# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Harvey 是全球最大的法律 AI 公司,客户是世界顶尖律所和企业法务团队。你可能没怎么听说过它,但在法律行业,它基本上是那个大家已经在用、不需要再讨论的选择——就像律师界的 Salesforce,你不会问"要不要用",只问"怎么接进来"。
6 月 1 日,联合创始人兼总裁 Gabe Pereyra 写了一篇很少见的技术文章:Harvey 为什么决定自己建云 Agent 基础设施,而不是用 OpenAI Agents API、Anthropic 的托管平台或者 Google Vertex AI。
现成的方案明明更快、更省事,他们为什么要多走这条路?
我读完停了一下。这篇文章里的逻辑,不只是 Harvey 的选择,它揭示的是任何认真做企业 AI Agent 的公司,迟早会撞上的那堵墙。

Harvey 的架构:一个抽象层统一连接多个模型提供商,底层跑在 Azure / AWS / Google Cloud
Harvey 两年前是聊天界面——律师问,AI 答,每次交互彼此独立。
今天完全不同了。一次 Agent 运行,背后是数百次模型调用加上工具调用、文件读写、中间状态保存、断点续跑的整条链路。一个复杂的法律任务——比如跨多份合同做条款比对,或者在大量案例里找先例——可能跑几分钟,也可能跑几小时,期间需要暂停、恢复,还要能回溯到任意检查点。
单次对话没有这个问题。Agent 有。
这时候,"调一个 API 就够了"的心智模型就不够用了。你需要的是一个完整的运行时(runtime)——管理跨步骤的状态、协调多个模型的调用顺序、处理工具执行的异常、保证数据安全边界。这个运行时,才是 Gabe 这篇文章真正在谈的东西。
「从聊天到 Agent,不只是换个界面。运行时的复杂度上升了一个数量级。」

左:绑定单一提供商,整个 Agent 工作流锁死在一个模型上;右:Harvey 自建抽象层,模型选择变成一个路由决策
最省事的选择是直接用 OpenAI 的 Agents API,或者 Anthropic 的托管方案。模型、运行时、工具调用框架全包了,接入几天就能跑起来,不需要自己搞基础设施。
Harvey 的工程团队认真评估过这条路。Gabe 说,评估之后他们发现有三个根本性的问题。不是"暂时的缺陷,等提供商更新一下就好了",而是结构性的不兼容——只要你用的是别人的托管平台,这三个问题就不会消失。
这三个问题,是他们决定自己建基础设施的全部理由。
法律 AI 这个行当,出错的代价是真实的。一份合同条款分析漏了关键风险点,可能就是几千万美元的合规敞口。Harvey 对每个新模型都跟得很紧,哪家有新进展就立刻评测,有更好的选项就换——我在旁边观察过类似的公司,这种紧张程度说实话有点神经质,但在这个行业里,这是对的。
这听起来理所当然,但托管平台的商业逻辑不支持这件事。
用 OpenAI 的 Agents API,你只能用 OpenAI 的模型。用 Anthropic 的托管平台,只能用 Claude。用 Google Vertex AI,只能跑 Gemini。
「模型提供商有内在的动机,让他们的平台绑定在自己的模型上——这不是批评,这是正当的商业逻辑。但对我们来说是个问题。」
Harvey 的要求是:今天用 Claude Sonnet 4.6,明天如果 Gemini 在某类文件分析任务上更准,就切 Gemini。后天 DeepSeek v4 Pro 在成本上碾压,就让 DeepSeek 跑那类任务。模型选择应该是一个路由决策,而不是一个基础设施锁定。
自己建运行时,才能在不改动 Agent 逻辑的前提下自由切换底层模型。用大厂平台,这扇门从一开始就关上了。
ZDR,Zero Data Retention,零数据留存。这是 Harvey 给顶尖律所和企业法务客户的安全承诺:你发给我们的任何数据,不会被写到磁盘上,不会被保留,会话结束就彻底消失。没有备份,没有日志,没有"存在第三方某台服务器上"。
这在法律行业几乎是必选项。律师事务所和企业法务处理的是未公开的并购信息、专利诉讼策略、高管薪酬结构——这类数据一旦留在任何一个不属于客户的系统里,合规部门和客户都过不了这一关。
听起来像是一个合规配置,打个勾就好了?
Gabe 说,不是这样的。ZDR 和有状态的 Agent 运行,在架构上是根本矛盾的——除非你完全控制自己的运行时。
我在这里停了好久。让我把这个矛盾说清楚。
有状态的 Agent 运行,意味着中间状态需要被持久化。一个复杂法律任务跑到一半,机器重启了,或者律师想第二天继续,你需要能从某个检查点恢复——这要求把工作记忆、中间文件、工具结果、检查点写到磁盘,静止存在,等待下次调用。这是 OpenAI、Anthropic 等托管平台的运作方式:状态写盘,跑完要手动调用 delete() 清除。
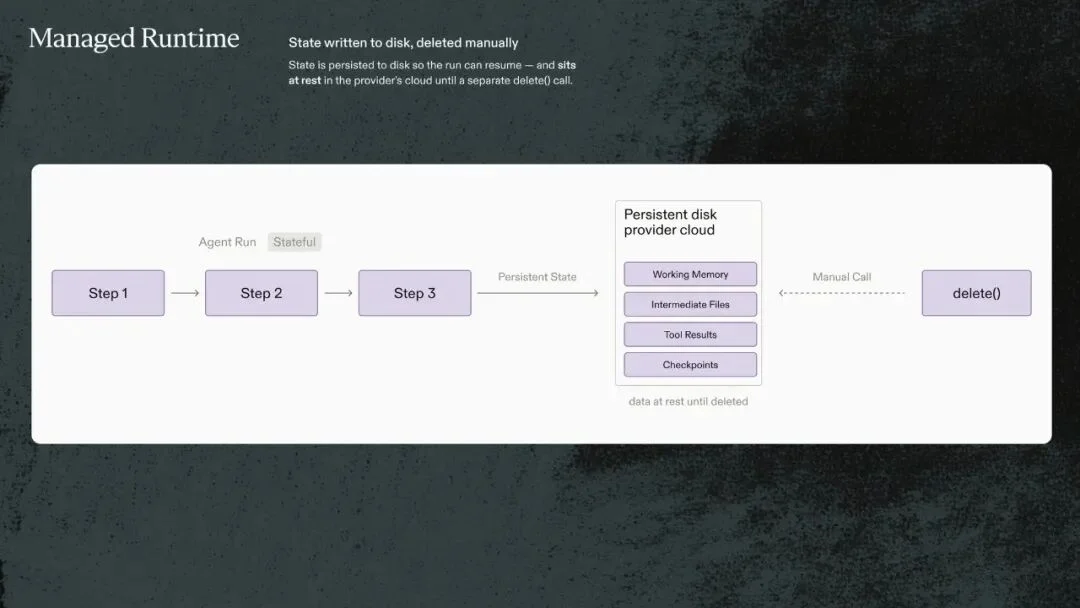
托管 Runtime:Agent 执行过程中状态写入磁盘,数据静止在提供商云端,需手动调用 delete() 清除
但 ZDR 要求数据永远不落盘。不是"加密存储",不是"用完手动删",而是物理上从来没有写过任何地方。客户的合同草案、内部会议纪要、诉讼证据策略——在任何不属于客户自己的服务器上存在,哪怕是短暂存在,都是合规风险。
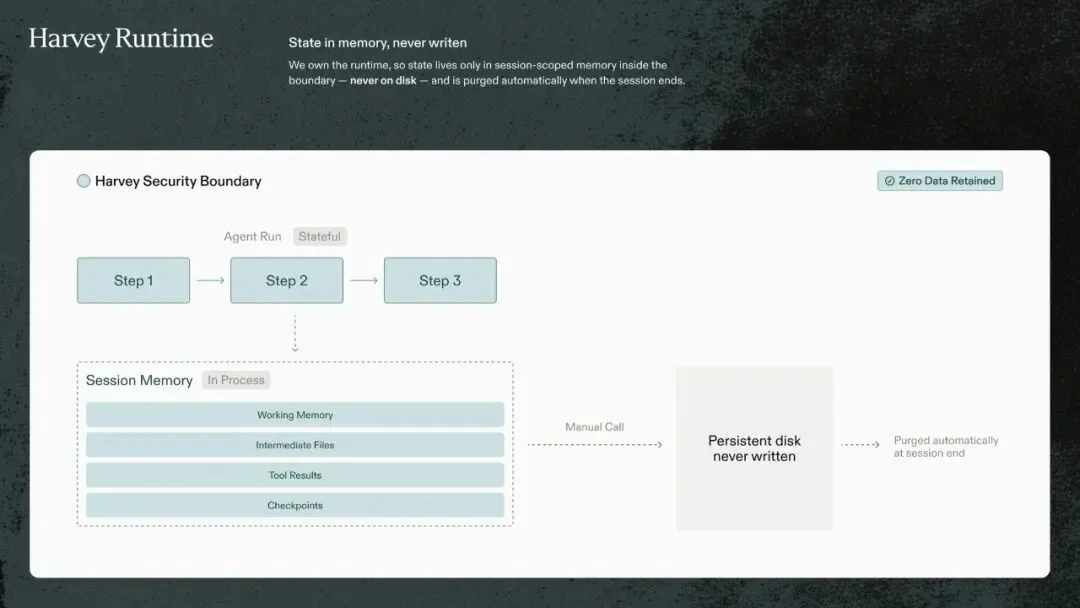
Harvey Runtime:状态只活在会话内存里,永不写入磁盘,会话结束自动清除——零数据留存
Harvey 的解决方案是:自己控制运行时,把 Agent 运行过程中产生的所有状态都留在内存里。会话结束,内存自动释放,状态永远不存在过。没有第三方云上的持久化磁盘,没有需要主动清除的东西,因为压根没有写过。
这个能力,只有完全控制运行时才能做到。用大厂托管平台,状态写在他们的磁盘上,你没有办法改变这件事。ZDR 和托管平台,在架构上互斥。
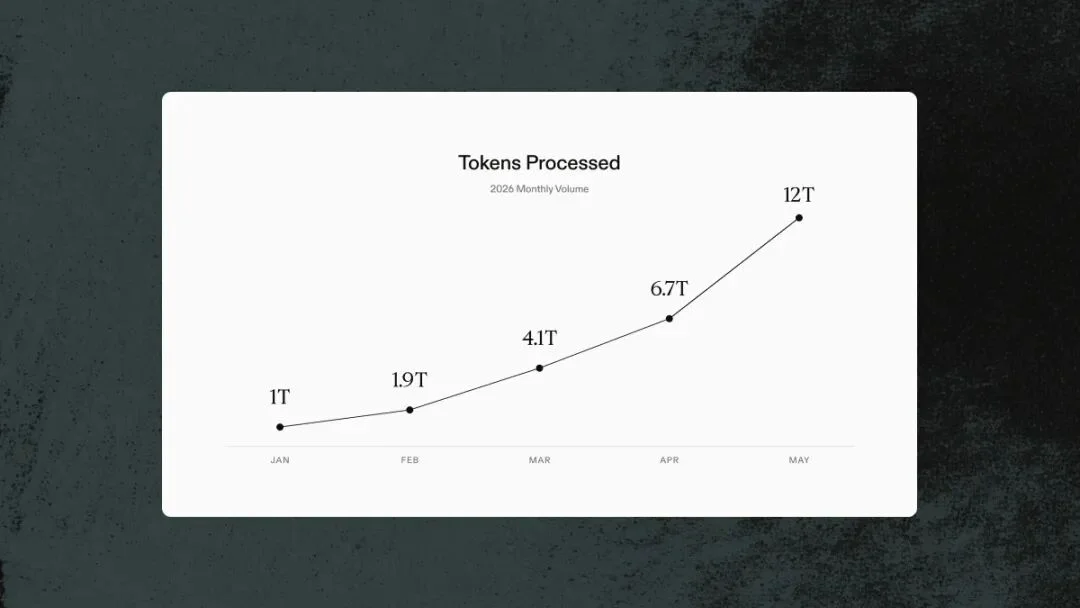
Harvey 2026 年 token 处理量:1 月 1 万亿 → 5 月 12 万亿,五个月增长 12 倍
这张图是全文最直接的数字。Harvey 5 月份处理了12 万亿 token,从 1 月的 1 万亿涨到现在,五个月涨了 12 倍。
在这个量级下,成本是一件非常认真的事。Gabe 说,自建基础设施之后,成本下降了3 到 5 倍。
怎么做到的?两个杠杆:一是可以根据任务类型选最合适的模型——不同法律任务对质量要求不同,合同摘要和高风险条款审查不需要用同一个模型,可以把轻量任务路由给成本更低的选项;二是可以用开源模型,完全避开商业 API 的溢价。
「我们现在用的开源模型,在 LAB 基准测试上的得分,已经能和一年前的前沿闭源模型持平,而成本是当时的一小部分。」
对于月处理 12 万亿 token 的公司来说,3-5 倍的成本差,是非常实际的数字。
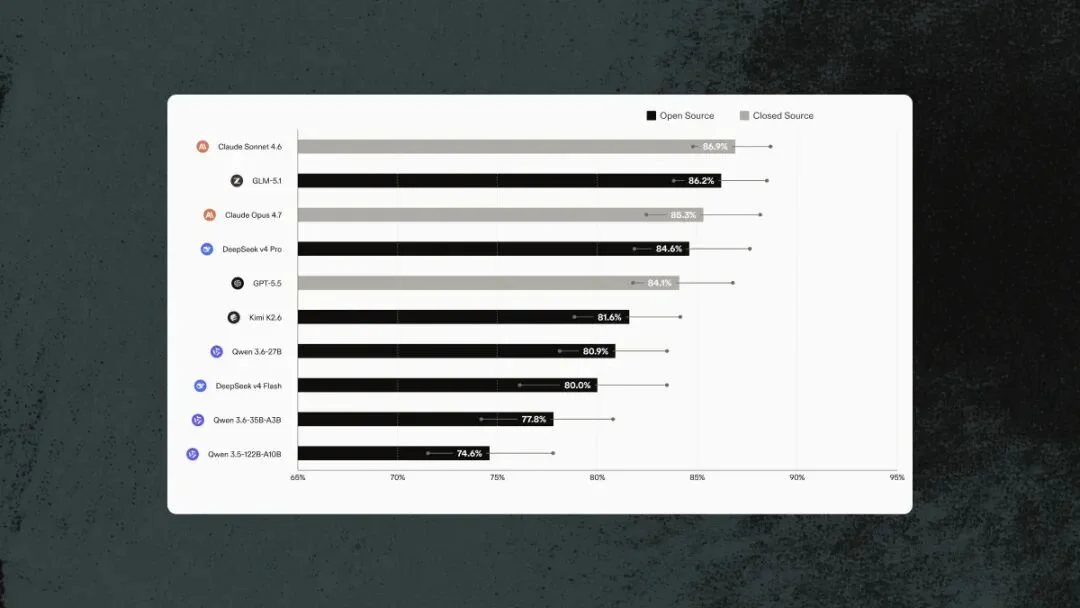
LAB(法律 Agent 基准)2026 年排行:开源模型正快速逼近闭源,GLM-5.1、DeepSeek v4 Pro 已进前四
这张 LAB 榜单是全文技术含量最高的部分。LAB 是 Harvey 自己建的法律 Agent 基准测试,专门评估模型在真实法律任务上的表现——不是通用 MMLU,是合同分析、案例检索、条款比对这类具体任务。
第一名是 Claude Sonnet 4.6,86.9%,闭源。
第二名是 GLM-5.1,86.2%,开源。差距只有 0.7 个百分点。
第四名 DeepSeek v4 Pro,84.6%,开源。第七名 Qwen 3.6-27B,80.9%,开源。
闭源模型仍然领先,但榜单上半段已经是开源和闭源混杂。一年前这张图大概率是清一色 GPT-4、Claude,现在面目全非了。
更重要的是,想用这些开源模型,你必须有自己的运行环境——你没办法在 OpenAI 的平台上跑 DeepSeek v4 Pro。这个逻辑反过来也成立:正因为你有了自建运行时,你才能做到"选最好最便宜的那个模型,不管它属于哪家公司"。自建基础设施和开源模型,是互相成立的。
这里有一个连环:模型差距在缩小 → 开源变得竞争力十足 → 用开源需要自建运行时 → 自建运行时又给了多模型灵活性和 ZDR。三个原因最终形成了一个互相强化的整体。
Harvey 的技术答案是一个抽象层(Abstraction Layer)。从架构图上看,它坐在 Agent 和所有模型提供商、所有云之间,把 harness(执行框架)、sandbox(沙盒)、behavior(行为规范)、routing(路由策略)全部标准化。
好处是:无论底层换模型还是换云,上层的 Agent 代码不需要动。今天在 Azure 上跑 Claude Sonnet,明天切到 AWS 上跑 DeepSeek v4 Pro,Agent 本身感知不到。换模型从一次"重大迁移"变成了一行配置改动。
代价是显然的:这层东西需要自己建、自己维护,而且它是基础设施,稳定性要求极高。Harvey 有工程能力和业务规模来支撑这个决定,大部分公司未必有。
我注意到一个细节:Gabe 在文章里的语气,不是"所有人都应该这么做",而是非常克制地说"对我们来说,这三个原因足够充分"。他花了相当大的篇幅解释为什么这不是每家公司的正确选择——对于量级不够大、数据敏感度没那么高的场景,用托管平台反而是更理性的决定。
这种分寸感很少见。通常写这类文章的人,总是想证明自己的路才是正确答案。
我读完这篇的第一反应是:Harvey 的三个理由,其实是一套选择框架,帮你判断什么时候值得自建运行时,什么时候不值得。
如果你不需要多模型灵活性——你现在用一个模型,未来也不打算换——那用托管平台是合理的。如果你的数据安全要求没有到 ZDR 级别,没有"数据不能落在第三方云"的硬约束,那也不需要为了这个自建。如果你的量级没有大到让 3-5 倍的成本差变得致命,那省下的工程成本比省下的计算成本更有价值。
Harvey 自建,是因为这三条他们都触到了,而且每一条都是硬约束,不是"最好有"。法律行业的数据敏感性、顶尖律所的合规要求、每月 12 万亿 token 的量级——把这三个放在一起,自建就变成了唯一合理的选择。
但我读完之后真正停下来想的,是另一件事。
Gabe 说这篇文章"本该早两年就写"——言下之意是,他们这个决定,是在正式构建 Agent 基础设施之前就做的,不是做了一半发现不对劲再回头的。
这个次序很关键。如果 Harvey 两年前先用了 OpenAI 的托管平台,今天要满足 ZDR、要跑多模型、要降低成本,迁移成本会非常高——不只是技术层面,还有客户承诺、合同条款、安全审计。
基础设施选型的问题,不是「现在够不够用」,是「三年后如果要换,代价是什么」。
大多数人在选型的时候问的是前半个问题。Harvey 的文章提醒你记得问后半个。
我说不好这套架构有多少人应该复制。Harvey 的体量和行业是极少数的组合,大多数公司也许这辈子都到不了需要做这个决定的门槛。
而且我不确定,即使问到了后半个问题,大多数公司的现实资源也未必能让他们提前做出最优选择。这个问题是对的,但能不能真的按答案行动,是另一件事。
也许真正值得带走的,只是那个习惯:在选一个基础设施之前,花十分钟问自己——三年后如果要换,那条路有多长?
来源:Gabe Pereyra (@gabepereyra),X Article,2026年6月1日
• 原文:Why we Built our own Cloud Agent Infrastructure
文章来自于"深思SenseAI",作者 "深思SenseAI"。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
