# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。
但自动驾驶需要的不只是 “看懂”。车辆真正要做的是在下一秒给出动作,是否减速、轨迹是否偏移、继续跟车还是选择绕行。因此关键问题变成了大模型的理解能力,如何真正服务于驾驶决策和轨迹规划?

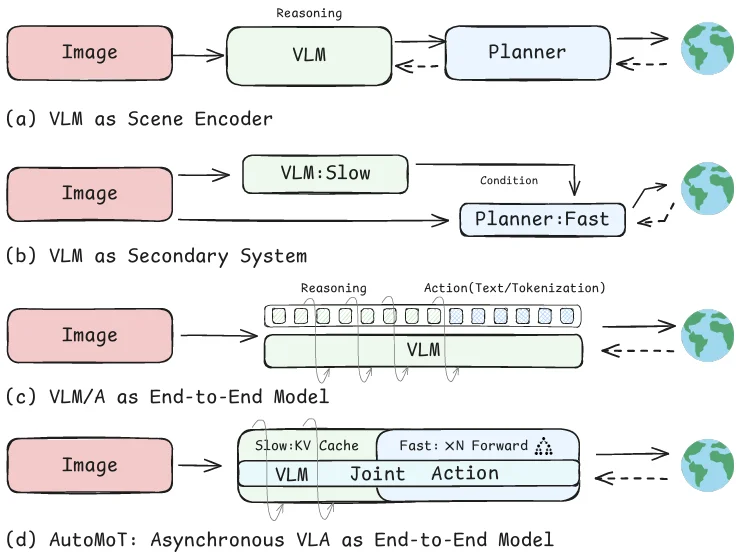
图中总结了近年来该领域代表性工作的探索方向:一种是把 VLM 放在前面,当作场景编码器,先理解图像,再把信息交给 planner。这种方式分工清楚,但理解和规划仍然是分开的。另一种是把 VLM 作为辅助模块,让它输出风险判断、驾驶意图或条件信号,实时控制仍由 planner 完成。这样对原系统改动较小,但也容易浪费大模型能力:复杂推理最后被压缩成少量提示,很难完整转化为动作。
还有一种更直接的做法,是把 reasoning 和 action 放进同一个 VLA 模型里。这样理解和动作被统一起来,但也带来实时性问题:高层推理可以慢,轨迹规划必须快。如果两者始终同步执行,大模型推理延迟就会限制系统反应速度。
针对上述问题,来自南洋理工大学 AutoMan Lab、哈佛大学和小米汽车的研究团队提出了 AutoMoT,一种面向端到端自动驾驶的统一 Vision-Language-Action 模型,将场景理解、轨迹规划与动作决策统一到同一潜在空间中,并通过异步推理实现 “低频理解、高频行动”。具体而言,理解模块负责高层语义建模,动作模块负责决策与轨迹规划,二者通过layer-wise shared attention 在模型内部进行直接交互。
实验结果表明,AutoMoT 在 Bench2Drive 和 nuScenes 两个基准上均取得了 SOTA 性能。其中,在 Bench2Drive 闭环评测中,AutoMoT 达到 87.34 DS / 70.00% SR,加入 Action Refiner 后的 AutoMoT+ 进一步提升至 89.42 DS / 74.09% SR;在 nuScenes 开环规划评测中,其平均碰撞率仅为 0.07%, 平均 L2 为 0.32。该工作已被 ICML 2026 正式接收。

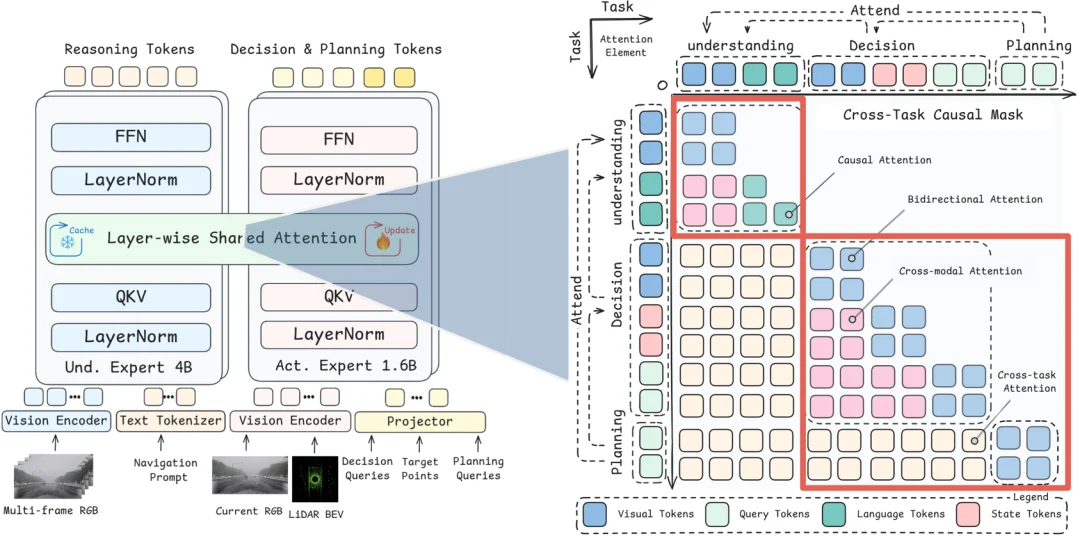
理解、决策与规划的统一
AutoMoT 由两个专家组成:Understanding Expert(UE) 和 Action Expert(AE)。
如上图左侧所示,UE 是一个 4B 级 Qwen3-VL backbone,输入多帧 RGB 图像和导航提示,生成 reasoning tokens;AE 是约 1.6B 参数的动作专家,输入当前 RGB、LiDAR BEV、decision queries、target points 和 planning queries,生成决策与规划 tokens。
关键在于 UE 和 AE 不是传统 hierarchical 式串联。AutoMoT 在每一层引入 Layer-wise Shared Attention:UE 提供高层场景理解,AE 在生成动作时可以访问这些中间表示。这样,UE 的场景理解不再只限于外部文本解释,而是直接参与动作生成。
上图右侧展示了 AutoMoT 的 attention 设计。Understanding、Decision、Planning 三类任务通过 cross-task causal mask 建立明确的信息流:Decision 可以读取 Understanding 的场景理解信息,Planning 则可以同时读取 Understanding 和 Decision 的信息;任务内部仍保持双向注意力。因此,Action Expert 并不是从零开始学习规划,而是在基座模型的先验知识的基础上学习决策与轨迹生成。模型先理解场景,再基于理解形成决策,最后结合理解与决策生成规划,使轨迹预测不再只是几何拟合,而是由场景语义和驾驶意图共同驱动。
异步推理,KV Cache 复用场景理解
AutoMoT 的异步推理主要用于解决闭环驾驶中的实时性问题。动作规划需要高频刷新,因为自车状态和周围交通参与者都在不断变化;而高层场景理解具有一定时间连续性,例如前方施工区域、慢速车辆或路口拓扑关系,并不会在相邻几个控制周期内完全改变。
因此,AutoMoT 让 UE 周期性更新高层理解,AE 则以更高频率生成动作。UE 完成一次理解后会保存对应的 KV cache,AE 在后续多个动作步中可以直接基于这些 cached states 进行多步决策和轨迹规划,而无需每一步都重新执行完整的大模型推理。
这说明 AutoMoT 并不是削弱大模型推理,而是重新定义其参与控制的方式:高层理解仍然影响动作生成,但不再阻塞每一次轨迹刷新。
闭环和开环结果
在 CARLA Bench2Drive 闭环评测中,AutoMoT 取得了 87.34 DS / 70.00% SR,超过 SimLingo 的 85.07 / 67.27。在加入 Action Refiner 后,AutoMoT+ 进一步提升至 89.42 DS / 74.09% SR,达到当前 SOTA 水平。这表明动作细化模块能够进一步提升规划质量和任务成功率,也体现了 AutoMoT 在完整路线执行中的闭环驾驶能力。
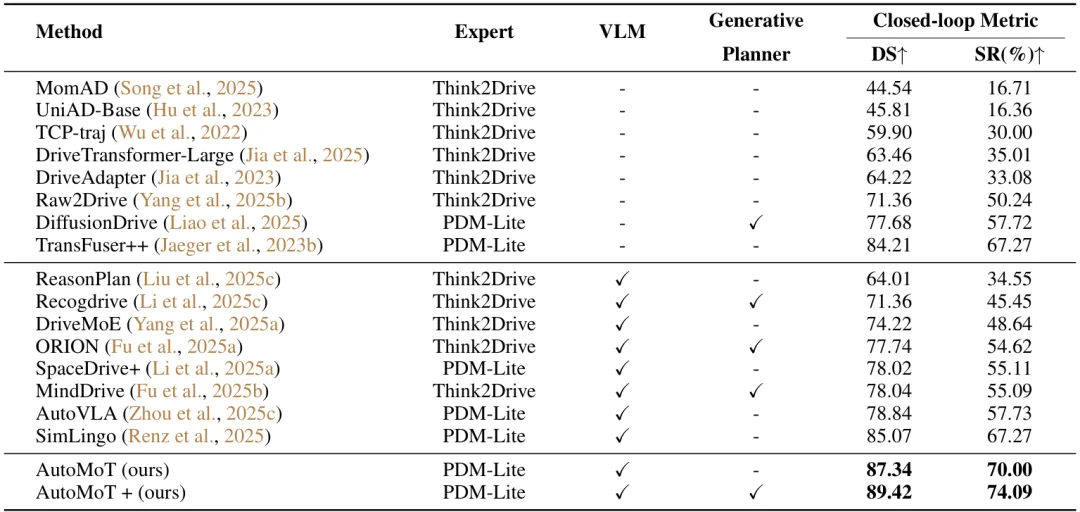
在 nuScenes 开环规划中,AutoMoT 的 L2@1s / 2s / 3s 分别为 0.14 / 0.29 / 0.54,平均 L2 为 0.32;碰撞率分别为 0.01% / 0.06% / 0.15%,平均碰撞率仅为 0.07%,在安全相关指标上达到当前 SOTA 水平。这说明 AutoMoT 不仅能够保持较低的轨迹误差,也能生成更安全的规划结果。
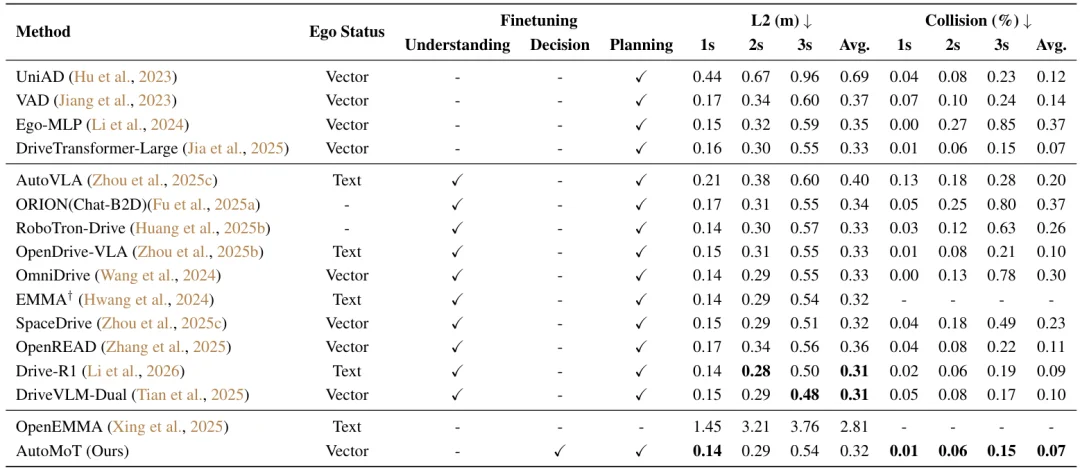
重新思考基座模型的通用能力到底要不要完全 tailor 到自动驾驶领域?
AutoMoT 还讨论了一个容易被忽略的问题:预训练基座模型进入自动驾驶后,是否需要整体微调成驾驶专用模型?在 AutoMoT 中,保留 Understanding Expert 的预训练能力并不是单纯为了节省算力,而是因为随着基座模型能力不断增强,它们已经具备很强的通用场景理解、视觉语义建模和复杂关系推理能力,并在自动驾驶场景理解任务中展现出 SOTA 水平。
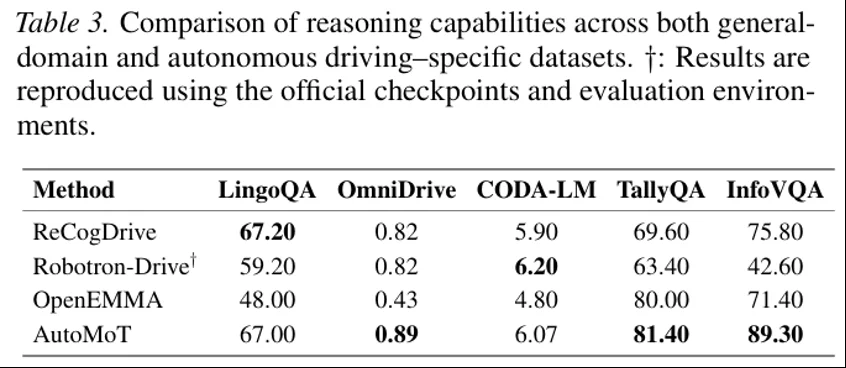
图第一组实验比较了 AutoMoT 在自动驾驶和通用任务上的 reasoning 能力。AutoMoT 在 LingoQA 上达到 67.00,接近 ReCogDrive 的 67.20;在 OmniDrive 上达到 0.89,高于 ReCogDrive 和 Robotron-Drive 的 0.82;在 CODA-LM 上达到 6.07。同时,它在 TallyQA 和 InfoVQA 等通用任务上分别达到 81.40 和 89.30。这说明,在不完全专门化 backbone 的情况下,AutoMoT 仍然能保持较好的驾驶场景理解和通用推理能力。
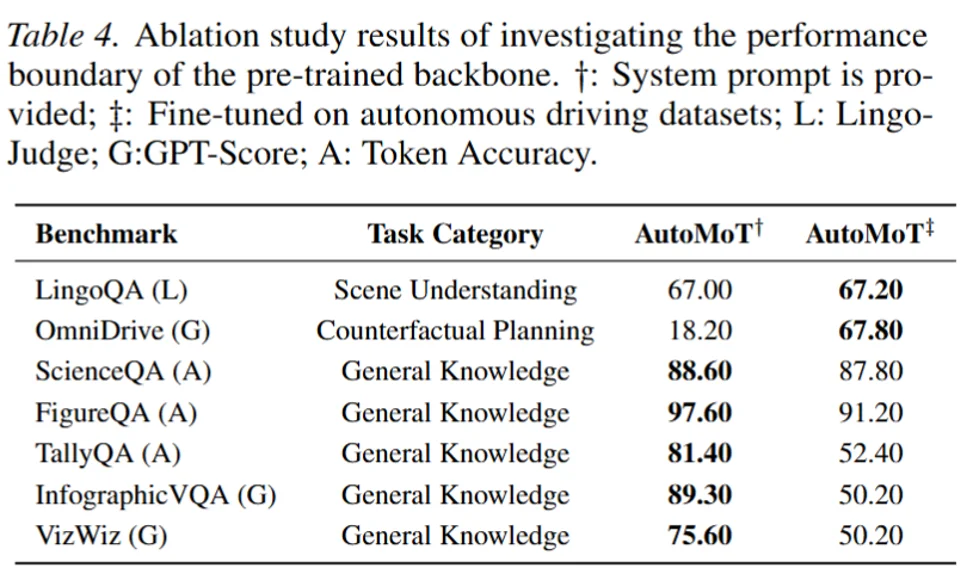
第二组实验进一步说明,fine-tuning 的收益并不均匀。对于 LingoQA 这类场景理解任务,微调几乎只带来边际提升,分数从 67.00 增至 67.20;但在 OmniDrive 这类更接近规划和动作层的任务上,提升非常明显,从 18.20 增至 67.80。这表明自动驾驶中真正需要强领域适配的部分,更多集中在如何把场景理解转化为决策和动作,而不是基础视觉语言理解本身。
但整体微调 backbone 也会带来代价。微调后,TallyQA 从 81.40 降到 52.40,InfographicVQA 从 89.30 降到 50.20,VizWiz 从 75.60 降到 50.20。这些结果说明,如果把整个基座模型深度改造成驾驶专用模型,可能会削弱其原本的通用理解和复杂推理能力。
因此,AutoMoT 采用了更明确的分工:UE 保留预训练 VLM 的通用场景理解能力,AE 则专门学习自动驾驶中的决策、规划和动作生成。需要强调的是,这并不是否定 fine-tuning 的价值,而是认为不同能力应当在更合适的模块中进行适配:高层理解能力由 UE 保留,action-level adaptation 则主要由 AE 完成,从而避免整体微调可能带来的通用能力退化。
AutoMoT 的核心并不是让 VLM 直接接管驾驶,而是在自动驾驶 VLA 系统中重新组织 “理解” 和 “行动” 的关系。
因此,AutoMoT 选择保留 UE 的通用理解能力,将自动驾驶中的动作学习主要交给 AE 完成。两者通过 layer - wise shared attention 连接,使 AE 在生成决策和轨迹时能够直接利用 UE 的中间表示,而不是仅仅接收一段外部文本解释。与此同时,异步推理与 KV cache 将完整 VLM 前向从每个动作周期中解耦出来,从而降低实时控制中的计算压力。
AutoMoT 提供了一个关于智能驾驶基座模型适配的新视角。将整个基座模型深度适配到驾驶领域固然有其优势,但也往往伴随着更高的标注、人力和算力成本。AutoMoT 的 SOTA 性能则展示了另一种更高效的可能:保留基座模型强大的通用场景理解能力,同时将驾驶相关的决策与规划能力交由专门的动作专家学习,并通过紧凑的跨模块注意力机制实现二者之间的高效协同。这样的设计在保持强性能的同时,也为面向真实部署的 VLA 系统提供了一条更具可扩展性的路径。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
