# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现有的开源多模态搜索智能体普遍受困于「裁剪 - 再搜索」的串行处理模式,面对多目标时往往陷入交互冗长、错误级联累积的泥沼。
为此,小红书研究团队提出了一款全新架构的模型:HyperEyes。通过统一定位与搜索的动作空间、构建并行可学习数据以及双粒度效率感知强化学习的全栈设计,HyperEyes 成功实现了从「搜得更深」到「搜得更宽」的并行多模态搜索范式跃迁。
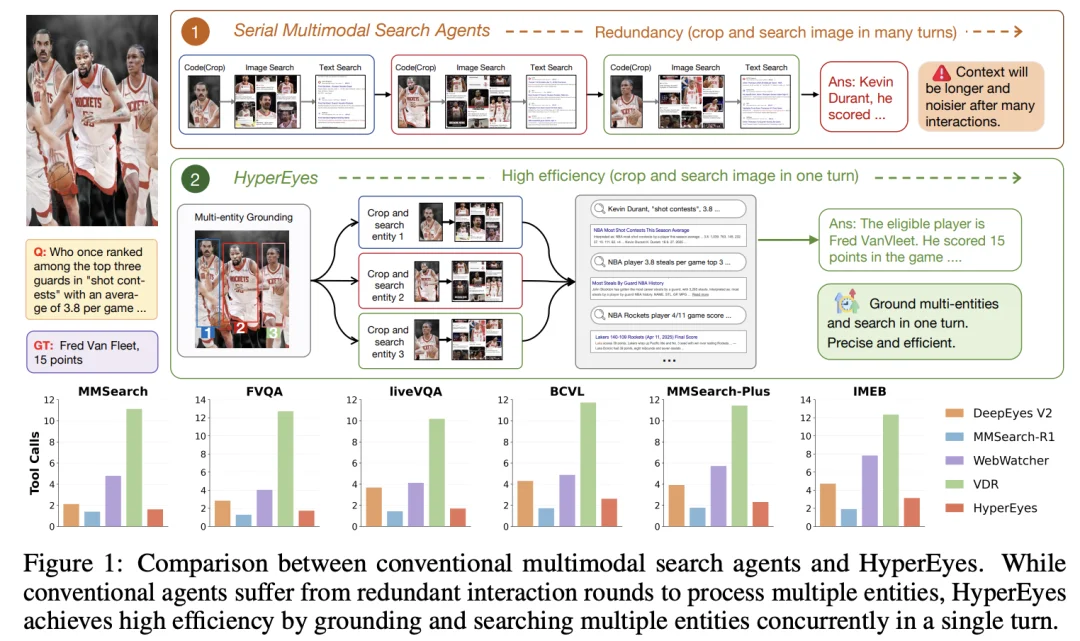

当前主流的 Agent 在面对包含多个实体的复杂图片时,往往只能采用笨拙的「N 轮串行调用」策略。
这种传统的处理路径带来了三重难以逾越的困境:首先是极大的交互冗余,原本一句话的多实体查询被迫退化为多次单实体搜索,导致延迟剧增;其次是错误放大的多米诺骨牌效应,前置定位一旦发生偏差,后续的搜索结果将被全部污染;最后是模型训练中普遍存在的奖励偏差与「信用分配」问题。
现有模型往往仅以「最终答案对错」作为唯一奖励标准,这不仅会导致智能体为了追求表面准确率而养成「暴力多搜」的坏习惯,引入更多噪声;更致命的是,这种粗粒度的稀疏奖励会带来粗暴的「连坐惩罚」—— 在那些最终失败的探索轨迹中,原本正确、富有逻辑的中间推理和工具调用也被一并全盘否定,导致模型根本无法从失败中有效汲取局部经验。
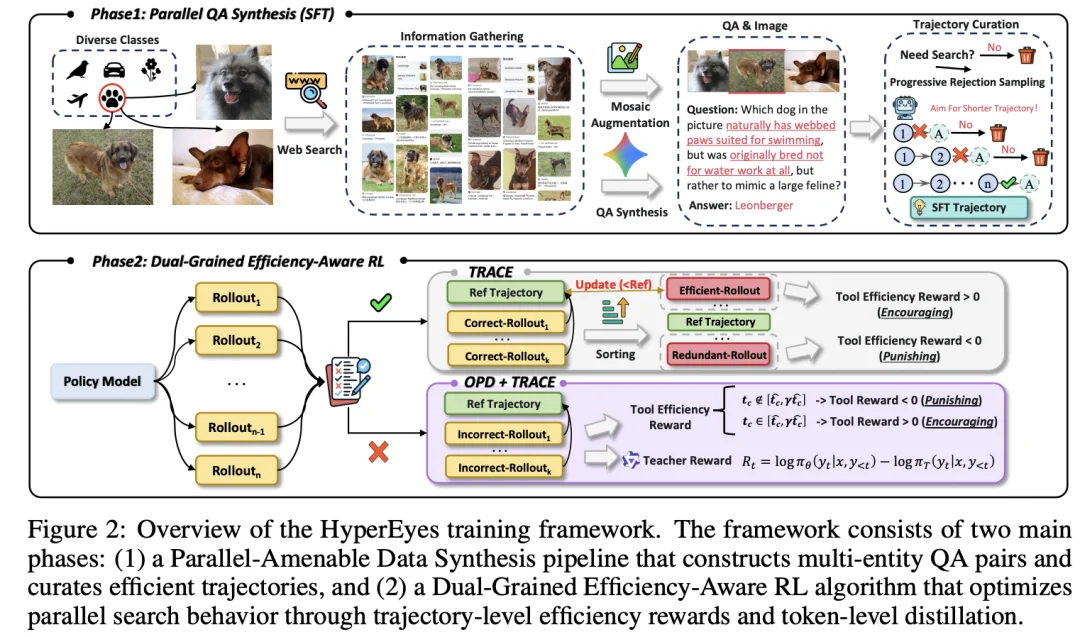
为了让智能体真正具备「一次出手,多目标并发」的内生能力,HyperEyes 研究团队在动作空间、数据合成与强化学习三个维度上进行了彻底的底层重构。
传统的智能体通常将「视觉裁剪」和「网络搜索」作为两个独立的步骤,而 HyperEyes 打破了这一隔离,提出了「统一定位即搜索」(UGS)的动作空间重构方案。它将视觉定位框直接作为检索动作的内嵌参数,使得一次函数调用就能并发携带多个目标框。这一设计从物理层面彻底打通了单轮交互内多目标并发的通路。
然而,空有架构还不够,开源社区长期缺乏「并行搜索」的训练语料。为此,研究团队设计了一套精密的合成流水线。他们首先将多类图片拼接,合成出必须同时进行定位与检索才能解答的视觉查询;接着基于图谱随机游走,构造出多约束的交集问题并严格剔除捷径解;最后,通过渐进式拒绝采样(PRS)技术,在严格的递增轮次预算下,提纯出 3 万条「零冗余」的并行行为种子数据,完美解决了模型 SFT 冷启动的难题。
在最核心的强化学习(RL)对齐阶段,HyperEyes 彻底颠覆了传统 RL 的「唯结果论」范式。传统的稀疏奖励往往会引发双重隐患:缺乏效率约束的奖励机制会纵容模型养成「冗余试错」的惰性,以牺牲推理速度为代价换取准确率;更糟糕的是,在处理长周期任务时,粗暴的结果导向会带来极其不公平的「连坐惩罚」—— 即便是一次堪称完美的中间推理过程,也会因为最终环节的失误被彻底抹杀,导致模型在复杂探索中迷失方向。

针对这一问题,团队创新性地提出了「宏观 + 微观」的双粒度效率感知强化学习框架。在宏观轨迹层面,系统引入了 TRACE(动态参考的成本效率奖励)机制。这并不是一个一刀切的步数死命令,而是一把「自我超越」的动态标尺。系统会将模型当前的工具调用表现与标尺对比,只有比标尺更高效才能获得奖励。在每个 Epoch 结束后,系统会自动用本轮表现最好、步数最少的轨迹去刷新并收紧标尺。这就像跳高比赛,横杆随着模型能力的提升越调越高,逼迫模型不断挤出水分。
而在微观 Token 层面,为了精准抢救失败轨迹中的「正确中间过程」,HyperEyes 引入了 OPD(策略内蒸馏)机制。这一机制只在轨迹最终答错时才会启动,届时会引入一个 235B 的满血版教师模型,为失败轨迹中的每一步提供稠密的 Token 级监督信号,精准打捞那些原本正确的中间规划。
这种「仅在失败时蒸馏」的非对称设计,完美避免了对学生模型「高效并发」本能的覆盖。成功时由宏观奖励主导效率,失败时由微观蒸馏托底纠偏,宏微观的严丝合缝,彻底释放了多模态大模型的并发检索天性。
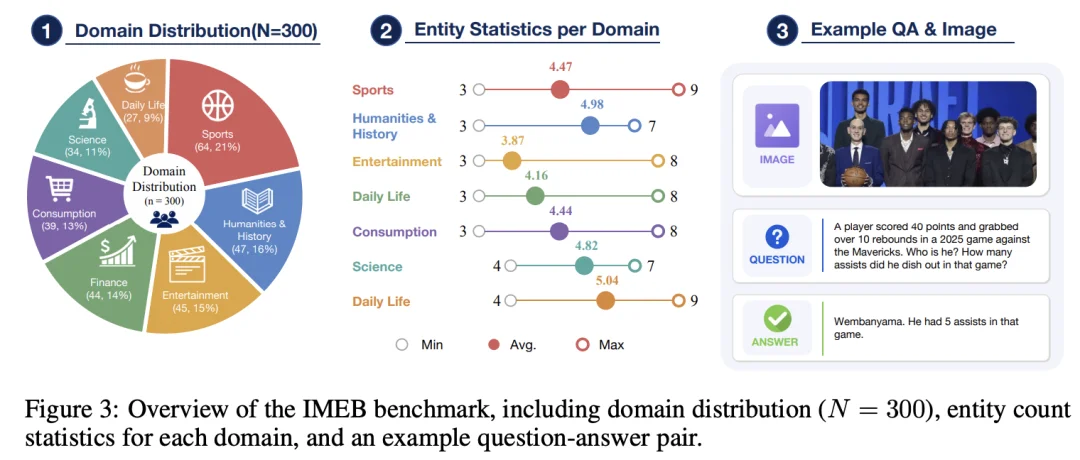
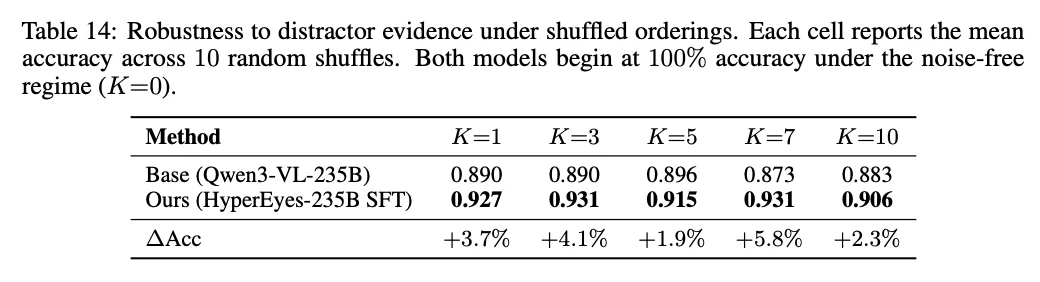
现有多模态榜单普遍存在「只看准不看快」的弊端。为了纠正这一导向,团队发布了首个包含 300 条极具挑战性多实体视觉评测基准的 IMEB (Image Multi-Entity Benchmark)。
与之配套,团队还提出了「成本感知评分」 (CAS)。该评分标准在统一标尺下,将准确率、Token 消耗和工具调用轮次进行联合评估,把传统的答案质量换算为「单位延迟下的有效信息密度」,从根本上遏制了大模型靠堆砌算力暴力刷榜的行为。
在随后的 6 大主流基准测试中,HyperEyes 展现出了极具统治力的表现,实现了准确率与效率的 Pareto 占优。全面建立开源 SOTA 并非虚言 ——HyperEyes-30B 以 64.0% 的准确率超越同量级最强开源模型 VDR 达 9.9%,而其平均工具调用轮次仅为 VDR 的不到五分之一(2.2 对比 11.6)。而其 235B 版本更是以仅 1.1% 的微弱差距逼近闭源旗舰 Gemini-3.1-Pro。
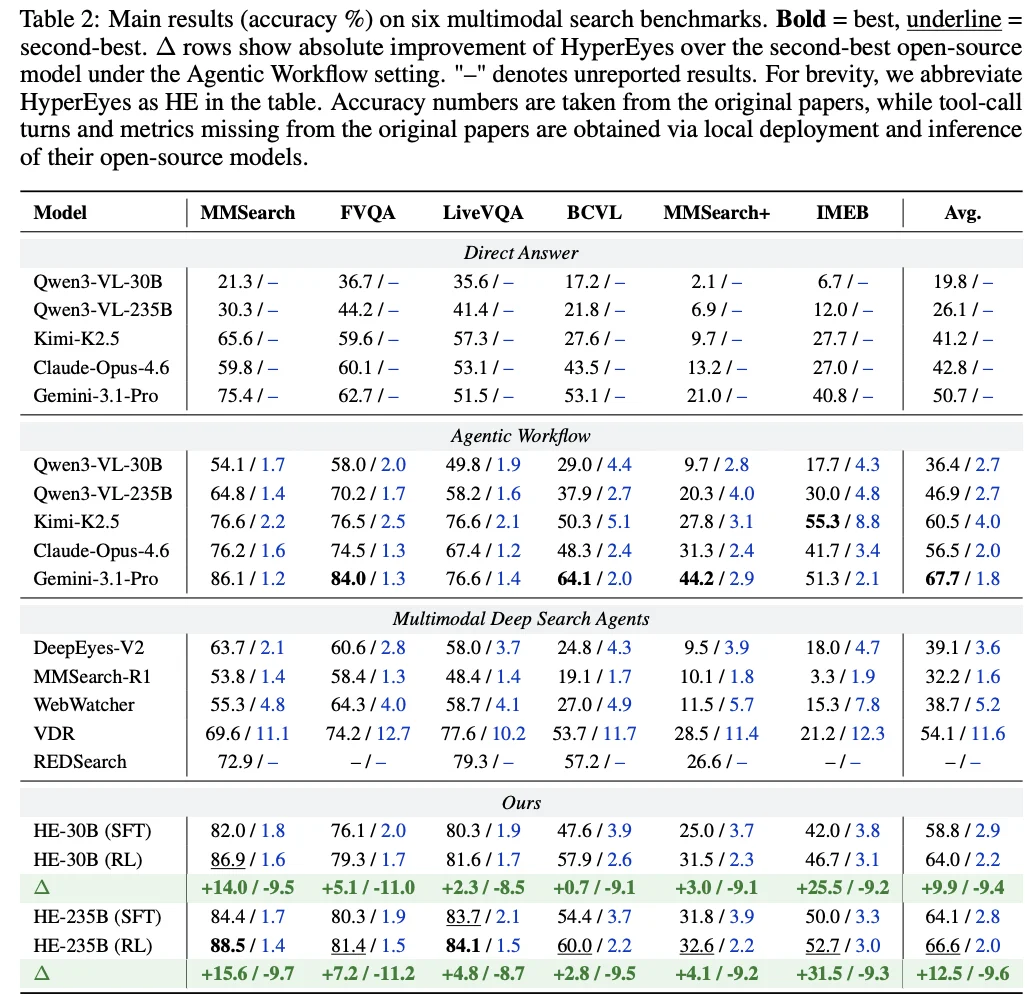
在极为严苛的 CAS 成本效率评分中,30B 版本的表现达到了次优开源模型的 7.6 倍,证明其每一单位算力输出的信息密度都极高。消融实验也证实了,这种底层的动作空间重构设计,对传统的「LLM 外挂裁剪」或「代码沙箱裁剪」构成了降维打击。
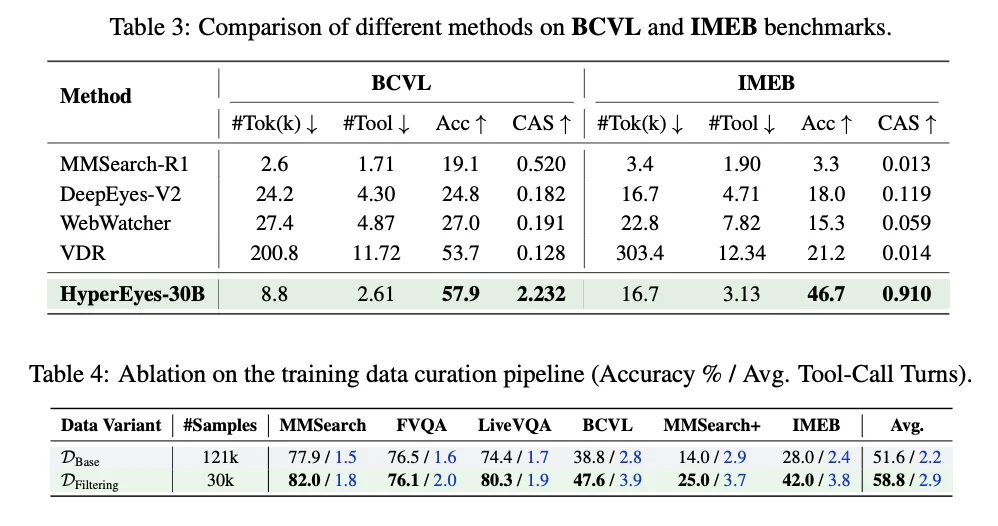
更有意思的是其面对噪声的强鲁棒性。在真假证据混合的干扰测试中,HyperEyes 这种「敢于少搜、一次看全」的并行策略,反而大幅规避了过度检索带来的幻觉陷阱。
在一个面对 6 人同框复杂问答的真实测试案例中,传统 Agent 因为「逐一裁剪 + 搜索」的笨拙逻辑将流程拖拽至 12 轮,最终因噪声累积而答错;而 HyperEyes 首轮即并发定位并检索了全部 6 人,仅用 3 轮便给出精准答案,直观地展现了什么叫「一次出手,看清全局」。

长期以来,大家普遍认为多模态搜索必须通过串行加深来保证准确度,而 HyperEyes 打破了这一固有惯性。它用翔实的实验证明了,在 Agent 训练中,「准确率」与「效率」完全可以协同进化。
随着多模态 Agent 逐渐步入电商比价、视觉检索、实时交互等真实的高并发业务场景,从「搜得更深」转向「搜得更宽」,必将成为下一代智能体角逐的核心竞争力。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
