# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
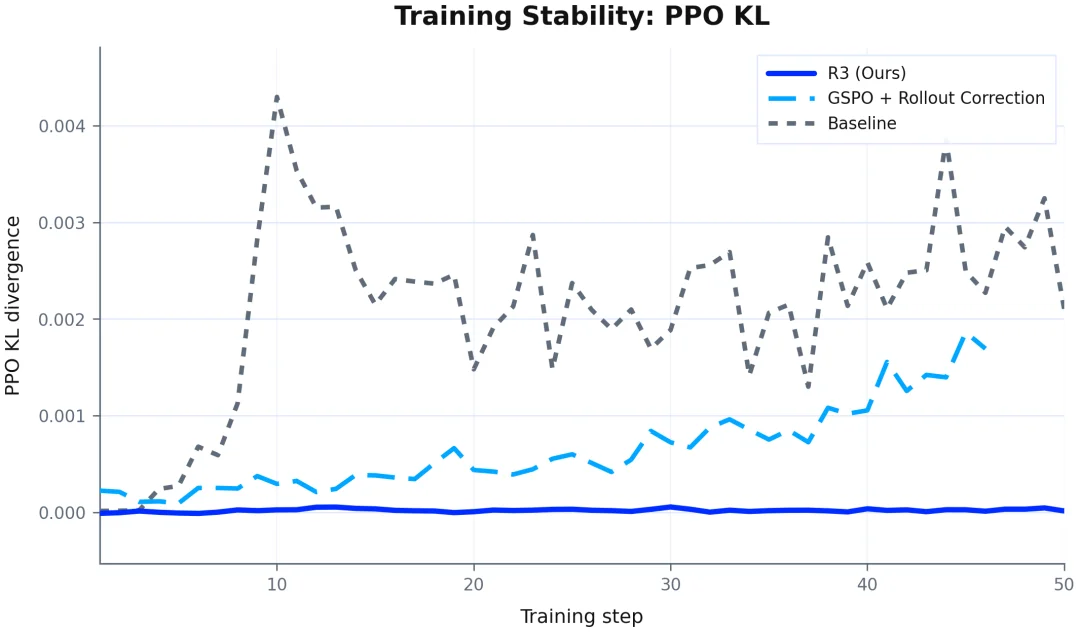
最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。
在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。
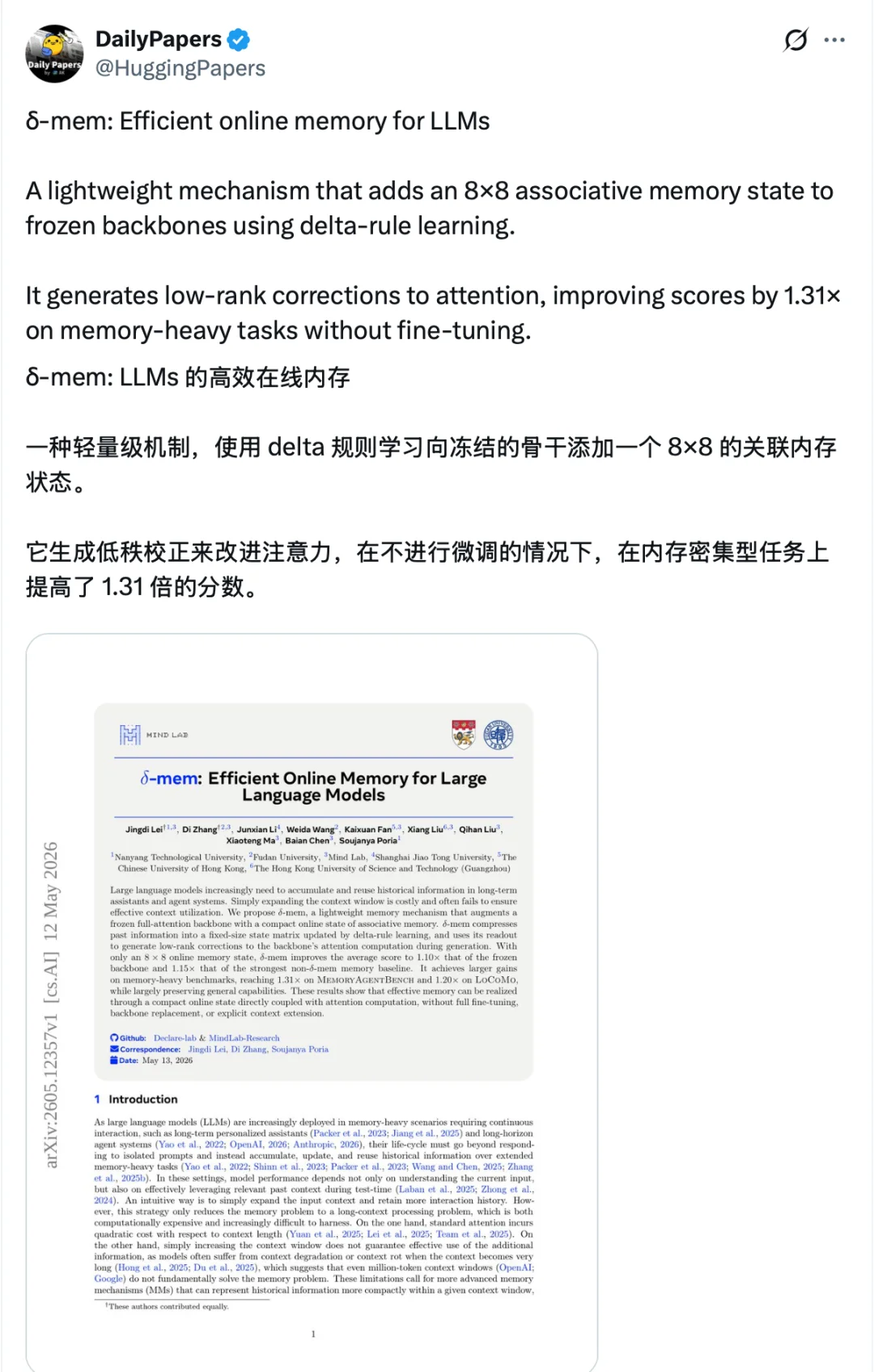
链接:https://x.com/HuggingPapers/status/2054431768779067542?s=20
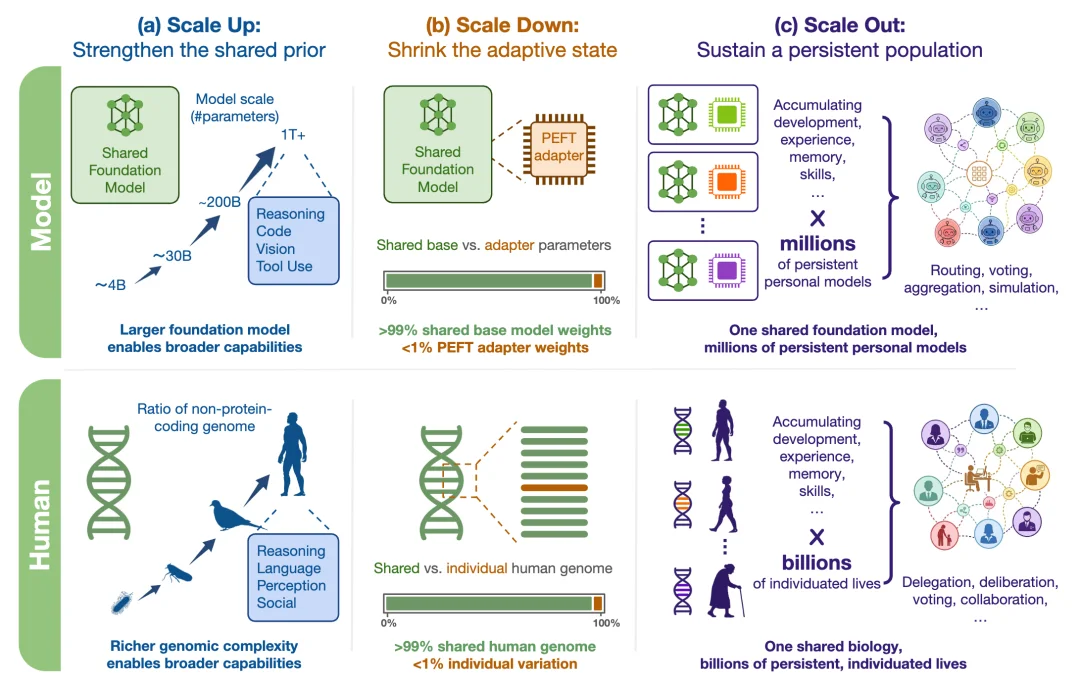
通过构建一条完整的技术链路,涵盖记忆架构(δ-mem)、底层基础设施(MinT)、扩展定律(Scaling of PEFT)以及生成式 UI 应用(Macaron-A2UI),Mind Lab 正在描绘一个宏大的愿景:让极少数强大的万亿参数基础模型,支撑起数以百万计的、具备独立记忆和技能的可持续学习智能体。
基于 LoRA 的线性注意力架构:δ-mem 在线记忆机制
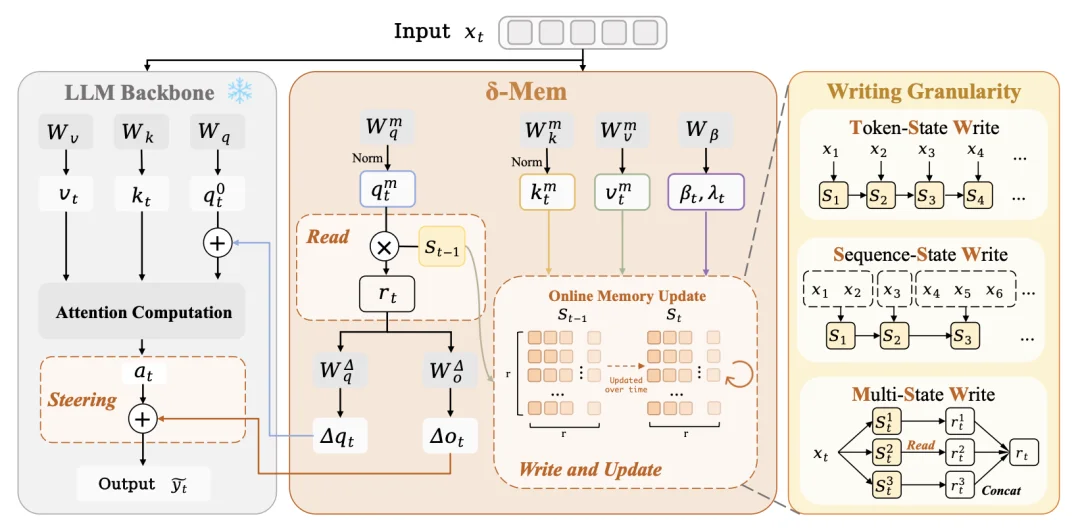
传统 Transformer 的 KV cache 只是推理过程中的冻结缓存,记录的是当前上下文的中间状态,本身不会随着交互持续学习。为了让智能体拥有可更新的持续记忆,Mind Lab 针对 LoRA 的特性提出了创新的平行混合线性注意力架构 δ-mem。
正如多家媒体报道的那样:仅仅使用一个 8×8 的在线记忆状态(参数增加低至 0.12%),δ-mem 就能让模型在 Memory Agent Bench 和 LoCoMo 等重度记忆基准测试中获得高达 1.31 倍和 1.20 倍的性能提升。即使移除了显式的历史上下文,它依然能恢复出大量相关信息。

链接:https://venturebeat.com/orchestration/a-0-12-parameter-add-on-gives-ai-agents-the-working-memory-rag-cant?utm_source=devbytes&utm_medium=androidapp&utm_campaign=fullarticle
与传统依赖扩展上下文窗口或外部文本检索的工程方式不同,δ-mem 深入到参数层进行优化,将冻结的全注意力主干网络与一个紧凑的在线关联记忆状态(Online State of Associative Memory)结合起来。
一名 reddit 网友在论文发布之后快速将 δ-mem 集成到自己的小龙虾中,获得了 agent 在记忆表现上的提升:
链接:https://www.reddit.com/r/LocalLLaMA/comments/1tf68yo/i_fitted_the_new_% CE% B4mem_research_for_apple_silicon/
δ-mem 会随着 Token 的输入,利用增量规则(delta-rule learning)持续更新一个固定大小的矩阵。在生成时,系统会从该状态中读取信号,对主干网络的 Attention Query 和 Output 施加低秩校正(low-rank corrections)。
X 网友 Dan 赞叹道:这就是 continual learning 的未来!

链接:https://x.com/daniel_mac8/status/2055740325822333419?s=20
LoRA Infra:百万级 LLM 的训练与服务基建 (MinT)
基于模型持续学习所打造的 agent 产品需要新的基础设施,Mind Lab 给出了他们的答案 MinT。
什么是 MinT, 我们可以先看 X 网友 Awais 的解读。

来源:https://x.com/drawais_ai/status/2056301110906757464?s=20
简单来讲:MinT 是一个专为 LoRA 训练和在线服务打造的托管基础设施系统。
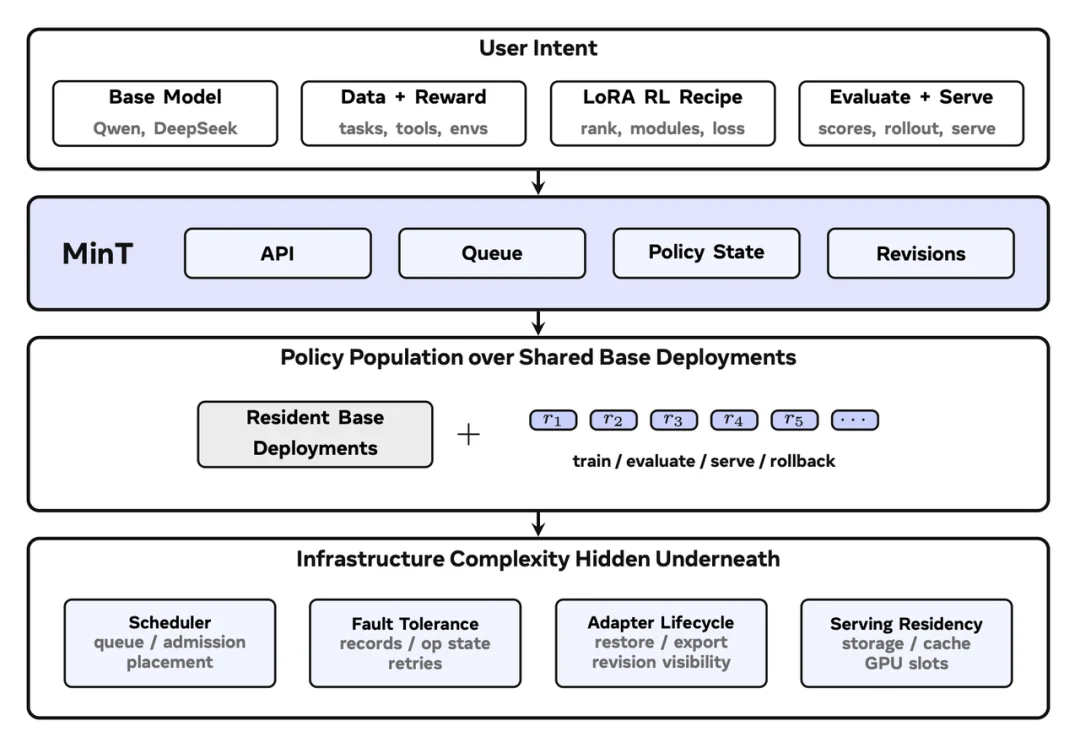
在 δ-mem 中提到,不同的人、不同的方式使用 agent,将会形成不同的记忆状态,LoRA 也同理,管理 LoRA 并非管理单个模型,是管理一大群模型的变体。
每个 LoRA 都有自己的版本、自己的训练曲线、自己的回滚点、更重要的是这个 LoRA 可能正在被某个用户使用着。支撑模型后训练在真实场景中持续学习这件事要成立,必须有一套基础设施能够管理这么多风格各异的 LoRA。
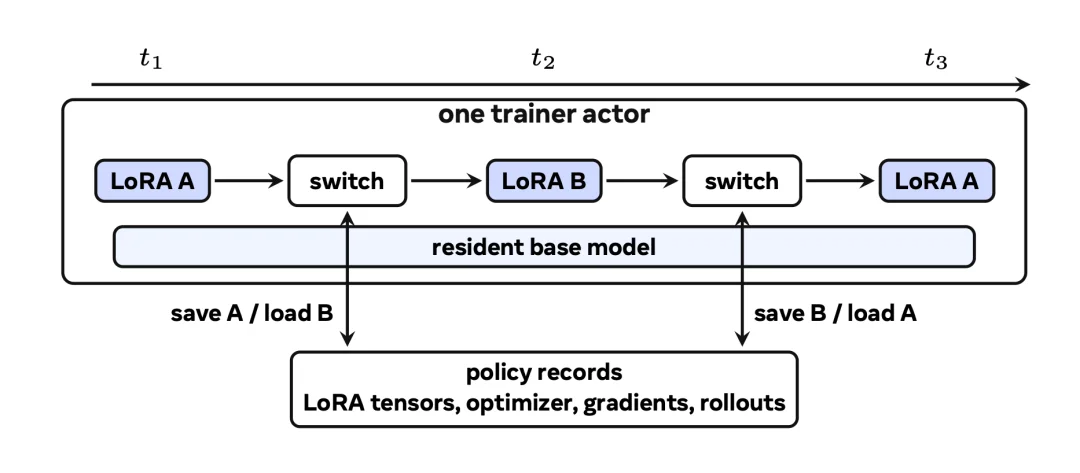
MinT 把基础模型长期保留在训练和推理服务中。一步训练结束后,系统导出的不是完整模型,而是一份很小的 LoRA Adapter。评估、上线和回滚时,MinT 也只移动和加载这份 adapter。
这样,上线一个新策略不需要把 LoRA 合并进完整模型,也不需要重新加载一份完整模型。系统只把新的 adapter 接到已经常驻的基础模型上。Adapter 的文件大小通常不到基础模型的 1%(在 rank-1 配置下可降到约 0.1%)。在实际测量中,从训练完成到推理服务可用的交接时间,最多可缩短 18.3 倍。
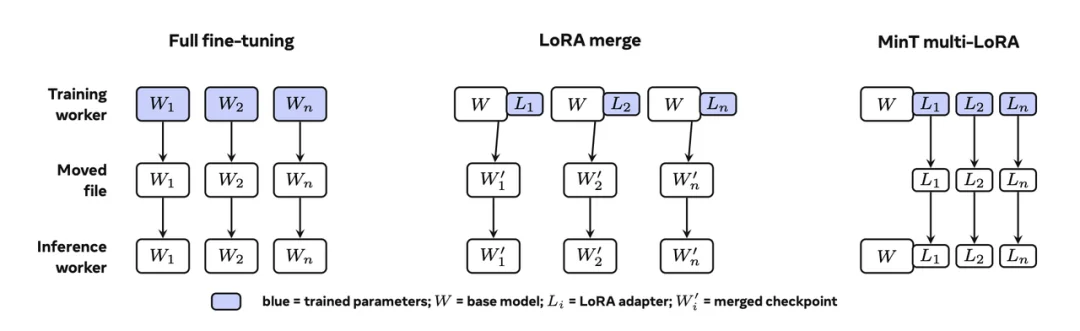
MinT 将持久化的策略目录(或者说海量 LoRA 集)与 CPU/GPU 的热工作集分离,支持 以上级别的策略寻址。针对冷启动加载的瓶颈,MinT 通过打包 MoE LoRA 张量,去除了大量小对象的读写风暴,使引擎的实时加载速度提升了 8.5 至 8.7 倍。
Packing 解决的是单次冷加载问题;为消除新增 LoRA 的冷加载对在线流量的干扰,MinT 进一步引入二阶段 rollout:先在 admission 控制下完成预热,使 LoRA 仅在就绪后才对用户流量可见。在混合负载测试下,该机制将用户可见的 LoRA 加载 p95 降至 0、首请求 TTFT p95 缩短 2.3 倍。
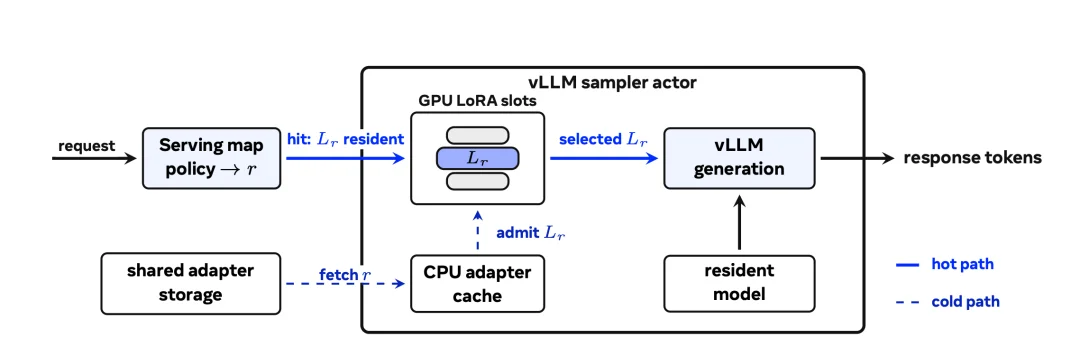
LoRA 的三大扩展轴:On the Scaling of PEFT
来源:https://x.com/HuggingPapers/status/2056021071862575448?s=20
Mind Lab 还发布了关于 LoRA 的研究论文 On the Scaling of PEFT,针对于 base model 能够 serve 百万个 LoRA 模型的可行性提出了三大基于 LoRA 的扩展轴:
第一个扩展轴:Scale up
强大的基础模型能让微小的更新产生巨大的杠杆效应。直觉上更大参数能够让模型拥有更强的能力,在基础上训练的 LoRA 也会有更强的表现。
1T 规模的稀疏 MoE 上进行 LoRA 强化学习并非容易之事,因为 MoE 在训练和推理过程中专家的激活路径不同会产生严重的训推不一致的现象。在 scale up 的过程中,Mind Lab 发现了现有路由重放(Router Replay)机制在前沿 MoE 模型上失效原因并提出相应修正以消除训练和推理的差异。
第二个扩展轴:Scale down
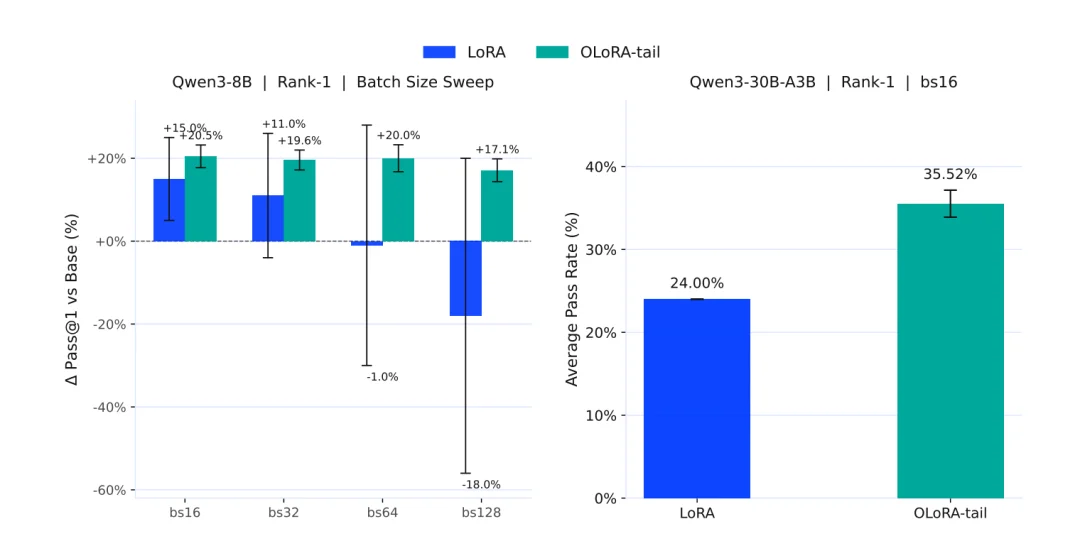
LoRA rank 决定 RL 适配的表达能力强弱。业界通常把 rank 设在 16–32,以求更稳的训练和推理。但要同时服务上百万模型,rank 还得继续压到 16 以下,而且性能不能掉。
得益于 MinT adapter 的架构,Mind Lab 通过了一种原生于 RL 的初始化方法 OLoRA-tail。将 LoRA scale down 到了极致。该方法利用预训练权重的次要奇异向量(minor singular vectors)进行初始化,并移除了可能导致强化学习不稳定的奇异值缩放因子,在不增加参数量的前提下,大幅提升了 Rank-1 适配器的稳定性与性能。
第三个扩展轴:Scale out
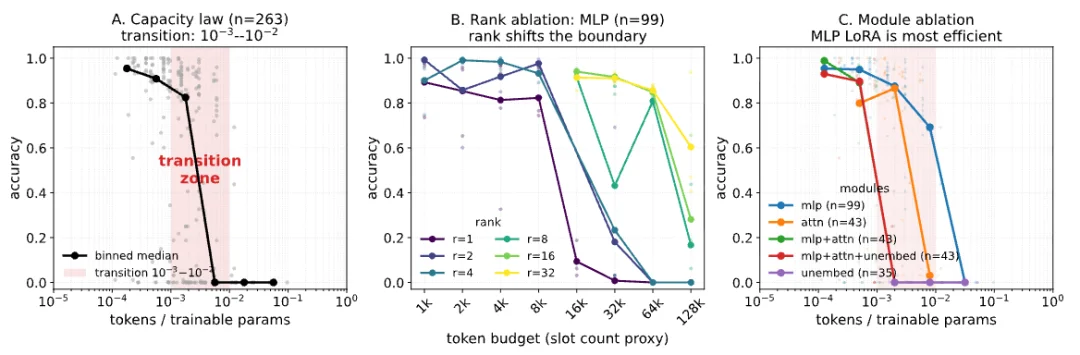
MinT 让上百个 LoRA adapter 同时在线,"模型数量" 成了可控的 scaling 变量。
模型的多样性从何而来?与 δ-mem 一脉相承,Mind Lab 提出了 LoRA as Memory 的概念并证明 LoRA 容量约 tokens/param,是一种有限介质,应留给 skill、persona 等持久行为状态而非可编辑事实,以适应底座模型分布外的任务;这种持续学习由 Context Learning 完成,让不同的 adapter 沿不同路径分化。


近期美团、阿里的研究也指向同一方向,LoRA RL 内化的技能能够为困难任务奠定认知基础,表现显著优于 skill 或 context,且 LoRA 能以极少参数高效装下结构化事实,形成差异化的稳定模型。
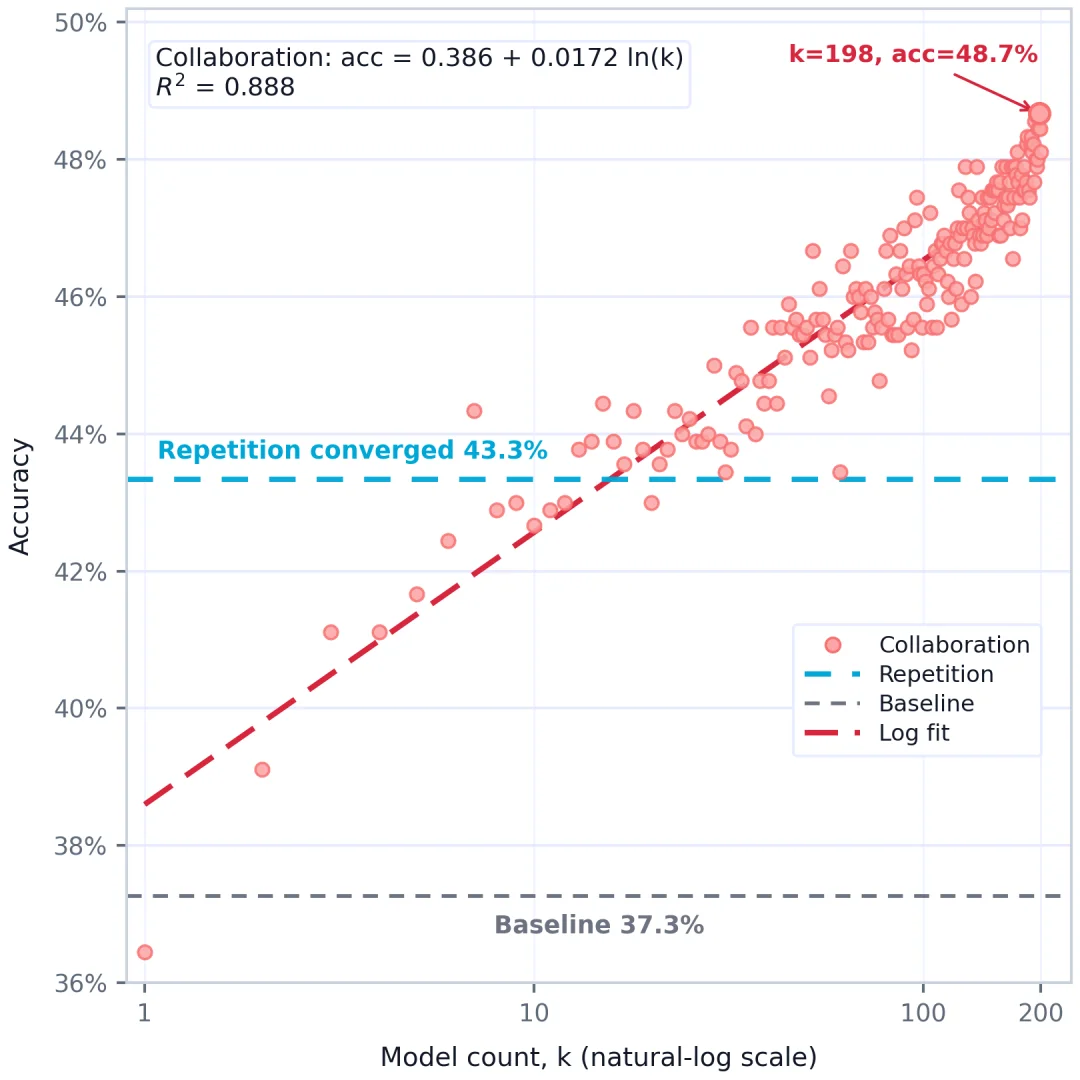
这种差异在聚合时被兑现, 多数投票下准确率随模型数量 k 呈现出经验上的对数增长定律()。这也是在三个扩展轴上涌现出来的、基于模型数量的 scaling law。
Macaron-A2UI:走向生成式 UI 的智能交互
不只是理论,Mind Lab 也试验性地发布了一个基于 MinT 训练出来的模型Macaron-A2UI。
他们自己的描述是:纯文本对话在处理复杂的用户任务时存在认知负荷高、流程繁琐的瓶颈。为此,Mind Lab 基于 MinT 训练了根据用户专属习惯持续学习的生成式 UI 模型 Macaron-A2UI。
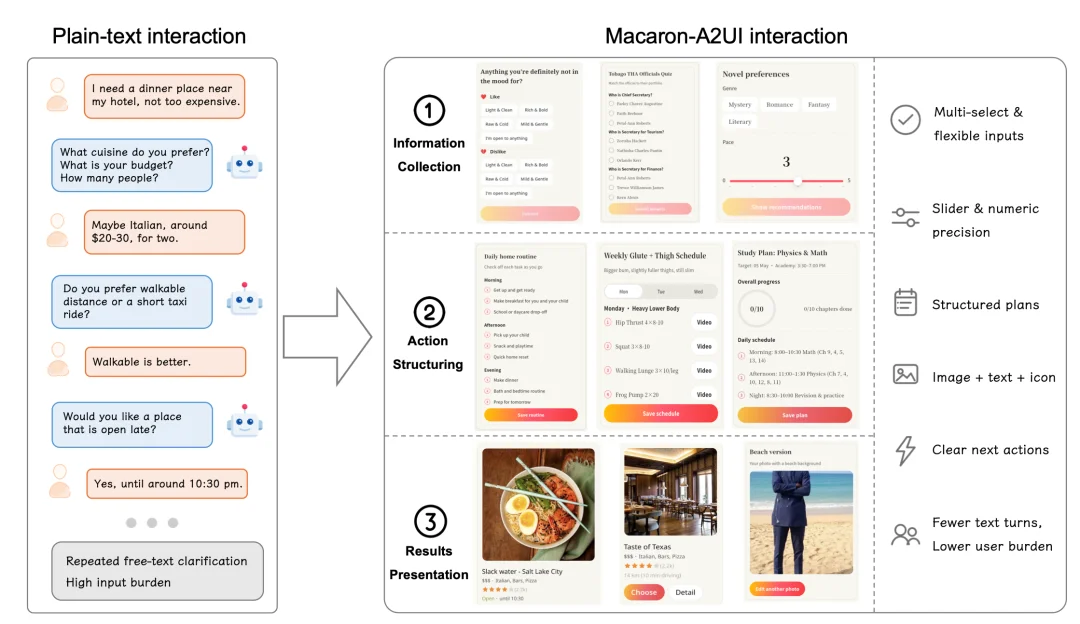
模型不仅仅输出文本,还能在实时交互中生成结构化的 A2UI 可执行动作(如多选框、滑块、确认卡片等)。
Macaron-A2UI 的训练过程也是诠释了 Mind Lab 上面的一系列理论:在 30B,235B 和 754B 的大语言模型底座上,基于 MinT 平台,团队先使用基于 LoRA 的 SFT(监督微调)建立文本到 UI 的对齐,随后使用 GRPO 强化学习提升可执行交互的质量。
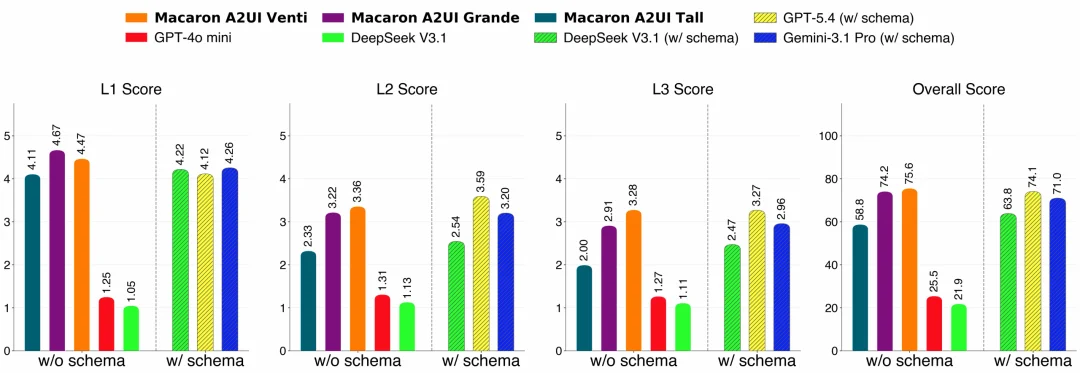
在极其轻量级的 Schema 提示下,表现最好的 Macaron-A2UI-Venti 模型在 A2UI-Bench 上斩获了 75.6 的综合高分,甚至超越了输入了完整冗长 Schema(长度约为 27 倍) 提示的最强前沿模型基线。这证明了复杂的 UI 生成能力完全可以通过高效微调被内化到模型权重中。
总结
从如今通用模型的痛点出发,Mind Lab 打造了能够在线持续学习的 δ-mem、面向百万 LoRA 模型的训推基础设施 MinT 以及 LoRA Scaling Law 理论。从最新发布的 A2UI 模型,到一贯坚持的持续学习研究方向,Mind Lab 再次展示了从应用、系统到理论的研究纵深。
据悉,Mind Lab 的所属公司是 Mindverse(心洲科技)。这家中国原生的 Neo Lab 跑通了一条低成本高收益的持续学习之路,正如其论文所描绘的那样,未来的 AI 架构或许正是如此:少数几个强大的万亿参数基础模型,支撑起数百万个参数量极小但具有独立个性、记忆和 UI 交互能力的可持续学习智能体。
文章来自于微信公众号 "机器之心",作者 "机器之心"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
