# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。
然而,当前大多数 TAD 方法仍然遵循一种 one-for-one(OFO)范式:每来一个新数据集,就要重新训练一个专属检测器,甚至重新调参、重新选择预处理方式。这不仅带来高昂的计算和运维成本,也让模型难以泛化到未知领域。
那么,表格异常检测能否像大模型一样,训练一次,就能迁移到不同领域的数据表上,实现真正的 one-for-all(OFA)?
近期,来自 Griffith University 和 Tongji University 的团队提出了 OFA-TAD,迈出了通用表格异常检测的重要一步。该方法将 TAD 从传统的 one-for-one(OFO)推进到 one-for-all(OFA)范式:模型只需在多个源数据集上训练一次,便可直接迁移到未见过的目标数据集,无需目标域微调或重新训练。
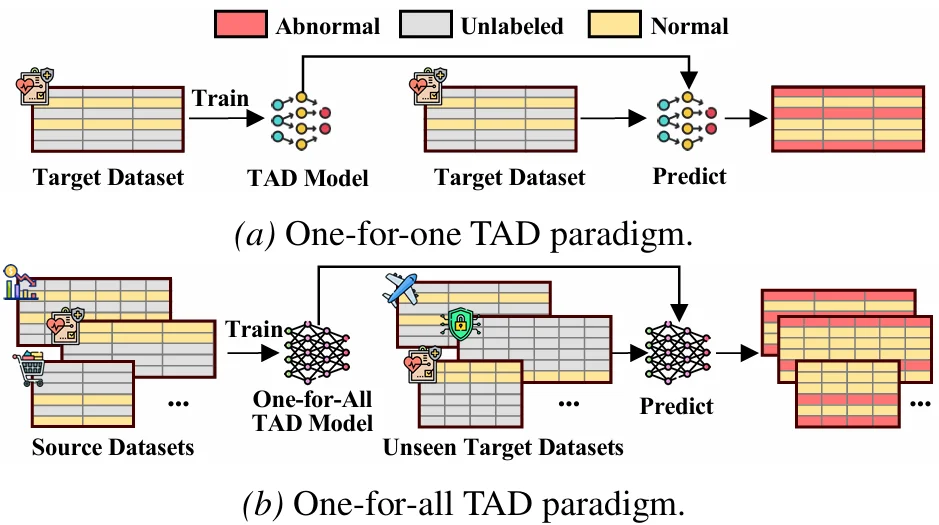
图注:传统 OFO 范式与 OFA-TAD 所追求的 OFA 范式对比。

传统 TAD 方法通常在单个数据集内训练和测试。无论是经典的 Isolation Forest、LOF、KNN,还是近年来的 AutoEncoder、DeepSVDD、MCM、DRL、DisentAD 等深度方法,它们大多默认每个数据集都有自己的训练流程。
这种范式在单一数据集上可能表现不错,但在真实部署中会遇到两个核心问题:
OFA-TAD 试图回答一个更具挑战性的问题:能否训练一个通用的表格异常检测器,在面对来自医疗、金融、图像特征、网络安全等不同领域的新数据表时,仍然能够即插即用地发现异常?
这一问题并不简单。表格数据天然存在「语义鸿沟」:不同数据集的特征维度、特征含义和数值分布都可能完全不同。医疗数据中的异常可能是异常血压或心率,金融数据中的异常则可能是异常交易金额或账户行为。直接对齐原始特征语义,几乎不可行。
OFA-TAD 的核心洞见是:跨领域可迁移的异常信号,不应依赖具体特征含义,而应来自更通用的邻域结构。
无论是异常病人记录、欺诈交易,还是异常网络行为,它们往往都有一个共同点:相对于正常样本,它们更「孤立」,也就是与局部邻居的距离模式更不寻常。
因此,OFA-TAD 不直接学习原始表格特征,而是将每个样本表示为其 Top-K 近邻距离序列,即「邻居距离画像」。这种表示具有两个优势:
换句话说,OFA-TAD 将不同领域的数据表,统一转化为一种可比较的「距离语言」。
仅使用一种距离空间仍然不够。表格数据对预处理方式高度敏感:标准化、归一化、分位数变换等操作,都会改变样本之间的邻域关系。某些异常在标准化空间中更明显,另一些异常可能在 MinMax 或 Quantile 空间中更容易被发现。
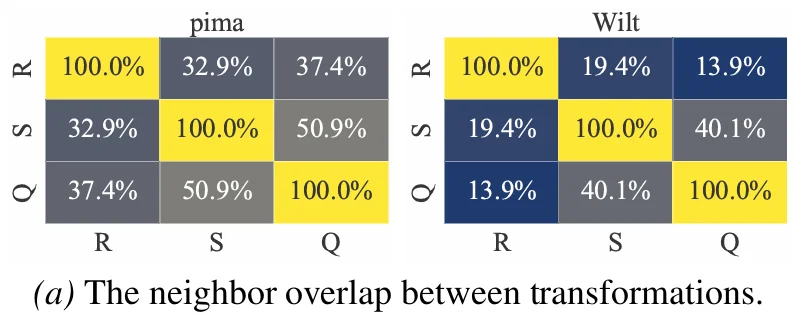
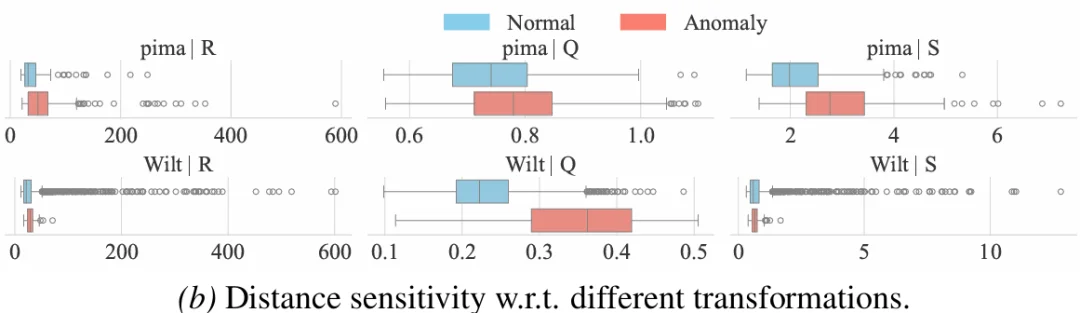
图注:不同特征变换会显著改变近邻结构与异常可分性。R:Raw,S:Standardized,and Q:Quantile。
为了解决这一问题,OFA-TAD 构建了多个由不同特征变换诱导的度量空间,例如 Raw、Standardized、MinMax、Quantile 等。对于同一个样本,模型会在每个视角下提取 Top-K 邻居距离序列,并通过分位数归一化将不同数据集中的距离尺度映射到统一范围。
这样,OFA-TAD 既避免了对某一种预处理方式的依赖,也能捕获互补的异常证据。
不同视角并非同等可靠。如果简单拼接或平均多个距离视角,反而可能让强信号被弱视角稀释。
为此,OFA-TAD 进一步引入了 Mixture-of-Experts(MoE)评分网络:
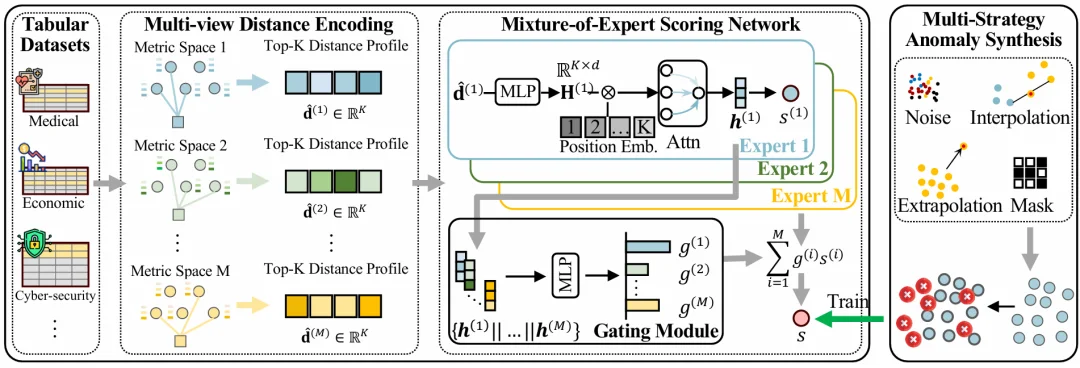
图注:OFA-TAD 的整体框架:多视角距离编码、MoE 自适应评分,以及多策略伪异常合成。
这种设计使得 OFA-TAD 不需要提前知道某个目标数据集最适合哪种预处理方式,而是能在推理时自动选择更可靠的距离证据。
表格异常检测通常处于 one-class setting:训练阶段只有正常样本,真实异常极少甚至完全不可见。为了在不破坏这一设定的前提下提供监督信号,OFA-TAD 设计了多策略伪异常合成机制。
具体而言,模型通过四类方式生成多样化的伪异常:
这些伪异常与正常样本共同构成训练信号,帮助模型学习更稳健、可迁移的异常决策边界。
实验中,OFA-TAD 在 7 个源数据集上训练一次,并在 34 个来自 14 个领域的数据集上进行评测。与之对比的 9 个代表性基线方法,包括经典方法 IForest、LOF、KNN,以及深度方法 AE、DeepSVDD、LUNAR、MCM、DRL、DisentAD。
值得注意的是,对比方法按照传统 OFO 范式在每个目标数据集上分别训练,而 OFA-TAD 不在目标数据集上重新训练或微调,仅使用目标数据集的正常训练样本作为推理时的上下文,用于近邻检索和距离归一化,并且使用固定的相同一组超参数在所有目标数据集上进行测试。
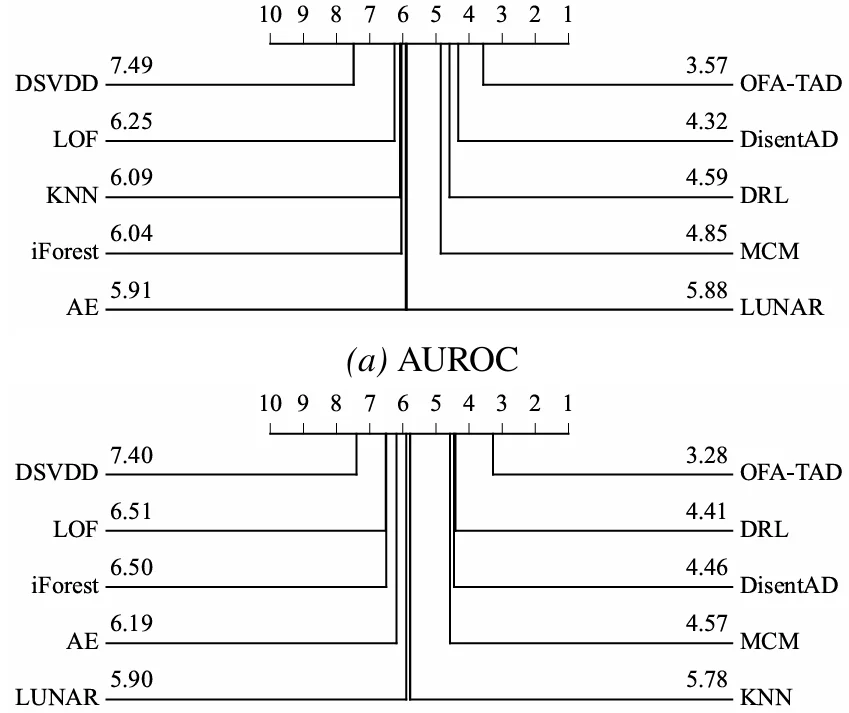
1)整体性能:一次训练,跨 34 个数据集稳定领先
在这一更严格的设置下,OFA-TAD 仍然取得了最优的整体表现。如下图所示,它在 AUROC、AUPRC 等指标上的平均排名均保持领先。
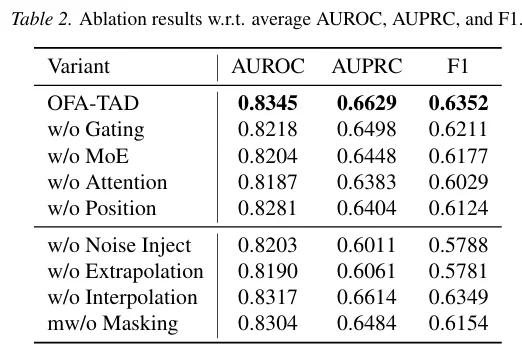
2)消融实验:多视角、MoE 与注意力缺一不可
消融实验进一步验证了各模块的重要性。如下图所示,去掉门控融合、MoE 专家、注意力池化或位置编码都会带来性能下降,其中注意力池化的影响尤为明显,说明对邻居距离证据进行自适应加权,是捕获稀疏异常信号的关键。
同时,多策略伪异常合成也提供了互补监督信号。移除任意一种合成策略都会造成性能下降,说明真实异常的形态复杂多样,需要通过多种伪异常模式共同刻画。
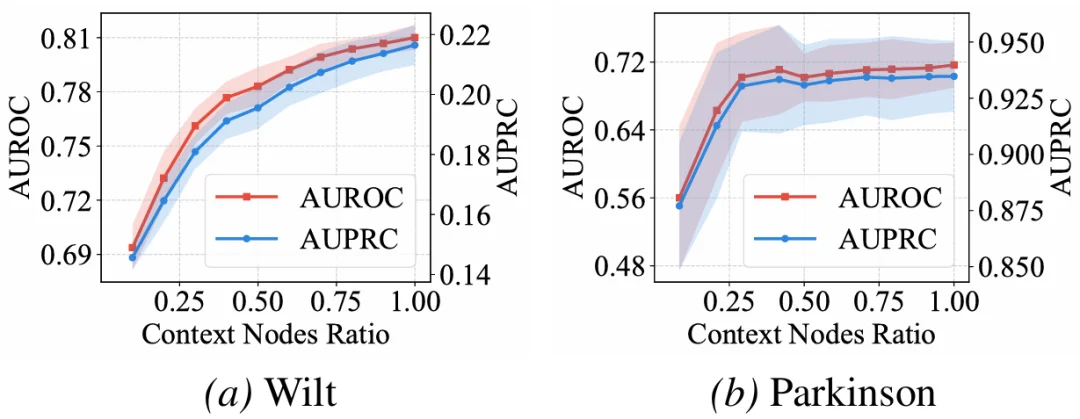
3)上下文鲁棒性:少量正常样本也能支持即时推理
OFA-TAD 还展现出良好的上下文鲁棒性。即使目标数据集中只有一小部分正常样本可作为上下文,模型仍能进行稳定的即时推理;随着上下文样本增多,性能进一步提升并逐渐趋于饱和。
这表明 OFA-TAD 可以在有限的正常样本下快速建立目标域邻域结构,从而完成 on-the-fly 异常检测。
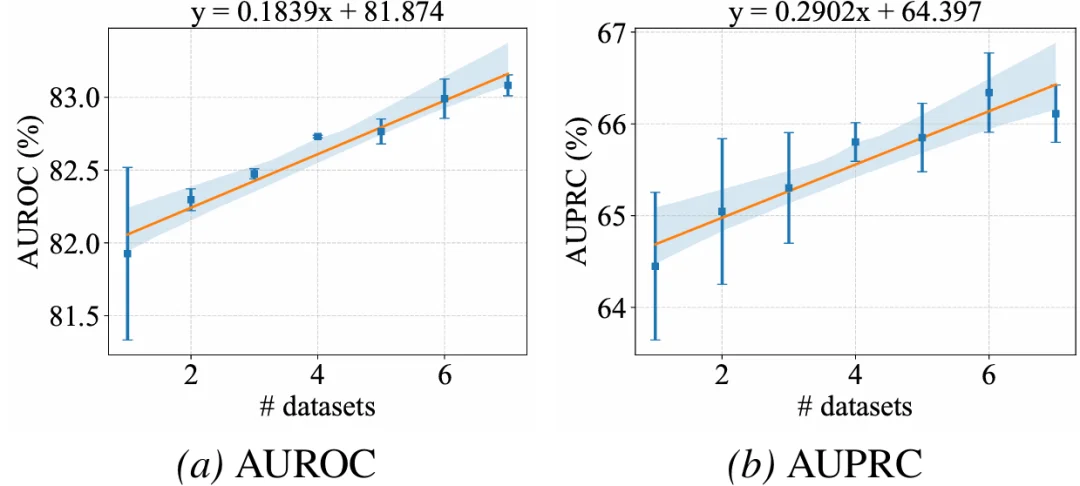
4)dataset-specific scaling
更进一步,随着源数据集数量增加,OFA-TAD 的迁移性能呈现稳定提升趋势。这说明通用表格异常检测具备类似「dataset-specific scaling」的潜力:预训练数据越丰富,模型越可能学到跨领域的异常检测规律。
OFA-TAD 为表格异常检测从 one-for-one 向 one-for-all 范式转变提供了一个初步的尝试,并在无需目标域微调的跨域迁移场景下展现出了极具潜力的性能。
未来,通用表格异常检测仍有广阔的探索空间。通过引入更大规模的预训练数据集、设计更先进的训练方法,以及更深度的上下文信息利用,通用 TAD 模型有望进一步降低工业部署成本,为医疗、金融、安全等高价值场景提供更加灵活可靠的异常检测基础设施。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
