# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型的能力边界正在不断拓展,从文字到视觉,再到音频,全模态理解已渐成现实。然而,当你问一个多模态大模型「这首歌的高潮从第几秒开始?」或者「第 30 秒之后乐器编配发生了什么变化?」,得到的往往是一个模糊甚至错误的回答。
能读、能看、能听,却依然「听不懂」音乐的时间线,这是当前多模态大模型的共同短板。
为了解决这一问题,来自复旦大学与字节跳动的研究团队提出了 GaMMA,一个专为音乐全局语义与时序动态联合建模而设计的多模态大模型。GaMMA 采用 LLaVA 风格的简洁编码器-解码器架构实现音乐与语言的跨模态对齐,并通过混合专家机制集成双路音频编码器,在同一套参数体系下统一处理时序与非时序两类音乐理解任务。
训练层面,GaMMA 结合大规模精心构建的数据集与渐进式三阶段流程,系统性地拓展了模型的音乐理解能力边界。为全面评估这一能力,团队同步推出了目前规模最大的音乐领域评测基准 MusicBench,包含 3,739 道人工标注的选择题,覆盖音乐理解的多个维度。
实验表明,GaMMA 在多个音乐基准上全面刷新 SoTA,在时序理解任务上超越 Gemini-3.0 Pro,并在专家人工评测中展现出显著优势。

音乐理解天然包含两类截然不同的任务。
一类是全局语义理解:例如「这首歌属于什么流派」「使用了哪些乐器」「整体情绪是欢快还是忧伤」。这类问题关注的是音乐的整体属性,对具体时间位置并不敏感。
另一类则是时序结构理解:例如「第 20 秒到第 40 秒属于主歌还是副歌」「和弦是在什么时间点发生转换」「某段 solo 使用了什么演奏技法」。这类任务要求模型能够持续跟踪音乐随时间展开的结构变化,本质上依赖对时间轴的精细建模。
但这两种能力的目标本身并不一致:全局语义任务强调压缩与抽象,希望模型提炼整体风格与高层特征;而时序任务则要求保留局部细节、节拍变化以及长期结构关系。现有方法通常尝试用同一个音频编码器同时完成这两类任务,希望统一的表征既能理解整体语义,又能捕捉精细时间结构。但由于两类任务对表示空间的需求天然存在冲突,单一编码器往往难以兼顾,最终导致模型在「全局理解」和「时序推理」之间反复权衡,却难以同时做好两者。
更关键的是,现阶段多数音频多模态模型的能力重心,仍然集中在语音与语言内容的建模上:它们更擅长理解「说了什么」这类语言语义信息,而对旋律、和声、节奏、曲式结构等音乐本体属性的建模能力仍然有限。换句话说,这类模型本质上更接近「语音理解模型」,而非真正意义上的「音乐理解模型」。这也直接导致它们在音乐时序推理任务上的表现长期受限。
除此之外,音乐时序理解目前还面临两个基础性瓶颈:
因此,问题并不只是「模型听不懂音乐」,而是现有体系从架构设计、训练数据到评测方式,都尚未为「音乐时间结构理解」提供足够支持。
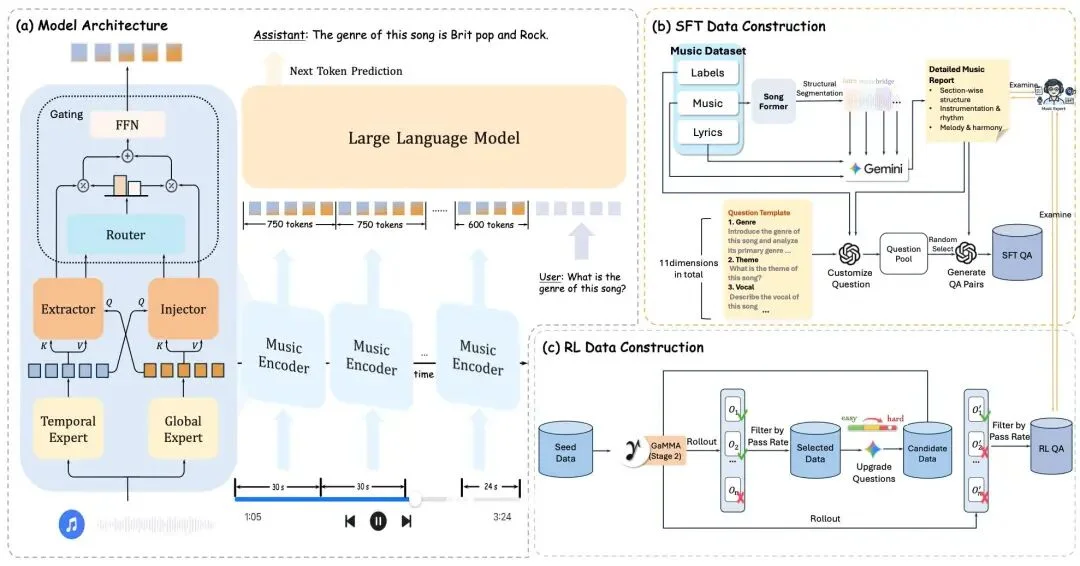
1. 双编码器融合网络(DFN):让「时间专家」和「语义专家」各司其职
GaMMA 的核心洞察在于:音乐中的时序结构理解与全局语义理解,本质上依赖两类不同的表征能力。前者关注音乐随时间展开的动态变化,后者强调整体风格与语义抽象。如果强行让单一编码器同时承担两类任务,往往会产生表征冲突,最终导致两种能力相互牵制。
为了解决这一问题,GaMMA 提出了双编码器融合网络(Dual-encoder Fusion Network,DFN)。整个架构由两个基于 Whisper 的专用编码器组成:
两个专家分别生成自己的音频嵌入序列后,模型通过双向交叉注意力机制进行信息交互:时序分支能够引入全局语义上下文,而全局分支也可以感知局部时间结构中的动态变化。
在此基础上,GaMMA 进一步引入了一个可学习的门控路由模块,在 token 级别动态决定不同专家信息的融合比例。最终,融合后的表示通过残差连接保留原始专家特征,再经过前馈网络生成最终音频表征。
2. 面向音乐任务的三阶段渐进式训练
除了架构设计之外,GaMMA 的另一个关键贡献,是围绕音乐时序理解构建了一套渐进式训练流程以及相应的大规模精细标注的音乐数据集,使模型能力能够从「基础对齐」逐步发展到「复杂时序推理」。
Stage 1:多模态对齐预训练
第一阶段的目标,是建立音乐与文本之间的基础对齐能力。
研究团队在数百万级音乐-文本对上进行训练,覆盖音乐-描述与音乐-歌词两类监督信号。此阶段中,音频长度被限制在 60 秒以内,每段最多对应 1500 个 token,以保证训练稳定性与对齐效率。
为了增强模型对多语言歌词的理解能力,团队根据歌词时间戳对音乐进行切分,确保每个音频片段仅对应一句歌词,并使用 Qwen 词表中的语言标记显式区分歌词语种。
这一阶段仅训练音频到语言空间的 Projector,而冻结 LLM 主体参数,从而最大程度保留预训练语言模型已有的语义能力。
Stage 2:监督微调(SFT)
第二阶段的核心在于构建高质量、具备时间结构监督信号的音乐指令数据。
首先,研究团队采用 SongFormer 对每一首音乐进行细粒度分割,将其划分为秒级(second-level)的结构化音乐片段,以获得精确的时间对齐信息。随后,将时间对齐后的音乐片段与对应歌词共同输入 Gemini 2.5 Pro,生成详细的音乐分析报告。
生成结果随后由具备音乐专业背景的人类专家进行严格校验。在此过程中,专家不仅对时间对齐关系进行修正,还对分析内容的语义一致性与音乐学合理性进行筛选与重写,从而确保数据的准确性与可靠性。
在此基础上,为了支持多轮音乐对话能力的学习,研究团队基于上述音乐分析报告构建指令数据。具体而言,预定义了一组覆盖 11 个音乐维度的系统化问题模板,涵盖结构、节奏、旋律、配器等多个层面。为避免模型对固定模板产生过拟合,同时提升指令泛化能力,研究团队进一步使用 GPT-5.1 对模板进行改写与个性化重述,从而生成多样化的问法表达。
最终,高质量问答对通过随机采样方式组成初始 SFT 训练集,用于监督微调阶段的模型训练。此阶段音频时长扩展至 300 秒(7500 个 token),全参数可训练。
Stage 3:强化学习(GRPO)
为确保在策略优化阶段提供具有足够信息密度的奖励信号,研究团队在这一阶段对训练样本进行分层筛选与再生成。
首先,研究团队沿用 SFT 阶段的数据生成流程构建初始种子样本,并利用训练后的 GaMMA 通过 Monte Carlo rollout 对每个问题的可解性进行估计,得到通过率 Pass。随后,仅保留满足中等难度条件的样本(25% ≤ Pass < 1),以避免过易或过难样本对学习信号造成退化,从而提升奖励信号的有效性与区分度。
在此基础上,研究团队使用 Gemini 2.5 Pro 进行问题合成。在仅提供原始问题及对应音乐片段、但不提供标准答案的条件下,模型被要求生成语义一致但推理路径更复杂的问题变体,从而提升任务难度与推理深度,同时保持答案空间的一致性。 最后,再次利用 GaMMA 进行 rollout-based 验证,对合成样本进行可解性筛选与一致性校验,仅保留能够提供稳定学习信号的高质量数据。
在完成 RL 数据构造后,研究团队采用 Group Relative Policy Optimization(GRPO)对 GaMMA 进行强化学习优化,使用上述多选题数据进行训练。给定输入音乐与问题,模型从当前策略中采样一组候选输出,并基于组内相对表现计算优势函数。奖励函数由答案正确性与格式一致性共同构成,其中正确答案与符合结构要求的输出获得正奖励,其余为零,从而引导模型在保持稳定性的同时提升复杂音乐推理能力。
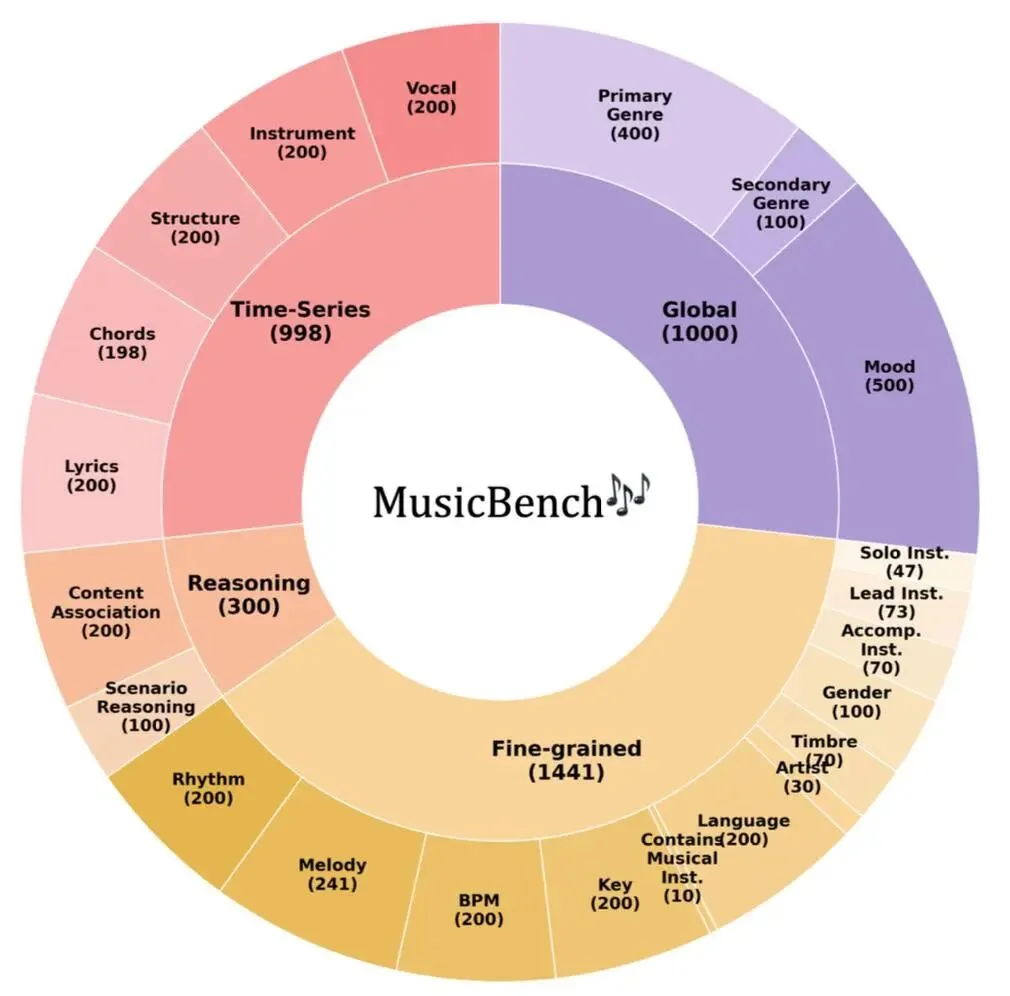
现有音乐评测基准存在一个关键盲区:它们几乎不涉及对时序推理能力的显式测评。MuChoMusic 主要考察全局知识和推理,MMAU 虽覆盖广泛但音乐时序维度薄弱。团队同时推出了 MusicBench,迄今最大、最全面的音乐理解基准,包含 3,739 道人类专家精心标注的多选题,分为两个子集:
MuChoMusic
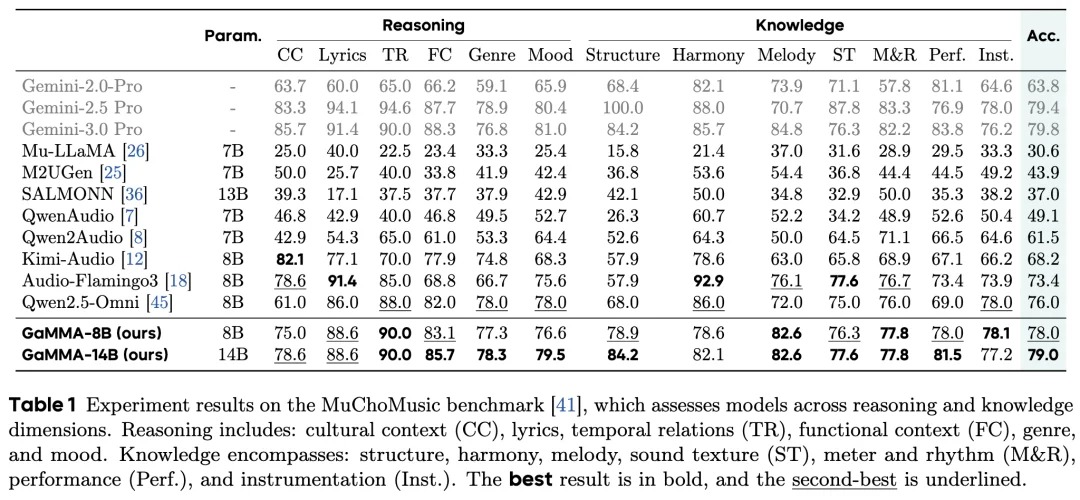
GaMMA-8B 以 78.0% 的总体准确率在同参数模型中登顶,大幅超越 Kimi-Audio(68.2%)和 Audio-Flamingo3(73.4%)。基座模型升级至 Qwen3-14B 后,准确率进一步达到 79.0%。
MusicBench:8B 模型超越 Gemini-3.0 Pro
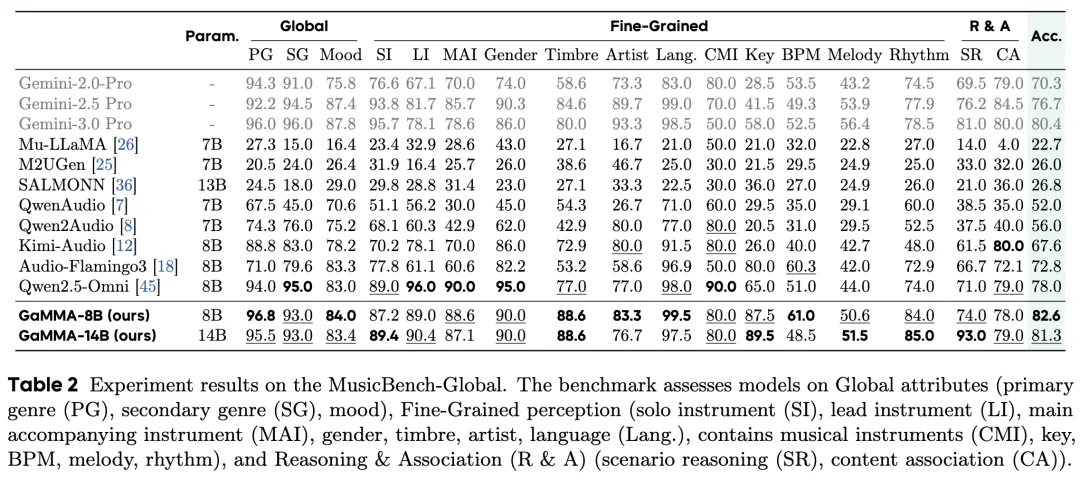
GaMMA-8B 在 MusicBench-Global 评测中取得 82.6% 的成绩,超过 Gemini-3.0 Pro 的 80.4%,在乐器识别、调性与旋律等细粒度感知任务上表现尤为突出。在时序任务中优势更加明显:GaMMA-14B 在和弦理解上达到 75.0%,相比 Gemini-3.0 Pro 的 53.0% 提升超过 22 个百分点;在结构分析(86.5%)与歌词对齐(95.5%)任务上也显著领先开源模型。
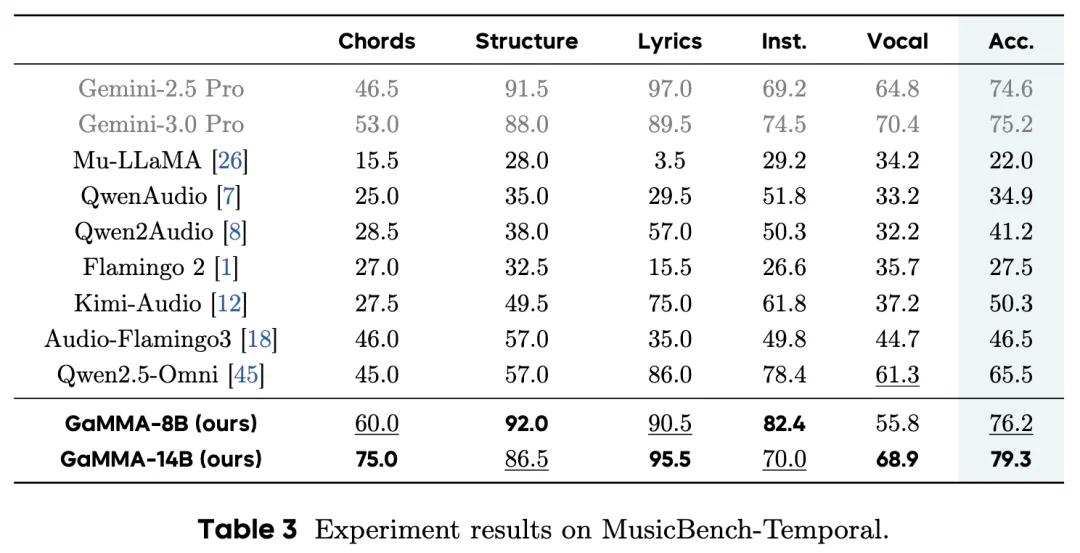
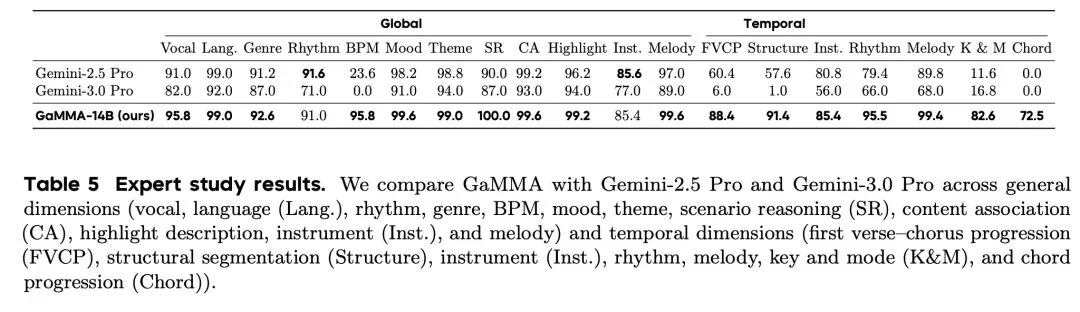
专家评测
尽管 MusicBench 通过多项选择题在判别能力方面提供了全面评估,但同样有必要在开放式自然语言任务中考察模型的生成能力。为此,研究团队对模型生成结果进行了人类主观评测。结果显示,GaMMA-14B 展现出压倒性的优势:
以下展示了 GaMMA 在多轮音乐对话中的实际表现。每个 Demo 对应一段真实音乐输入(仅使用音频,模型无法获取歌曲标题和歌手信息),GaMMA 基于音频内容进行分析和对话。
Demo 1:南方-达达乐队

User: 歌曲里面有一段呐喊将情感推向高潮,具体的时间是在哪?
GaMMA: 是的,歌曲中有一段非常突出的情感高潮。这并非一次性的呐喊,而是一个持续的、充满力量的吟唱部分,它从大约 2:35 开始,并一直延续到 3:32 左右。在这个长达近一分钟的时间里,主唱用高亢且带有撕裂感的声音反复吟唱着「南方」这个词,背景音乐也达到了最宏大和激烈的程度,形成了整首歌的顶点。
Demo 2:《让我们荡起双桨》(重金属版)

User: 这首歌有什么不寻常的地方?
GaMMA: 这首歌最大的亮点在于其「反差萌」的魅力。它将硬朗、充满力量感的摇滚乐编曲与极其简单、童真、朗朗上口的旋律和歌词(如「小船儿轻轻飘荡在水中」)完美地结合在一起。这种成人摇滚与儿童歌曲元素的碰撞,创造出一种既酷炫又充满童趣的独特听感,让人印象深刻。

User:请详细分析这首歌的结构,包括各段落的时间范围以及各音乐结构下的歌词(如有)。列出每个段落包含的乐器。列出每个音乐结构的和弦进行和每个和弦对应时间,并分析。描述每个段落的拍号。描述每个段落感受到的节奏感律动。提供每个段落的旋律信息,包括旋律发展/走向、主副歌对比、音域、和弦、音程、节奏型、核心动机、记忆点、发展逻辑以及如何与歌词配合。
GaMMA:
1. 前奏 (Intro)
* 时间范围: 00:00 - 00:08
* 包含乐器: Whistle (主旋律), Acoustic Guitar, Shaker, Bass
* 和弦进行与分析:
* F:maj (00:00) - C:maj (00:02) - G:maj (00:04) - A:min (00:06) - G:maj (00:07)
* 这是一个经典的 I-V-IV-vi-V (在C大调中) 的变体,以明亮的IV级和弦(Fmaj)开始,迅速确立了歌曲阳光、积极的基调。
* 拍号与律动: 4/4拍。律动轻松、舒缓,由吉他的分解和弦和轻微的摇摆感(Shake)节奏构成。
* 旋律信息: 核心动机由口哨声呈现,这是一个简单、上口且极具辨识度的旋律片段,奠定了全曲的记忆点。
2. 主歌 A1 (Verse 1)
* 时间范围: 00:08 - 00:23
* 歌词: "I'm soaking up the sunshine... my internal third degree... trying to unwind but wandering mind, but these trees keep telling me..."
* 包含乐器: Male Vocal, Acoustic Guitar, Bass, Light Percussion (Shaker)
* 和弦进行与分析:
* F:maj (00:08) - C:maj (00:10) - G:maj (00:12) - A:min (00:14) - F:maj (00:17) - C:maj (00:19) - G:maj (00:21) - G:maj (00:22)
* 和声进行延续了前奏的模式,为叙事性的歌词提供了稳定而温和的背景。
* 拍号与律动: 4/4拍。律动保持前奏的轻柔感,节奏平稳,为叙事留出空间。
* 旋律信息: 旋律线较为平直,音域集中在中音区,音程跳动小,节奏与口语节奏贴近,服务于歌词的自然叙述。旋律配合歌词“soaking up the sunshine”营造出一种慵懒、放松的感觉。
3. 副歌 B1 (Chorus 1)
* 时间范围: 00:24 - 00:39
* 歌词: "Take it easy, take it easy, take it easy, my friend... breathing freely, take it easy... Don't wait 'til the beginning meets the end."
* 包含乐器: Male Vocal, Acoustic Guitar, Bass, Percussion (Kick, Clap/Snare, Shaker)
* 和弦进行与分析:
* F:maj (00:25) - C:maj (00:27) - G:maj (00:29) - A:min (00:31) - F:maj (00:33) - C:maj (00:35) - G:maj (00:37) - C:maj (00:39)
* 和声进行依然是I-V-IV-vi等核心进行,但配器更丰满,推动感更强。
* 拍号与律动: 4/4拍。律动变得清晰有力,加入了底鼓和军鼓/拍手声,形成稳定的四分音符律动,能量感显著提升。
* 旋律信息: 这是歌曲的核心记忆点。旋律线明显上扬,音域比主歌更高,使用了更多长音来强调“Take it easy”的口号式主题。旋律与歌词完美契合,通过重复和上行的旋律走向,传达出一种劝说和鼓励的力量。
4. 主歌 A2 (Verse 2)
* 时间范围: 00:39 - 00:56
* 歌词: "Can we move a little smoother? A million miles in baby steps... Mother nature knows the truth hurts, there's life and death in every breath."
* 包含乐器: Male Vocal, Acoustic Guitar, Bass, Percussion
* 和弦进行与分析:
* F:maj (00:41) - C:maj (00:43) - G:maj (00:45) - A:min (00:47) - F:maj (00:49) - C:maj (00:51) - G:maj (00:53)
* 和声结构与第一段主歌类似,保持了歌曲的连贯性。
* 拍号与律动: 4/4拍。律动与第一段主歌相似,但由于有了完整的鼓组,整体感觉更坚实。
* 旋律信息: 旋律发展逻辑与第一段主歌一致,保持叙事性,音域和节奏型都相对收敛,为下一段副歌的能量爆发做铺垫。
5. 前副歌 (Pre-Chorus)
* 时间范围: 00:57 - 01:12
* 歌词: "It's the final destination... We can't escape and can't forget... But one simple observation, all we know for sure is our time's not over yet."
* 包含乐器: Male Vocal, Acoustic Guitar, Bass, Percussion (力度渐强)
* 和弦进行与分析:
* F:maj (00:57) - C:maj (00:59) - G:maj (01:02) - A:min (01:04) - F:maj (01:06) - C:maj (01:08) - G:maj (01:10)
* 这段和声进行持续建立张力,最后停留在属和弦(G)上,制造出强烈的期待感,为进入副歌做准备。
* 拍号与律动: 4/4拍。律动感增强,通常会加入一些鼓的填充(fill),推动音乐前进。
* 旋律信息: 旋律线开始呈现上行趋势,音高逐渐攀升,情绪也随之提升,与歌词中“time's not over yet”的积极展望相匹配,成功地将听众的情绪引向高潮。
6. 副歌 B2 (Chorus 2)
* 时间范围: 01:13 - 01:29
* 歌词: "So take it easy, take it easy, take it easy, my friend... breathing freely, take it easy... Don't wait 'til the beginning meets the end."
* 包含乐器: Male Vocal, Acoustic Guitar, Bass, Full Percussion
* 和弦进行与分析:
* F:maj (01:14) - C:maj (01:16) - G:maj (01:18) - A:min (01:20) - F:maj (01:22) - C:maj (01:24) - G:maj (01:26) - C:maj (01:28)
* 重复副歌的经典和声进行,但配器更饱满,能量达到新的高度。
* 拍号与律动: 4/4拍。这是全曲第一个能量顶点,律动强劲,富有感染力。
* 旋律信息: 重复副歌旋律,但在更丰富的编曲和更具力量的演唱下,情感表达更为强烈。
7. 桥段 (Bridge)
* 时间范围: 01:30 - 01:57
* 歌词: "When you're choosing your regrets... The internet forgets while the universe indents... So can you really live with all the you you've left unsaid... 'Cause you can't take it with you when you're dead... No, you can't take it with you when you're dead... But it isn't what we take, what truly counts is what we leave."
* 包含乐器: Male Vocal, Acoustic Guitar, Bass, Percussion (节奏型变化)
* 和弦进行与分析:
* F:maj (01:30) - C:maj (01:32) - G:maj (01:34) - A:min (01:36) - F:maj (01:38) - C:maj (01:40) - G:maj (01:42) - C:maj (01:44) - G:maj (01:47) - C:maj (01:49) - F:maj (01:51) - C:maj (01:53) - G:maj (01:55)
* 和声进行依然围绕C大调核心和弦展开,但在编曲上做出变化,创造出新鲜感。
* 拍号与律动: 4/4拍。律动有所变化,可能变为半速(Half-time)或简化,为歌词的哲学思考提供空间,随后逐渐恢复速度。
* 旋律信息: 桥段引入了全新的旋律材料,节奏型和旋律走向都与主副歌不同,更具独白和反思的色彩。旋律配合歌词的哲理内容,从个人感悟到普世道理,逻辑上层层递进,为歌曲的情感升华服务。
8. 演唱桥段 (Vocal Bridge)
* 时间范围: 01:58 - 02:22
* 歌词: "So I hope through all I gave, you can see how I believed... Moving with intention, let the tension be released... Tear down my pretenses, and the rest is left in peace."
* 包含乐器: Male Vocal, Acoustic Guitar, Bass, Light Percussion
* 和弦进行与分析:
* F:maj (01:59) - C:maj (02:01) - G:maj (02:03) - A:min (02:05) - F:maj (02:07) - C:maj (02:09) - G:maj (02:11) - A:min (02:13) - F:maj (02:15) - C:maj (02:17) - G:maj (02:19) - C:maj (02:21)
* 和声回归到最基础、最温暖的进行,为最后的情感爆发做铺垫。
* 拍号与律动: 4/4拍。律动再次变得轻柔,如同暴风雨前的宁静。
* 旋律信息: 旋律回归到主歌的叙事风格,但情感更真挚,像是在娓娓道来一个故事的结尾,充满了希望和释然。
9. 尾声 (Outro)
* 时间范围: 02:23 - 02:57
* 歌词: "Now you're here singing with me... do our best to plant the seeds... To the kids in 2050, I hope you have some pretty trees."
* 包含乐器: Male Vocal, Whistle, Acoustic Guitar, Bass, Percussion
* 和弦进行与分析:
* F:maj (02:23) - C:maj (02:25) - G:maj (02:27) - A:min (02:29) - F:maj (02:31) - C:maj (02:33) - G:maj (02:35) - C:maj (02:38)
* 在反复的I-V-IV-vi进行中,最终解决回主和弦C大调,带来完满的结束感。
* 拍号与律动: 4/4拍。律动逐渐减弱,最终回归到前奏的轻柔状态,与开头形成呼应。
* 旋律信息: 旋律再次回到前奏的口哨动机,并结合了新的歌词,仿佛是对整首歌曲主题的总结和升华。歌曲在平静而充满希望的氛围中缓缓结束,留下悠长的回味。
本文提出了 GaMMA,一个旨在全面捕捉音乐内容复杂性的音频多模态大模型。通过将 DFN 与三阶段渐进式训练策略相结合,GaMMA 首次在一套参数体系内统一处理时序与非时序两类音乐理解任务。为衡量该领域的研究进展,研究团队同步推出了 MusicBench,这是目前规模最大、覆盖维度最全面的人工标注音乐 LMM 评测基准。GaMMA 在 MusicBench 和 MuChoMusic 上均取得 SOTA 表现,充分证明了其在通用音乐理解上的有效性。研究团队相信,GaMMA 是让多模态大模型更自然地融入现实世界的重要一步:在这个世界中,音乐是人类体验不可或缺的一部分。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
