
独家|牛津博士后林庆泓加入世界模型创企Video Rebirth,探索多模态智能体
独家|牛津博士后林庆泓加入世界模型创企Video Rebirth,探索多模态智能体Z Potentials 独家获悉,新加坡国立大学博士,牛津大学博士后研究员林庆泓(Kevin)近期以首席研究员(Principal Researcher)身份加入世界模型公司 Video Rebirth,负责多模态智能体与世界模型相关研究。
来自主题: AI资讯
9663 点击 2026-07-29 10:11
 搜索
搜索
Z Potentials 独家获悉,新加坡国立大学博士,牛津大学博士后研究员林庆泓(Kevin)近期以首席研究员(Principal Researcher)身份加入世界模型公司 Video Rebirth,负责多模态智能体与世界模型相关研究。

Z Potentials 获悉,AI多模态内容互动娱乐社区海艺近期完成超亿元人民币B轮融资,由视觉中国、华盖创赢、祥峰投资联合领投,广发信德、天投资本、川创投、广州合伟永晟参与。
7 月 24 日,Vivix 正式发布两款激活参数约 30B 的模型 Vivix-A1(开放世界演员)和 Vivix-W1(开放世界剧情)。这次发布试图回答的问题不是"生成能不能更快",而是更前一步的:模型在持续生成音视频的同时,能不能随时接住用户的新输入,并即时改变正在生成的内容?

近日,腾讯宣布混元多模态模型部门与大语言模型部门合并,成立基础模型部,统一由腾讯首席AI科学家姚顺雨管理,以进一步提升模型研发和协同效率,探索全模态模型的智能上限。
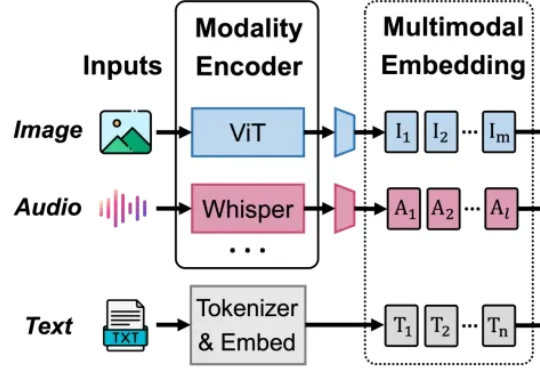
BigMac 是原生多模场景下的流水并行训练新范式。它针对多模态大模型训练中计算效率与显存占用难以兼顾的问题,提出了依赖安全的嵌套流水线:以成熟的 LLM 流水线为主干,在不打乱 LLM 执行顺序的前提下,有序嵌入编码器和生成器计算,从而在不增加 LLM 流水线空泡、保持激活显存有界的同时,高效实现多模态流水训练。

独家获悉,近期,腾讯混元多模态理解负责人胡瀚提出了离职。此前,他曾担任微软亚洲研究院视觉计算组首席研究员。2025年初加入腾讯后,负责视觉大模型的研究。在后续的调整中,他加入大语言模型部旗下的“Frontier”前沿技术研究组,负责多模态理解的相关研究,汇报给姚顺雨。

多模态生成式创新公司智象未来(HiDream.ai)已于近日完成15亿元的C轮融资。这已经是智象未来在近三个月内完成的第三轮融资。融资之外,另据公开信息显示,智象未来已经同步完成了股改,正式更名为“智象未来(合肥)科技股份有限公司”。在资本市场,股改往往意味着一家公司在对接资本市场的进程中迈出了重要的一步
刚刚结束的 2026 年世界人工智能大会(WAIC) ,具身智能与 AI 终端占据了最显眼的位置,人形机器人、灵巧手和各类智能硬件吸引了大量目光。
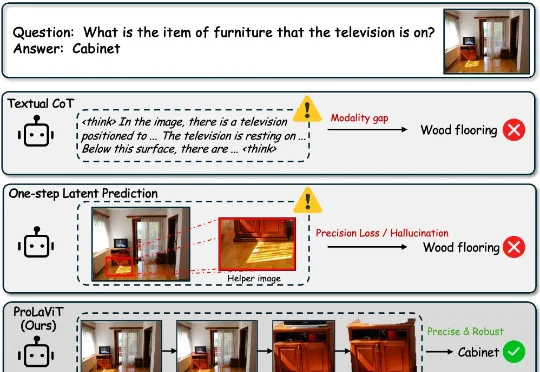
针对这一挑战,腾讯内容服务部 BAC 提出了一个名为 ProLaViT(Progressive Latent Visual Thought) 的全新框架。它的核心思想是:别急着下结论,先在连续隐空间里像人一样「步步推导」。 即让模型遵循 「定位 → 聚焦 → 分离」(Locate → Focus → Isolate) 的因果链,逐步收紧视觉注意力,最终精准锁定目标。

最近,世界人工智能大会上,中科闻歌磐石 ScienceOne 团队一口气亮出两张王牌:专攻科学场景下深入理解、预测与生成的科学多模态统一推理模型 —— S1-Omni;以 S1-Omni 为基座、贯穿整个科研生命周期的智能化服务平台 —— ScienceOne。