# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026 年 5 月的红杉 AI Ascent 大会上,英伟达具身智能掌门人 Jim Fan 用短短 20 分钟的演讲《Robotics: Endgame》,给过去三年的机器人技术路线画上了一个引人深思的句号。
他直言不讳地指出,当下主导具身智能的 Vision-Language-Action (VLA) 模型,本质上是 “LVA”—— 把最大的参数量倾注在语言上,导致模型在编码物理常识和动作执行上常常 “翻车”。Jim Fan 给出的破局之道,是复刻大语言模型的 “伟大的平行(The Great Parallel)”:与其模拟下一个文本 Token,不如让机器人去模拟下一个物理世界状态。

Jim Fan 押注的这条 “先预测世界,再生成动作” 的新路,正是当下具身智能领域最炙手可热的下一代范式 —— 世界动作模型(World Action Models,简称 WAM)。
虽然 WAM 正在迅速成为各大顶尖实验室的核心发力点,但业界至今仍然缺乏对它的统一标准和系统梳理。近期,复旦大学可信具身智能研究院,上海创智学院,新加坡国立大学发表了首篇 WAM 的详细综述。

这篇综述的目标,正是给这个快速形成中的前沿方向画出一张清晰的 “导航地图”:系统梳理 WAM 的定义、架构、训练数据、评测方式和开放问题,帮助读者快速理解这个新兴领域为什么重要、难在哪里、接下来又将走向何处。
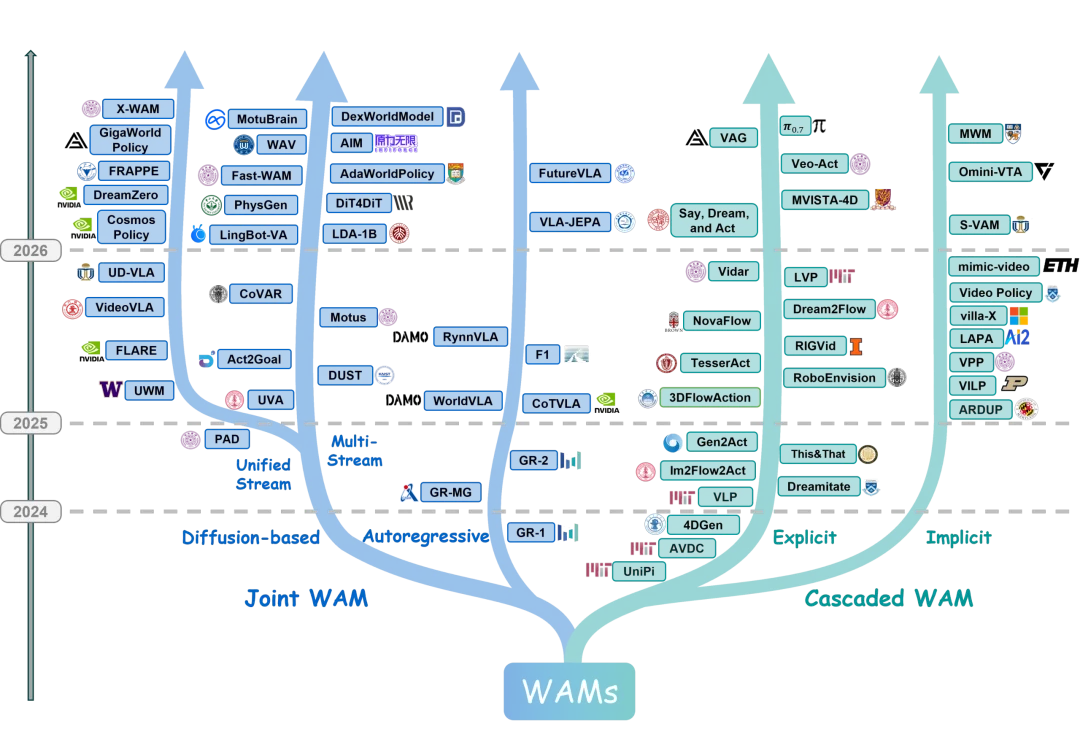
图 1. 世界动作模型(WAM)的发展脉络图
1. 世界动作模型(WAM)到底是什么?
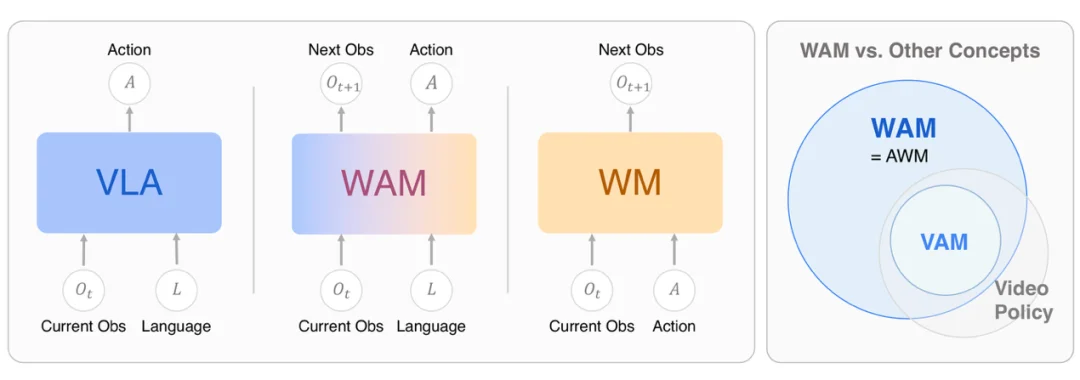
图 2. WAM 概念定义与相关范式对比
过去两年,VLA 几乎成了具身智能的代名词。从 RT-2 到 OpenVLA,视觉、语言和动作的统一让机器人能够理解开放词汇指令。但 VLA 存在一个根本性的盲区:它只关心 “当前输入对应什么动作”,而不直接约束模型去预测 “执行动作后的未来状态”。 这导致它在复杂的物理交互场景下短板暴露无遗。
WAM 正在试图填补这个缺口。一个简洁的定义是:World Action Model 是把未来状态预测与动作生成统一建模的具身基础模型。它不只是回答 “下一步做什么”,还要建模 “这样做之后世界会怎样”。
视觉语言动作模型(VLA)、世界模型(WM)、世界动作模型(WAM)三类范式的核心差异,可以用一组公式概括:
在 WAM 出现之前,世界模型其实已经开始以 “外挂” 的形式帮助 VLA(即 WM for VLA),主要用于改进模仿学习、支持强化学习或扩展策略评测。
但 WAM 的关键进化在于,它把这种 “外部辅助” 推进到了模型结构内部:未来状态预测不再只是训练的辅助工具,而是直接参与动作生成。当一个模型同时学习 “世界会如何变化” 和 “应该如何行动” 时,它就不再是被世界模型增强的 VLA,而是一个真正的 World Action Model。
从架构演进的角度来看,当前的世界动作模型(WAM)在设计思路上主要分为两大阵营:Cascaded WAM(级联式) 与 Joint WAM(联合式)。前者采用解耦策略,主打 “先想象,再行动”;后者则追求大一统,试图将 “预测世界” 与 “生成动作” 彻底融合进同一个大脑。
2.Cascaded WAM:
先想象,再行动的 “两步走” 路线
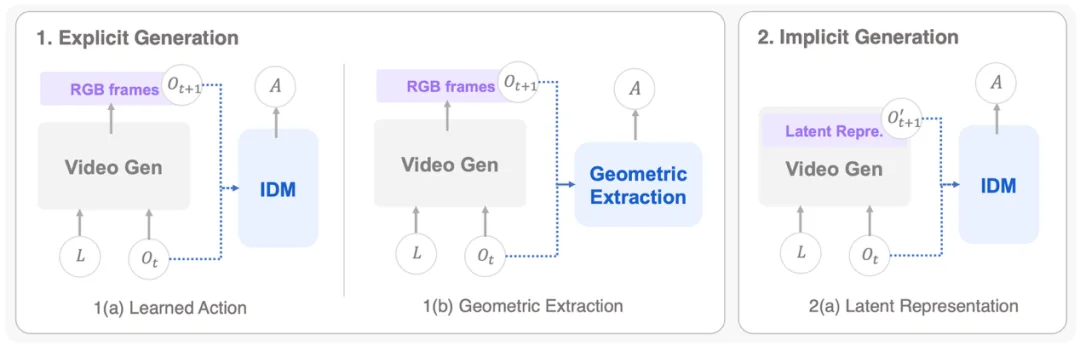
图 4. Cascaded WAM 结构图:包含显式生成(分为 Learned Action 和 Geometric Extraction)和隐式生成(Latent Representation)两种模式
Cascaded WAM 把世界预测和动作生成拆分为两个独立阶段:先由世界模型 “脑补” 出一个未来的预期计划,再由下游独立的动作模型将这个计划解码为机器人的可执行动作。
根据中间这层 “预期计划” 形态的不同,Cascaded WAM 分为两条路线:
3.Joint WAM:
把世界预测写进模型内部
如果说 Cascaded WAM 是把两个模型串联打配合,那么 Joint WAM 则是把未来状态预测和动作生成彻底融合进同一个模型框架中。这也是目前各家顶尖实验室最看好、最具潜力的端到端方向。
按照底层生成范式的不同,Joint WAM 内部又分化出两条主流路线:
路线一:自回归(Autoregressive)
将视觉状态、未来状态和动作全部组织成 Token 序列,利用 Transformer 按时间顺序逐步预测。它的核心优势是与现有 LLM(大语言模型)的范式天然兼容,可以充分复用大模型的上下文能力;劣势在于顺序生成速度较慢,且在长序列中容易产生误差累积。
路线二:扩散生成路线(Diffusion-based)
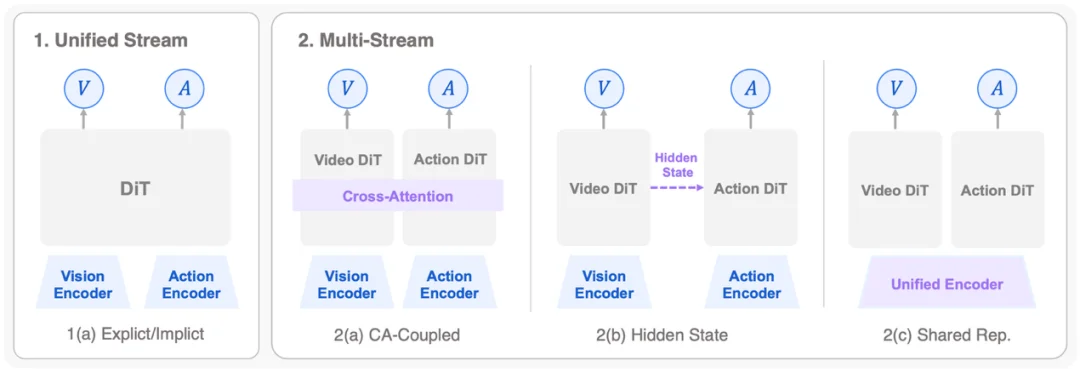
图 5. Diffusion-based Joint WAM 架构图:分为 Unified Stream 和 Mutli-Stream,其中 Multi-Stream 通过 Cross-Attention Coupled、Hidden-State Coupling 和 Shared Representation 融合
用扩散模型或 flow matching 联合生成未来状态和动作。它更适合连续、多峰、需要平滑控制的物理动作,但实时控制的推理成本仍是一大挑战。为了在联合生成与推理效率间取得平衡,主要衍生出两大架构策略:
4.WAM 需要什么数据?——
四类核心数据源的协同融合
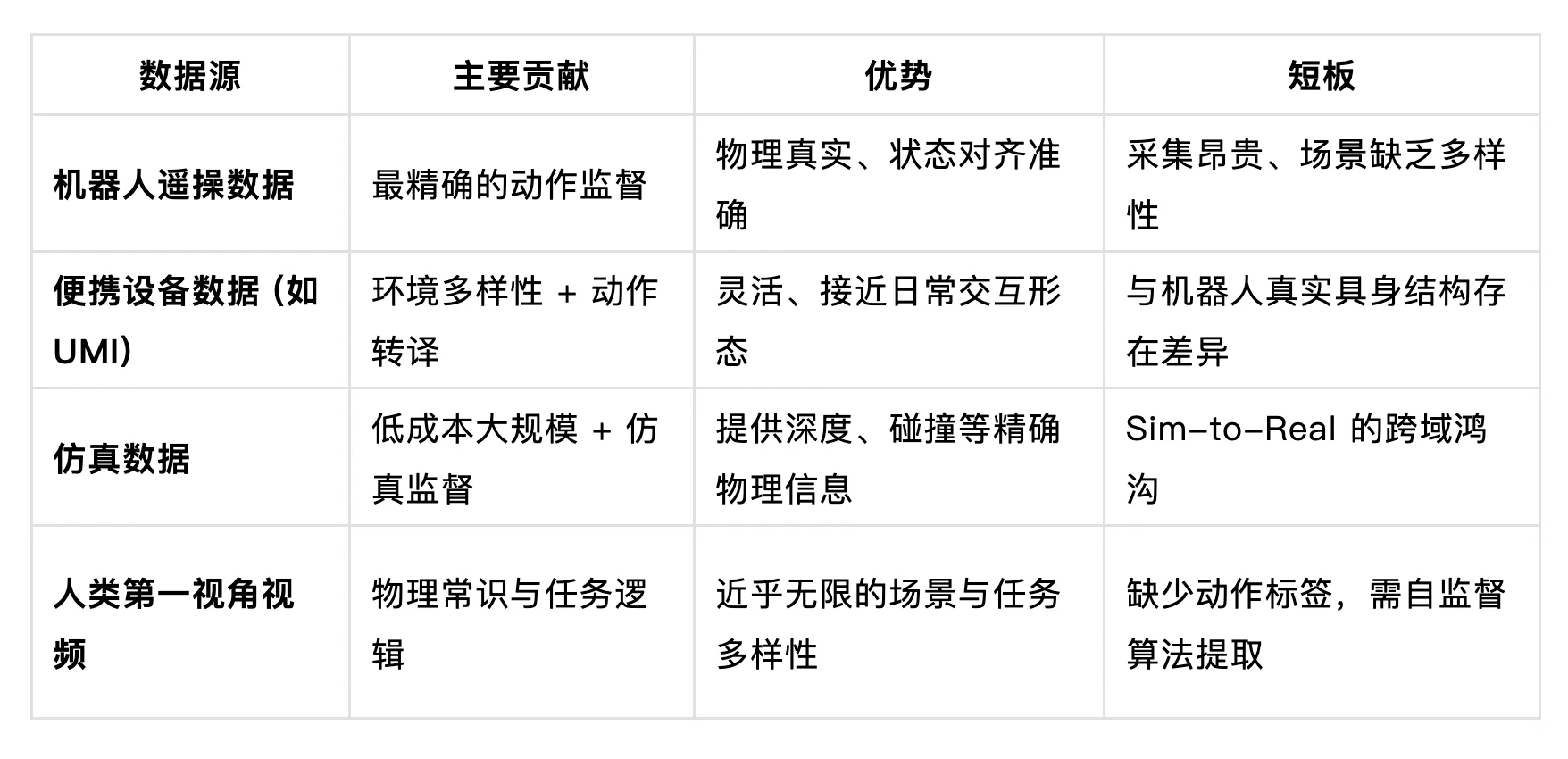
过去的 VLA 主要依赖带有精确动作标注的真实机器人轨迹数据,而 WAM 的数据获取版图迎来了维度的跨越:它不仅可以利用 “状态 - 动作” 强对齐的控制数据,更能直接吸收海量无动作标注的互联网原始视频,从中自主挖掘并学习物理规律。
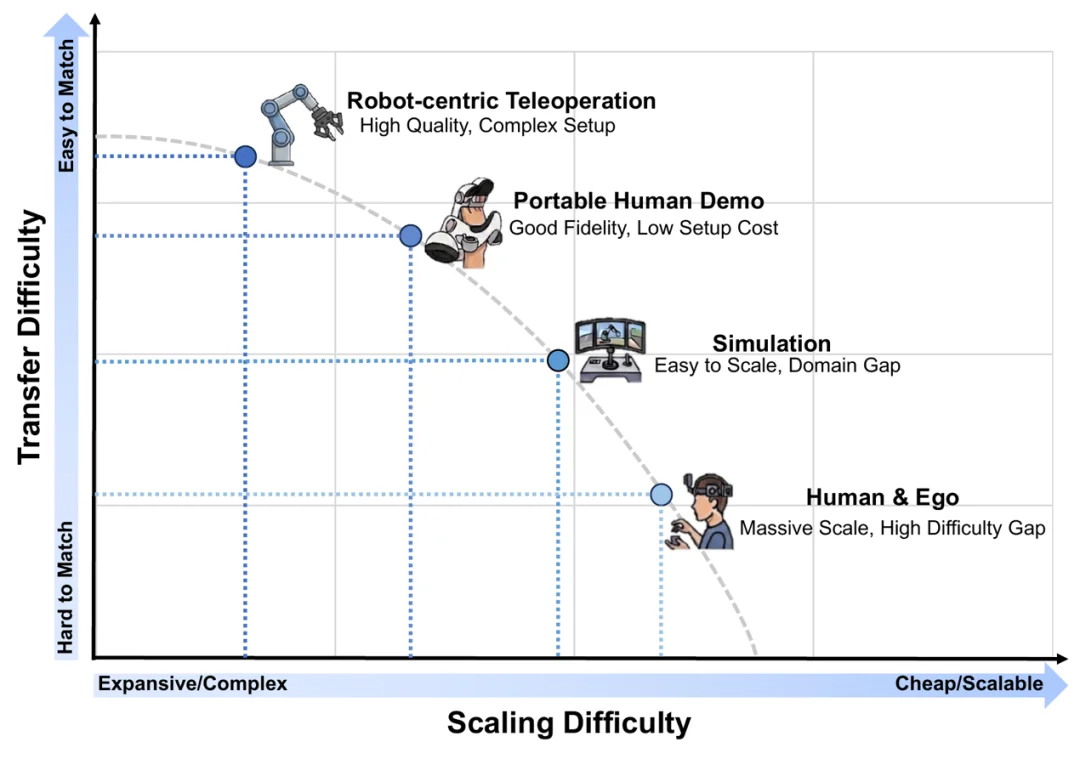
图 6. WAM 训练数据版图:按 Transfer Difficulty 与 Scaling Difficulty 展示机器人遥操作、便携式人类示范、仿真、人类 / 第一视角视频等数据来源。
5. 如何评测 WAM?——
不止看 “像不像”,更要看 “能不能用”
评测 WAM 极具挑战性,因为它必须同时跨越两个维度的考核:世界预测能力(未来是否合理)与动作策略能力(控制是否有效)。
6. 挑战与未来:
WAM 下一个突破点在哪里?
尽管 WAM 展现出了通向具身智能终局的巨大潜力,但要将其从实验室原型真正推向物理世界的规模化部署,仍需跨越以下核心挑战:
7. 结语
WAM 的意义,绝不只是给 VLA 挂上一个预测插件,而是重新定义了具身智能的第一性原理:“在行动之前,先理解行动将如何改变世界。”
过去的机器人基础模型在追问 "What should I do next?";而 WAM 进一步拷问灵魂:"What will happen if I act, and how should I act to make the right future happen?"
如果 VLA 打通了语言与动作的桥梁,那么 WAM 则完成了动作与物理反馈的闭环。正如 Jim Fan 在红杉大会上留下的断言 —— 机器人终局的齿轮已经转动。在这场 “伟大的平行” 中,WAM 无疑是最关键的一块拼图。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


