就是——
他们做了一个世界模型驱动的多人游戏,最多四个玩家,人类和AI混在一起,在同一个AI生成的世界里搏斗。
说实话,看到这里我有点手痒痒了。
别废话了,快让我瞧瞧这游戏咋回事。
结果定睛一看帖子,还真有游戏链接。
团队还在评论区补了一句:
去碾压那些菜鸟吧!
行。
那还说啥了。
终于实现人生梦想。
上班期间,就这样在工位上堂堂正正,赤赤果果地打游戏(bushi)。
点进去的第一秒,我就知道,自己当时看视频的直觉没错。
这个东西不太正常。
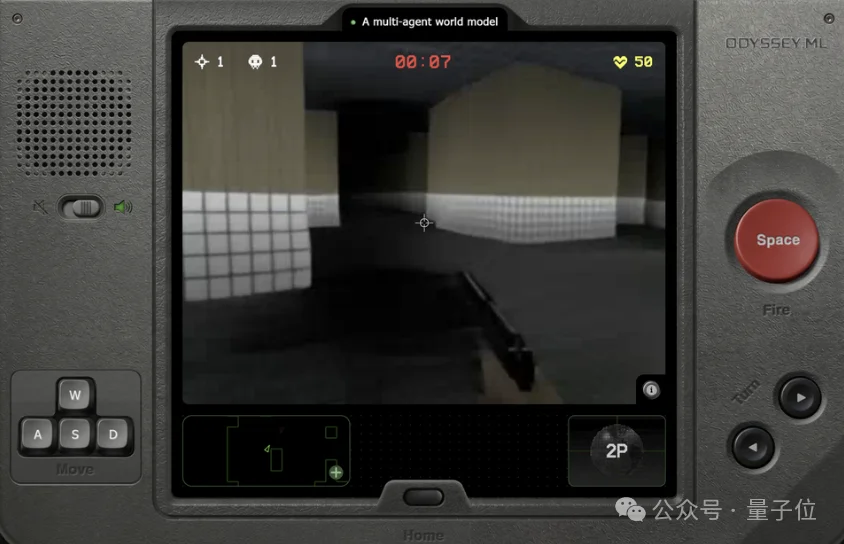
没骂人,就是网页打开第一秒,那个bgm就不对劲。
我到现在脑子里还在循环那段旋律……
UI也是,就是特别怪,深色调,低饱和度……随时有种在看《黑镜》的错觉。
细节也是配套的。
鼠标碰到按钮,会有模拟音效。
老式收音机的那种声音质感,沙沙的,像恐怖游戏。
不废话了,正式开始吧,
游戏开始前,会先让你选名字。
我就选的我的笔名,接着进入等待室。

三缺一。急急急。
ps:后来发现,其实也不是非要凑齐四个人,等久了两个人也能直接开。
这点挺奇怪的,不是说有AI玩家吗?凑不齐的时候让AI顶上不就完了?
搞不懂。

对了,关于这个游戏的规则,其实很简单,我补充下背景大家就理解了。
是致敬的《GoldenEye 007》。
任天堂N64上1997年的经典,007电影《黄金眼》改编的游戏,被很多人认为是主机FPS多人对战的起点之一。
规则极其简单:几个人分屏对打,手枪、冲锋枪、火箭筒、黄金枪,互相干掉对方就完了。
纯粹的死亡竞赛,Deathmatch。没有剧情,没有任务,就是追着砍。
Agora这次的游戏设计基本就是照着这个来的。
好。游戏开始了。
进去之后是一个后室风格的场景,长这样。
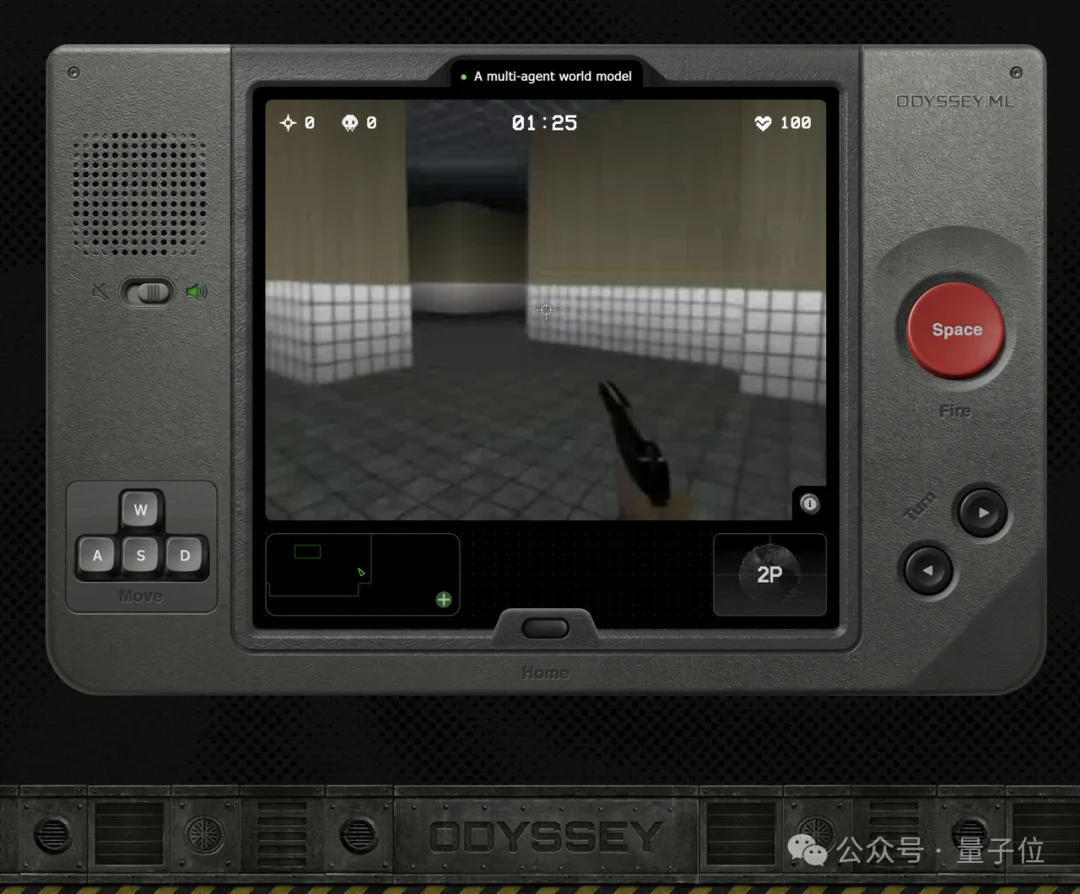
更诡异的是玩家……视野里会偶尔闪过其他角色,没脚步声,跟溜冰一样就溜过去了。
说真的,这人物动作太离谱了,大家看着都挺伪人的。我是真分不清哪个是AI哪个是真人。
而且,我必须吐槽下,这个操控体验真是能气死个人!!
不能用鼠标调视野,偏偏要用左右键。
延迟高,还有后摇,动起来跟在冰面上漂移一样。
不知道怎么想的。
关键是瞄不准啊!
根本刹不住车,光标根本没法停在敌人身上。
然后,我就死了。
一枪没打着……
对面绝对是AI啊,凭什么你就瞄得准!!
气死了!!不许笑!!不是我的问题!!
这个死亡画面也很憋屈了,血一样的深红。

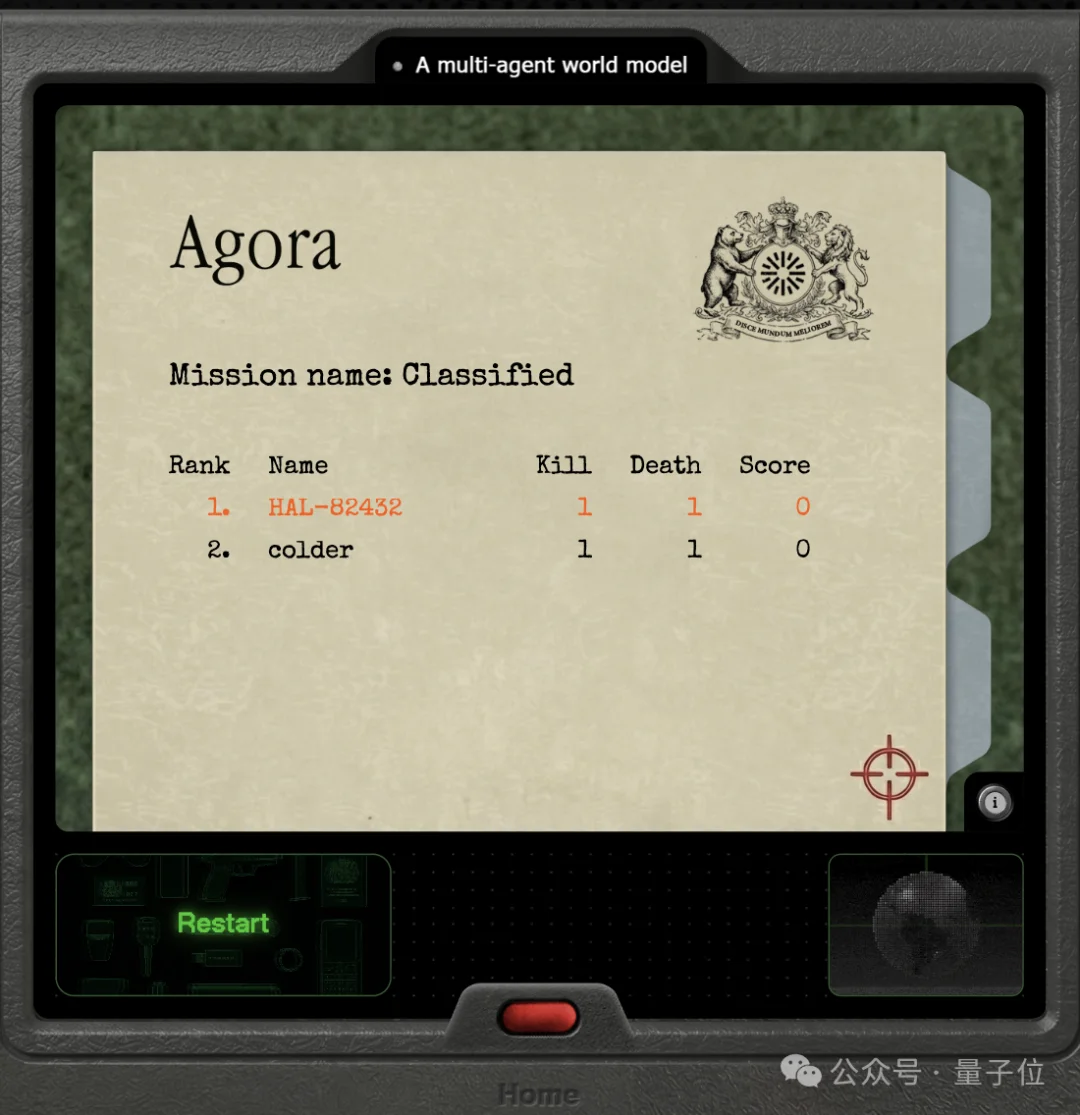
最后会给你个战绩。
你别说,还可以,菜鸡互啄了属于是。
(也可能只是因为对面是人机……)
除了对战本身,这个游戏还藏了一些很有趣的东西。
比如点information按钮能看到Odyssey的公司介绍。

还有玩家说,游戏里的砖块你可以卡bug钻进去。
之后,世界模型会自动把空缺的部分补上。
不会崩溃,不会黑屏,它会即兴生成了一个你本不该看到的空间。

这太有意思了。
传统游戏里,地图边界之外是虚无,是程序员没写的地方。
但世界模型没有边界的概念。
但重点其实不在游戏本身。
回想刚刚的操作,传统游戏思路里听起来很简单。
但不要忘了,这是一个AI生成的世界。
没有硬编码的物理规则,没有预制的地图贴图。你看到的每一帧画面,包括那些你不该看到的越界画面,都是模型实时算出来的。
《黄金眼》作为试验场也非常秀肌肉。
混乱的分屏式玩法之所以难,就是因为很容易暴露出不同步和不连贯的问题。
想要多人FPS游戏,必须保证大家看到的世界是一样的,这个持续模拟的环境得随时保证一致性。
更重要的是,游戏场景是实时互动很容易失控。
要在复杂性和可玩性之间取得平衡,非常非常难。
所以,究竟是谁做出来的?
做出这款游戏的公司,成立于2023年,叫Odyssey。
对,就是古希腊史诗里那个英雄奥德赛。
这名字跟他们公司的整体调性还挺符合的,视觉设计啥的,大家看就知道了。

一家专注于通用世界模型的AI实验室。基本所有产品都是世界模型。
创始人的履历也挺有意思,叫Oliver Cameron和Jeff Hawke,俩人都是自动驾驶起家的。

2024年7月,他们首次在资本市场亮相,拿到900万美元种子轮,领投方是GV。
几个月后,Odyssey又完成1800万美元A轮,总融资来到2700万美元。
不过,他们最初的业务其实和游戏没关系,当时还是流行做AI视频,但现在叙事开始转向主动交互了。
Agora-1是他们最新的成果。
最大的特点就是——
多人。
之前的世界模型,不管做得多精美,里面都只有一个人。
你一个人在AI生成的世界里晃荡,看风景,探索世界,但画面再怎么精致,始终是单机体验。
而Agora-1,最多可引入四个玩家,同时在同一个生成世界里实时交互。
(不过没那么友好就是了)
所以,多人到底难在哪?
这块挺有意思的,可以展开聊聊。
之前不是没人试过。
有两家可以参照的,Multiverse和Solaris。
Multiverse的思路比较直觉,把所有玩家的状态拼成一个分屏画面,当成一张图来处理。
能跑,但很粗暴,不本质。
Solaris则把每个参与者沿着单个自回归扩散Transformer的序列维度进行拼接,从而生成一个更稳健的共享仿真。
但问题也明显,人一多上下文就炸,扩展性很差。
而且这两家有一个共同的痛点:
当玩家彼此离开视野时,很难稳定维持一致性。
简单点说就是脑容量不够用了。
为了减轻负载,Agora-1探索的是另一条路线——
把仿真和渲染解耦。
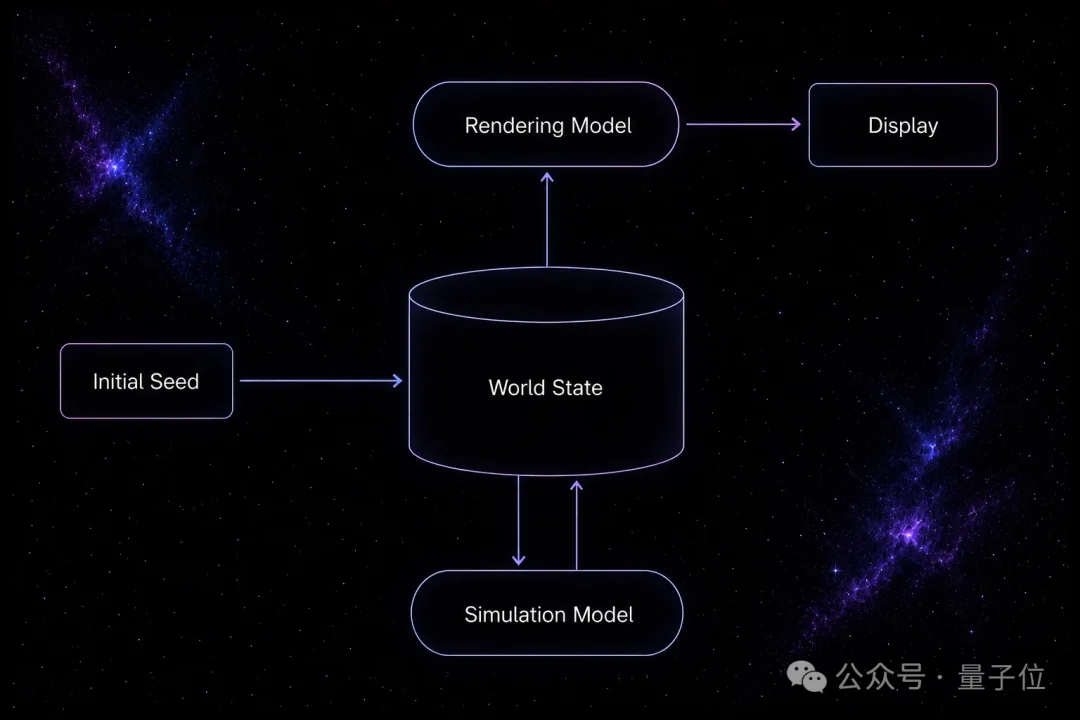
Agora-1学习的是两个不同的函数。
1、仿真。
它学习世界状态会如何随着时间推移而变化,以及这种变化如何响应玩家交互。
为此,团队直接在一个或多个游戏的内部状态上训练模型。
在Agora-1中,这个游戏就是GoldenEye。这个模型会学习底层的游戏动态,以及玩家动作如何触发状态转移。
2、渲染。
这里,Agora-1学习如何把这个共享状态渲染成视觉画面。
这一步是通过一个基于DiT的世界模型完成的。这个模型直接以共享游戏状态为条件,而不依赖提示词、图像或其他传统条件信号。
你可以把这种拆分粗略理解成现代游戏引擎的结构。
区别在于,这两个组件都是靠模型自己学习出来的,它们不依赖手写的游戏逻辑或渲染规则。
结果就是:底层游戏状态可以被直接操控。
也就是说,Agora-1可以生成全新的关卡,同时保留与源游戏一致的游戏动态。
这就是保证多人游戏一致性的秘诀。

对了,在Agora-1发布的前一天,他们其实还发布了另一个东西。
而且坦率地讲,这个给我的触动更大。
叫Starchild-1,他们自称是首个实时多模态世界模型。

视觉加听觉,同时实时生成,并且可交互。
可以让它弹钢琴,琴键落下的同时,声音跟着出来。
也可以用AI重构的方式,带你再次重温一段温暖的记忆,比如——
婚礼。

这点太有想象空间了。
AIGC内容,或许可以被用作那些怎么努力也回想不起来的,记忆缺口的填充物。
突然有点恍惚。
我知道这些产品都很早期。画质糊,操控差,延迟高,体验绝对说不上好。远没到GPT-Image-2那个让普通人也能直观感受到震撼的阶段。
但我在玩Agora-1的时候,有一个瞬间是真的恍惚了一下。
我瞄准一个角色开枪,它倒了。
我不知道它是人还是AI。
我不知道我看到的这个世界是怎么被渲染的。
我甚至不知道,我的对手看到的世界和我看到的,是不是同一个。
然后我突然回想起来——
我看到的一切,都是一个模型算出来的。
这个感觉很奇怪。
最近GPT更新,大家都在担心AI生成虚假聊天记录,有图为证的时代结束了。
但我现在真觉得,图片还好,毕竟只是静态的。
世界模型不一样。
它在模拟一个持续运转的、多人共享的、实时演化的环境。
它模拟的,是时间和主观体验本身。
说实话,今年看着世界模型持续进化,从糊到清晰,从单人到多人,从只有画面到声音、触觉、全感官……
我有时候会突然起一身鸡皮疙瘩。
我该怎么知道自己现在待的这个世界,不是某个更高级的世界模型生成的?
1997年,年轻人们在N64的小屏幕上分屏四处追逐,觉得这就是最酷的事情。
2026年,AI学会了自己生成世界,然后其创造者「哄骗」着把我丢了进去。
按照如今AI的发展速度,2035年,又会是什么样?

所谓的真实……
真的重要吗?
游戏链接:
https://agora.odyssey.ml/
参考链接:
[1]https://odyssey.ml/introducing-agora-1
[2]https://odyssey.ml/introducing-starchild-1
文章来自于"量子位",作者 "Jay"。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
